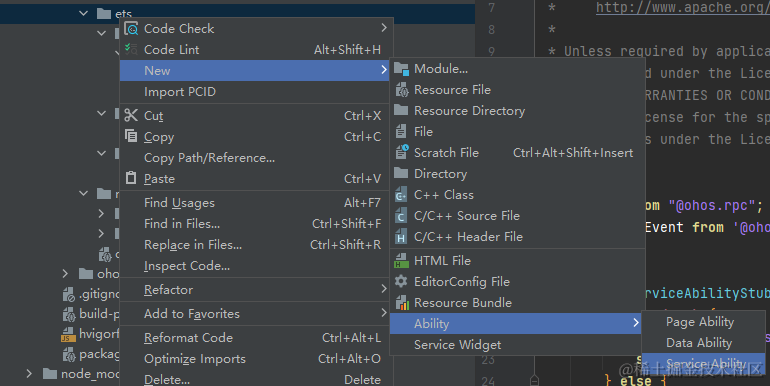
初创企业需要建站的朋友看这篇文章,谢谢支持:我给不会敲代码又想搭建网站的人建议
(接上一篇。。。)
排名
经过搜索引擎蜘蛛抓取页面,索引程序计算得到倒排索引后,搜索引擎就准备好可以随时处理用户搜索了。用户在搜索框填入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程是与用户直接互动的。
1、搜索词处理
搜索引擎接收到用户输入的搜索词后,需要对搜索词做一些处理,才能进入排名过程。
搜索词处理包括如下几方面。
(1) 中文分词。与页面索引时一样,搜索词也必须进行中文分词,将查询字符串转换为以词为基础的关键词组合。分词原理与页面分词相同。
(2)去停止词。和索引时一样,搜索引擎也需要把搜索词中的停止词去掉,最大限度地提高排名相关性及效率。
(3)指令处理。查询词完成分词后,搜索引擎的默认处理方式是在关键词之间使用“与”逻辑。也就是说用户搜索“减肥方法”时,程序分词为“减肥”和“方法”两个词,搜索引擎排序时默认认为,用户寻找的是既包含“减肥”,也包含“方法”的页面。只包含“减肥”不包含“方法”,或者只包含“方法”不包含“减肥”的页面,被认为是不符合搜索条件的。
当然,这只是极为简化的为了说明原理的说法,实际上我们还是会看到只
包含一部分关键词的搜索结果。
另外用户输入的查询词还可能包含一些高级搜索指令,如加号、减号等,搜索引擎都需要做出识别和相应处理。有关高级搜索指令,后面还有详细说明。
(4)拼写错误矫正。用户如果输入了明显错误的字或英文单词拼错,搜索引擎会提示用户正确的用字或拼法,如下图所示。

(5)整合搜索触发。某些搜索词会触发整合搜索,比如明星姓名就经常触发图片和视频内容,当前的热门话题又容易触发资讯内容。哪些词触发哪些整合搜索,也需要在搜索词处理阶段计算。
2、文件匹配
搜索词经过处理后,搜索引擎得到的是以词为基础的关键词集合。文件匹配阶段就是找出含有所有关键词的文件。在索引部分提到的倒排索引使得文件匹配能够快速完成,如下表所示。

假设用户搜索“关键词2关键词7”,排名程序只要在倒排索引中找到“关键词2”和“关键词7”这两个词,就能找到分别含有这两个词的所有页面。经过简单计算就能找出既包含“关键词2”,也包含“关键词7”的所有页面:文件1和文件6。
3、初始子集的选择
找到包含所有关键词的匹配文件后,还不能进行相关性计算,因为找到的文件经常会有几十万几百万,甚至上千万个。要对这么多文件实时进行相关性计算,需要的时间还是比较长的。
实际上用户并不需要知道所有匹配的几十万、几百万个页面,绝大部分用户只会查看前两页,也就是前20个结果。搜索引擎也并不需要计算这么多页面的相关性,而只要计算最重要的一部分页面就可以了。常用搜索引擎的人都会注意到,搜索结果页面通常最多显示100个。用户点击搜索结果页面底部的“下一页”链接,最多也只能看到第100页,也就是1000个搜索结果,百度则通常返回76页结果。
所以搜索引擎只需要计算前1000个结果的相关性,就能满足要求。
但问题在于,还没有计算相关性时,搜索引擎又怎么知道哪一千个文件是最相关的?所以用于最后相关性计算的初始页面子集的选择,必须依靠其他特征而不是相关性,其中最主要的就是页面权重。由于所有匹配文件都已经具备了最基本的相关性(这些文件都包含所有查询关键词),搜索引擎通常会用非相关性的页面特征选出一个初始子集。初始子集的数目是多少?几万个?或许更多,外人并不知道。不过可以肯定的是,当匹配页面数目巨大时,搜索引擎不会对这么多页面进行计算,而必须选出页面权重较高的一个子集,再对子集中的页面进行相关性计算。
4、相关性计算
选出初始子集后,对子集中的页面计算关键词相关性。计算相关性是排名过程中最重要的一步。相关性计算是搜索引擎算法中最令SEO 感兴趣的部分。
影响相关性的主要因素包括如下几方面。
(1)关键词常用程度。经过分词后的多个关键词,对整个搜索字符串的意义贡献并不相同。越常用的词对搜索词的意义贡献越小,越不常用的词对搜索词的意义贡献越大。举个例子,假设用户输入的搜索词是“我们冥王星”。“我们”这个词常用程度非常高,在很多页面上会出现,它对“我们冥王星”这个搜索词的辨识程度和意义相关度贡献就很小。
找出那些包含“我们”这个词的页面,对搜索排名相关性几乎没有什么影响,有太多页面包含“我们”这个词。
而“冥王星”这个词常用程度就比较低,对“我们冥王星”这个搜索词的意义贡献要大得多。那些包含“冥王星”这个词的页面,对“我们冥王星”这个搜索词会更为相关。
常用词的极致就是停止词,对页面意义完全没有影响。
所以搜索引擎对搜索词串中的关键词并不是一视同仁地处理,而是根据常用程度进行加权。不常用的词加权系数高,常用词加权系数低,排名算法对不常用的词给予更多关注。
我们假设A、B两个页面都各出现“我们”及“冥王星”两两个词。但是“我们”这个词在A页面出现于普通文字中,“冥王星”这个词在A页面出现于标题标签中。B页面正相反,“我们”出现在标题标签中,而“冥王星”出现在普通文字中。那么针对“我们冥王星”这个搜索词,A页面将更相关。
(2)词频及密度。一般认为在没有关键词堆积的情况下,搜索词在页面中出现的次数多,密度越高,说明页面与搜索词越相关。当然这只是一个大致规律,实际情况未必如此,所以相关性计算还有其他因素。出现频率及密度只是因素的一部分,而且重要程度越来越低。
(3)关键词位置及形式。就像在索引部分中提到的,页面关键词出现的格式和位置都被记录在索引库中。关键词出现在比较重要的位置,如标题标签、黑体、H1等,说明页面与关键词越相关。这一部分就是页面 SEO所要解决的。
(4)关键词距离。切分后的关键词完整匹配地出现,说明与搜索词最相关。比如搜索“减肥方法”时,页面上连续完整出现“减肥方法”四个字是最相关的。如果“减肥”和“方法”两个词没有连续匹配出现,出现的距离近一些,也被搜索引擎认为相关性稍微大一些。
*(5)链接分析及页面权重。*除了页面本身的因素,页面之间的链接和权重关系也影响关键词的相关性,其中最重要的是锚文字。页面有越多以搜索词为锚文字的导入链接,说明页面的相关性越强。
链接分析还包括了链接源页面本身的主题、锚文字周围的文字等。
5、排名过滤及调整
选出匹配文件子集、计算相关性后,大体排名就已经确定了。之后搜索引擎可能还有一些过滤算法,对排名进行轻微调整,其中最主要的过滤就是施加惩罚。一些有作弊嫌疑的页面,虽然按照正常的权重和相关性计算排到前面,但搜索引擎的惩罚算法却可能在最后一步把这些页面调到后面去。典型的例子是百度的11位,Google 的负6、负30、负950等算法。
6、排名显示
所有排名确定后,排名程序调用原始页面的标题标签、说明标签、快照日期等数据显示在页面上。有时搜索引擎需要动态生成页面摘要,而不是调用页面本身的说明标签。
7、搜索缓存
用户搜索的关键词有很大一部分是重复的。按照2/8定律,20%的搜索词占到了总搜索次数的80%。按照长尾理论,最常见的搜索词没有占到80%那么多,但通常也有一个比较粗大的头部,很少一部分搜索词占到了所有搜索次数的很大一部分。尤其是有热门新闻
发生时,每天可能有几百万人搜索完全相同的关键词。
如果每次搜索都重新处理排名可以说是很大的浪费。搜索引擎会把最常见的搜索词存入缓存,用户搜索时直接从缓存中调用,而不必经过文件匹配和相关性计算,大大提高了排名效率,缩短了搜索反应时间。
8、查询及点击日志
搜索用户的IP地址、搜索的关键词、搜索时间,以及点击了哪些结果页面,搜索引擎都记录形成日志。这些日志文件中的数据对搜索引擎判断搜索结果质量、调整搜索算法、预期搜索趋势等都有重要意义。
上面我们简单介绍了搜索引擎的工作过程。当然实际搜索引擎的工作步骤与算法是非常复杂的。上面的说明很简单,但其中有很多技术难点。
搜索引擎还在不断优化算法,优化数据库格式。不同搜索引擎的工作步骤也会有差异。但大致上所有主流搜索引擎的基本工作原理都是如此,在过去几年及可以预期的未来几年,都不会有实质性的改变。
(完)