一、了解基本概念以及信息
1.什么是爬虫
爬虫是一段自动抓取互联网信息的程序,可以从一个URL出发,访问它所关联的URL,提取我们所需要的数据。也就是说爬虫是自动访问互联网并提取数据的程序。
它可以将互联网上的数据为我所用,开发出属于自己的网站或APP。
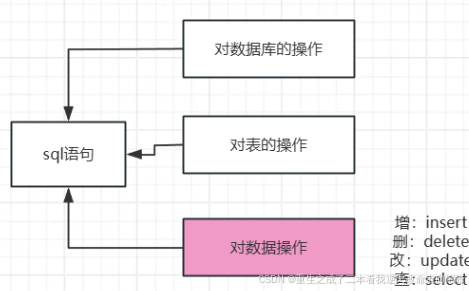
2.在爬虫程序中有三个模块
(1)URL管理器:对将要爬取的URL和已经爬取过的URL这两个数据进行管理
(2)网页下载器:将URL管理器里提供的一个URL对应的网页下载下来,存储为一个字符串,这个字符串会传送给网页解析器进行解析
(3)网页解析器:一方面会解析出有价值的数据,另一方面,由于每一个页面都有很多指向其它页面的网页,这些URL被解析出来之后,可以补充进URL管理器




3.网页解析器——LXML和Xpath
1.网页解析概述:
除了学会向服务器发出请求、下载HTML源码,要获取结构化的数据还面临一个最常见的任务,就是从HTML源码中提取数据。
三种方法:
正则表达式
lxml库
BeautifulSoup
针对文本的解析,用正则表达式
针对html/xml的解析,有Xpath、BeautifulSoup、正则表达式
针对JSON的解析,有JSONPath
2.xpath(XML Path Language)实现路径选择,变换路径实现对信息的采集。使用路径表达式来选取XML文档中的节点或者节点集
3.Xpath里面管理扩展程序保持一个类似这样的格式
// 是当前根目录下 @ [] 通过检查找到你想要的东西

4.如何Copy Xpath,以豆瓣电影为例(http:淄博 - 在线购票&影讯)
右键点击检查按钮

进入Xpath的管理扩展程序,具体的插件要下载安装找教程


就像这样:

具体的解释:

5.Lxml库:
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
lxml python 官方文档:http://lxml.de/index.html
需要安装C语言库,可使用 pip 安装:pip install lxml
Lxml进行解析封装:
我们可以利用他来解析HTML代码,并且在解析HTML代码的时候,如果HTML代码不规范,他会自动的进行补全
1.使用 lxml 的 etree 库 from lxml import etree
2.python 3.5后的lxml模块中不能再直接引入etree模块,需要使用以下方法引用
from lxml import html
etree=html.etree
二、如何使用PyCharm写代码来实现网络爬虫
淄博 - 在线购票&影讯淄博电影院在线优惠购票及影讯排片查询![]() https://movie.douban.com/cinema/nowplaying/zibo/还是以这个网址为例:
https://movie.douban.com/cinema/nowplaying/zibo/还是以这个网址为例:
1.url就是你要爬虫页面的网址,headers是一个请求头,要这样寻找:
1.还是要在页面上右键检查


2.这个代码是一个简单的网络爬虫,用于从豆瓣电影的“正在上映”页面中提取电影信息。代码详情:
# 导入所需的库
import requests # 用于发送HTTP请求
from bs4 import BeautifulSoup # 用于解析HTML文档# 设置目标URL和请求头
url = "https://movie.douban.com/cinema/nowplaying/zibo/" # 豆瓣电影正在上映页面的URL
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36 Edg/133.0.0.0"
} # 请求头,模拟浏览器访问,避免被服务器识别为爬虫# 发送HTTP GET请求,获取网页内容
res = requests.get(url, headers=headers) # 使用requests库发送请求,获取响应对象
soup = BeautifulSoup(res.text, "lxml") # 使用BeautifulSoup解析HTML文档,lxml是解析器类型# 查找电影列表
lists = soup.find("ul", class_="lists") # 在HTML文档中查找第一个<ul>标签,且其class属性为"lists"
if lists: # 如果找到了电影列表movies = [] # 初始化一个空列表,用于存储提取的电影信息# 查找所有<li>标签,且其class属性为"stitle"lis = lists.find_all("li", class_="stitle")for li in lis: # 遍历每个<li>标签a = li.find("a") # 在<li>标签中查找<a>标签if a: # 如果找到了<a>标签title = a.get_text() # 获取<a>标签的文本内容,即电影标题href = a["href"] # 获取<a>标签的href属性值,即电影详情页的链接movie = {"title": title.strip(), "href": href} # 将电影标题和链接以字典形式存储movies.append(movie) # 将字典添加到movies列表中# 输出方式1:直接打印字典列表# print(movies) # 直接输出movies列表,内容为字典形式# 输出方式2:换行输出每个电影的标题和链接for movie in movies: # 遍历movies列表中的每个电影print(f"Title: {movie['title']}\nLink: {movie['href']}\n") # 打印电影标题和链接,并换行
else: # 如果没有找到电影列表print("未找到电影列表") # 打印提示信息# 或者这样写(注释掉的代码):
# if lists:
# movies = []
# for li in lists.find_all("li", class_="stitle"):
# a = li.find("a")
# if a:
# title = a.get_text()
# href = a["href"]
# movies.append({"title": title.strip(), "href": href})
# print(movies) # 直接输出movies列表,内容为字典形式
# else:
# print("未找到电影列表") # 打印提示信息3.代码功能总结
-
导入库:使用
requests发送 HTTP 请求,使用BeautifulSoup解析 HTML 文档。 -
设置 URL 和请求头:定义目标 URL 和请求头,模拟浏览器访问。
-
发送请求并解析 HTML:获取网页内容并解析为
BeautifulSoup对象。 -
查找电影列表:通过 HTML 标签和类名定位电影列表。
-
提取电影信息:从每个电影条目中提取标题和链接,并存储在列表中。
-
输出结果:
-
方式1:直接打印
movies列表,输出字典形式的内容。 -
方式2:遍历
movies列表,换行输出每个电影的标题和链接。
-

这是运行详情,其他的页面也是同样的道理。