一、TCP的粘包和拆包问题?
TCP在发送和接受数据的时候,有一个滑动窗口来控制接受数据的大小,这个滑动窗口你就可以理解为一个缓冲区的大小。缓冲区满了就会把数据发送,数据包的大小是不固定的,有时候比缓冲区大有时候小。
如果一次请求发送的数据量比较小,没达到缓冲区大小,TCP则会将多个请求合并为同一个请求进行发送,这就形成了粘包问题;
如果一次请求发送的数据量比较大,超过了缓冲区大小,TCP就会将其拆分为多次发送,这就是拆包,也就是将一个大的包拆分为多个小包进行发送。
TCP会发生粘包问题:TCP 是面向连接的传输协议,TCP 传输的数据是以流的形式,而流数据是没有明确的开始结尾边界,所以 TCP 也没办法判断哪一段流属于一个消息;TCP协议是流式协议;流式协议是协议的内容是像流水一样的字节流,内容与内容之间没有明确的分界标志,需要认为手动地去给这些协议划分边界。
粘包时:发送方每次写入数据 < 接收方套接字(Socket)缓冲区大小。
拆包时:发送方每次写入数据 > 接收方套接字(Socket)缓冲区大小。
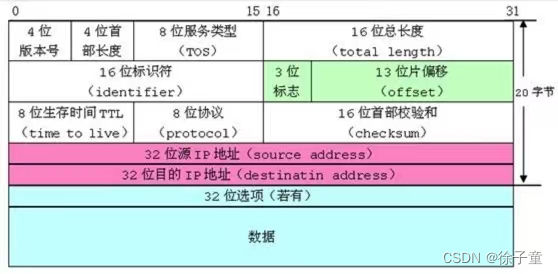
UDP不会发生粘包问题:UDP具有保护消息边界,在每个UDP包中就有了消息头(UDP长度、源端口、目的端口、校验和)。
粘包拆包问题在数据链路层、网络层以及传输层都有可能发生。日常的网络应用开发大都在传输层进行,由于UDP有消息保护边界,不会发生粘包拆包问题,因此粘包拆包问题只发生在TCP协议中。
对于粘包和拆包问题,常见的解决方案有四种:
- 客户端在发送数据包的时候,每个包都固定长度,比如1024个字节大小,如果客户端发送的数据长度不足1024个字节,则通过补充空格的方式补全到指定长度;
- 客户端在每个包的末尾使用固定的分隔符,例如\r\n,如果一个包被拆分了,则等待下一个包发送过来之后找到其中的\r\n,然后对其拆分后的头部部分与前一个包的剩余部分进行合并,这样就得到了一个完整的包;
- 将消息分为头部和消息体,在头部中保存有当前整个消息的长度,只有在读取到足够长度的消息之后才算是读到了一个完整的消息;
- 通过自定义协议进行粘包和拆包的处理。
HTTP如何解决粘包问题的?
http请求报文格式
1)请求行:以\r\n结束;
2)请求头:以\r\n结束;
3)\r\n;
3)数据;
http响应报文格式
1)响应行:以\r\n结束;
2)响应头:以\r\n结束;
3)\r\n;
4)数据;
读取请求行/请求头、响应行/响应头
- 遇到第一个\r\n表示读取请求行或响应行结束;
- 遇到\r\n\r\n表示读取请求头或响应头结束;
读取body数据
- HTTP协议通常使用Content-Length来标识body的长度。在服务器端,需要先申请对应长度的buffer,然后再赋值。
- 如果需要一边生产数据一边发送数据,就需要使用"Transfer-Encoding: chunked" 来代替Content-Length,也就是对数据进行分块传输。
Content-Length 描述
http server接收数据时,发现header中有Content-Length属性,则读取Content-Length的值,确定需要读取body的长度。
http server发送数据时,根据需要发送byte的长度,在header中增加Content-Length项,其中value为byte的长度,然后将byte数据当做body发送到客户端。
chunked描述
http server接收数据时,发现header中有Transfer-Encoding: chunked,则会按照chunked协议分批读取数据。
http server发送数据时,如果需要分批发送到客户端,则需要在header中加上Transfer-Encoding:chunked,然后按照chunked协议分批发送数据。
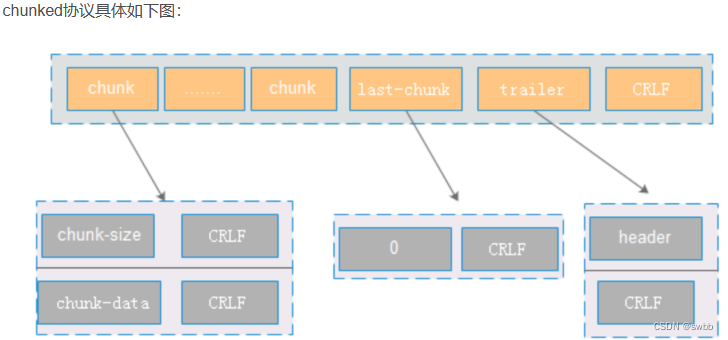
- 主要包含三部分: chunk,last-chunk和trailer。如果分多次发送,则chunk有多份。
- chunk主要包含大小和数据,大小表示这个这个chunk包的大小,使用16进制标示。其中chunk之间的分隔符为CRLF。
- 通过last-chunk来标识chunk发送完成。一般读取到last-chunk(内容为0)的时候,代表chunk发送完成。
- trailer表示增加header等额外信息,一般情况下header是空。通过CRLF来标识整个chunked数据发送完成。
- 优点
- 假如body的长度是10K,对于Content-Length则需要申请10K连续的buffer,而对于Transfer-Encoding:chunked可以申请1k的空间,然后循环使用10次。节省了内存空间的开销。
- 如果内容的长度不可知,则可使用chunked方式能有效的解决Content-Length的问题
- http服务器压缩可以采用分块压缩,而不是整个块压缩。分块压缩可以一边进行压缩,一般发送数据,来加快数据的传输时间。
- 缺点
- chunked协议解析比较复杂。
- 在http转发的场景下(比如nginx)难以处理,比如如何对分块数据进行转发。
二、HTTP和HTTPS的区别
- URL不同;
- 默认端口不同,HTTP 是80,HTTPS 是443;
- HTTP 明文传输,数据都是未加密的,安全性较差,HTTPS(SSL+TLS+HTTP) 数据传输过程是加密的,安全性较好;
- 使用 HTTPS 协议需要到 CA(Certificate Authority,数字证书认证机构) 申请证书,一般免费证书较少,因而需要一定费用;
- HTTP 页面响应速度比 HTTPS 快,主要是因为 HTTP 使用 TCP 三次握手建立连接,客户端和服务器需要交换 3 个包,而 HTTPS除了 TCP 的三个包,还要加上TLS握手需要的 9 个包,所以一共是 12 个包;
- HTTPS 其实是建构在 SSL/TLS 之上的 HTTP 协议,所以,要比 HTTP 要更耗费服务器资源。
SSL/TLS 协议基本流程:
- 客户端向服务器索要并验证服务器的公钥。
- 双方协商生产「会话秘钥」。
- 双方采用「会话秘钥」进行加密通信。
前两步也就是 SSL/TLS 的建立过程,也就是 TLS 握手阶段。
TLS 的握手阶段涉及四次通信,使用不同的密钥交换算法,TLS 握手流程也会不一样的,现在常用的密钥交换算法有两种:RSA 算法 (opens new window)和ECDHE 算法 (opens new window)。
SSL/TLS协议通过3点解决HTTP 原有的3大风险:
- 加密传播,防窃听
- 校验机制,防篡改
- CA证书,解决冒充风险
三、TCP如何去抓包
tcpdump 和 Wireshark 就是最常用的网络抓包和分析工具,更是分析网络性能必不可少的利器。
- tcpdump 仅支持命令行格式使用,常用在 Linux 服务器中抓取和分析网络包。
- Wireshark 除了可以抓包外,还提供了可视化分析网络包的图形页面。
四、MySQL中主从架构如何保证数据一致性
在写redo log 和 binlog 这两份日志的时候,如果出现半成功的状态,就会造成主从环境的数据不一致性。这是因为 redo log 影响主库的数据,binlog 影响从库的数据,所以 redo log 和 binlog 必须保持一致才能保证主从数据一致。
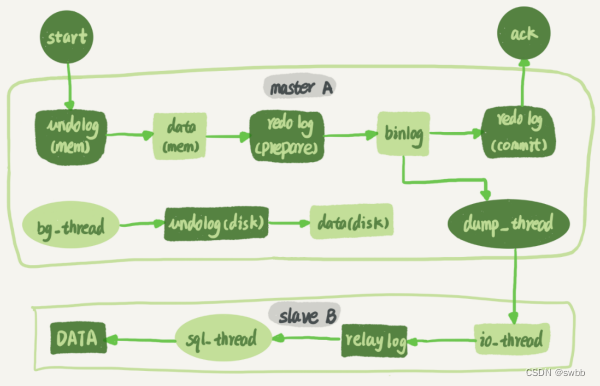
- 在备库 B 上通过 change master 命令,设置主库 A 的 IP、端口、用户名、密码,以及要从哪个位置开始请求 binlog,这个位置包含文件名和日志偏移量。
- 在备库 B 上执行 start slave 命令,这时候备库会启动两个线程,就是图中的 io_thread 和 sql_thread,其中 io_thread 负责与主库的 dump_thread 建立连接。
- 主库 A 校验完用户名、密码后,开始按照备库 B 传过来的位置,从本地读取 binlog,发给 B。
- 备库 B 拿到 binlog 后,写到本地文件,称为中转日志(relay log)。
- sql_thread 读取中转日志,解析出日志里的命令,并执行。
从图中可看出,事务的提交过程有两个阶段,就是将 redo log 的写入拆成了两个步骤:prepare 和 commit,中间再穿插写入binlog,具体如下:
prepare 阶段:将 XID(内部 XA 事务的 ID) 写入到 redo log,同时将 redo log 对应的事务状态设置为 prepare,然后将 redo log 持久化到磁盘(innodb_flush_log_at_trx_commit = 1 的作用);
commit 阶段:把 XID 写入到 binlog,然后将 binlog 持久化到磁盘(sync_binlog = 1 的作用),接着调用引擎的提交事务接口,将 redo log 状态设置为 commit,此时该状态并不需要持久化到磁盘,只需要 write 到文件系统的 page cache 中就够了,因为只要 binlog 写磁盘成功,就算 redo log 的状态还是 prepare 也没有关系,一样会被认为事务已经执行成功;
两阶段提交是以 binlog 写成功为事务提交成功的标识,因为 binlog 写成功了,就意味着能在 binlog 中查找到与 redo log 相同的 XID。
XID 是 binlog 与 redo log 共同的数据字段,崩溃恢复的时候,会按顺序扫描 redo log
- 如果碰到既有 prepare、又有 commit 的 redo log,就直接提交;
- 如果碰到只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应的事务。
在我们真实的开发场景中,往往主库不会一直是主库,从库不会一直是从库。为了保证安全性,往往是这样设计的。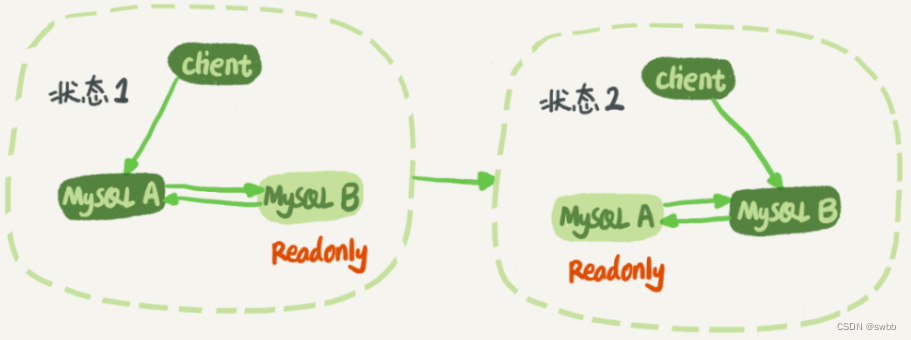
这样的就会出现另一个问题。业务逻辑在节点 A 上更新了一条语句,然后再把生成的 binlog 发给节点 B,节点 B 执行完这条更新语句后也会生成 binlog。(建议把参数 log_slave_updates 设置为 on,表示备库执行 relay log 后生成 binlog)。
那么,如果节点 A 同时是节点 B 的备库,相当于又把节点 B 新生成的 binlog 拿过来执行了一次,然后节点 A 和 B 间,会不断地循环执行这个更新语句,也就是循环复制了。这个要怎么解决呢?
解决方案:
- 规定两个库的 server id 必须不同,如果相同,则它们之间不能设定为主备关系;
- 一个备库接到 binlog 并在重放的过程中,生成与原 binlog 的 server id 相同的新的 binlog;
- 每个库在收到从自己的主库发过来的日志后,先判断 server id,如果跟自己的相同,表示这个日志是自己生成的,就直接丢弃这个日志。
按照这个逻辑,如果设置了双 M 结构,日志的执行流就会变成这样:
- 从节点 A 更新的事务,binlog 里面记的都是 A 的 server id;
- 传到节点 B 执行一次以后,节点 B 生成的 binlog 的 server id 也是 A 的 server id;
- 再传回给节点 A,A 判断到这个 server id 与自己的相同,就不会再处理这个日志。
所以,死循环在这里就断掉了。
防止主从数据的丢失
在MySQL中,一次事务提交后,需要写undo、写redo、写binlog,写数据文件等等。在这个过程中,可能在某个步骤发生crash,就有可能导致主从数据的不一致。为了避免这种情况,我们需要调整主从上面相关选项配置,确保即便发生crash了,也不能发生主从复制的数据丢失。
-
在master上修改配置

上述两个选项的作用是:保证每次事务提交后,都能实时刷新到磁盘中,尤其是确保每次事务对应的binlog都能及时刷新到磁盘中,只要有了binlog,InnoDB就有办法做数据恢复,不至于导致主从复制的数据丢失。
-
在slave上修改配置

上述前两个选项的作用是:确保在slave上和复制相关的数据表也采用InnoDB引擎,受到InnoDB事务安全的保护,而后一个选项的作用是开启relay log自动修复机制,发生crash时,会自动判断哪些relay log需要重新从master上抓取回来再次应用,以此避免部分数据丢失的可能性。
五、算法题
给定一个数组,同时多次给定不同的区间下标i和j(下标从0开始),快速求这些区间和。
解决思路:要快速求多个区间的和,可以使用前缀和(Prefix Sum)的方法。前缀和是指从数组的第一个元素开始,依次累加到当前位置的元素之和。通过计算出数组的前缀和,可以在O(1)的时间内求出任意区间的和,而不需要每次都重新计算。
#include <iostream>
#include <vector>using namespace std;vector<int> prefix_sum(const vector<int>& arr) {int n = arr.size();vector<int> prefix(n + 1, 0);// 计算前缀和for (int i = 1; i <= n; i++) {prefix[i] = prefix[i - 1] + arr[i - 1];}return prefix;
}int interval_sum(const vector<int>& prefix, int i, int j) {// 区间和等于前缀和j处的值减去前缀和i处的值return prefix[j + 1] - prefix[i];
}int main() {// 示例数组vector<int> arr = {1, 2, 3, 4, 5};// 计算前缀和vector<int> prefix = prefix_sum(arr);// 获取区间和int i = 1;int j = 3;cout << "区间[" << i << ", " << j << "]的和为: " << interval_sum(prefix, i, j) << endl;return 0;
}
六、如何解决MySQL深分页问题
日常做分页需求时,一般会用limit实现,但是当偏移量特别大的时候,查询效率就变得低下。
CREATE TABLE account (id int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id',name varchar(255) DEFAULT NULL COMMENT '账户名',balance int(11) DEFAULT NULL COMMENT '余额',create_time datetime NOT NULL COMMENT '创建时间',update_time datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY (id),KEY idx_name (name),KEY idx_update_time (update_time) //索引
) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';假设深分页的执行SQL如下:
select id,name,balance from account where update_time> '2020-09-19' limit 100000,10;

执行完需要0.742秒,深分页为什么会变慢呢?如果换成 limit 0,10,只需要0.006秒哦
先来看下这个SQL的执行流程:
- 通过普通二级索引树idx_update_time,过滤update_time条件,找到满足条件的记录ID。
- 通过ID,回到主键索引树,找到满足记录的行,然后取出展示的列(回表)
- 扫描满足条件的100010行,然后扔掉前100000行,返回后10条。

SQL变慢原因有两个:
- limit语句会先扫描offset+n行,然后再丢弃掉前offset行,返回后n行数据。也就是说
limit 100000,10,就会扫描100010行,而limit 0,10,只扫描10行。 limit 100000,10扫描更多的行数,也意味着回表更多的次数。
通过子查询优化
因为以上的SQL,回表了100010次,实际上,我们只需要10条数据,也就是我们只需要10次回表其实就够了。因此,我们可以通过减少回表次数来优化。
回顾B+ 树结构
那么,如何减少回表次数呢?我们先来复习下B+树索引结构哈~
InnoDB中,索引分主键索引(聚簇索引)和二级索引
- 主键索引,叶子节点存放的是整行数据
- 二级索引,叶子节点存放的是主键的值
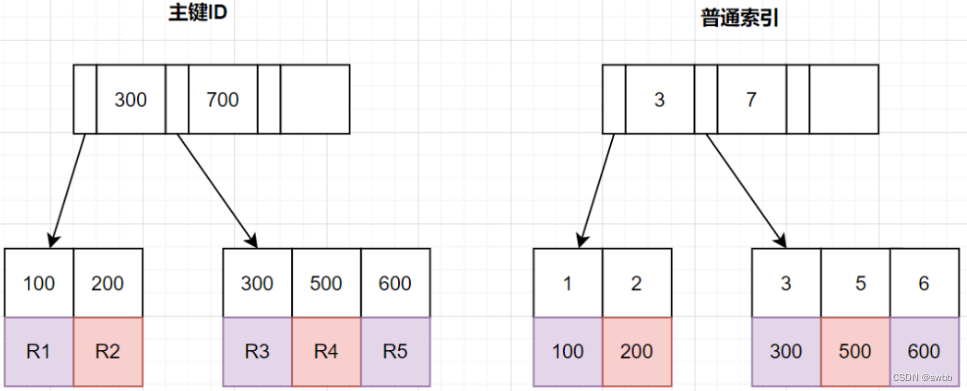
把条件转移到主键索引树
如果我们把查询条件,转移回到主键索引树,那就可以减少回表次数啦。转移到主键索引树查询的话,查询条件得改为主键id了,之前SQL的update_time这些条件咋办呢?抽到子查询那里嘛~
子查询那里怎么抽的呢?因为二级索引叶子节点是有主键ID的,所以我们直接根据update_time来查主键ID即可,同时我们把 limit 100000的条件,也转移到子查询,完整SQL如下:
select id,name,balance FROM account where id >= (select a.id from account a where a.update_time >= '2020-09-19' limit 100000, 1) LIMIT 10;由执行计划得知,子查询 table a查询是用到了idx_update_time索引。首先在索引上拿到了聚集索引的主键ID,省去了回表操作,然后第二查询直接根据第一个查询的 ID往后再去查10个就可以了。

INNER JOIN(内连接) 延迟关联
延迟关联的优化思路,跟子查询的优化思路其实是一样的:都是把条件转移到主键索引树,然后减少回表。不同点是,延迟关联使用了inner join代替子查询。
优化后的SQL如下:
SELECT acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.update_time >= '2020-09-19' ORDER BY a.update_time LIMIT 100000, 10) AS acct2 on acct1.id= acct2.id;查询思路就是,先通过idx_update_time二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表。
标签记录法
limit 深分页问题的本质原因就是:偏移量(offset)越大,mysql就会扫描越多的行,然后再抛弃掉,这样就导致查询性能的下降。
其实我们可以采用标签记录法,就是标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描。就好像看书一样,上次看到哪里了,你就折叠一下或者夹个书签,下次来看的时候,直接就翻到啦。
假设上一次记录到100000,则SQL可以修改为:
select id,name,balance FROM account where id > 100000 order by id limit 10;这样的话,后面无论翻多少页,性能都会不错的,因为命中了id主键索引。但是这种方式有局限性:需要一种连续自增的字段(一般是 order by 主键,使其具有顺序)。
使用between...and...
很多时候,可以将limit查询转换为已知位置的查询,这样MySQL通过范围扫描between...and,就能获得到对应的结果。
如果知道边界值为100000,100010后,就可以这样优化:
select id,name,balance FROM account where id between 100000 and 100010 order by id;