目录
一、ZooKeeper基本介绍
1.ZooKeeper的简介
2.ZooKeeper的工作机制
3.ZooKeeper的特点
4.ZooKeeper的数据结构
5.ZooKeeper的应用场景
5.1 统一命名服务
5.2 统一配置管理
5.3 统一集群管理
5.4 服务器动态上下线
5.5 软负载均衡
二.ZooKeeper的选举机制
1.第一次启动选举机制
2.非第一次启动选举机制
3.选举Leader规则
三、部署ZooKeeper集群
1.环境准备
1.1 关闭防火墙
1.2 安装JDK
1.3 下载安装包
2.修改配置文件(所有节点)
3.创建数据目录和日志目录(所有节点)
4.在 dataDir 指定目录下创建一个 myid 的文件(所有节点)
5.配置 Zookeeper 启动脚本(所有节点)
6.启动、设置开机自启、查看服务状态
一、ZooKeeper基本介绍
1.ZooKeeper的简介
- Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。
- 是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
- ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
- ZooKeeper包含一个简单的原语集,提供Java和C的接口。
- ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在$zookeeper_home\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
2.ZooKeeper的工作机制
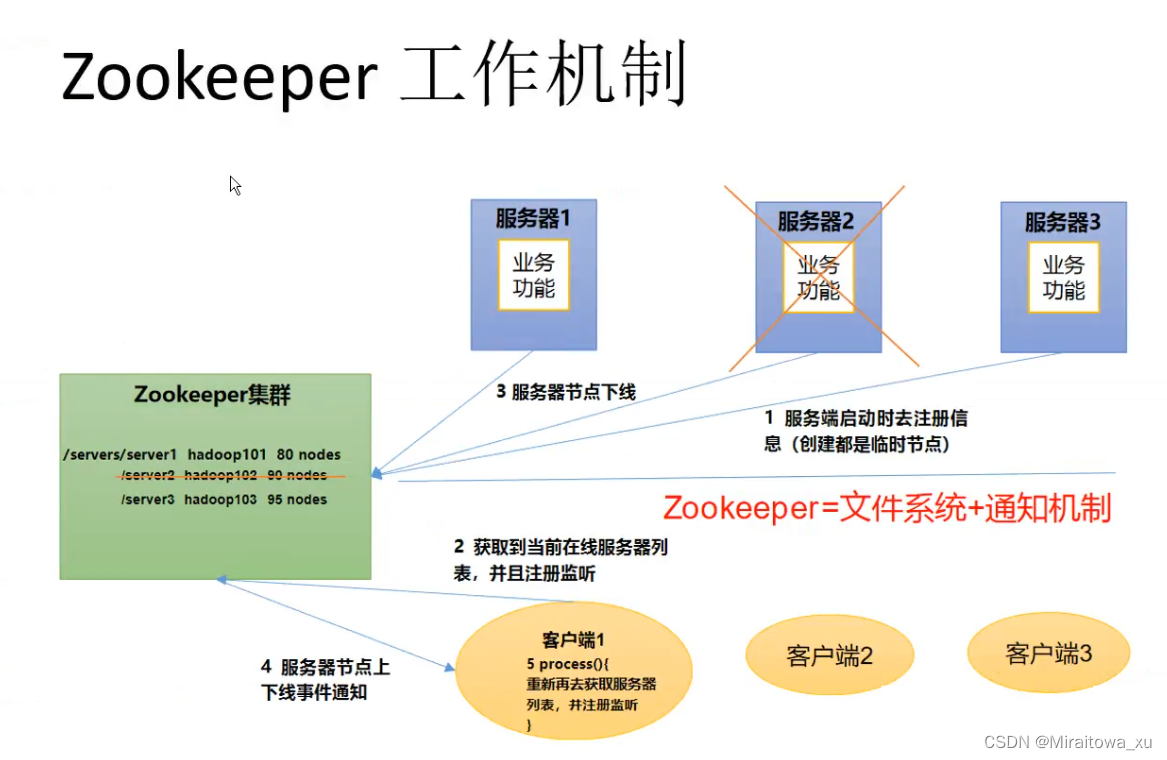
ZooKeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,ZooKeeper就将负责通知已经在ZooKeeper上注册的那些观察者做出相应的反应。
3.ZooKeeper的特点

- Zookeeper:一个领导者(Leader) ,多个跟随者(Follower) 组成的集群。
- Zookeepe集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
- 全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server, 数据都是一致的。
- 更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行,即先进先出。.
- 数据更新原子性,一次数据更新要么成功,要么失败。
- 实时性,在一定时间范围内,Client能读到最新数据。
4.ZooKeeper的数据结构
 ZooKeeper数据模型的结构与Linux文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每一个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
ZooKeeper数据模型的结构与Linux文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每一个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
5.ZooKeeper的应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
5.1 统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如:IP不容易记住,而域名容易记住。
5.2 统一配置管理
(1)分布式环境下,配置文件同步非常常见。一般要求一个集群中,所有节点的配置信息是一致的,比如Kafka集群。对配置文件修改后,希望能够快速同步到各个节点上。
(2)配置管理可交由ZooKeeper实现。可将配置信息写入ZooKeeper上的一个Znode。各个客户端服务器监听这个Znode。一旦 Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。
5.3 统一集群管理
(1)分布式环境中,实时掌握每个节点的状态是必要的。可根据节点实时状态做出一些调整。
(2)ZooKeeper可以实现实时监控节点状态变化。可将节点信息写入ZooKeeper上的一个ZNode。监听这个ZNode可获取它的实时状态变化。
5.4 服务器动态上下线
客户端能实时洞察到服务器上下线的变化。
5.5 软负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求。
二.ZooKeeper的选举机制
1.第一次启动选举机制
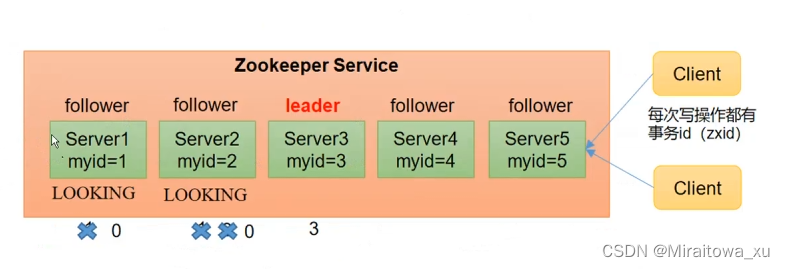
- 服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
- 服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
- 服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
- 服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
- 服务器5启动,同4一样当小弟。
2.非第一次启动选举机制

- 当ZooKeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举
- 服务器初始化启动。
- 服务器运行期间无法和Leader保持连接。
- 而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态
-
集群中本来就已经存在一个Leader。
对于已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并进行状态同步即可。 -
集群中确实不存在Leader
假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。
SID:服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。
ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑速度有关。
Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加
3.选举Leader规则
- EPOCH大的直接胜出。
- EPOCH相同,事务id大的胜出。
- 事务id相同,服务器id大的胜出。
三、部署ZooKeeper集群
1.环境准备
| 服务器 | IP地址 |
| Zookeeper服务器1 | 192.168.21.10 |
| Zookeeper服务器2 | 192.168.21.30 |
| Zookeeper服务器3 | 192.168.21.40 |
1.1 关闭防火墙
systemctl stop firewalld
setenforce 0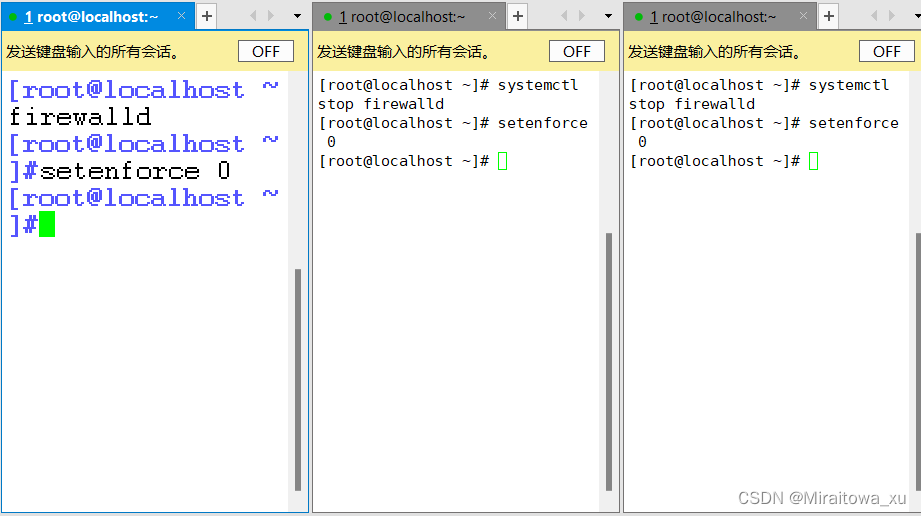
1.2 安装JDK
#非最小化安装一般自带
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
java -version
1.3 下载安装包
cd /opt/
rz -E
tar zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7##########或者在官方下载安装包##############
cd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
2.修改配置文件(所有节点)
cd /usr/local/zookeeper-3.5.7/conf/
cp zoo_sample.cfg zoo.cfgvim zoo.cfg
-----------------------------------------------------------------------------
tickTime=2000 #通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10 #Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5 #Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data ●修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs ●添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连接端口
#添加集群信息
server.1=192.168.21.10:3188:3288
server.2=192.168.21.30:3188:3288
server.3=192.168.21.40:3188:3288
#集群节点通信时使用端口3188,选举leader时使用的端口3288
-------------------------------------------------------------------------------------
server.A=B:C:D
●A是一个数字,表示这个是第几号服务器。集群模式下需要在zoo.cfg中dataDir指定的目录下创建一个文件myid,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
●B是这个服务器的地址。
●C是这个服务器Follower与集群中的Leader服务器交换信息的端口。●D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。

3.创建数据目录和日志目录(所有节点)
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/local/zookeeper-3.5.7/logs
4.在 dataDir 指定目录下创建一个 myid 的文件(所有节点)
echo 1 > /usr/local/zookeeper-3.5.7/data/myid #zookeeper服务器1上添加
echo 2 > /usr/local/zookeeper-3.5.7/data/myid #zookeeper服务器2上添加
echo 3 > /usr/local/zookeeper-3.5.7/data/myid #zookeeper服务器3上添加
5.配置 Zookeeper 启动脚本(所有节点)
vim /etc/init.d/zookeeper
--------------------------------------------------
#!/bin/bash
#chkconfig:2345 20 90
#description: Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)
echo "-----zookeeper启动-----"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "----zookeeper停止-------"
$ZK_HOME/bin/ zkServer.sh stop
;;
restart)
echo "----zookeeper重启-------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "-----zookeeper状态------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac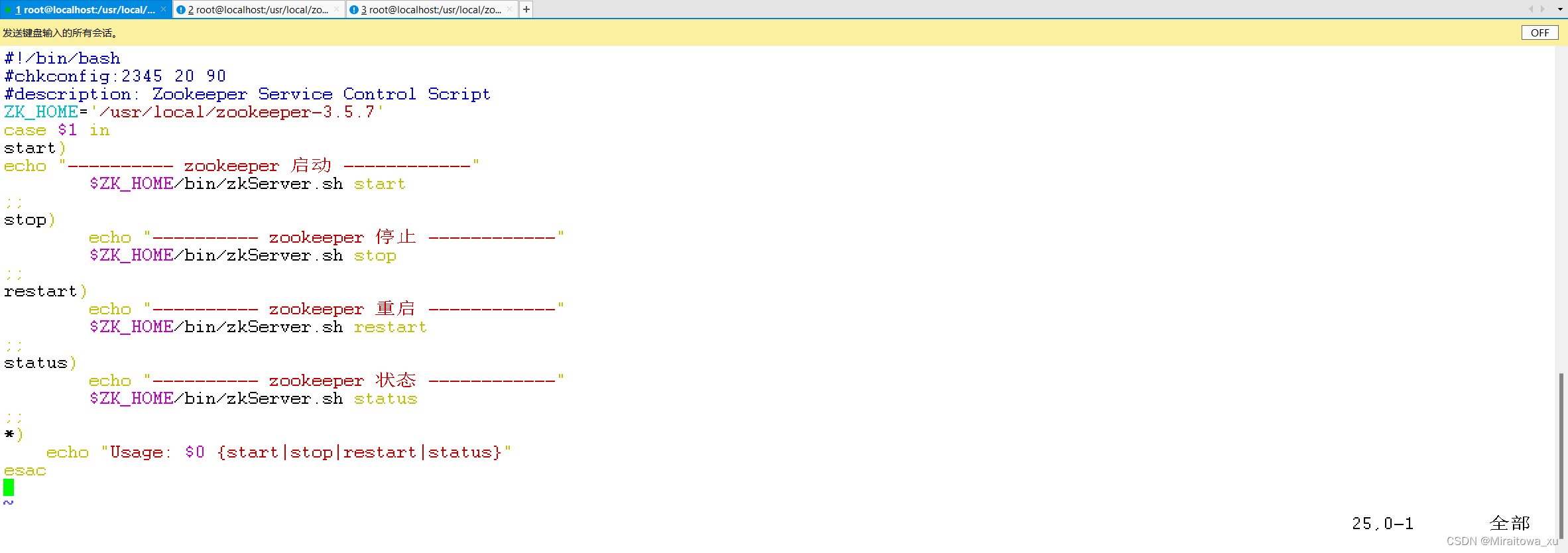
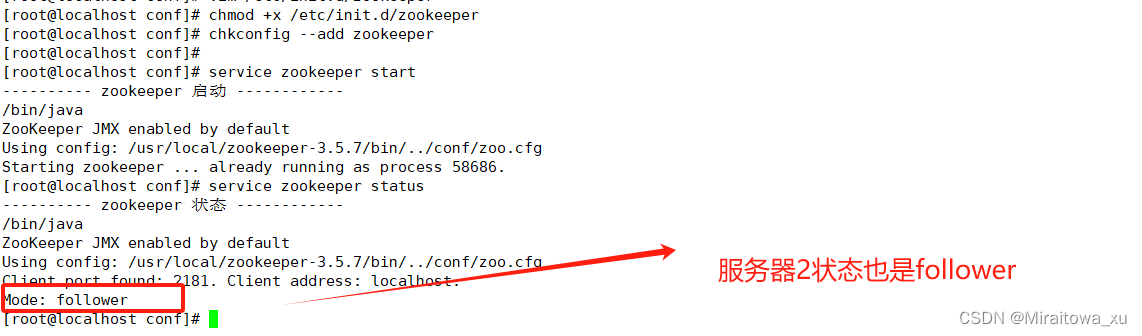
6.启动、设置开机自启、查看服务状态
#设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper#分别启动 Zookeeper
service zookeeper start#查看当前状态
service zookeeper status
![[大模型]Yi-6B-Chat FastApi 部署调用](https://img-blog.csdnimg.cn/direct/5c79717db8944bf397fe34e753afe963.png#pic_center)