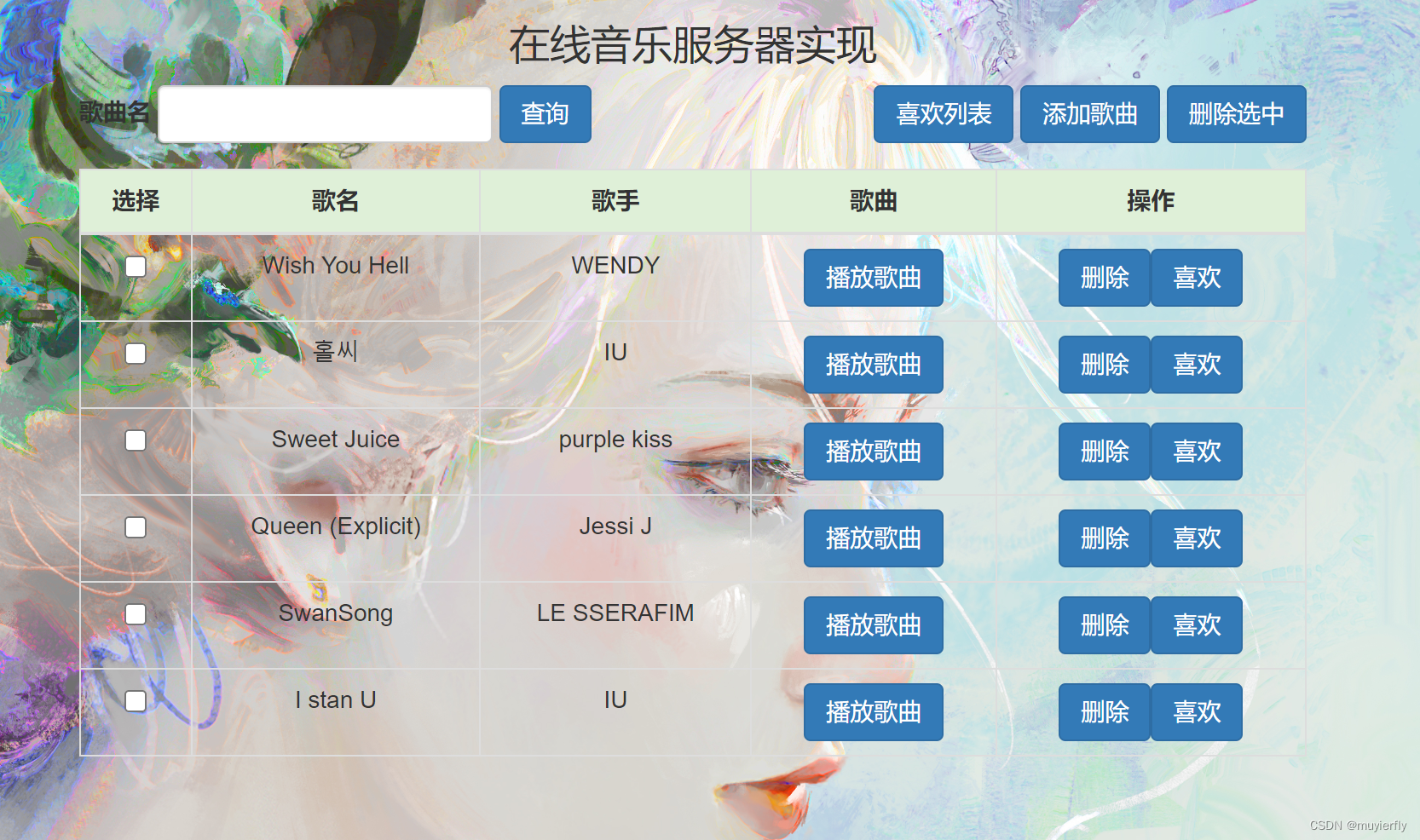
一、本文介绍
这篇文章给大家带来的是模型的蒸馏,利用教师模型指导学生模型从而进行模型的涨点,本文的内容不仅可以用于论文中,在目前的绝大多数的工作中模型蒸馏是一项非常重要的技术,所以大家可以仔细学习一下本文的内容,本文从YOLOv8的项目文件为例,进行详细的修改教程, 文章内包括完整的修改教程,针对小白我出了视频修改教程,如果你还不会我提供了修改后的文件大家直接运行即可,所以说不用担心不会适用!模型蒸馏真正的无损涨点,蒸馏你只看这一篇文章就足够了!
欢迎大家订阅我的专栏一起学习YOLO!
专栏目录:YOLOv8改进有效系列目录 | 包含卷积、主干、检测头、注意力机制、Neck上百种创新机制
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
目录
一、本文介绍
二、蒸馏教程
2.1 修改一
2.2 修改二
2.3 修改三
2.4 修改四
2.5 修改五
2.6 修改六
2.7 修改七
2.8 修改八
2.8 修改九
2.9 修改十
2.10 修改十一
2.11 修改十二
2.12 修改十三
2.13 修改十四
2.14 修改十五
三、使用教程
3.1 模型蒸馏代码
3.2 开始蒸馏
四、本文总结
二、蒸馏教程
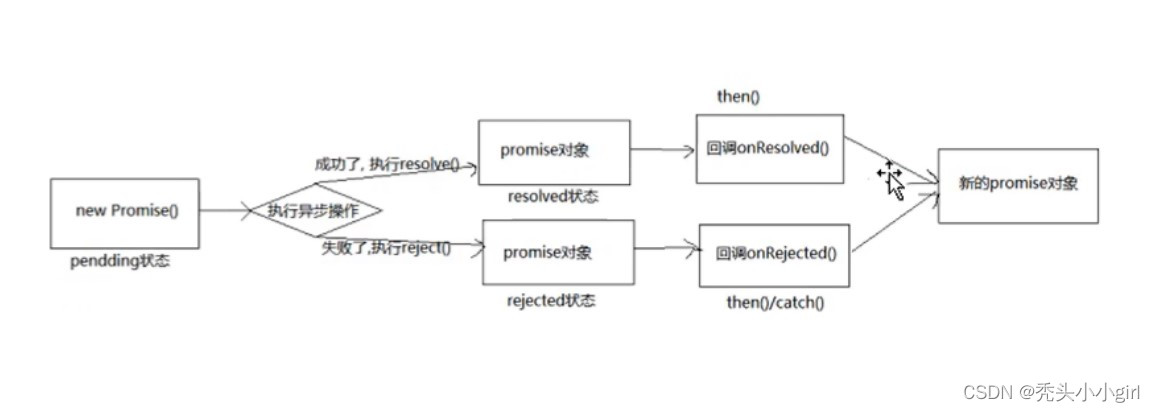
知识蒸馏的主要方法可以分为三种:基于响应的知识蒸馏(利用教师模型的输出或对最终预测的模仿)、基于特征的知识蒸馏(使用教师模型中间层的特征表示)以及基于关系的知识蒸馏(利用模型内部不同层或不同数据点之间的关系)。每种方法都旨在从大模型中提取有效信息,并通过特定的损失函数将这些信息灌输给学生模型。
首先,基于模型的知识蒸馏类型包括:
- 1. 基于响应的蒸馏(Response-based):使用教师模型的最后输出层的信息(如类别概率)来训练学生模型。
- 2. 基于特征的蒸馏(Feature-based):利用教师模型的中间层特征来指导学生模型。
- 3. 基于关系的蒸馏(Relation-based):侧重于教师模型内不同特征之间的关系,如特征图之间的相互作用。
蒸馏过程的实施方式:
- 1. 在线蒸馏(Online distillation):教师模型和学生模型同时训练,学生模型实时学习教师模型的知识。
- 2. 离线蒸馏(Offline distillation):先训练教师模型,再使用该模型来训练学生模型,学生模型不会影响教师模型。
- 3. 自蒸馏(Self distillation):模型使用自己的预测作为软标签来提高自己的性能。
知识蒸馏是一个多样化的领域,包括各种不同的方法来优化深度学习模型的性能和大小。从基本的基于响应、特征和关系的蒸馏,到更高级的在线、离线和自蒸馏过程,再到特定的技术如对抗性蒸馏或量化蒸馏等,每一种方法都旨在解决不同的问题和需求。
PS: 开始之前给大家说一下,本文的修改内容涉及的改动比较多(我的教程会很详细的写),我也会出一期视频带大家从头到尾修改一遍,如果你还修改不对我也会提供修改完成版本的代码(直接训练运行即可),但是大家肯定想自己修改到自己的项目里如果你修改过程中的报错,我已经提供很完整的教程了(多种方案给大家选择),所以报错回复我只能是随缘回复(因为本文的内容肯定大家一堆报错会遇到稍微操作不当就是报错),同时本项目仅用于YOLOv8项目上,和本项目无关的报错一律不回复。
👑正式修改教程👑
2.1 修改一
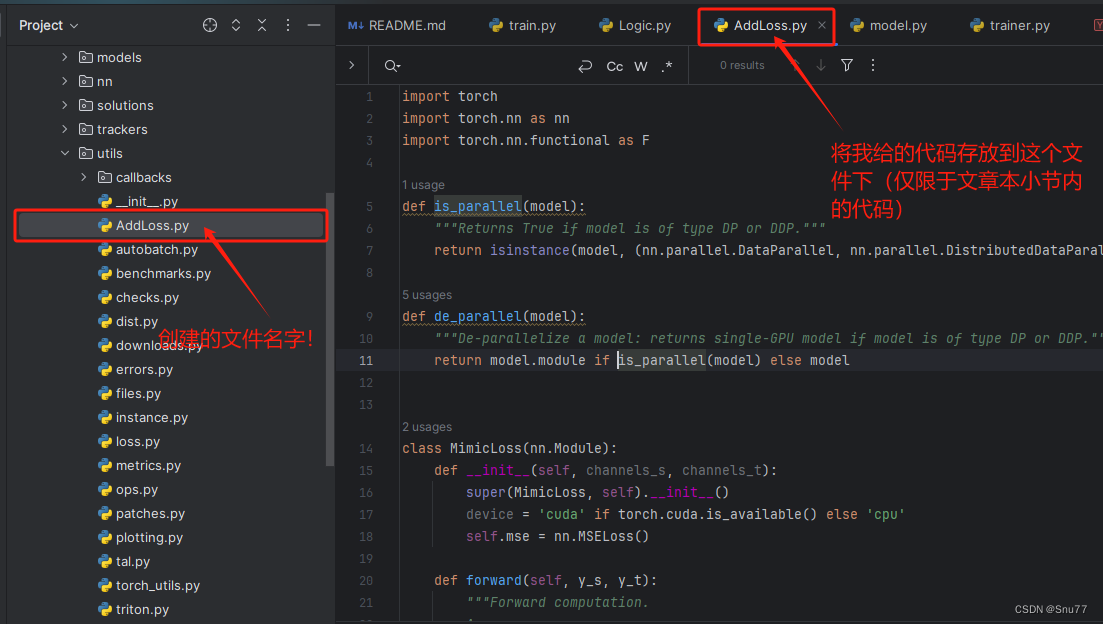
下面给出了一段代码,我们将这段代码找到目录'ultralytics/utils'下创建一个.py文件存放进去,文件的名字我们命名为AddLoss.py,创建好的文件如下图所示->
import torch
import torch.nn as nn
import torch.nn.functional as Fdef is_parallel(model):"""Returns True if model is of type DP or DDP."""return isinstance(model, (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel))def de_parallel(model):"""De-parallelize a model: returns single-GPU model if model is of type DP or DDP."""return model.module if is_parallel(model) else modelclass MimicLoss(nn.Module):def __init__(self, channels_s, channels_t):super(MimicLoss, self).__init__()device = 'cuda' if torch.cuda.is_available() else 'cpu'self.mse = nn.MSELoss()def forward(self, y_s, y_t):"""Forward computation.Args:y_s (list): The student model prediction withshape (N, C, H, W) in list.y_t (list): The teacher model prediction withshape (N, C, H, W) in list.Return:torch.Tensor: The calculated loss value of all stages."""assert len(y_s) == len(y_t)losses = []for idx, (s, t) in enumerate(zip(y_s, y_t)):assert s.shape == t.shapelosses.append(self.mse(s, t))loss = sum(losses)return lossclass CWDLoss(nn.Module):"""PyTorch version of `Channel-wise Distillation for Semantic Segmentation.<https://arxiv.org/abs/2011.13256>`_."""def __init__(self, channels_s, channels_t, tau=1.0):super(CWDLoss, self).__init__()self.tau = taudef forward(self, y_s, y_t):"""Forward computation.Args:y_s (list): The student model prediction withshape (N, C, H, W) in list.y_t (list): The teacher model prediction withshape (N, C, H, W) in list.Return:torch.Tensor: The calculated loss value of all stages."""assert len(y_s) == len(y_t)losses = []for idx, (s, t) in enumerate(zip(y_s, y_t)):assert s.shape == t.shapeN, C, H, W = s.shape# normalize in channel diemensionsoftmax_pred_T = F.softmax(t.view(-1, W * H) / self.tau, dim=1) # [N*C, H*W]logsoftmax = torch.nn.LogSoftmax(dim=1)cost = torch.sum(softmax_pred_T * logsoftmax(t.view(-1, W * H) / self.tau) -softmax_pred_T * logsoftmax(s.view(-1, W * H) / self.tau)) * (self.tau ** 2)losses.append(cost / (C * N))loss = sum(losses)return lossclass MGDLoss(nn.Module):def __init__(self, channels_s, channels_t, alpha_mgd=0.00002, lambda_mgd=0.65):super(MGDLoss, self).__init__()device = 'cuda' if torch.cuda.is_available() else 'cpu'self.alpha_mgd = alpha_mgdself.lambda_mgd = lambda_mgdself.generation = [nn.Sequential(nn.Conv2d(channel, channel, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(channel, channel, kernel_size=3, padding=1)).to(device) for channel in channels_t]def forward(self, y_s, y_t):"""Forward computation.Args:y_s (list): The student model prediction withshape (N, C, H, W) in list.y_t (list): The teacher model prediction withshape (N, C, H, W) in list.Return:torch.Tensor: The calculated loss value of all stages."""assert len(y_s) == len(y_t)losses = []for idx, (s, t) in enumerate(zip(y_s, y_t)):assert s.shape == t.shapelosses.append(self.get_dis_loss(s, t, idx) * self.alpha_mgd)loss = sum(losses)return lossdef get_dis_loss(self, preds_S, preds_T, idx):loss_mse = nn.MSELoss(reduction='sum')N, C, H, W = preds_T.shapedevice = preds_S.devicemat = torch.rand((N, 1, H, W)).to(device)mat = torch.where(mat > 1 - self.lambda_mgd, 0, 1).to(device)masked_fea = torch.mul(preds_S, mat)new_fea = self.generation[idx](masked_fea)dis_loss = loss_mse(new_fea, preds_T) / Nreturn dis_lossclass Distill_LogitLoss:def __init__(self, p, t_p, alpha=0.25):t_ft = torch.cuda.FloatTensor if t_p[0].is_cuda else torch.Tensorself.p = pself.t_p = t_pself.logit_loss = t_ft([0])self.DLogitLoss = nn.MSELoss(reduction="none")self.bs = p[0].shape[0]self.alpha = alphadef __call__(self):# per outputassert len(self.p) == len(self.t_p)for i, (pi, t_pi) in enumerate(zip(self.p, self.t_p)): # layer index, layer predictionsassert pi.shape == t_pi.shapeself.logit_loss += torch.mean(self.DLogitLoss(pi, t_pi))return self.logit_loss[0] * self.alphadef get_fpn_features(x, model, fpn_layers=[15, 18, 21]):y, fpn_feats = [], []with torch.no_grad():model = de_parallel(model)module_list = model.model[:-1] if hasattr(model, "model") else model[:-1]for m in module_list:# if not from previous layerif m.f != -1:x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersx = m(x)y.append(x if m.i in model.save else None) # save outputif m.i in fpn_layers:fpn_feats.append(x)return fpn_featsdef get_channels(model, fpn_layers=[15, 18, 21]):y, out_channels = [], []p = next(model.parameters())x = torch.zeros((1, 3, 64, 64), device=p.device)with torch.no_grad():model = de_parallel(model)module_list = model.model[:-1] if hasattr(model, "model") else model[:-1]for m in module_list:# if not from previous layerif m.f != -1:x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersx = m(x)y.append(x if m.i in model.save else None) # save outputif m.i in fpn_layers:out_channels.append(x.shape[1])return out_channelsclass FeatureLoss(nn.Module):def __init__(self, channels_s, channels_t, distiller='cwd'):super(FeatureLoss, self).__init__()device = 'cuda' if torch.cuda.is_available() else 'cpu'self.align_module = nn.ModuleList([nn.Conv2d(channel, tea_channel, kernel_size=1, stride=1, padding=0).to(device)for channel, tea_channel in zip(channels_s, channels_t)])self.norm = [nn.BatchNorm2d(tea_channel, affine=False).to(device)for tea_channel in channels_t]if distiller == 'mimic':self.feature_loss = MimicLoss(channels_s, channels_t)elif distiller == 'mgd':self.feature_loss = MGDLoss(channels_s, channels_t)elif distiller == 'cwd':self.feature_loss = CWDLoss(channels_s, channels_t)else:raise NotImplementedErrordef forward(self, y_s, y_t):assert len(y_s) == len(y_t)tea_feats = []stu_feats = []for idx, (s, t) in enumerate(zip(y_s, y_t)):s = self.align_module[idx](s)s = self.norm[idx](s)t = self.norm[idx](t)tea_feats.append(t)stu_feats.append(s)loss = self.feature_loss(stu_feats, tea_feats)return loss2.2 修改二
下面的代码我们找到文件'ultralytics/engine/trainer.py'按照我的图片内容复制粘贴到指定位置即可!根据下图进行修改->
在该文件的开头我们先添加两行模块的导入代码,
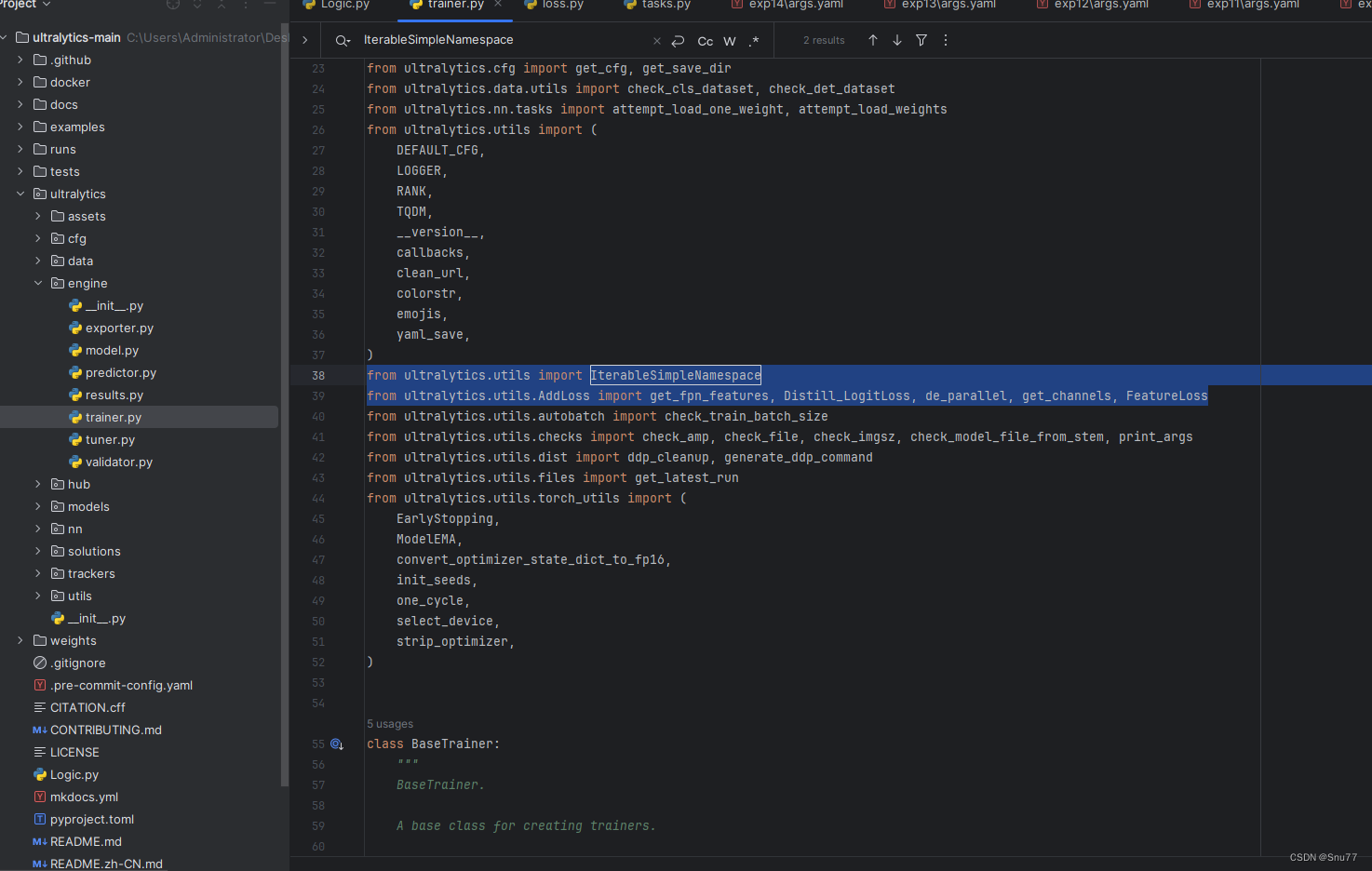
from ultralytics.utils import IterableSimpleNamespace
from ultralytics.utils.AddLoss import get_fpn_features, Distill_LogitLoss, de_parallel, get_channels, FeatureLoss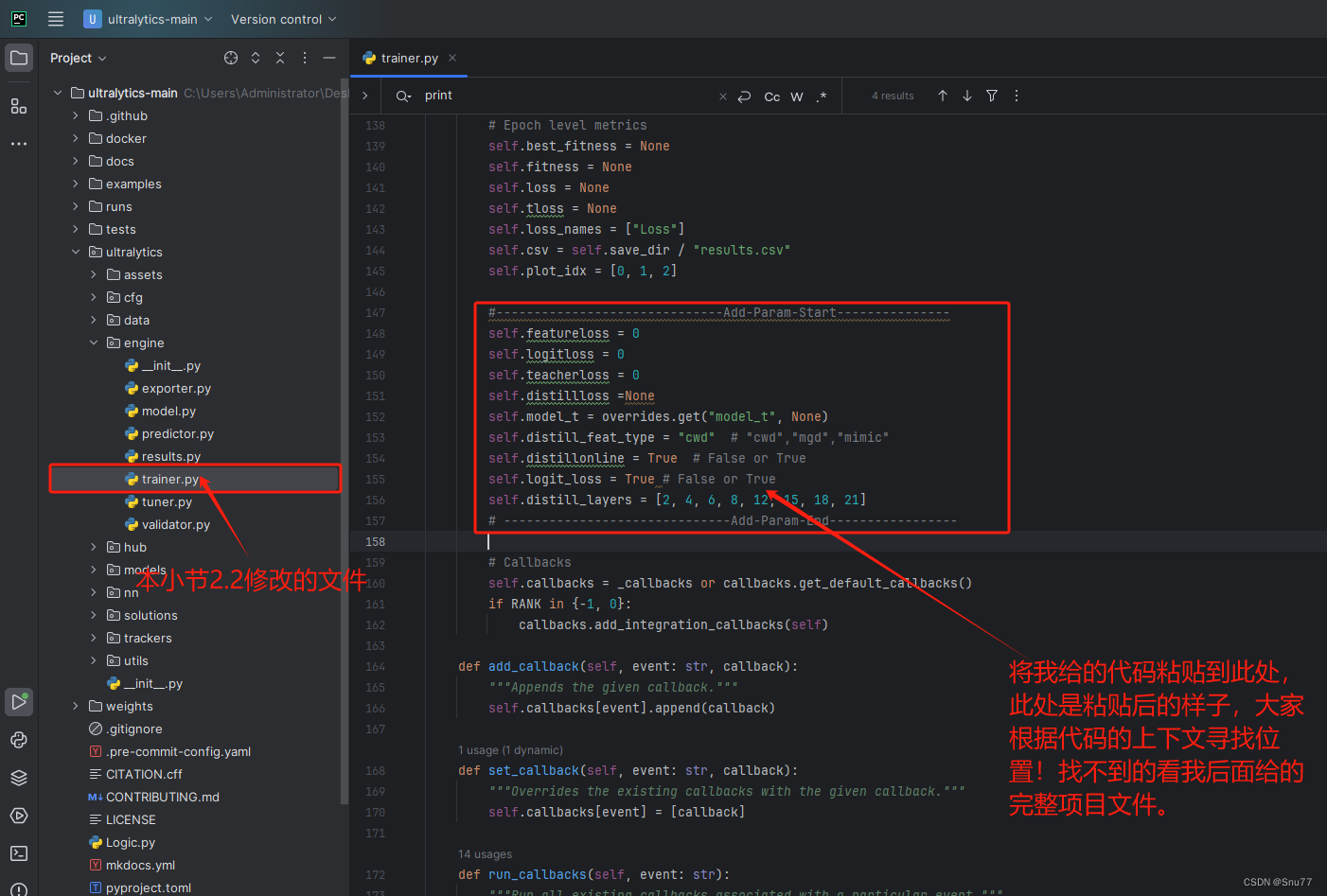
#------------------------------Add-Param-Start---------------self.featureloss = 0self.logitloss = 0self.teacherloss = 0self.distillloss =Noneself.model_t = overrides.get("model_t", None)self.distill_feat_type = "cwd" # "cwd","mgd","mimic"self.distillonline = False # False or Trueself.logit_loss = False # False or Trueself.distill_layers = [2, 4, 6, 8, 12, 15, 18, 21]# ------------------------------Add-Param-End-----------------2.3 修改三
按照图片进行修改即可。
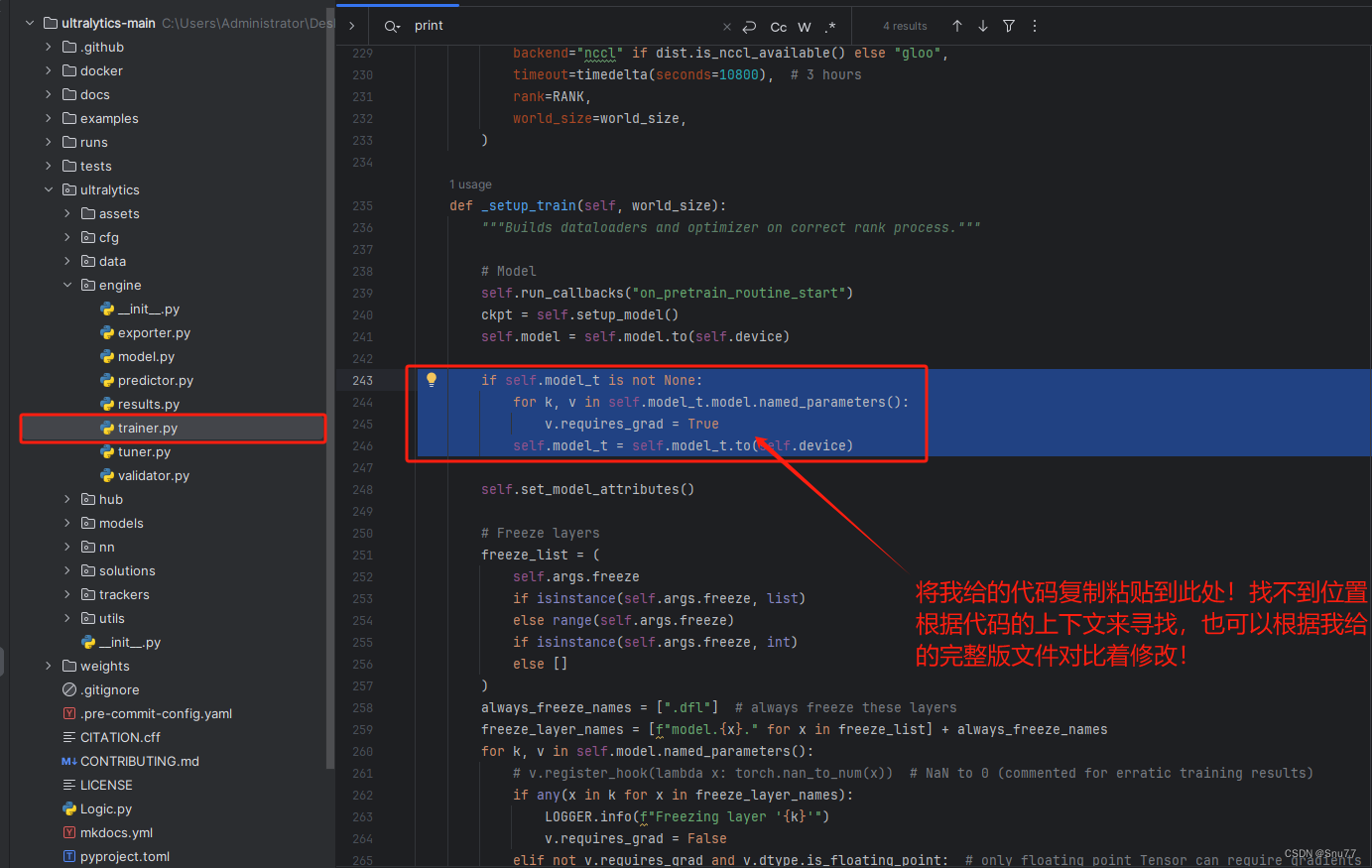
if self.model_t is not None:for k, v in self.model_t.model.named_parameters():v.requires_grad = Trueself.model_t = self.model_t.to(self.device)
2.4 修改四
按照图片进行修改即可。

if self.model_t is not None:self.model_t = nn.parallel.DistributedDataParallel(self.model_t, device_ids=[RANK])2.5 修改五
此处的修改和上面有些不一样,上面的代码都是添加,此处的代码为替换。
self.optimizer = self.build_optimizer(model=self.model,model_t=self.model_t,distillloss=self.distillloss,distillonline=self.distillonline,name=self.args.optimizer,lr=self.args.lr0,momentum=self.args.momentum,decay=weight_decay,iterations=iterations)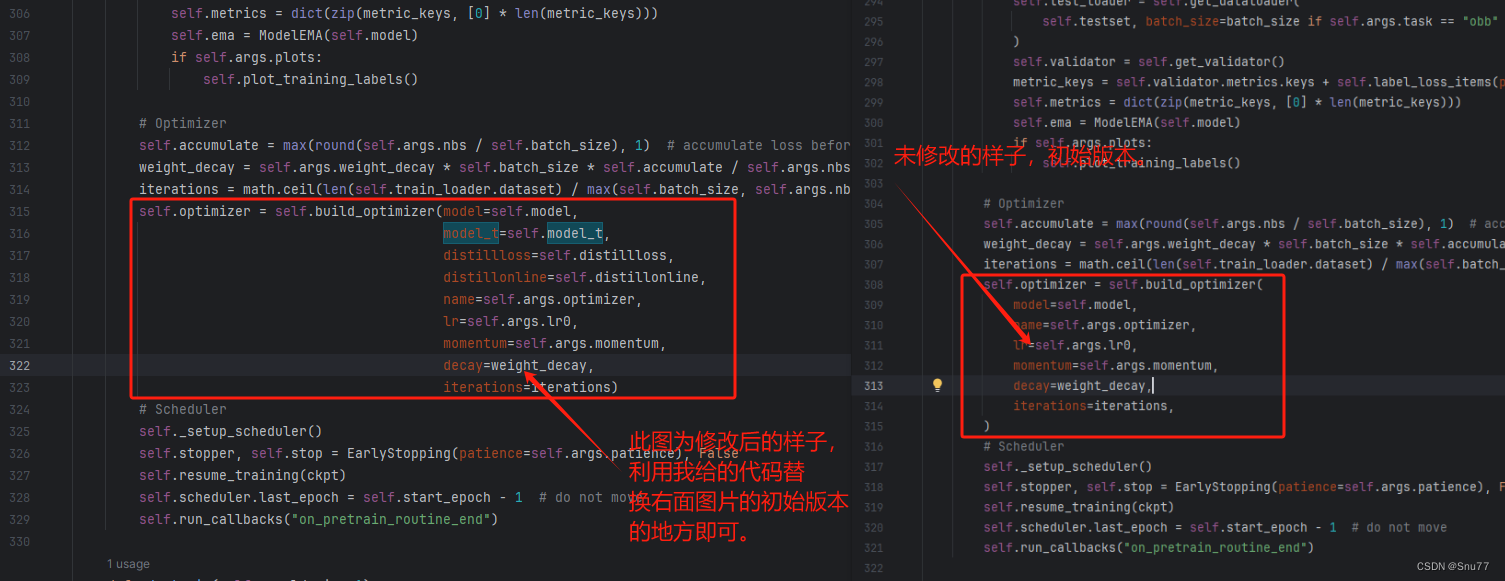
2.6 修改六
修改教程看图片!
self.model = de_parallel(self.model)if self.model_t is not None:self.model_t = de_parallel(self.model_t)self.channels_s = get_channels(self.model,self.distill_layers)self.channels_t = get_channels(self.model_t,self.distill_layers)self.distillloss = FeatureLoss(channels_s=self.channels_s, channels_t=self.channels_t, distiller= self.distill_feat_type)

2.7 修改七
修改教程看图片!
if self.model_t is not None:self.model_t.eval()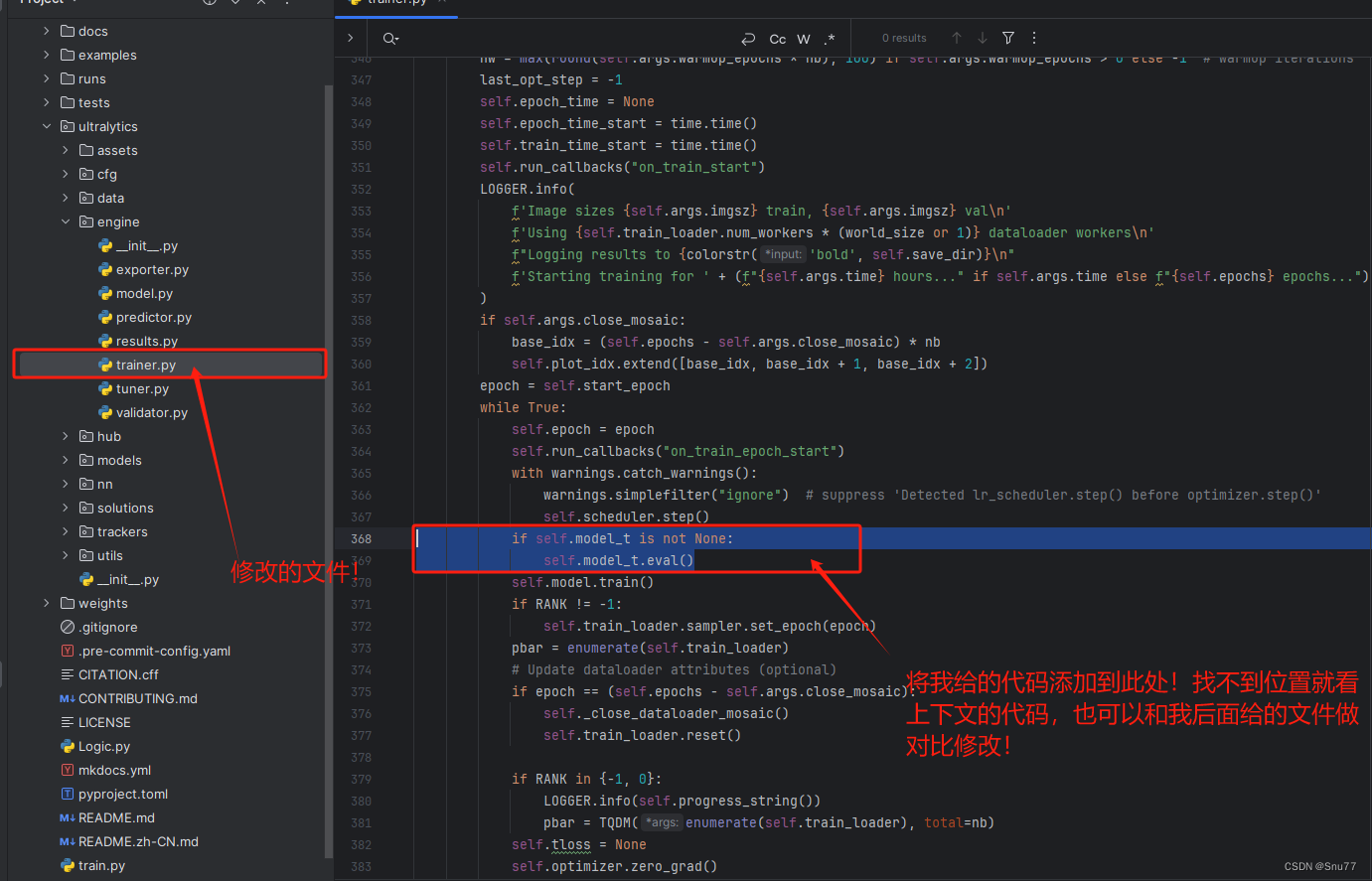
2.8 修改八
修改教程看图片!
pred_s= self.model(batch['img'])stu_features = get_fpn_features(batch['img'], self.model,fpn_layers=self.distill_layers)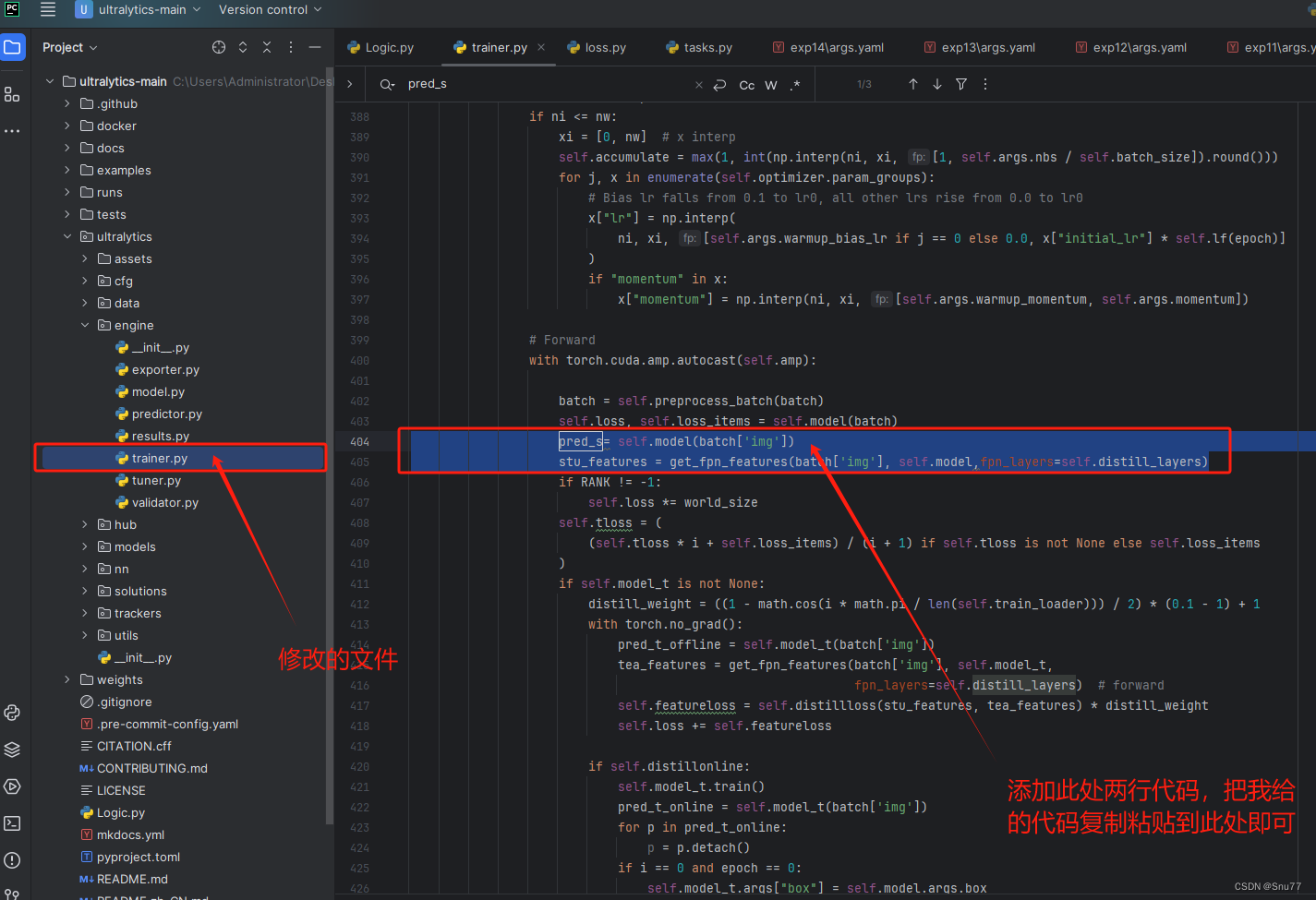
2.8 修改九
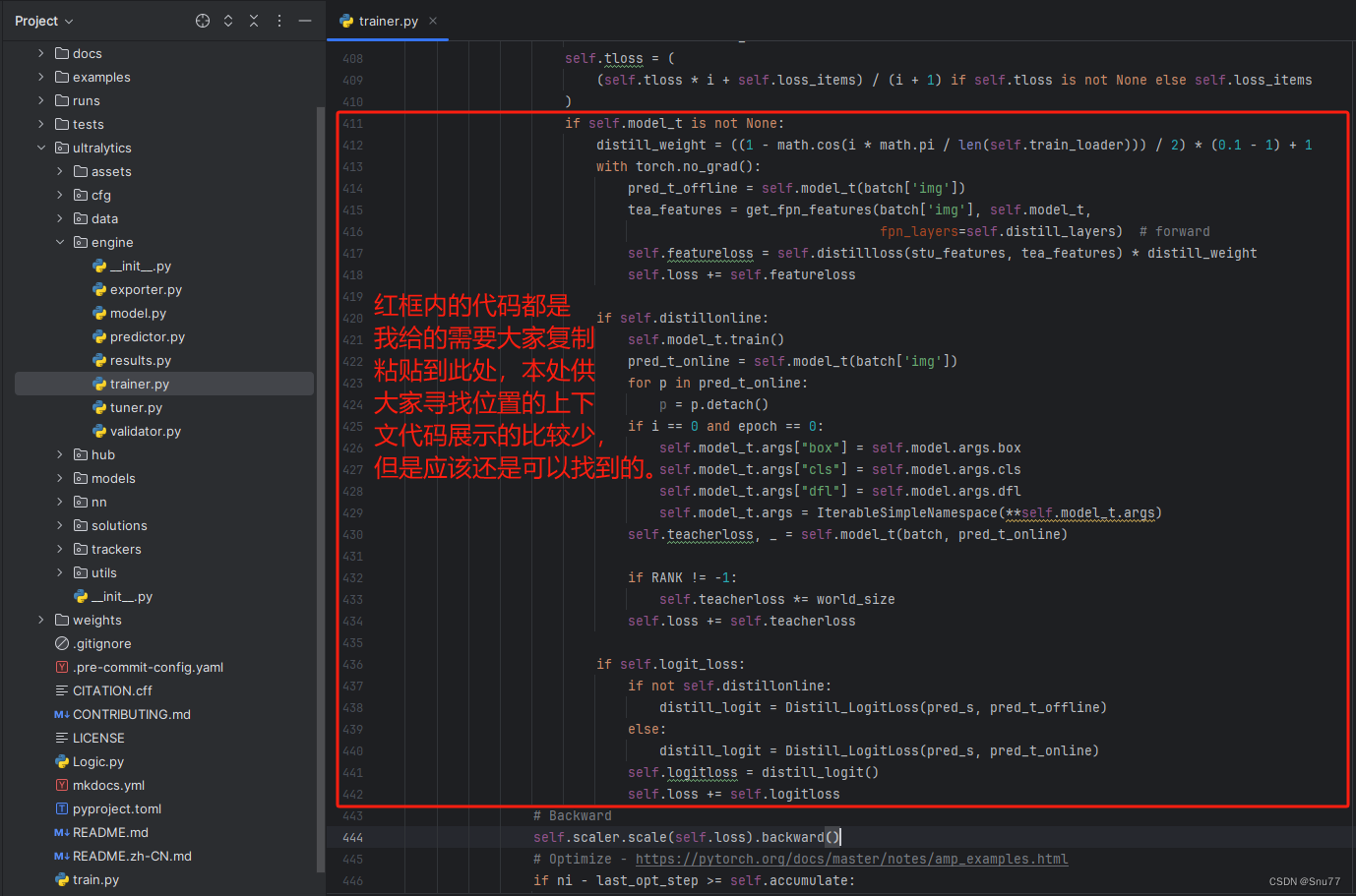
if self.model_t is not None:distill_weight = ((1 - math.cos(i * math.pi / len(self.train_loader))) / 2) * (0.1 - 1) + 1with torch.no_grad():pred_t_offline = self.model_t(batch['img'])tea_features = get_fpn_features(batch['img'], self.model_t,fpn_layers=self.distill_layers) # forwardself.featureloss = self.distillloss(stu_features, tea_features) * distill_weightself.loss += self.featurelossif self.distillonline:self.model_t.train()pred_t_online = self.model_t(batch['img'])for p in pred_t_online:p = p.detach()if i == 0 and epoch == 0:self.model_t.args["box"] = self.model.args.boxself.model_t.args["cls"] = self.model.args.clsself.model_t.args["dfl"] = self.model.args.dflself.model_t.args = IterableSimpleNamespace(**self.model_t.args)self.teacherloss, _ = self.model_t(batch, pred_t_online)if RANK != -1:self.teacherloss *= world_sizeself.loss += self.teacherlossif self.logit_loss:if not self.distillonline:distill_logit = Distill_LogitLoss(pred_s, pred_t_offline)else:distill_logit = Distill_LogitLoss(pred_s, pred_t_online)self.logitloss = distill_logit()self.loss += self.logitloss2.9 修改十
修改教程看图片!
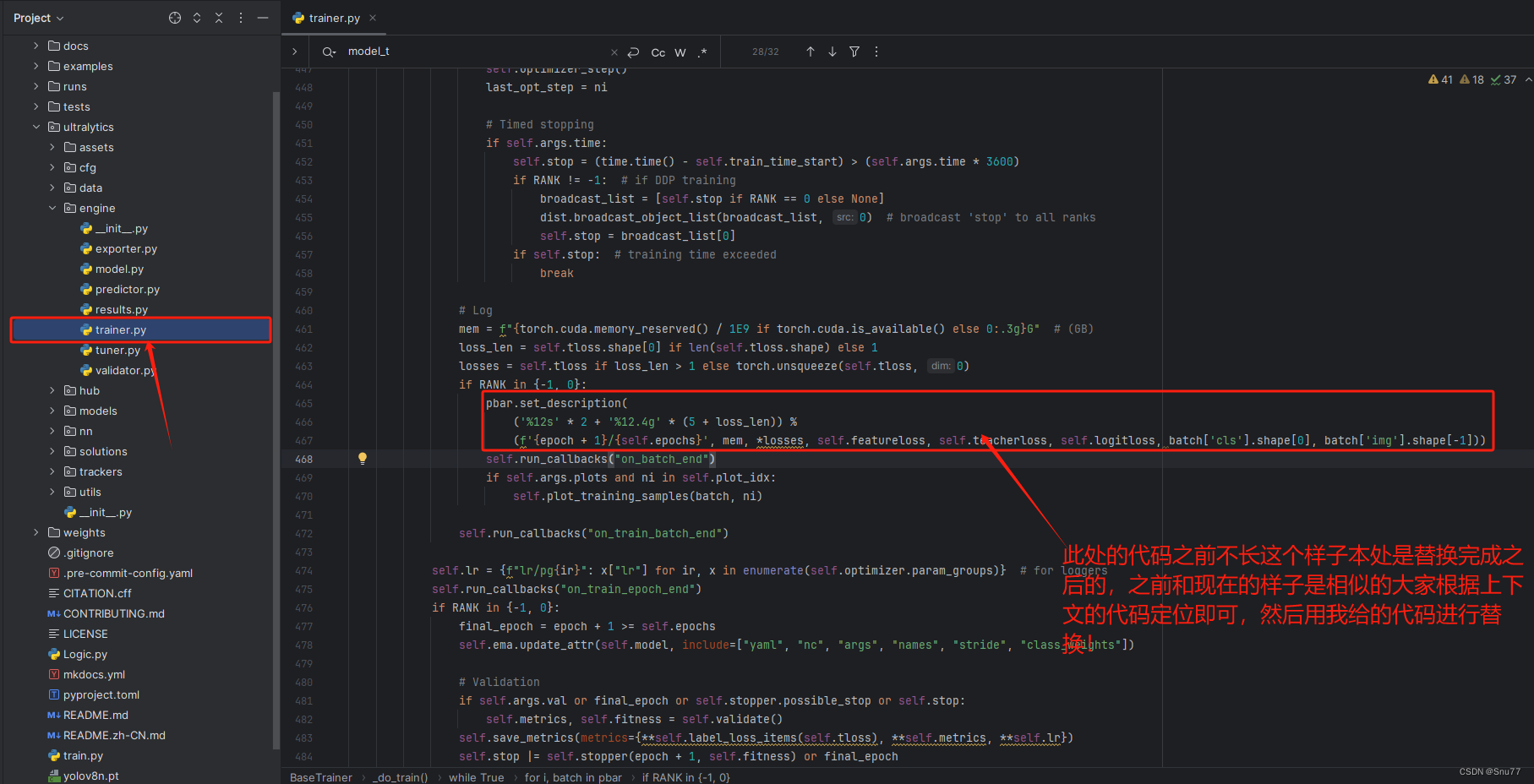
pbar.set_description(('%12s' * 2 + '%12.4g' * (5 + loss_len)) %(f'{epoch + 1}/{self.epochs}', mem, *losses, self.featureloss, self.teacherloss, self.logitloss, batch['cls'].shape[0], batch['img'].shape[-1]))2.10 修改十一
修改教程看图片!
, model_t, distillloss, distillonline=False,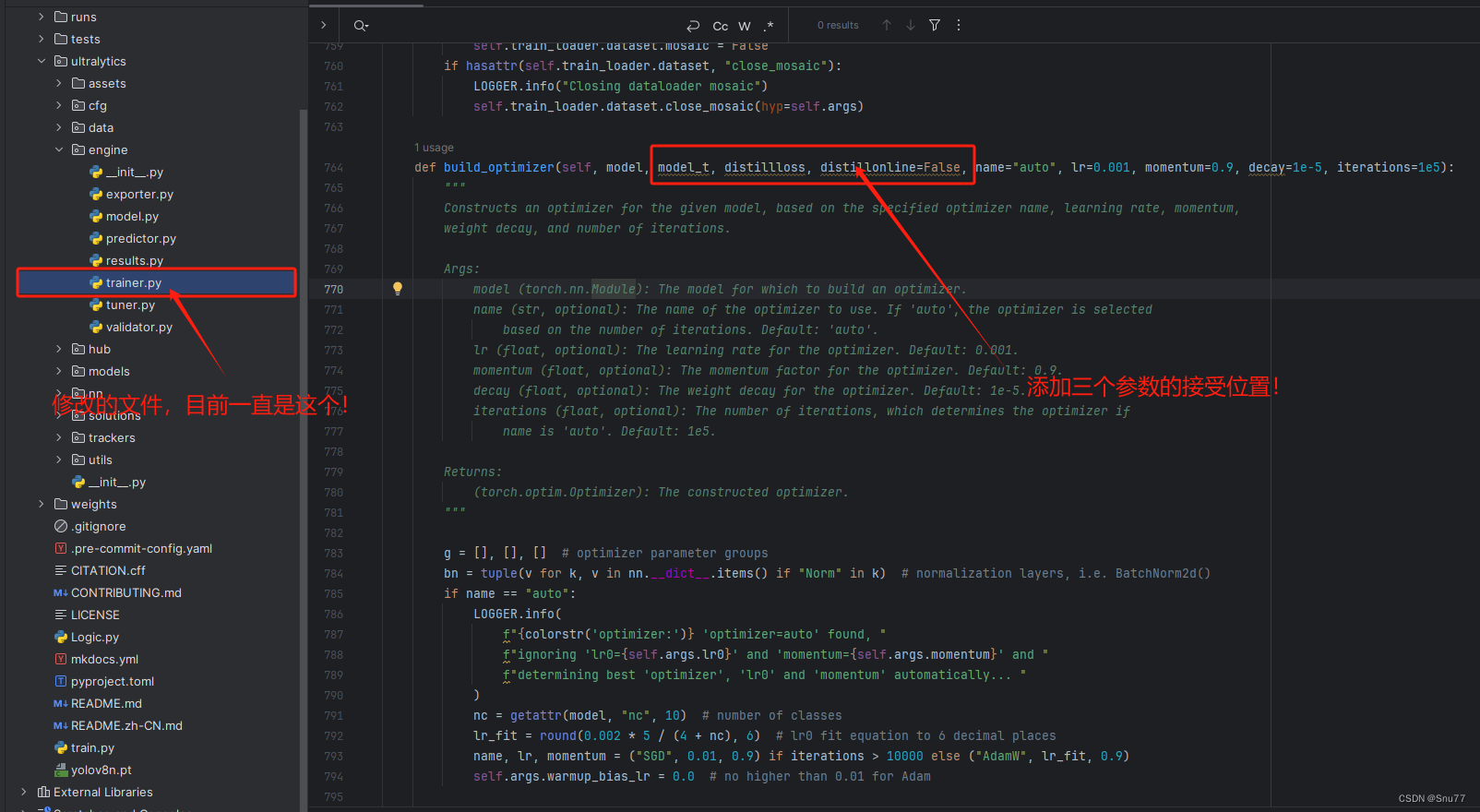
2.11 修改十二
修改教程看图片!
if model_t is not None and distillonline:for v in model_t.modules():# print(v)if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias (no decay)g[2].append(v.bias)if isinstance(v, bn): # weight (no decay)g[1].append(v.weight)elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)g[0].append(v.weight)if model_t is not None and distillloss is not None:for k, v in distillloss.named_modules():# print(v)if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias (no decay)g[2].append(v.bias)if isinstance(v, bn) or 'bn' in k: # weight (no decay)g[1].append(v.weight)elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)g[0].append(v.weight)

2.12 修改十三
PS:注意此处我们更换了修改的文件了!!
我们找到文件'ultralytics/cfg/__init__.py',按照我的图片进行修改!

2.13 修改十四
PS:注意此处我们更换了修改的文件了!!
我们找到文件'ultralytics/models/yolo/detect/train.py'按照图片进行修改即可!
return ('\n' + '%12s' *(7 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'dfeaLoss', 'dlineLoss', 'dlogitLoss', 'Instances','Size')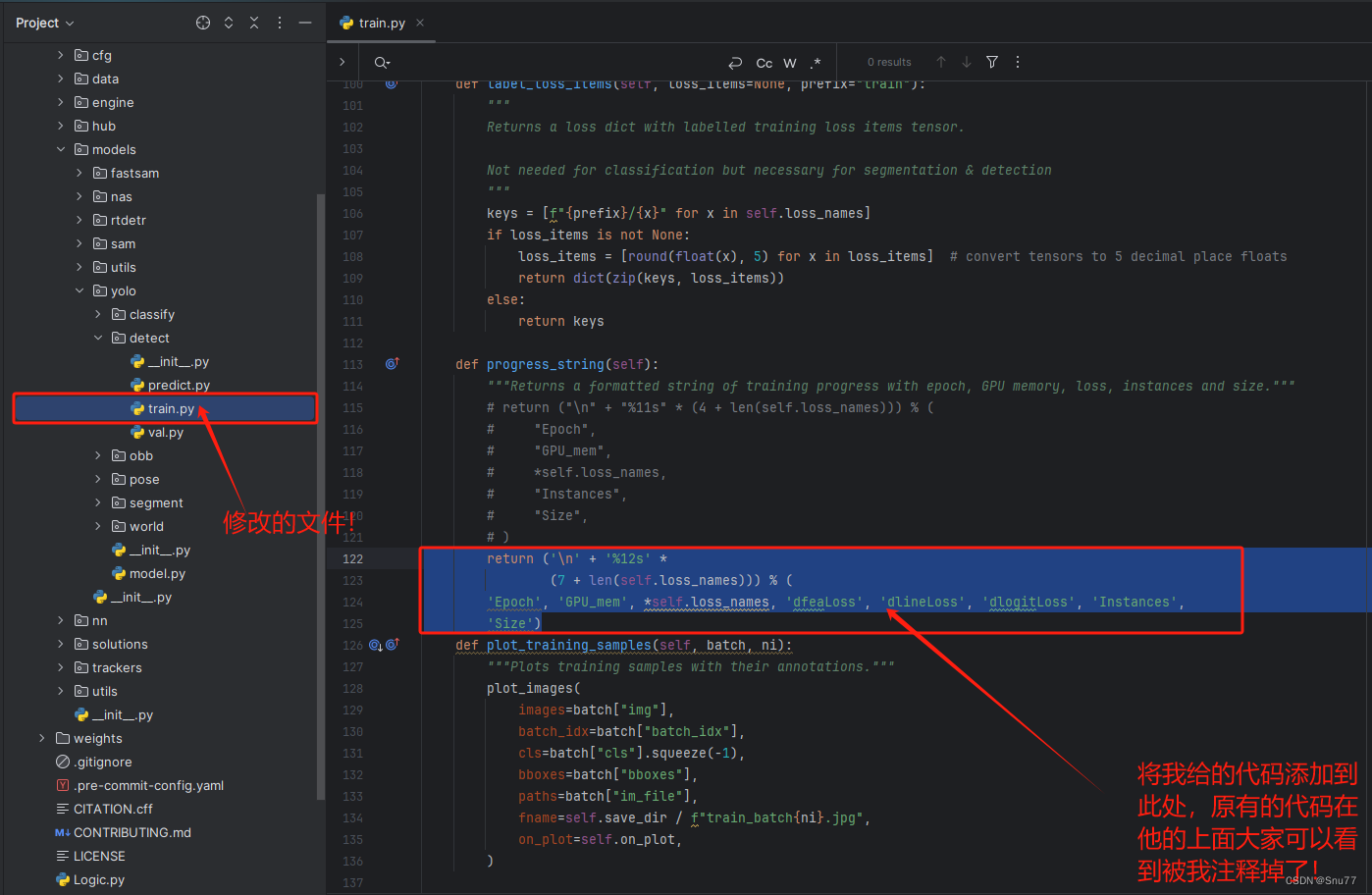
2.14 修改十五
PS:注意此处我们更换了修改的文件了!!
我们找到文件'ultralytics/engine/model.py'按照图片进行修改即可!
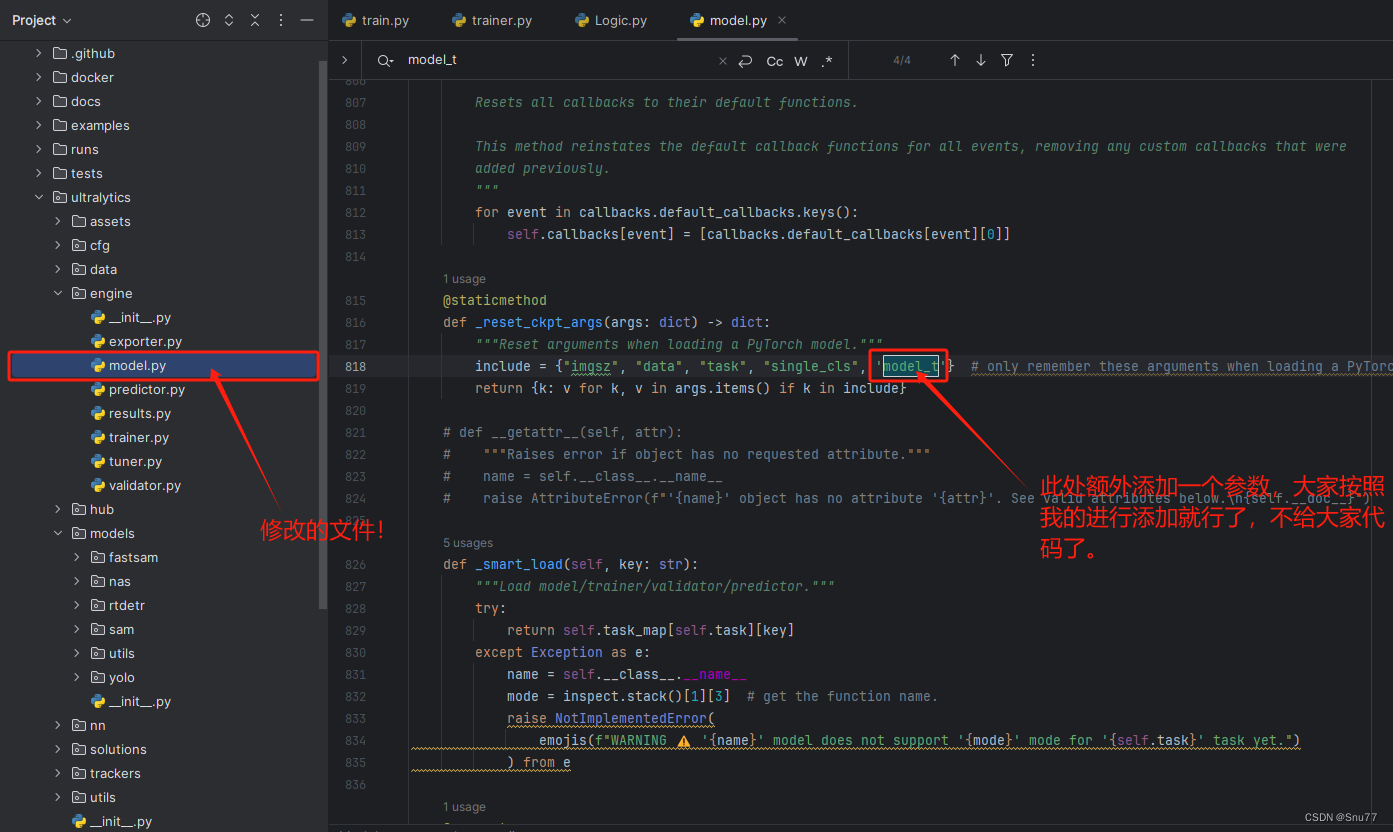
到此处就修改完成了,剩下的就是如何使用进行模型蒸馏了!
三、使用教程
模型蒸馏指的是:用训练好的模型(注意是训练好的模型)去教另一个模型!(其中教师模型必须是训练好的权重,学生模型可以是yaml文件也可以是权重文件地址)
在开始之前我们需要准备一个教师模型,我们这里就用YOLOv8l为例,其权重文件可以去官方下载。
3.1 模型蒸馏代码
PS:需要注意的是,学生模型和教师模型的模型配置文件需要保持一致,也就是说你学生模型假设用了BiFPN那么你的教师模型也需要用BiFPN去训练否则就会报错!
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':model_t = YOLO(r'weights/yolov8l.pt') # 此处填写教师模型的权重文件地址model_t.model.model[-1].set_Distillation = True # 不用理会此处用于设置模型蒸馏model_s = YOLO(r'ultralytics/cfg/models/v8/yolov8.yaml') # 学生文件的yaml文件 or 权重文件地址model_s.train(data=r'C:\Users\Administrator\Desktop\Snu77\ultralytics-main\New_GC-DET\data.yaml', # 将data后面替换你自己的数据集地址cache=False,imgsz=640,epochs=100,single_cls=False, # 是否是单类别检测batch=1,close_mosaic=10,workers=0,device='0',optimizer='SGD', # using SGDamp=True, # 如果出现训练损失为Nan可以关闭ampproject='runs/train',name='exp',model_t=model_t.model)
3.2 开始蒸馏
我们将蒸馏的代码复制粘贴到一个py文件内,如下图所示!
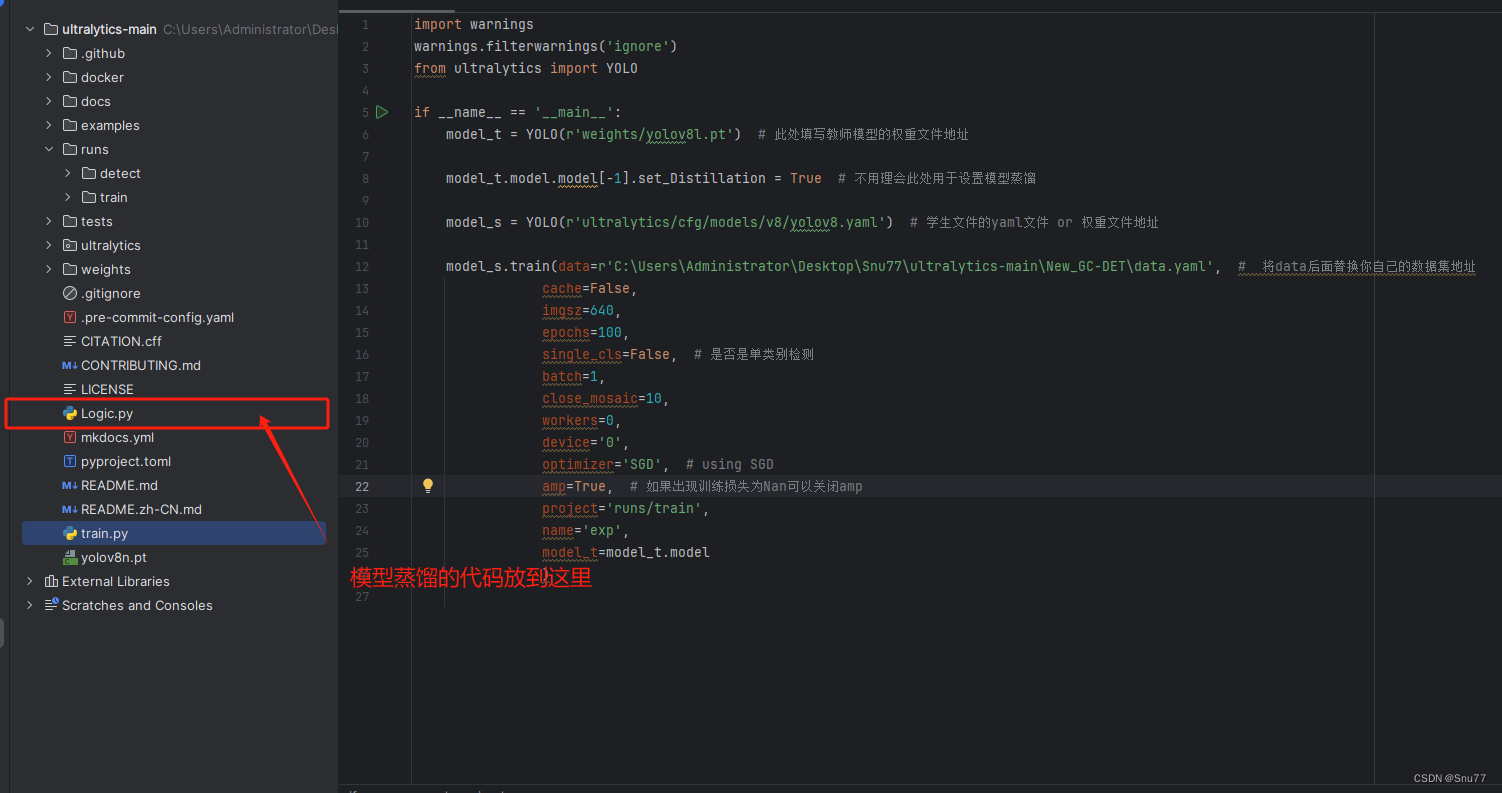
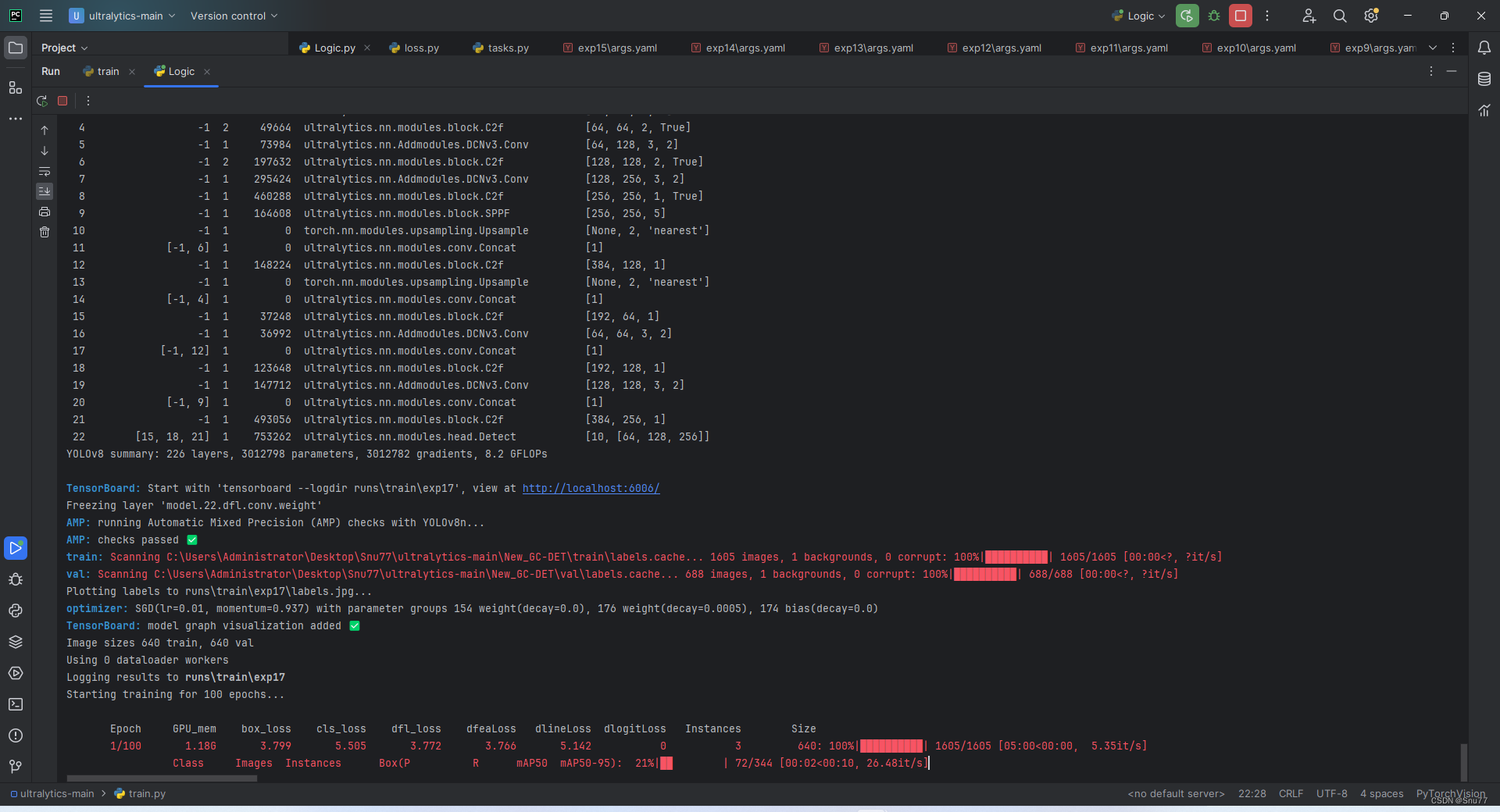
我们运行蒸馏的py文件即可,模型就会开始训练并且蒸馏。下面的图片就是模型开始训练并且蒸馏,可以看到我们开启了蒸馏损失'dfeaLoss dlineLoss'
四、完整文件和视频讲解
百度网盘因为链接很容易过期,如果下面文件过期大家可以提醒我,或者进群,群内我也会上传!
链接:https://pan.baidu.com/s/1_gwwemBDPF6YEoyO2BkTlA?pwd=j8uq
提取码:j8uq
四、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备