文章目录
- 一、链表的概念及结构
- 二、单链表的实现
- SList.h
- 链表的打印
- 申请新的结点
- 链表的尾插
- 链表的头插
- 链表的尾删
- 链表的头删
- 链表的查找
- 在指定位置之前插入数据
- 在指定位置之后插入数据
- 删除pos结点
- 删除pos之后的结点
- 销毁链表
- 三、完整源代码
- SList.h
- SList.c
- test.c
一、链表的概念及结构
概念:链表是 ⼀种物理存储结构上⾮连续、⾮顺序 的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的
链表的结构跟⽕⻋⻋厢相似,淡季时⻋次的⻋厢会相应减少,旺季时⻋次的⻋厢会额外增加⼏节。只需要将⽕⻋⾥的某节⻋厢去掉/加上,不会影响其他⻋厢,每节⻋厢都是独⽴存在的。
⻋厢是独⽴存在的,且每节⻋厢都有⻋⻔。
想象⼀下这样的场景,假设每节⻋厢的⻋⻔都是锁上的状态,需要不同的钥匙才能解锁,每次只能携带⼀把钥匙的情况下如何从⻋头⾛到⻋尾?
最简单的做法:每节⻋厢⾥都放⼀把下⼀节⻋厢的钥匙。
在链表⾥,每节“⻋厢”是什么样的呢?
与顺序表不同的是,链表⾥的每节"⻋厢"都是独⽴申请下来的空间,我们称之为“结点/节点”
节点的组成主要有两个部分:当前节点要保存的数据和保存下⼀个节点的地址(指针变量)。
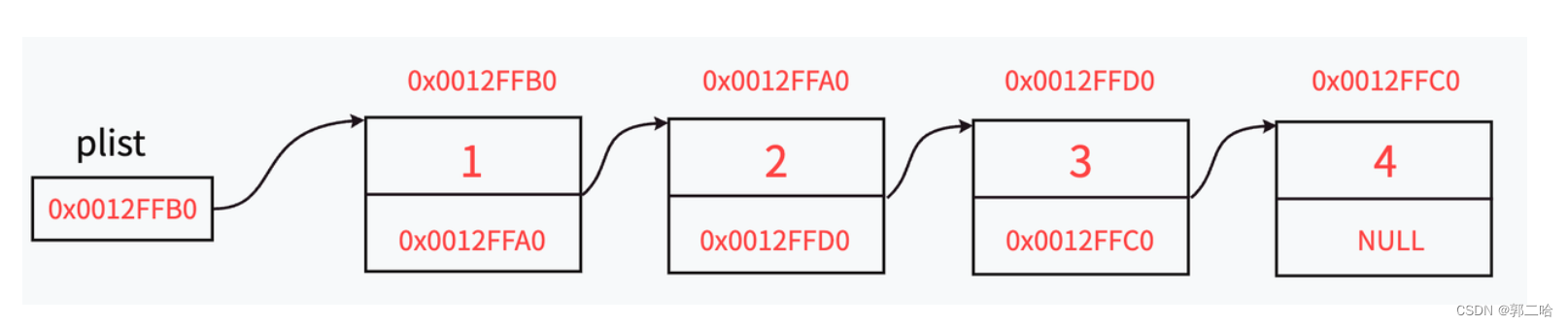
图中指针变量plist保存的是第⼀个节点的地址,我们称plist此时“指向”第⼀个节点,如果我们希
望plist“指向”第⼆个节点时,只需要修改plist保存的内容为0x0012FFA0。
为什么还需要指针变量来保存下⼀个节点的位置?
链表中每个节点都是独⽴申请的(即需要插⼊数据时才去申请⼀块节点的空间),我们需要通过指针
变量来保存下⼀个节点位置才能从当前节点找到下⼀个节点。
结合前⾯学到的结构体知识,我们可以给出每个节点对应的结构体代码:
假设当前保存的节点为整型:
struct SListNode
{
int data; //节点数据
struct SListNode* next; //指针变量⽤保存下⼀个节点的地址
};
当我们想要保存⼀个整型数据时,实际是向操作系统申请了⼀块内存,这个内存不仅要保存整型数
据,也需要保存下⼀个节点的地址(当下⼀个节点为空时保存的地址为空)。
当我们想要从第⼀个节点⾛到最后⼀个节点时,只需要在前⼀个节点拿上下⼀个节点的地址(下⼀个
节点的钥匙)就可以了。
思考:当我们想保存的数据类型为字符型、浮点型或者其他⾃定义的类型时,该如何修改?
可以用typedef将数据类型重命名,这样方便后续修改数据类型
typedef int SLTDateType;//将int类型重命名为SLTDateType
补充说明:
1、链式机构在逻辑上是连续的,在物理结构上不⼀定连续
2、节点⼀般是从堆上申请的
3、从堆上申请来的空间,是按照⼀定策略分配出来的,每次申请的空间可能连续,可能不连续
二、单链表的实现
SList.h 单链表头文件,声明单链表,以及需要的函数
SList.c 单链表函数实现文件
test.c 测试代码
SList.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
//单链表
typedef int SLTDateType;
typedef struct SListNode
{SLTDateType date;struct SListNode* next;
}SLTNode;//链表的打印
void SLTPrint(SLTNode* phead);//链表的尾插
void SLTPushBack(SLTNode** pphead, SLTDateType x);//链表的头插
void SLTPushFront(SLTNode** pphead, SLTDateType x);//链表的尾删
void SLTPopBack(SLTNode** pphead);//链表的头删
void SLTPopFront(SLTNode** pphead);//链表的查找
SLTNode* SLTFind(SLTNode* phead, SLTDateType x);//在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDateType x);//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDateType x);//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos);//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos);//销毁链表
void SListDesTroy(SLTNode** pphead);
链表的打印
//打印
void SLTPrint(SLTNode* phead)
{SLTNode* pcur = phead;while (pcur){printf("%d->", pcur->date);pcur = pcur->next;}printf("NULL\n");
}
申请新的结点
//申请新的结点
SLTNode* SLTBuyNode(SLTDateType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror("malloc fail");exit(1);}newnode->date = x;newnode->next = NULL;return newnode;
}链表的尾插
//尾插
void SLTPushBack(SLTNode** pphead, SLTDateType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);//空链表和非空链表if (*pphead == NULL){*pphead = newnode;}else{//找到尾结点SLTNode* ptail = *pphead;while (ptail->next){ptail = ptail->next;}ptail->next = newnode;}
}
链表的头插
//头插
void SLTPushFront(SLTNode** pphead, SLTDateType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);newnode->next = *pphead;*pphead = newnode;
}
链表的尾删
//尾删
void SLTPopBack(SLTNode** pphead)
{//不能为空链表assert(pphead && *pphead);//只有一个结点if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}//有多个结点else{SLTNode* prev = *pphead;SLTNode* ptail = *pphead;while (ptail->next){prev = ptail;ptail = ptail->next;}free(ptail);ptail = NULL;prev->next = NULL;}
}
链表的头删
//头删
void SLTPopFront(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* next = (*pphead)->next;free(*pphead);*pphead = next;
}
链表的查找
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDateType x)
{assert(phead);SLTNode* pcur = phead;while (pcur){if (pcur->date == x){return pcur;}pcur = pcur->next;}return NULL;
}
在指定位置之前插入数据
//在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDateType x)
{assert(pphead && *pphead);assert(pos);//在第一个结点前插入数据就是头插if (pos == *pphead){SLTPushFront(pphead, x);}else{SLTNode* newnode = SLTBuyNode(x);SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}newnode->next = pos;prev->next = newnode;}
}
在指定位置之后插入数据
//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDateType x)
{assert(pos);SLTNode* newnode = SLTBuyNode(x);newnode->next = pos->next;pos->next = newnode;
}
删除pos结点
//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead && *pphead);assert(pos);//如果是头结点if (pos == *pphead){SLTPopFront(pphead);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;}
}
删除pos之后的结点
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos)
{assert(pos && pos->next);SLTNode* del = pos->next;pos->next = del->next;free(del);del = NULL;
}
销毁链表
//销毁链表
void SListDesTroy(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}
三、完整源代码
SList.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
//单链表
typedef int SLTDateType;
typedef struct SListNode
{SLTDateType date;struct SListNode* next;
}SLTNode;//链表的打印
void SLTPrint(SLTNode* phead);//链表的尾插
void SLTPushBack(SLTNode** pphead, SLTDateType x);//链表的头插
void SLTPushFront(SLTNode** pphead, SLTDateType x);//链表的尾删
void SLTPopBack(SLTNode** pphead);//链表的头删
void SLTPopFront(SLTNode** pphead);//链表的查找
SLTNode* SLTFind(SLTNode* phead, SLTDateType x);//在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDateType x);//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDateType x);//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos);//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos);//销毁链表
void SListDesTroy(SLTNode** pphead);
SList.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "SList.h"//打印
void SLTPrint(SLTNode* phead)
{SLTNode* pcur = phead;while (pcur){printf("%d->", pcur->date);pcur = pcur->next;}printf("NULL\n");
}//申请新的结点
SLTNode* SLTBuyNode(SLTDateType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror("malloc fail");exit(1);}newnode->date = x;newnode->next = NULL;return newnode;
}//尾插
void SLTPushBack(SLTNode** pphead, SLTDateType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);//空链表和非空链表if (*pphead == NULL){*pphead = newnode;}else{//找到尾结点SLTNode* ptail = *pphead;while (ptail->next){ptail = ptail->next;}ptail->next = newnode;}
}//头插
void SLTPushFront(SLTNode** pphead, SLTDateType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);newnode->next = *pphead;*pphead = newnode;
}//尾删
void SLTPopBack(SLTNode** pphead)
{//不能为空链表assert(pphead && *pphead);//只有一个结点if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}//有多个结点else{SLTNode* prev = *pphead;SLTNode* ptail = *pphead;while (ptail->next){prev = ptail;ptail = ptail->next;}free(ptail);ptail = NULL;prev->next = NULL;}
}//头删
void SLTPopFront(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* next = (*pphead)->next;free(*pphead);*pphead = next;
}//查找
SLTNode* SLTFind(SLTNode* phead, SLTDateType x)
{assert(phead);SLTNode* pcur = phead;while (pcur){if (pcur->date == x){return pcur;}pcur = pcur->next;}return NULL;
}//在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDateType x)
{assert(pphead && *pphead);assert(pos);//在第一个结点前插入数据就是头插if (pos == *pphead){SLTPushFront(pphead, x);}else{SLTNode* newnode = SLTBuyNode(x);SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}newnode->next = pos;prev->next = newnode;}
}//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDateType x)
{assert(pos);SLTNode* newnode = SLTBuyNode(x);newnode->next = pos->next;pos->next = newnode;
}//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead && *pphead);assert(pos);//如果是头结点if (pos == *pphead){SLTPopFront(pphead);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;}
}//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos)
{assert(pos && pos->next);SLTNode* del = pos->next;pos->next = del->next;free(del);del = NULL;
}//销毁链表
void SListDesTroy(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}
test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "SList.h"
//测试代码
void test1()
{SLTNode* s1 = (SLTNode*)malloc(sizeof(SLTNode));s1->date = 1;SLTNode* s2 = (SLTNode*)malloc(sizeof(SLTNode));s2->date = 2;SLTNode* s3 = (SLTNode*)malloc(sizeof(SLTNode));s3->date = 3;SLTNode* s4 = (SLTNode*)malloc(sizeof(SLTNode));s4->date = 4;s1->next = s2;s2->next = s3;s3->next = s4;s4->next = NULL;//测试打印SLTNode* plist = s1;SLTPrint(plist);
}void test2()
{SLTNode* s = NULL;SLTPrint(s);//测试尾插SLTPushBack(&s, 2);SLTPushBack(&s, 3);SLTPushBack(&s, 4);SLTPrint(s);//测试头插/*SLTPushFront(&s, 8);SLTPushFront(&s, 7);SLTPushFront(&s, 6);SLTPrint(s);*///测试尾删/*SLTPopBack(&s);SLTPrint(s);SLTPopBack(&s);SLTPrint(s);SLTPopBack(&s);SLTPrint(s);SLTPopBack(&s);SLTPrint(s);*///测试头删/*SLTPopFront(&s);SLTPrint(s);SLTPopFront(&s);SLTPrint(s);SLTPopFront(&s);SLTPrint(s);SLTPopFront(&s);SLTPrint(s);*///测试查找/*SLTNode* find = SLTFind(s, 40);if (find != NULL){printf("找到了!\n");}else{printf("没有找到!\n");}*///测试在指定位置之前插入数据/*SLTNode* find = SLTFind(s, 3);SLTInsert(&s, find, 8);SLTPrint(s);*///测试在指定位置之后插入数据/*SLTNode* find = SLTFind(s, 2);SLTInsertAfter(find, 8);SLTPrint(s);*///删除pos结点/*SLTNode* find = SLTFind(s, 2);SLTErase(&s, find);SLTPrint(s);*///删除pos之后的结点/*SLTNode* find = SLTFind(s, 3);SLTEraseAfter(find);SLTPrint(s);*///链表的销毁SListDesTroy(&s);SLTPrint(s);
}int main()
{//test1();test2();return 0;
}