目录
一、说明
二、为什么需要时间序列模型?
三、下载数据
3.1 从 Alphavantage 获取数据
3.1 从 Kaggle 获取数据
3.3 数据探索
3.4 数据可视化
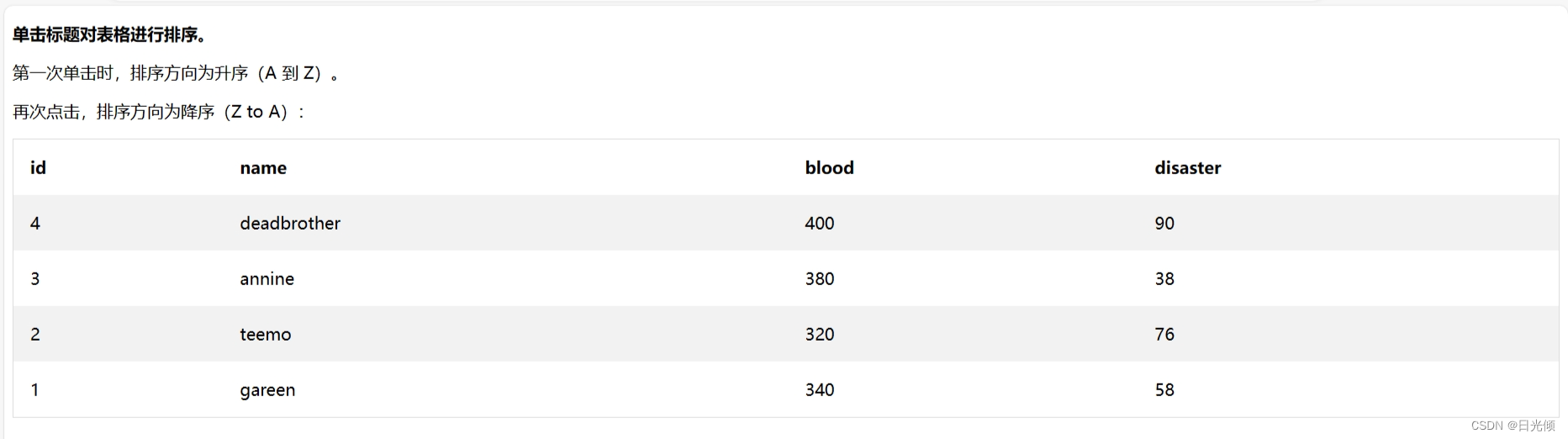
四、将数据拆分为训练集和测试集
五、数据标准化
六、通过平均进行一步预测
6.1 标准平均值
6.2 指数移动平均线
6.3 如果指数移动平均线这么好,为什么还需要更好的模型?
6.4 预测未来不止一步
七、LSTM 简介:预测未来的股票走势
7.1 数据生成器
7.2 数据增强
7.3 定义超参数
7.4 定义输入和输出
7.5 定义 LSTM 和回归层的参数
7.6 计算 LSTM 输出并将其馈送到回归层以获得最终预测
7.7 损失计算和优化器
7.9 运行 LSTM
八、可视化预测
九、最后的评论
参考
一、说明
- 了解为什么您需要能够预测股价走势;
- 下载数据 - 您将使用从雅虎财经收集的股票市场数据;
- 分割训练测试数据并执行一些数据标准化;
- 回顾并应用一些可用于一步预测的平均技术;
- 激发并简要讨论LSTM 模型,因为它可以提前预测不止一步;
- 利用当前数据预测和可视化未来股市
如果您不熟悉深度学习或神经网络,您应该看看我们的Python 深度学习课程。它涵盖了基础知识,以及如何在 Keras 中自行构建神经网络。这是与本教程中将使用的 TensorFlow 不同的包,但其思想是相同的。
二、为什么需要时间序列模型?
您希望正确地对股票价格进行建模,以便作为股票购买者,您可以合理地决定何时购买股票以及何时出售股票以赚取利润。这就是时间序列建模的用武之地。您需要良好的机器学习模型,该模型可以查看数据序列的历史记录并正确预测序列的未来元素。
警告:股票市场价格高度不可预测且不稳定。这意味着数据中不存在一致的模式,无法让您近乎完美地对一段时间内的股票价格进行建模。不要从我这里听,而是从普林斯顿大学经济学家伯顿·马尔基尔那里听,他在 1973 年的著作《华尔街随机漫步》中指出,如果市场真正有效并且股价立即反映了所有因素当它们被公开时,一只蒙着眼睛的猴子向报纸上的股票投掷飞镖应该和任何投资专业人士一样。
然而,我们不要完全相信这只是一个随机或随意的过程,并且机器学习没有希望。让我们看看您是否至少可以对数据进行建模,以便您所做的预测与数据的实际行为相关联。换句话说,您不需要未来的确切股票价值,而是股票价格走势(即,在不久的将来是否会上涨或下跌)。
# Make sure that you have all these libaries available to run the code successfully
from pandas_datareader import data
import matplotlib.pyplot as plt
import pandas as pd
import datetime as dt
import urllib.request, json
import os
import numpy as np
import tensorflow as tf # This code has been tested with TensorFlow 1.6
from sklearn.preprocessing import MinMaxScaler三、下载数据
您将使用以下来源的数据:
-
Alpha Vantage 库存 API。不过,在开始之前,您首先需要一个 API 密钥,您可以在此处免费获取该密钥。之后,您可以将该键分配给
api_key变量。在本教程中,我们将检索美国航空股票 20 年的历史数据。作为可选读物,您可以参考此股票 API 入门指南,了解使用历史市场数据的最佳实践。 -
使用此页面中的数据。您需要将zip 文件中的Stocks文件夹复制到项目主文件夹中。
股票价格有几种不同的表现。他们是,
- 开盘价:当日股票开盘价
- 收盘价:当日收盘价
- High:数据中最高的股价
- 最低价:当日最低股价
3.1 从 Alphavantage 获取数据
您将首先从 Alpha Vantage 加载数据。由于您将利用美国航空股票市场价格进行预测,因此您将股票代码设置为"AAL"。此外,您还定义了一个url_string,它将返回一个 JSON 文件,其中包含过去 20 年内美国航空的所有股票市场数据,以及一个file_to_save,它将是您保存数据的文件。您将使用ticker之前定义的变量来帮助命名该文件。
接下来,您将指定一个条件:如果您尚未保存数据,您将继续从您在 中设置的 URL 中获取数据url_string;您将把日期、最低价、最高价、交易量、收盘价、开盘价存储到 pandas DataFrame 中df,并将其保存到file_to_save.但是,如果数据已经存在,您只需从 CSV 加载即可。
3.1 从 Kaggle 获取数据
Kaggle 上找到的数据是 csv 文件的集合,您无需进行任何预处理,因此可以直接将数据加载到 Pandas DataFrame 中。
data_source = 'kaggle' # alphavantage or kaggle
if data_source == 'alphavantage':# ====================== Loading Data from Alpha Vantage ==================================api_key = '<your API key>'# American Airlines stock market pricesticker = "AAL"# JSON file with all the stock market data for AAL from the last 20 yearsurl_string = "https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol=%s&outputsize=full&apikey=%s"%(ticker,api_key)# Save data to this filefile_to_save = 'stock_market_data-%s.csv'%ticker# If you haven't already saved data,# Go ahead and grab the data from the url# And store date, low, high, volume, close, open values to a Pandas DataFrameif not os.path.exists(file_to_save):with urllib.request.urlopen(url_string) as url:data = json.loads(url.read().decode())# extract stock market datadata = data['Time Series (Daily)']df = pd.DataFrame(columns=['Date','Low','High','Close','Open'])for k,v in data.items():date = dt.datetime.strptime(k, '%Y-%m-%d')data_row = [date.date(),float(v['3. low']),float(v['2. high']),float(v['4. close']),float(v['1. open'])]df.loc[-1,:] = data_rowdf.index = df.index + 1print('Data saved to : %s'%file_to_save) df.to_csv(file_to_save)# If the data is already there, just load it from the CSVelse:print('File already exists. Loading data from CSV')df = pd.read_csv(file_to_save)else:# ====================== Loading Data from Kaggle ==================================# You will be using HP's data. Feel free to experiment with other data.# But while doing so, be careful to have a large enough dataset and also pay attention to the data normalizationdf = pd.read_csv(os.path.join('Stocks','hpq.us.txt'),delimiter=',',usecols=['Date','Open','High','Low','Close'])print('Loaded data from the Kaggle repository')
Data saved to : stock_market_data-AAL.csv
此代码根据data_source变量的值从 Alpha Vantage 或 Kaggle 加载股票市场数据。
• 如果data_source设置为'alphavantage',则代码首先将api_key 变量设置为 Alpha Vantage 的用户 API 密钥。
• 然后将股票代码变量设置为美国航空公司的股票代码。
• url_string变量设置为从Alpha Vantage 的API 检索指定股票的每日时间序列数据的URL。
• file_to_save变量设置为数据将保存到的CSV 文件的名称。
• 如果CSV 文件尚不存在,代码将使用urllib库打开URL 并以JSON 对象形式检索数据。
• 然后提取相关数据(日期、最低价、最高价、成交量、收盘价和开盘价)并将其存储在 Pandas DataFrame 中。
• 然后,DataFrame 将保存到file_to_save指定的CSV 文件中。
• 如果CSV 文件已存在,则代码只需将文件中的数据加载到Pandas DataFrame 中。
• 如果data_source设置为'alphavantage'以外的任何值,则代码假定数据是从 Kaggle 加载的。
• 它使用Pandas 的read_csv函数从包含HP 股票市场数据的CSV 文件加载数据。
• usecols参数用于指定从CSV 文件加载哪些列。
• 最后,代码打印一条消息,指示数据是从Alpha Vantage 还是Kaggle 加载的。3.3 数据探索
在这里,您将把收集到的数据打印到 DataFrame 中。您还应该确保数据按日期排序,因为数据的顺序在时间序列建模中至关重要。
# Sort DataFrame by date
df = df.sort_values('Date')# Double check the result
df.head()
此代码使用sort_values()方法按“日期”列中的值对DataFrame df进行排序。
• 然后将排序后的DataFrame 分配回变量df。
•然后使用head()方法显示排序后的 DataFrame 的前几行,以仔细检查结果。
• 总体而言,此代码确保DataFrame 按日期升序排序,这对于时间序列分析或数据顺序很重要的其他应用程序非常有用。| 日期 | 打开 | 高的 | 低的 | 关闭 | |
|---|---|---|---|---|---|
| 0 | 1970年1月2日 | 0.30627 | 0.30627 | 0.30627 | 0.30627 |
| 1 | 1970-01-05 | 0.30627 | 0.31768 | 0.30627 | 0.31385 |
| 2 | 1970-01-06 | 0.31385 | 0.31385 | 0.30996 | 0.30996 |
| 3 | 1970-01-07 | 0.31385 | 0.31385 | 0.31385 | 0.31385 |
| 4 | 1970年1月8日 | 0.31385 | 0.31768 | 0.31385 | 0.31385 |
3.4 数据可视化
现在让我们看看您拥有什么类型的数据。您希望数据随着时间的推移而出现各种模式。
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),(df['Low']+df['High'])/2.0)
plt.xticks(range(0,df.shape[0],500),df['Date'].loc[::500],rotation=45)
plt.xlabel('Date',fontsize=18)
plt.ylabel('Mid Price',fontsize=18)
plt.show()
此代码创建股票中间价格随时间变化的线图。
• plt.figure(figsize = (18,9)) 将图窗的大小设置为18 英寸宽和9 英寸高。
• plt.plot(range(df.shape[0]),(df['Low']+df['High'])/2.0) 创建线图。
• x 轴是数据帧df 中的行数范围,y 轴是df 中“低”和“高”列的平均值。
• plt.xticks(range(0,df.shape[0],500),df['Date'].loc[::500],rotation=45) 将 x 轴刻度线设置为每 500 行df,刻度标签将成为 df' 中按这些时间间隔的“日期”列。
•rotation=45 参数将刻度标签旋转 45 度以获得更好的可读性。
• plt.xlabel('Date',fontsize=18) 将 x 轴标签设置为“Date”,字体大小为 18。
• plt.ylabel('Mid Price',fontsize=18) 将 y 轴标签设置为“Mid Price”,字体大小为 18。
• plt.show()` 显示绘图。
这张图已经说明了很多事情。我选择这家公司而不是其他公司的具体原因是,随着时间的推移,这张图表充满了股票价格的不同行为。这将使学习更加稳健,并为您提供一个改变来测试各种情况下的预测效果如何。
另一件值得注意的事情是,接近 2017 年的值比接近 1970 年代的值要高得多,波动也更大。因此,您需要确保数据在整个时间范围内表现在相似的值范围内。您将在数据标准化阶段处理这个问题。
四、将数据拆分为训练集和测试集
您将使用通过一天的最高记录价格和最低记录价格的平均值计算出的中间价格。
# First calculate the mid prices from the highest and lowest
high_prices = df.loc[:,'High'].as_matrix()
low_prices = df.loc[:,'Low'].as_matrix()
mid_prices = (high_prices+low_prices)/2.0
此代码根据金融资产的最高价格和最低价格计算中间价格。
• 首先,它使用loc 方法从名为“df”的pandas DataFrame 中提取“High”和“Low”列。
• 逗号之前的: 表示我们要选择所有行,逗号之后的“High”和“Low”表示我们只想选择这两列。
• 然后,使用as_matrix() 方法将选定的列转换为NumPy 数组。
• 最后,通过将最高价和最低价相加并将结果除以2.0 计算出中间价。
• 生成的中间价格存储在名为 mid_prices 的新 NumPy 数组中。现在您可以拆分训练数据和测试数据。训练数据将是时间序列的前 11,000 个数据点,其余数据将是测试数据。
train_data = mid_prices[:11000]
test_data = mid_prices[11000:]This code is written in Python.
• The code creates two new variables, train_data and test_data, by slicing the mid_prices list.
• The train_data variable is assigned the first 11000 elements of the mid_prices list, while the test_data variable is assigned the remaining elements starting from the 11000th index.
• This is a common technique used in machine learning to split a dataset into a training set and a testing set.
• The training set is used to train a model, while the testing set is used to evaluate the performance of the model on unseen data.五、数据标准化
现在您需要定义一个缩放器来标准化数据。MinMaxScalar将所有数据缩放到 0 和 1 的区域内。您还可以将训练和测试数据重塑为形状[data_size, num_features]。
# Scale the data to be between 0 and 1
# When scaling remember! You normalize both test and train data with respect to training data
# Because you are not supposed to have access to test data
scaler = MinMaxScaler()
train_data = train_data.reshape(-1,1)
test_data = test_data.reshape(-1,1)
提示:选择窗口大小时,请确保它不要太小,因为当您执行窗口归一化时,它可能会在每个窗口的最后引入一个中断,因为每个窗口都是独立归一化的。
在此示例中,4 个数据点将受此影响。但考虑到您有 11,000 个数据点,4 个点不会造成任何问题
# Train the Scaler with training data and smooth data
smoothing_window_size = 2500
for di in range(0,10000,smoothing_window_size):scaler.fit(train_data[di:di+smoothing_window_size,:])train_data[di:di+smoothing_window_size,:] = scaler.transform(train_data[di:di+smoothing_window_size,:])# You normalize the last bit of remaining data
scaler.fit(train_data[di+smoothing_window_size:,:])
train_data[di+smoothing_window_size:,:] = scaler.transform(train_data[di+smoothing_window_size:,:])
此代码在数据集上训练缩放器并将其应用于标准化数据。
• 首先,将变量smoothing_window_size 设置为2500。
• 然后,使用for 循环以smoothing_window_size 的增量迭代训练数据。
• 在每次迭代中,在训练数据切片(从di 到di+smoothing_window_size)上调用缩放器对象的fit 方法。
• 这会根据该部分数据训练缩放器。
• 然后,在训练数据的同一切片上调用缩放器的变换方法,该方法使用在拟合步骤中学到的参数对数据进行归一化。
• 然后将标准化数据分配回训练数据的同一切片。
• 循环完成后,训练数据的剩余部分(如果有)将以与循环的最后一次迭代相同的方式标准化。
• 对剩余数据调用fit 方法,然后调用transform 方法对其进行归一化。
• 总体而言,此代码用于使用缩放器对象对训练数据进行标准化,这有助于提高基于数据训练的机器学习模型的性能。 将数据重塑回形状[data_size]
# Reshape both train and test data
train_data = train_data.reshape(-1)# Normalize test data
test_data = scaler.transform(test_data).reshape(-1)
此代码重塑了 train_data 和 test_data 数组。
• 在第一行中,使用reshape() 方法以-1 作为参数对train_data 进行整形。
• reshape() 中的-1 参数表示该维度的大小是根据数组的长度和其余维度推断的。
• 当您想要重塑数组但不知道其中一个维度的确切大小时,通常会使用此方法。
• 在第二行中,test_data 首先使用scaler.transform() 方法进行归一化,该方法将数据缩放至均值和单位方差为零。
• 然后,使用以-1 作为参数的reshape() 重新调整生成的数组,就像第一行中一样。
• 这确保了重塑后test_data 的形状与train_data 的形状相匹配。
• 总体而言,此代码通过重塑train_data 和test_data 数组并规范化测试数据来准备用于机器学习模型的train_data 和test_data 数组。您现在可以使用指数移动平均线来平滑数据。这可以帮助您摆脱股票价格数据固有的不规则性并产生更平滑的曲线。
请注意,您应该只平滑训练数据。
# Now perform exponential moving average smoothing
# So the data will have a smoother curve than the original ragged data
EMA = 0.0
gamma = 0.1
for ti in range(11000):EMA = gamma*train_data[ti] + (1-gamma)*EMAtrain_data[ti] = EMA# Used for visualization and test purposes
all_mid_data = np.concatenate([train_data,test_data],axis=0)
此代码对 train_data 数组执行指数移动平均 (EMA) 平滑。
• EMA 是一种移动平均线,它对最近的数据点给予更大的权重,而对旧的数据点给予更少的权重。
• 代码将EMA 变量初始化为0.0,并将gamma 值设置为0.1。
• 然后,它循环遍历train_data 数组的前11000 个元素,并使用公式EMA = gamma*train_data[ti] + (1-gamma)*EMA 更新EMA 值。
• 此公式计算当前数据点和先前EMA 值的加权平均值,其中gamma 是给予当前数据点的权重,(1-gamma) 是给予先前EMA 值的权重。
• 更新EMA 值后,代码用新的EMA 值替换train_data 数组中的当前数据点。
• 对train_data 数组中的每个数据点重复此过程。
• 最后,代码将train_data 和test_data 数组连接成一个名为all_mid_data 的数组。
• 这样做是为了可视化和测试目的。六、通过平均进行一步预测
平均机制允许您通过将未来股票价格表示为之前观察到的股票价格的平均值来进行预测(通常提前一时间)。多次执行此操作可能会产生非常糟糕的结果。您将了解下面两种平均技术;标准平均线和指数移动平均线。您将对两种算法产生的结果进行定性(目视检查)和定量(均方误差)评估。
均方误差 (MSE) 可以通过向前一步的真实值与预测值之间的平方误差计算,并对所有预测进行平均。
6.1 标准平均值
您可以通过首先尝试将其建模为平均计算问题来理解此问题的难度。首先,您将尝试预测未来的股票市场价格(例如, x t+1)作为固定大小窗口内先前观察到的股票市场价格的平均值(例如, x t-N , ..., x t)(比如说前 100 天)。此后,您将尝试更奇特的“指数移动平均线”方法,看看效果如何。然后你将继续迈向时间序列预测的“圣杯”;长短期记忆模型。
首先,您将了解正常平均是如何工作的。就是你说的,

换句话说,您说 $t+1$ 的预测是您在 $t$ 到 $tN$ 窗口内观察到的所有股票价格的平均值。
window_size = 100
N = train_data.size
std_avg_predictions = []
std_avg_x = []
mse_errors = []for pred_idx in range(window_size,N):if pred_idx >= N:date = dt.datetime.strptime(k, '%Y-%m-%d').date() + dt.timedelta(days=1)else:date = df.loc[pred_idx,'Date']std_avg_predictions.append(np.mean(train_data[pred_idx-window_size:pred_idx]))mse_errors.append((std_avg_predictions[-1]-train_data[pred_idx])**2)std_avg_x.append(date)print('MSE error for standard averaging: %.5f'%(0.5*np.mean(mse_errors)))
此代码计算标准平均模型的均方误差 (MSE)。
• 首先,将窗口大小设置为100,并确定训练数据的大小。
• 然后,对于从窗口大小到训练数据大小范围内的每个索引,代码计算前 100 个数据点的平均值,并将其附加到标准平均预测列表中。
• 它还计算该指数的预测值和实际值之间的MSE,并将其附加到MSE 误差列表中。
• 最后,它将与该索引对应的日期附加到日期列表中。
• 最后,代码通过获取MSE 误差的平均值并将其乘以0.5 来打印标准平均模型的MSE 误差。
• 该代码使用datetime 模块将日期从字符串转换为datetime 对象。
• 它还使用numpy 模块进行数学运算。MSE error for standard averaging: 0.00418 看看下面的平均结果。它非常接近股票的实际行为。接下来,您将了解一种更准确的一步预测方法。
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True')
plt.plot(range(window_size,N),std_avg_predictions,color='orange',label='Prediction')
#plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45)
plt.xlabel('Date')
plt.ylabel('Mid Price')
plt.legend(fontsize=18)
plt.show()
此代码使用 Python 中的 matplotlib 库创建一个绘图。
• plt.figure(figsize = (18,9)) 行将图形的大小设置为 18 英寸宽和 9 英寸高。
• plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True') 线在图表上绘制数据的真实中间价格。
• range(df.shape[0]) 创建从0 到df 数据帧中的行数的数字范围。
• all_mid_data 变量包含数据的中间价格。
• color='b' 将线条的颜色设置为蓝色,label='True' 将线条的标签设置为“True”。
• plt.plot(range(window_size,N),std_avg_predictions,color='orange',label='Prediction') 线在图表上绘制预测中间价格。
• range(window_size,N) 创建从window_size 变量到N 的数字范围。
• std_avg_predictions 变量包含预测的中间价格。
• color='orange' 将线的颜色设置为橙色,label='Prediction' 将线的标签设置为“Prediction”。
• plt.xlabel('Date') 行将x 轴的标签设置为“Date”,plt.ylabel('Mid Price') 行将y 轴的标签设置为“Mid Price”。
• plt.legend(fontsize=18) 行向绘图添加字体大小为 18 的图例。
• 最后,plt.show() 行显示绘图。
那么上面的图表(和 MSE)说明了什么?
对于非常短的预测(提前一天)来说,这个模型似乎还不错。鉴于股价不会在一夜之间从 0 变为 100,这种行为是明智的。接下来,您将了解一种更高级的平均技术,称为指数移动平均线。
6.2 指数移动平均线
您可能在互联网上看到过一些文章使用非常复杂的模型并预测了股票市场几乎准确的行为。但要小心!这些只是视错觉,并不是因为学习了有用的东西。您将在下面看到如何使用简单的平均方法来复制该行为。
在指数移动平均法中,您可以将 计算为:
其中
且
是指数移动随着时间的推移您保持的平均值。
上面的等式基本上计算了时间步长的指数移动平均值,并将其用作一步预测。
决定最近预测对 EMA 的贡献。例如,
仅将当前值的 10% 输入 EMA。因为您只取最近值的一小部分,所以它可以保留您在平均值中很早看到的更旧的值。看看下面这个用于预测领先一步的效果有多好。
window_size = 100
N = train_data.sizerun_avg_predictions = []
run_avg_x = []mse_errors = []running_mean = 0.0
run_avg_predictions.append(running_mean)decay = 0.5for pred_idx in range(1,N):running_mean = running_mean*decay + (1.0-decay)*train_data[pred_idx-1]run_avg_predictions.append(running_mean)mse_errors.append((run_avg_predictions[-1]-train_data[pred_idx])**2)run_avg_x.append(date)print('MSE error for EMA averaging: %.5f'%(0.5*np.mean(mse_errors)))
此代码计算指数移动平均线 (EMA) 预测的均方误差 (MSE)。
• 首先,代码将窗口大小设置为100 并获取训练数据的大小。
• 然后,它初始化运行平均值预测、运行平均值和MSE 误差的空列表。
• 接下来,代码将初始运行平均值设置为0.0,并将其附加到运行平均值预测列表中。
• 它还将衰减率设置为0.5。
• 然后,代码循环遍历1 到N(训练数据的大小)范围内的每个预测索引。
• 对于每个预测指数,它使用先前的预测和衰减率计算运行平均值。
• 它将运行平均值附加到运行平均值预测列表中,并计算运行平均值预测与实际值之间的MSE 误差。
• 它还将日期附加到运行平均值列表中。
• 最后,代码通过获取MSE 误差的平均值并将其乘以0.5 来打印EMA 平均的MSE 误差。MSE error for EMA averaging: 0.00003 此代码片段只是显示指数移动平均 (EMA) 平均的均方误差 (MSE) 值。
• MSE 误差值为0.00003。
• 此代码片段中没有提及特定的编程语言。
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True')
plt.plot(range(0,N),run_avg_predictions,color='orange', label='Prediction')
#plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45)
plt.xlabel('Date')
plt.ylabel('Mid Price')
plt.legend(fontsize=18)
plt.show()
此代码使用 Python 中的 matplotlib 库创建一个绘图。
• 第一行将图形尺寸设置为18 英寸宽和9 英寸高。
• 第二行使用plot() 函数将真实中间价格数据绘制为蓝线。
• range() 函数用于创建从0 到df 数据帧中的行数的数字列表。
• 颜色参数将线条的颜色设置为蓝色,标签参数将线条的标签设置为“True”。
• 第三行使用plot() 函数将预测的中间价格数据绘制为橙色线。
• 再次使用range()函数,但这次它只上升到N的值。
• 颜色参数将线条的颜色设置为橙色,标签参数将线条的标签设置为“预测”。
• 第四行被注释掉,但它会在 df 数据帧的每 50 行处添加 x 轴刻度线,刻度标签是 df 数据帧的“日期”列中的日期。
• 旋转参数将刻度标签的角度设置为45 度。
• 第五行将x 轴标签设置为“Date”。
• 第六行将y 轴标签设置为“Mid Price”。
• 第七行向绘图添加一个字体大小为 18 的图例。
• 第八行显示绘图。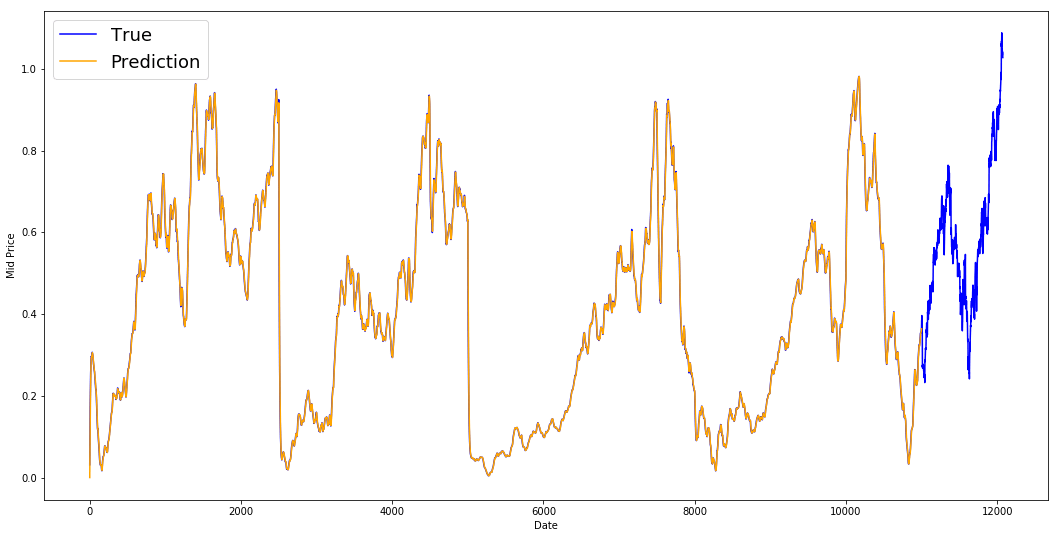
6.3 如果指数移动平均线这么好,为什么还需要更好的模型?
您会看到它符合一条遵循True分布的完美线(并且由非常低的 MSE 证明是合理的)。实际上,仅凭第二天的股市价值并不能做太多事情。就我个人而言,我想要的不是第二天确切的股市价格,而是未来 30 天内股市价格会上涨还是下跌。尝试这样做,你就会暴露 EMA 方法的无能。
您现在将尝试在窗口中进行预测(假设您预测接下来 2 天的窗口,而不是仅仅预测第二天)。然后你就会意识到 EMA 可能会出错。这是一个例子:
6.4 预测未来不止一步
为了使事情具体化,我们假设一些值,例如 $x_t=0.4$、$EMA=0.5$ 和 $\gamma = 0.5$
- 假设您通过以下等式获得输出
- 所以你有
- 所以
- 所以下一个预测
变为,
- 或者在本例中,
因此,无论您预测未来的步骤有多少,对于所有未来的预测步骤,您都会得到相同的答案。
可以输出有用信息的一种解决方案是查看基于动量的算法。他们根据过去的近期值是上升还是下降(不是确切的值)进行预测。例如,他们会说,如果过去几天价格一直在下跌,那么第二天的价格可能会更低,这听起来很合理。但是,您将使用更复杂的模型:LSTM 模型。
这些模型在时间序列预测领域掀起了风暴,因为它们非常擅长对时间序列数据进行建模。您将看到数据中是否确实隐藏着可供利用的模式。
七、LSTM 简介:预测未来的股票走势
长短期记忆模型是极其强大的时间序列模型。他们可以预测未来的任意数量的步骤。 LSTM 模块(或单元)具有 5 个基本组件,使其能够对长期和短期数据进行建模。
- 细胞状态 (ct ) - 这表示细胞的内部存储器,存储短期记忆和长期记忆
- 隐藏状态 (ht ) - 这是根据当前输入、先前隐藏状态和当前单元输入计算的输出状态信息,最终用于预测未来股票市场价格。此外,隐藏状态可以决定仅检索存储在单元状态中的短期或长期或两种类型的记忆来进行下一个预测。
- 输入门 (it ) - 决定当前输入有多少信息流向单元状态
- 遗忘门 (ft ) - 决定有多少来自当前输入和先前单元状态的信息流入当前单元状态
- 输出门 (ot ) - 决定有多少信息从当前细胞状态流入隐藏状态,以便如果需要 LSTM 只能选择长期记忆或短期记忆和长期记忆
下图是一个单元格。
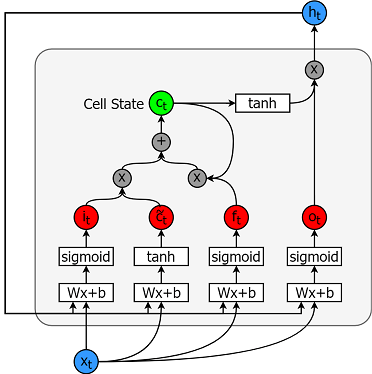
计算每个实体的方程式如下。
- i t = σ(W ix X t + W ih h t-1 + b i )
为了更好(更技术性)地理解 LSTM,您可以参考这篇文章。
TensorFlow 提供了一个很好的子 API(称为 RNN API)来实现时间序列模型。您将在您的实现中使用它。
7.1 数据生成器
您首先要实现一个数据生成器来训练您的模型。该数据生成器将有一个名为的方法,.unroll_batches(...)该方法将输出一组按顺序获得的num_unrollings批输入数据,其中一批数据的大小为[batch_size, 1]。那么每一批输入数据都会有对应的一批输出数据。
例如,如果num_unrollings=3和batch_size=4一组展开的批次,它可能看起来像,
- 输入数据:
- 输出数据:
7.2 数据增强
另外,为了使您的模型稳健,您不会使的输出始终为
。相反,您将从集合
中随机采样输出,其中 N 是小窗口大小。
在这里,您做出以下假设:
彼此之间的距离不会太远
我个人认为这是股票走势预测的合理假设。
下面您将说明如何直观地创建一批数据。
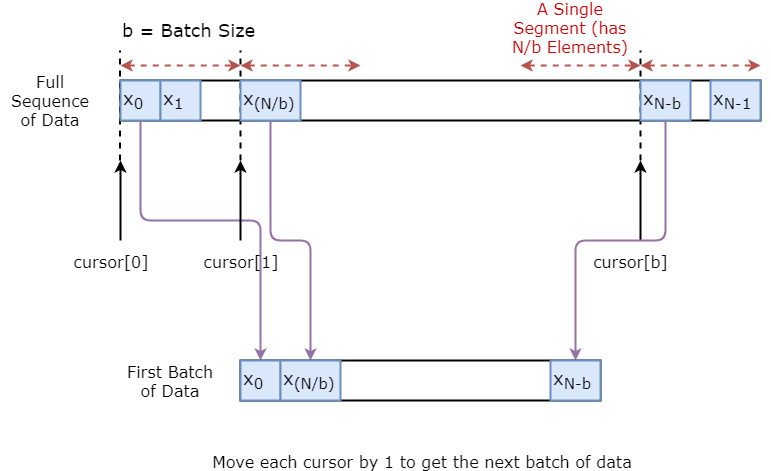
class DataGeneratorSeq(object):def __init__(self,prices,batch_size,num_unroll):self._prices = pricesself._prices_length = len(self._prices) - num_unrollself._batch_size = batch_sizeself._num_unroll = num_unrollself._segments = self._prices_length //self._batch_sizeself._cursor = [offset * self._segments for offset in range(self._batch_size)]def next_batch(self):batch_data = np.zeros((self._batch_size),dtype=np.float32)batch_labels = np.zeros((self._batch_size),dtype=np.float32)for b in range(self._batch_size):if self._cursor[b]+1>=self._prices_length:#self._cursor[b] = b * self._segmentsself._cursor[b] = np.random.randint(0,(b+1)*self._segments)batch_data[b] = self._prices[self._cursor[b]]batch_labels[b]= self._prices[self._cursor[b]+np.random.randint(0,5)]self._cursor[b] = (self._cursor[b]+1)%self._prices_lengthreturn batch_data,batch_labelsdef unroll_batches(self):unroll_data,unroll_labels = [],[]init_data, init_label = None,Nonefor ui in range(self._num_unroll):data, labels = self.next_batch() unroll_data.append(data)unroll_labels.append(labels)return unroll_data, unroll_labelsdef reset_indices(self):for b in range(self._batch_size):self._cursor[b] = np.random.randint(0,min((b+1)*self._segments,self._prices_length-1))dg = DataGeneratorSeq(train_data,5,5)
u_data, u_labels = dg.unroll_batches()for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)): print('\n\nUnrolled index %d'%ui)dat_ind = datlbl_ind = lblprint('\tInputs: ',dat )print('\n\tOutput:',lbl)
此代码定义了一个名为 DataGeneratorSeq 的类,它为序列预测问题生成批量数据和标签。
• 构造函数接受三个参数:prices(价格列表)、batch_size(每个批次的大小)和num_unroll(展开数据的时间步数)。
• next_batch 方法生成下一批数据和标签。
• 它首先使用形状(batch_size,) 初始化两个零数组来存储数据和标签。
• 然后循环遍历每个批次并检查当前光标位置加一是否大于或等于价格列表的长度。
• 如果是,它将光标位置设置为0 到(b+1)*self._segments 之间的随机整数,其中b 是当前批次索引,self._segments 是价格列表中的段数。
• 然后将当前批次数据设置为当前光标位置的价格,并将当前批次标签设置为当前光标位置的价格加上0 到5 之间的随机整数。
• 最后,它通过将光标位置加1 并取价格长度的模来更新光标位置。
• unroll_batches 方法通过调用next_batch 方法num_unroll 次并将结果附加到两个列表来生成num_unroll 批数据和标签。
• 然后返回这些列表。
• reset_indices 方法将每个批次的光标位置重置为 0 到 (b+1)*self._segments 最小值之间的随机整数,并且价格列表的长度减 1。
• 然后,代码创建 DataGeneratorSeq 类的实例,其中包含 train_data、批量大小为 5、展开的时间步数为 5。
• 然后调用unroll_batches 方法来生成展开的数据和标签并将其打印出来。Unrolled index 0Inputs: [0.03143791 0.6904868 0.82829314 0.32585657 0.11600105]Output: [0.08698314 0.68685144 0.8329321 0.33355275 0.11785509]Unrolled index 1Inputs: [0.06067836 0.6890754 0.8325337 0.32857886 0.11785509]Output: [0.15261841 0.68685144 0.8325337 0.33421066 0.12106793]Unrolled index 2Inputs: [0.08698314 0.68685144 0.8329321 0.33078218 0.11946969]Output: [0.11098009 0.6848606 0.83387965 0.33421066 0.12106793]Unrolled index 3Inputs: [0.11098009 0.6858036 0.83294916 0.33219692 0.12106793]Output: [0.132895 0.6836884 0.83294916 0.33219692 0.12288672]Unrolled index 4Inputs: [0.132895 0.6848606 0.833369 0.33355275 0.12158521]Output: [0.15261841 0.6836884 0.83383167 0.33355275 0.12230608]
7.3 定义超参数
在本部分中,您将定义几个超参数。D是输入的维数。这很简单,因为您将前一个股票价格作为输入并预测下一个股票价格,应该是1。
那么你就有了num_unrollings,这是一个与时间反向传播 (BPTT) 相关的超参数,用于优化 LSTM 模型。这表示您为单个优化步骤考虑的连续时间步骤数。您可以将此视为通过查看时间步来优化网络,而不是通过查看单个时间步来优化模型num_unrollings。越大越好。
然后你就拥有了batch_size.批量大小是您在单个时间步中考虑的数据样本数量。
接下来,您定义num_nodes代表每个单元中隐藏神经元的数量。您可以看到此示例中有三层 LSTM。
D = 1 # Dimensionality of the data. Since your data is 1-D this would be 1
num_unrollings = 50 # Number of time steps you look into the future.
batch_size = 500 # Number of samples in a batch
num_nodes = [200,200,150] # Number of hidden nodes in each layer of the deep LSTM stack we're using
n_layers = len(num_nodes) # number of layers
dropout = 0.2 # dropout amounttf.reset_default_graph() # This is important in case you run this multiple times
7.4 定义输入和输出
接下来,您定义训练输入和标签的占位符。这非常简单,因为您有一个输入占位符列表,其中每个占位符都包含一批数据。该列表具有num_unrollings占位符,将立即用于单个优化步骤。
# Input data.
train_inputs, train_outputs = [],[]# You unroll the input over time defining placeholders for each time step
for ui in range(num_unrollings):train_inputs.append(tf.placeholder(tf.float32, shape=[batch_size,D],name='train_inputs_%d'%ui))train_outputs.append(tf.placeholder(tf.float32, shape=[batch_size,1], name = 'train_outputs_%d'%ui))
此代码定义了循环神经网络 (RNN) 模型中使用的输入和输出数据的占位符。
• 输入数据随时间展开,这意味着模型将一次处理一个输入序列,每个输入都被视为一个单独的时间步长。
• train_inputs 和train_outputs 列表最初为空,for 循环迭代由num_unrollings 变量指定的展开数。
• 对于每个时间步,使用tf.placeholder 函数创建一个新的占位符。
• tf.placeholder 函数创建一个占位符张量,将在训练过程中为其提供数据。
• tf.float32 参数指定张量的数据类型,shape 参数指定张量的形状。
• 在这种情况下,输入张量的形状为[batch_size, D],其中batch_size 是并行处理的输入序列的数量,D 是每个输入向量的维度。
• 输出张量的形状为[batch_size, 1],表示模型将为每个输入序列输出单个标量值。
• name 参数用于为每个占位符提供唯一的名称,这对于调试和可视化目的非常有用。
• 名称包括当前时间步长的索引,该索引在循环的每次迭代中由ui 变量递增。7.5 定义 LSTM 和回归层的参数
您将拥有三层 LSTM 和一个线性回归层(用 和 表示w)b,它获取最后一个长短期记忆单元的输出并输出下一个时间步的预测。您可以使用TensorFlow 中的 来封装您创建的MultiRNNCell三个对象。LSTMCell此外,您可以让 dropout 实现 LSTM 单元,因为它们可以提高性能并减少过度拟合。
lstm_cells = [tf.contrib.rnn.LSTMCell(num_units=num_nodes[li],state_is_tuple=True,initializer= tf.contrib.layers.xavier_initializer())for li in range(n_layers)]drop_lstm_cells = [tf.contrib.rnn.DropoutWrapper(lstm, input_keep_prob=1.0,output_keep_prob=1.0-dropout, state_keep_prob=1.0-dropout
) for lstm in lstm_cells]
drop_multi_cell = tf.contrib.rnn.MultiRNNCell(drop_lstm_cells)
multi_cell = tf.contrib.rnn.MultiRNNCell(lstm_cells)w = tf.get_variable('w',shape=[num_nodes[-1], 1], initializer=tf.contrib.layers.xavier_initializer())
b = tf.get_variable('b',initializer=tf.random_uniform([1],-0.1,0.1))
This code defines a multi-layer LSTM (Long Short-Term Memory) neural network for a time series prediction task.
• First, the code creates a list of LSTM cells using a list comprehension.
• Each cell has a specified number of nodes (num_nodes) and is initialized using the Xavier initializer.
• Next, the code creates a list of dropout LSTM cells using another list comprehension.
• The dropout rate is specified by the variable 'dropout'.
• Then, the code creates a multi-layer cell by stacking the dropout LSTM cells using the MultiRNNCell function.
• This cell is used during training to prevent overfitting.
• Finally, the code defines the output layer of the neural network by creating two variables 'w' and 'b'.
• 'w' is a weight matrix with dimensions [num_nodes[-1], 1] and is initialized using the Xavier initializer.
• 'b' is a bias vector with a single element and is initialized using a uniform distribution between -0.1 and 0.1.
• These variables are used to compute the final output of the neural network.7.6 计算 LSTM 输出并将其馈送到回归层以获得最终预测
在本部分中,您首先创建 TensorFlow 变量 (c和h),用于保存长短期记忆单元的单元状态和隐藏状态。然后将 的列表转换train_inputs为 的形状[num_unrollings, batch_size, D],这是使用函数计算输出所需要的tf.nn.dynamic_rnn。然后,您使用该函数计算 LSTM 输出 tf.nn.dynamic_rnn,并将输出拆分回张num_unrolling量列表。预测与真实股票价格之间的损失。
# Create cell state and hidden state variables to maintain the state of the LSTM
c, h = [],[]
initial_state = []
for li in range(n_layers):c.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))h.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))initial_state.append(tf.contrib.rnn.LSTMStateTuple(c[li], h[li]))# Do several tensor transofmations, because the function dynamic_rnn requires the output to be of
# a specific format. Read more at: https://www.tensorflow.org/api_docs/python/tf/nn/dynamic_rnn
all_inputs = tf.concat([tf.expand_dims(t,0) for t in train_inputs],axis=0)# all_outputs is [seq_length, batch_size, num_nodes]
all_lstm_outputs, state = tf.nn.dynamic_rnn(drop_multi_cell, all_inputs, initial_state=tuple(initial_state),time_major = True, dtype=tf.float32)all_lstm_outputs = tf.reshape(all_lstm_outputs, [batch_size*num_unrollings,num_nodes[-1]])all_outputs = tf.nn.xw_plus_b(all_lstm_outputs,w,b)split_outputs = tf.split(all_outputs,num_unrollings,axis=0)
此代码使用 TensorFlow 创建长短期记忆 (LSTM) 神经网络。
• 首先,它创建变量来维护LSTM 的状态。
• 这些变量是单元状态和隐藏状态,它们被初始化为零张量。
• LSTM 每层的节点数由num_nodes 列表指定,层数由n_layers 指定。
• 接下来,代码执行一些张量转换,为dynamic_rnn 函数准备输入数据。
• train_inputs 列表包含每个时间步的输入数据,这些输入使用tf.concat 连接成单个张量。
• 生成的张量具有维度[seq_length、batch_size、input_size],其中seq_length 是时间步数,batch_size 是并行处理的序列数,input_size 是每个输入向量的大小。
• 然后使用drop_multi_cell 单元调用dynamic_rnn 函数,该单元是一个多层LSTM 单元,在输入和输出上应用了dropout。
•initial_state 参数设置为之前创建的LSTM 的初始状态。
• time_major 参数设置为True,表示输入张量的维度为[seq_length、batch_size、input_size]。
•dynamic_rnn 的输出是LSTM 输出的张量,其维度为[seq_length、batch_size、num_nodes[-1]],其中num_nodes[-1] 是LSTM 最后一层的节点数。
• 然后将all_lstm_outputs 张量重塑为尺寸为[batch_size*num_unrollings, num_nodes[-1]] 的2D 张量,其中num_unrollings 是训练期间展开的时间步数。
• 然后,将此重塑张量乘以权重矩阵 w,并使用 tf.nn.xw_plus_b 添加到偏置向量 b,以生成最终输出张量 all_outputs。
• 最后,使用tf.split 将all_outputs 拆分为张量列表,每个张量的维度为[batch_size, num_nodes[-1]]。
• 这些张量代表LSTM 在每个时间步的输出。7.7 损失计算和优化器
现在,您将计算损失。但是,您应该注意,计算损失时有一个独特的特征。对于每批预测和真实输出,您计算均方误差。然后将所有这些均方损失相加(不是平均)。最后,您定义将用于优化神经网络的优化器。在这种情况下,您可以使用 Adam,这是一个非常新且性能良好的优化器。
# When calculating the loss you need to be careful about the exact form, because you calculate
# loss of all the unrolled steps at the same time
# Therefore, take the mean error or each batch and get the sum of that over all the unrolled stepsprint('Defining training Loss')
loss = 0.0
with tf.control_dependencies([tf.assign(c[li], state[li][0]) for li in range(n_layers)]+[tf.assign(h[li], state[li][1]) for li in range(n_layers)]):for ui in range(num_unrollings):loss += tf.reduce_mean(0.5*(split_outputs[ui]-train_outputs[ui])**2)print('Learning rate decay operations')
global_step = tf.Variable(0, trainable=False)
inc_gstep = tf.assign(global_step,global_step + 1)
tf_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)
tf_min_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)learning_rate = tf.maximum(tf.train.exponential_decay(tf_learning_rate, global_step, decay_steps=1, decay_rate=0.5, staircase=True),tf_min_learning_rate)# Optimizer.
print('TF Optimization operations')
optimizer = tf.train.AdamOptimizer(learning_rate)
gradients, v = zip(*optimizer.compute_gradients(loss))
gradients, _ = tf.clip_by_global_norm(gradients, 5.0)
optimizer = optimizer.apply_gradients(zip(gradients, v))print('\tAll done')
此代码定义了循环神经网络 (RNN) 模型的训练损失和优化操作。
• 首先,代码将损失变量初始化为0.0,然后使用for 循环计算每个展开步骤的预测输出和实际输出之间的均方误差。
• 损失在所有展开的步骤上累积。
• 接下来,代码定义学习率衰减操作。
• 它创建一个全局步骤变量,该变量在每个训练步骤后递增。
• 然后使用衰减率为0.5 且阶梯参数设置为True 的指数衰减函数计算学习率。
• 学习率设置为衰减学习率的最大值和用户指定的最小学习率。
• 最后,代码使用 Adam 优化器定义优化器操作,并应用梯度裁剪来防止梯度爆炸。
• 使用损失函数计算梯度,然后按最大范数 5.0 进行裁剪。
• 然后使用优化器将剪裁的梯度应用于模型参数。Defining training Loss
Learning rate decay operations
TF Optimization operationsAll done
7.8 预测相关计算
您可以在此处定义与预测相关的 TensorFlow 操作。首先,定义用于输入输入的占位符 ( sample_inputs),然后与训练阶段类似,定义用于预测的状态变量 (sample_c和sample_h)。最后,您使用该函数计算预测,然后通过回归层(和)tf.nn.dynamic_rnn发送输出。您还应该定义重置单元状态和隐藏状态的操作。每次进行一系列预测时,您都应该在开始时执行此操作。wbreset_sample_state
print('Defining prediction related TF functions')sample_inputs = tf.placeholder(tf.float32, shape=[1,D])# Maintaining LSTM state for prediction stage
sample_c, sample_h, initial_sample_state = [],[],[]
for li in range(n_layers):sample_c.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))sample_h.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))initial_sample_state.append(tf.contrib.rnn.LSTMStateTuple(sample_c[li],sample_h[li]))reset_sample_states = tf.group(*[tf.assign(sample_c[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)],*[tf.assign(sample_h[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)])sample_outputs, sample_state = tf.nn.dynamic_rnn(multi_cell, tf.expand_dims(sample_inputs,0),initial_state=tuple(initial_sample_state),time_major = True,dtype=tf.float32)with tf.control_dependencies([tf.assign(sample_c[li],sample_state[li][0]) for li in range(n_layers)]+[tf.assign(sample_h[li],sample_state[li][1]) for li in range(n_layers)]): sample_prediction = tf.nn.xw_plus_b(tf.reshape(sample_outputs,[1,-1]), w, b)print('\tAll done')
此代码定义了 TensorFlow 函数,用于使用经过训练的 LSTM 模型进行预测。
• 首先,为输入数据创建形状为[1,D] 的占位符,其中D 是输入要素的数量。
• 接下来,为预测阶段初始化LSTM 状态。
• 这是通过为LSTM 每层的单元状态(sample_c)、隐藏状态(sample_h) 和初始状态(initial_sample_state) 创建空列表来完成的。
• 然后,对于每一层,为单元状态和隐藏状态创建一个变量,两者都用零初始化并设置为不可训练。
• 最后,每层的初始状态被设置为相应单元和隐藏状态的元组。
• 之后,定义一个函数将LSTM 状态重置为零。
• 这是通过将单元的零分配和每层的隐藏状态分组在一起来完成的。
• 然后,调用dynamic_rnn 函数通过LSTM 模型运行输入数据。
• multi_cell 参数是 LSTM 单元对象,输入数据扩展为批量大小为 1。
• 初始状态设置为之前创建的initial_sample_state,time_major 参数设置为True 以指示输入数据采用时间主要格式。
• 该函数的输出是每个时间步的LSTM 输出(sample_outputs) 和LSTM 的最终状态(sample_state)。
• 最后,使用dynamic_rnn 函数的输出定义sample_prediction。
• 将sample_outputs 重塑为[1,-1] 形状(其中-1 被推断为剩余维度的乘积),然后乘以权重矩阵(w) 并添加到偏差向量(b )使用 xw_plus_b 函数。
• control_dependency 函数用于确保LSTM 状态在每次预测后更新为最终状态。
• 总体而言,此代码设置了使用经过训练的 LSTM 模型进行预测所需的函数。Defining prediction related TF functionsAll done
7.9 运行 LSTM
在这里,您将训练和预测几个时期的股票价格走势,并查看预测随着时间的推移是变得更好还是更差。您按照以下步骤操作。
- 在时间序列上定义一组起始点 (
test_points_seq) 来评估模型 - 对于每个纪元
- 对于训练数据的完整序列长度
- 展开一组
num_unrollings批次 - 使用展开的批次训练神经网络
- 展开一组
- 计算平均训练损失
- 对于测试集中的每个起点
- 通过迭代
num_unrollings测试点之前找到的先前数据点来更新 LSTM 状态 n_predict_once使用先前的预测作为当前输入,连续对步骤进行预测n_predict_once计算预测点与这些时间戳的真实股票价格之间的 MSE 损失
- 通过迭代
- 对于训练数据的完整序列长度
epochs = 30
valid_summary = 1 # Interval you make test predictionsn_predict_once = 50 # Number of steps you continously predict fortrain_seq_length = train_data.size # Full length of the training datatrain_mse_ot = [] # Accumulate Train losses
test_mse_ot = [] # Accumulate Test loss
predictions_over_time = [] # Accumulate predictionssession = tf.InteractiveSession()tf.global_variables_initializer().run()# Used for decaying learning rate
loss_nondecrease_count = 0
loss_nondecrease_threshold = 2 # If the test error hasn't increased in this many steps, decrease learning rateprint('Initialized')
average_loss = 0# Define data generator
data_gen = DataGeneratorSeq(train_data,batch_size,num_unrollings)x_axis_seq = []# Points you start your test predictions from
test_points_seq = np.arange(11000,12000,50).tolist()for ep in range(epochs): # ========================= Training =====================================for step in range(train_seq_length//batch_size):u_data, u_labels = data_gen.unroll_batches()feed_dict = {}for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)): feed_dict[train_inputs[ui]] = dat.reshape(-1,1)feed_dict[train_outputs[ui]] = lbl.reshape(-1,1)feed_dict.update({tf_learning_rate: 0.0001, tf_min_learning_rate:0.000001})_, l = session.run([optimizer, loss], feed_dict=feed_dict)average_loss += l# ============================ Validation ==============================if (ep+1) % valid_summary == 0:average_loss = average_loss/(valid_summary*(train_seq_length//batch_size))# The average lossif (ep+1)%valid_summary==0:print('Average loss at step %d: %f' % (ep+1, average_loss))train_mse_ot.append(average_loss)average_loss = 0 # reset losspredictions_seq = []mse_test_loss_seq = []# ===================== Updating State and Making Predicitons ========================for w_i in test_points_seq:mse_test_loss = 0.0our_predictions = []if (ep+1)-valid_summary==0:# Only calculate x_axis values in the first validation epochx_axis=[]# Feed in the recent past behavior of stock prices# to make predictions from that point onwardsfor tr_i in range(w_i-num_unrollings+1,w_i-1):current_price = all_mid_data[tr_i]feed_dict[sample_inputs] = np.array(current_price).reshape(1,1) _ = session.run(sample_prediction,feed_dict=feed_dict)feed_dict = {}current_price = all_mid_data[w_i-1]feed_dict[sample_inputs] = np.array(current_price).reshape(1,1)# Make predictions for this many steps# Each prediction uses previous prediciton as it's current inputfor pred_i in range(n_predict_once):pred = session.run(sample_prediction,feed_dict=feed_dict)our_predictions.append(np.asscalar(pred))feed_dict[sample_inputs] = np.asarray(pred).reshape(-1,1)if (ep+1)-valid_summary==0:# Only calculate x_axis values in the first validation epochx_axis.append(w_i+pred_i)mse_test_loss += 0.5*(pred-all_mid_data[w_i+pred_i])**2session.run(reset_sample_states)predictions_seq.append(np.array(our_predictions))mse_test_loss /= n_predict_oncemse_test_loss_seq.append(mse_test_loss)if (ep+1)-valid_summary==0:x_axis_seq.append(x_axis)current_test_mse = np.mean(mse_test_loss_seq)# Learning rate decay logicif len(test_mse_ot)>0 and current_test_mse > min(test_mse_ot):loss_nondecrease_count += 1else:loss_nondecrease_count = 0if loss_nondecrease_count > loss_nondecrease_threshold :session.run(inc_gstep)loss_nondecrease_count = 0print('\tDecreasing learning rate by 0.5')test_mse_ot.append(current_test_mse)print('\tTest MSE: %.5f'%np.mean(mse_test_loss_seq))predictions_over_time.append(predictions_seq)print('\tFinished Predictions')
该代码训练循环神经网络 (RNN) 来预测股票价格。
• 它使用序列到序列模型,其中输入序列是股票价格的过去行为,输出序列是预测的未来价格。
• 代码首先设置一些超参数,例如时期数、进行测试预测的间隔以及连续预测的步骤数。
• 它还初始化一些变量以累积训练和测试损失以及随时间的预测。
• 然后,它初始化TensorFlow 会话和数据生成器以生成批量训练数据。
• 它还设置一个循环来迭代历元,并设置另一个循环来迭代每个历元中的步骤。
• 在每个步骤中,它都会展开批量训练数据并将其输入 RNN。
• 然后使用优化器计算损失并更新权重。
• 在每个时期之后,代码通过进行测试预测来执行验证。
• 它首先计算该时期训练数据的平均损失。
• 然后,它设置一个循环来迭代测试点并对每个点进行预测。
• 它根据最近的股票价格行为来做出从该点开始的预测。
• 然后,它对一定数量的步骤进行预测,每个预测都使用先前的预测作为其当前输入。
• 它计算预测价格和实际价格之间的均方误差(MSE),并随时间累积预测和MSE。
• 该代码还实现了学习率衰减逻辑,如果测试误差在一定数量的步骤中没有增加,则可以降低学习率。
• 它打印出测试MSE 和每个时期的预测。Initialized
Average loss at step 1: 1.703350Test MSE: 0.00318Finished Predictions.........
Average loss at step 30: 0.033753Test MSE: 0.00243Finished Predictions
八、可视化预测
您可以看到 MSE 损失如何随着训练量的增加而下降。这是一个好兆头,表明该模型正在学习一些有用的东西。为了量化您的发现,您可以将网络的 MSE 损失与进行标准平均 (0.004) 时获得的 MSE 损失进行比较。您可以看到 LSTM 的表现比标准平均要好。而且您知道标准平均法(尽管并不完美)合理地遵循了真实的股价走势。
best_prediction_epoch = 28 # replace this with the epoch that you got the best results when running the plotting codeplt.figure(figsize = (18,18))
plt.subplot(2,1,1)
plt.plot(range(df.shape[0]),all_mid_data,color='b')# Plotting how the predictions change over time
# Plot older predictions with low alpha and newer predictions with high alpha
start_alpha = 0.25
alpha = np.arange(start_alpha,1.1,(1.0-start_alpha)/len(predictions_over_time[::3]))
for p_i,p in enumerate(predictions_over_time[::3]):for xval,yval in zip(x_axis_seq,p):plt.plot(xval,yval,color='r',alpha=alpha[p_i])plt.title('Evolution of Test Predictions Over Time',fontsize=18)
plt.xlabel('Date',fontsize=18)
plt.ylabel('Mid Price',fontsize=18)
plt.xlim(11000,12500)plt.subplot(2,1,2)# Predicting the best test prediction you got
plt.plot(range(df.shape[0]),all_mid_data,color='b')
for xval,yval in zip(x_axis_seq,predictions_over_time[best_prediction_epoch]):plt.plot(xval,yval,color='r')plt.title('Best Test Predictions Over Time',fontsize=18)
plt.xlabel('Date',fontsize=18)
plt.ylabel('Mid Price',fontsize=18)
plt.xlim(11000,12500)
plt.show()
该代码训练循环神经网络 (RNN) 来预测股票价格。
• 它使用序列到序列模型,其中输入序列是股票价格的过去行为,输出序列是预测的未来价格。
• 代码首先设置一些超参数,例如时期数、进行测试预测的间隔以及连续预测的步骤数。
• 它还初始化一些变量以累积训练和测试损失以及随时间的预测。
• 然后,它初始化TensorFlow 会话和数据生成器以生成批量训练数据。
• 它还设置一个循环来迭代历元和另一个循环来迭代ste。此代码绘制了测试预测随时间的演变以及最佳测试预测随时间的变化。
• 第一行设置具有最佳预测结果的纪元。
• 下一行创建一个带有两个子图的图形,每个子图的大小为18x18。
• 第一个子图以蓝色绘制一段时间内的中间价格数据。
• 第二个子图以蓝色绘制随时间变化的中间价格数据,以红色绘制随时间变化的最佳测试预测。
• 第一个子图中的for 循环以不同的alpha 值绘制随时间变化的预测,较旧的预测具有较低的alpha 值,较新的预测具有较高的alpha 值。
• 第二个子图中的for 循环以红色绘制随时间变化的最佳测试预测。
• x 轴限制在11000 到12500 的范围内。
• 最后,使用 plt.show().ps 在每个时期显示绘图。
• 在每个步骤中,它都会展开批量训练数据并将其输入 RNN。
• 然后使用优化器计算损失并更新权重。
• 在每个时期之后,代码通过进行测试预测来执行验证。
• 它首先计算该时期训练数据的平均损失。
• 然后,它设置一个循环来迭代测试点并对每个点进行预测。
• 它根据最近的股票价格行为来做出从该点开始的预测。
• 然后,它对一定数量的步骤进行预测,每个预测都使用先前的预测作为其当前输入。
• 它计算预测价格和实际价格之间的均方误差(MSE),并随时间累积预测和MSE。
• 该代码还实现了学习率衰减逻辑,如果测试误差在一定数量的步骤中没有增加,则可以降低学习率。
• 它打印出测试MSE 和每个时期的预测。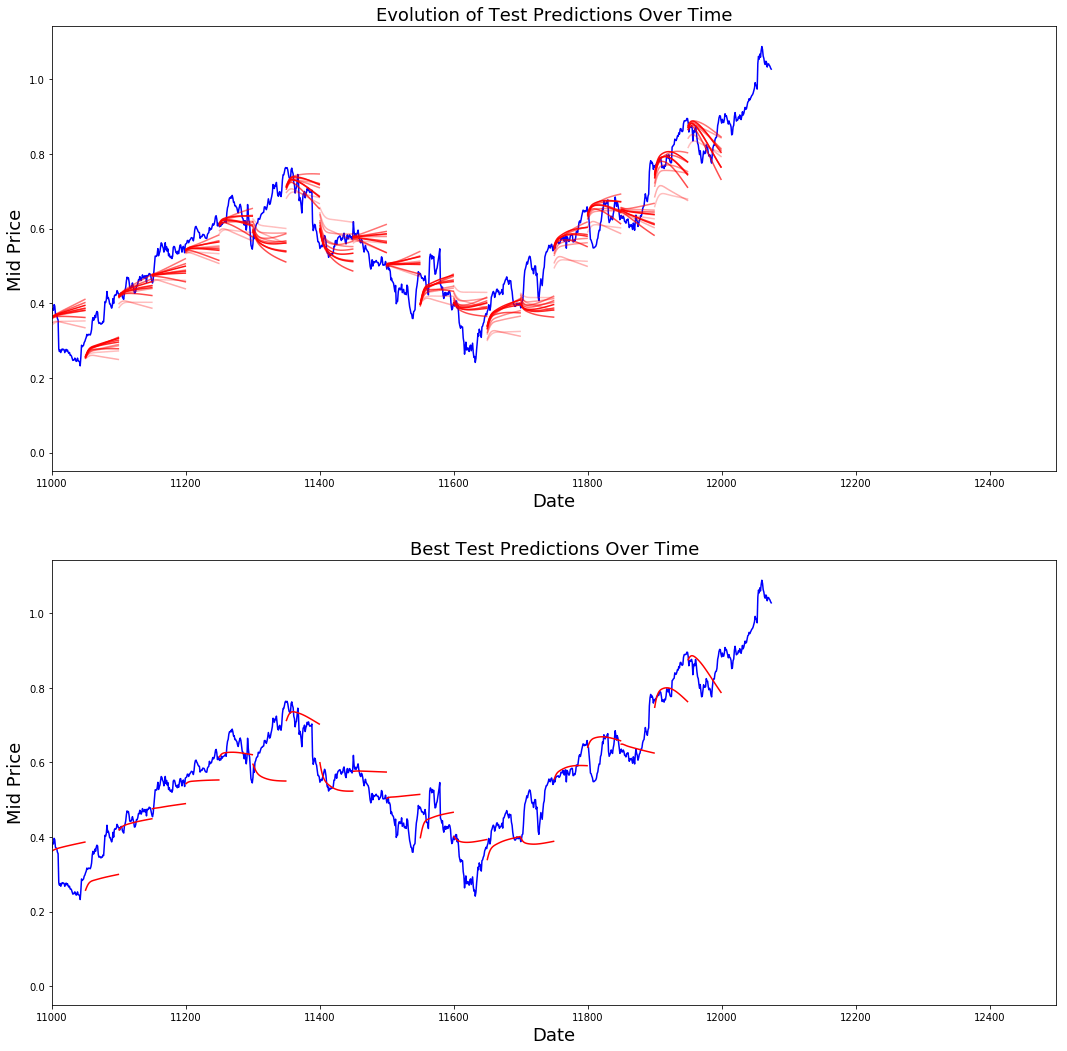
尽管并不完美,但 LSTM 似乎在大多数情况下都能正确预测股票价格行为。请注意,您的预测大致在 0 到 1.0 的范围内(即,不是真实的股票价格)。这没关系,因为您预测的是股票价格走势,而不是价格本身。
九、最后的评论
我希望您觉得本教程有用。我应该指出,这对我来说是一次有益的经历。在本教程中,我了解到建立能够正确预测股票价格走势的模型是多么困难。您一开始就知道为什么需要对股票价格进行建模。接下来是下载数据的解释和代码。然后您了解了两种平均技术,可以让您对未来进行一步预测。接下来您会发现,当您需要预测未来的不止一步时,这些方法是徒劳的。此后,您讨论了如何使用 LSTM 来预测未来的许多步骤。最后,您将结果可视化,并发现您的模型(尽管并不完美)非常擅长正确预测股票价格走势。
如果您想了解有关深度学习的更多信息,请务必查看我们的Python 深度学习课程。它涵盖了基础知识,以及如何在 Keras 中自行构建神经网络。这是与本教程中将使用的 TensorFlow 不同的包,但其思想是相同的。
在这里,我将阐述本教程的几个要点。
-
股票价格/走势预测是一项极其困难的任务。就我个人而言,我认为任何股票预测模型都不应该被视为理所当然并盲目依赖它们。然而,模型在大多数时候可能能够正确预测股价走势,但并非总是如此。
-
不要被那些显示预测曲线与真实股价完全重叠的文章所愚弄。这可以通过简单的平均技术来复制,但在实践中它是无用的。更明智的做法是预测股价走势。
-
模型的超参数对您获得的结果极其敏感。因此,一个非常好的做法是对超参数运行一些超参数优化技术(例如网格搜索/随机搜索)。下面我列出了一些最关键的超参数
- 优化器的学习率
- 层数及每层隐藏单元数
- 优化器。我发现 Adam 表现最好
- 模型的类型。您可以尝试 GRU/ Standard LSTM/ 带 Peepholes 的 LSTM 并评估性能差异
-
在本教程中,您做了一些错误的事情(由于数据量太小)!也就是说,您使用测试损失来降低学习率。这间接地将有关测试集的信息泄漏到训练过程中。处理此问题的更好方法是使用单独的验证集(除了测试集)并根据验证集的性能衰减学习率。
参考
本文参考了这个存储库来了解如何使用 LSTM 进行股票预测。但细节可能与参考文献中的实现有很大不同。