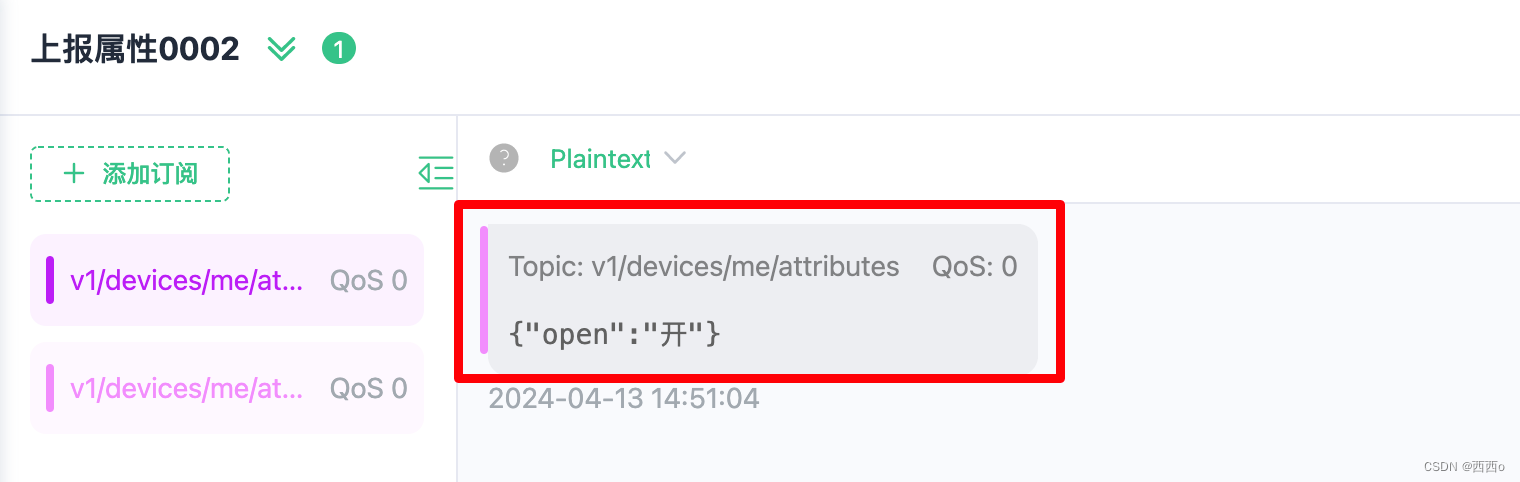
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 摘要
- Abstract
- 文献阅读:3D场景编辑方法——CustomNeRF
- 1、研究背景
- 2、提出方法
- 3、CustomNeRF
- 3.1、整体框架步骤
- 3.2、对特定问题的解决
- 4、实验结果
- 5、总结
- 简单Transformer的实现
- 总结
摘要
本周主要阅读了CVPR文章,Customize your NeRF: Adaptive Source Driven 3D Scene Editing via Local-Global lterative Training。一种将文本描述和参考图像统一为编辑提示的CustomNeRF框架,可以通过微调预训练的扩散模型将参考图像中包含的特定视觉主体V∗嵌入到混合提示中,从而满足一般化和定制化的3D场景编辑要求。除此之外,还学习了简单的Transformer代码的学习。
Abstract
This week, I mainly read the CVPR article, “Customize your NeRF: Adaptive Source Driven 3D Scene Editing via Local-Global Iterative Training.” It introduces a CustomNeRF framework that unifies text descriptions and reference images into editing cues. By fine-tuning a pre-trained diffusion model, the framework can embed specific visual subjects V∗ contained in the reference image into the mixed cues, thus satisfying the requirements of generalized and customized 3D scene editing. Additionally, I also studied the basics of Transformer code.
文献阅读:3D场景编辑方法——CustomNeRF
Title: Customize your NeRF: Adaptive Source Driven 3D Scene Editing via Local-Global lterative Training
Author:Runze He, Shaofei Huang, Xuecheng Nie, Tianrui Hui, Luogi Liu, Jiao Dai, jizhong Han, Guanbin Li, Si Liu
From:2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
1、研究背景
自2020年神经辐射场(Neural Radiance Field, NeRF)提出以来,将隐式表达推上了一个新的高度。作为当前最前沿的技术之一,NeRF快速泛化应用在计算机视觉、计算机图形学、增强现实、虚拟现实等领域,并持续受到广泛关注。有赖于易于优化和连续表示的特点,NeRF在3D场景重建中有着大量应用,也带动了3D场景编辑领域的研究,如3D对象或场景的纹理重绘、风格化等。为了进一步提高3D场景编辑的灵活性,近期基于预训练扩散模型进行3D场景编辑的方法也正在被大量探索,但由于NeRF的隐式表征以及3D场景的几何特性,获得符合文本提示的编辑结果并非易事。
2、提出方法
为了让文本驱动的3D场景编辑也能够实现精准控制,论文提出了一种将文本描述和参考图像统一为编辑提示的CustomNeRF框架,可以通过微调预训练的扩散模型将参考图像中包含的特定视觉主体V∗嵌入到混合提示中,从而满足一般化和定制化的3D场景编辑要求。为了实现仅对图像前景区域进行准确编辑,该论文提出了一种局部-全局迭代编辑(LGIE)的训练方案,在图像前景区域编辑和全图像编辑之间交替进行。该方案能够准确定位图像前景区域,并在保留图像背景的同时仅对图像前景进行操作。此外,在由图像驱动的3D场景编辑中,存在因微调的扩散模型过拟合到参考图像视角,所造成的编辑结果几何不一致问题。对此,该论文设计了一种类引导的正则化,在局部编辑阶段仅使用类词来表示参考图像的主体,并利用预训练扩散模型中的一般类先验来促进几何一致的编辑。
3、CustomNeRF
3.1、整体框架步骤
- 首先,在重建原始的3D场景时,CustomNeRF引入了额外的mask field来估计除常规颜色和密度之外的编辑概率。如下图(a) 所示,对于一组需要重建3D场景的图像,该论文先使用 Grouded SAM 从自然语言描述中提取图像编辑区域的掩码,结合原始图像集训练 foreground-aware NeRF。在NeRF重建后,编辑概率用于区分要编辑的图像区域(即图像前景区域)和不相关的图像区域(即图像背景区域),以便于在图像编辑训练过程中进行解耦合的渲染。
- 其次,为了统一图像驱动和文本驱动的3D场景编辑任务,如下图(b)所示,该论文采用了Custom Diffusion 的方法在图像驱动条件下针对参考图进行微调,以学习特定主体的关键特征。经过训练后,特殊词 V∗ 可以作为常规的单词标记用于表达参考图像中的主体概念,从而形成一个混合提示,例如 “a photo of a V∗ dog”。通过这种方式,CustomNeRF能够对自适应类型的数据(包括图像或文本)进行一致且有效的编辑。
- 在最终的编辑阶段,由于NeRF的隐式表达,如果使用SDS损失对整个3D区域进行优化会导致背景区域发生显著变化,而这些区域在编辑后理应与原始场景保持一致。如下图(c)所示,该论文提出了局部-全局迭代编辑(LGIE)方案进行解耦合的SDS训练,使其能够在编辑布局区域的同时保留背景内容。

3.2、对特定问题的解决
- 实现仅对图像前景区域进行准确编辑:
提出了一种局部-全局迭代编辑(LGIE)的训练方案,在图像前景区域编辑和全图像编辑之间交替进行。该方案能够准确定位图像前景区域,并在保留图像背景的同时仅对图像前景进行操作。 - 编辑结果几何不一致问题:
设计了一种类引导的正则化,在局部编辑阶段仅使用类词来表示参考图像的主体,并利用预训练扩散模型中的一般类先验来促进几何一致的编辑。
4、实验结果
下图展示了CustomNeRF与基线方法的3D场景重建结果对比,在参考图像和文本驱动的3D场景编辑任务中,CustomNeRF均取得了不错的编辑结果,不仅与编辑提示达成了良好的对齐,且背景区域和原场景保持一致。

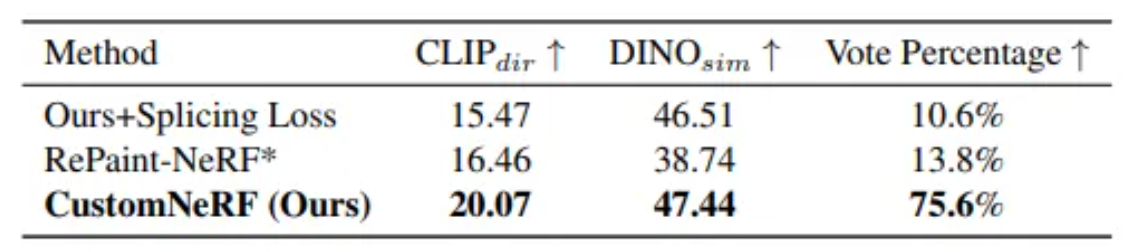
下图展示了CustomNeRF在图像、文本驱动下与基线方法的量化比较,结果显示在文本对齐指标、图像对齐指标和人类评估中,CustomNeRF均超越了基线方法。
5、总结
本论文创新性地提出了CustomNeRF模型,同时支持文本描述或参考图像的编辑提示,并解决了两个关键性挑战——精确的仅前景编辑以及在使用单视图参考图像时多个视图的一致性。该方案包括局部-全局迭代编辑(LGIE)训练方案,使得编辑操作能够在专注于前景的同时保持背景不变;以及类引导正则化,减轻图像驱动编辑中的视图不一致,通过大量实验,也验证了CustomNeRF在各种真实场景中,能够准确编辑由文本描述和参考图像提示的3D场景。
简单Transformer的实现
# 定义多头注意力机制模块
class MultiHeadAttention(nn.Module): def __init__(self, d_model, num_heads): super(MultiHeadAttention, self).__init__() # 调用父类(nn.Module)的构造函数 self.num_heads = num_heads # 设置多头注意力的头数 self.d_model = d_model # 输入特征的维度 # 确保d_model可以被num_heads整除 assert d_model % self.num_heads == 0 # 计算每个头的维度 self.depth = d_model // self.num_heads # 定义线性变换层,用于计算查询、键和值的表示 self.wq = nn.Linear(d_model, d_model) self.wk = nn.Linear(d_model, d_model) self.wv = nn.Linear(d_model, d_model) # 定义线性变换层,用于最后的输出变换 self.dense = nn.Linear(d_model, d_model) # 将输入张量分割成多个头 def split_heads(self, x, batch_size): # 重塑张量以准备分割 x = x.reshape(batch_size, -1, self.num_heads, self.depth) # 置换张量的维度,以便后续的矩阵乘法 return x.permute(0, 2, 1, 3) # 前向传播函数 def forward(self, v, k, q, mask): batch_size = q.shape[0] # 获取批次大小 # 通过线性变换层计算查询、键和值的表示 q = self.wq(q) # 查询(batch_size, seq_len, d_model) k = self.wk(k) # 键(batch_size, seq_len, d_model) v = self.wv(v) # 值(batch_size, seq_len, d_model) # 将查询、键和值分割成多个头 q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth) k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth) v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth) # 计算缩放点积注意力 scaled_attention, attention_weights = self.scaled_dot_product_attention(q, k, v, mask) # 将注意力输出的维度重新排列并合并回原始维度 scaled_attention = scaled_attention.permute(0, 2, 1, 3).contiguous() new_context_layer_shape = scaled_attention.shape[:-2] + (self.d_model,) scaled_attention = scaled_attention.reshape(new_context_layer_shape) # 通过线性变换层得到最终的输出 output = self.dense(scaled_attention) return output, attention_weights # 计算缩放点积注意力 def scaled_dot_product_attention(self, q, k, v, mask): # 计算查询和键的点积 matmul_qk = torch.matmul(q, k.transpose(-2, -1)) # (batch_size, num_heads, seq_len_q, seq_len_k) dk = torch.tensor(self.depth, dtype=torch.float32).to(q.device) # 获取每个头的维度 # 缩放点积注意力分数 scaled_attention_logits = matmul_qk / dk # 如果提供了掩码,则将其应用于注意力分数 if mask is not None: scaled_attention_logits += (mask * -1e9) # 将掩码位置的值设置为一个非常小的负数 # 应用softmax函数得到注意力权重 attention_weights = F.softmax(scaled_attention_logits, dim=-1) # (batch_size, num_heads
总结
本周主要阅读了CVPR文章,Customize your NeRF: Adaptive Source Driven 3D Scene Editing via Local-Global lterative Training。一种将文本描述和参考图像统一为编辑提示的CustomNeRF框架,可以通过微调预训练的扩散模型将参考图像中包含的特定视觉主体V∗嵌入到混合提示中,从而满足一般化和定制化的3D场景编辑要求。除此之外,还学习了简单的Transformer代码的学习。下一周继续学习