概述
在机器学习中,模型评价是评估和比较不同模型性能的关键步骤之一。它是通过对模型的预测结果与真实标签进行比较,从而量化模型的预测能力、泛化能力和稳定性。模型评价旨在选择最佳的模型,理解模型的行为,并为模型的改进提供指导。
本文将介绍机器学习中常用的模型评价方法,包括基本流程、常见的评价指标以及这些评价方法的优缺点。此外,将使用Python实现这些模型评价方法,并通过可视化展示评价结果。
基本流程
机器学习模型评价的基本流程如下:
- 数据准备:将数据集划分为训练集和测试集,确保模型在未见过的数据上进行评估。
- 选择模型:选择待评估的模型,可以是分类模型、回归模型或其他类型的机器学习模型。
- 训练模型:使用训练集对选定的模型进行训练,调整模型参数以达到最佳性能。
- 模型评价:使用测试集对训练好的模型进行评价,计算评价指标以量化模型性能。
- 结果分析:分析评价结果,理解模型的表现,确定是否需要进一步改进模型。
常见的模型评价方法
在模型评价过程中,常见的模型评价方法包括:
- 准确率(Accuracy):即模型预测正确的样本数与总样本数的比例,适用于平衡类别的分类问题。
- 精确率(Precision):预测为正类别且实际为正类别的样本数与所有预测为正类别的样本数的比例,衡量模型预测为正类别的准确性。
- 召回率(Recall):预测为正类别且实际为正类别的样本数与所有实际为正类别的样本数的比例,衡量模型捕捉正类别样本的能力。
- F1分数(F1 Score):精确率和召回率的调和平均数,综合考虑了模型的准确性和全面性。
- ROC曲线与AUC值(ROC Curve and AUC):ROC曲线是以假正例率(False Positive Rate)为横轴,真正例率(True Positive Rate)为纵轴绘制的曲线,AUC值是ROC曲线下的面积,用于衡量模型分类的能力。
- 混淆矩阵(Confusion Matrix):列出模型预测结果与真实标签的对应关系,直观地展示模型的分类情况。
方法的优缺点
- 准确率:简单直观,但无法反映不同类别之间的不平衡。
- 精确率与召回率:可以针对不同类别进行评价,但在样本不平衡的情况下,可能无法全面评估模型性能。
- F1分数:综合考虑了精确率和召回率,但对模型预测结果的权衡关系较为敏感。
- ROC曲线与AUC值:能够直观地反映模型的分类能力,但对类别平衡和不平衡的数据都有效。
- 混淆矩阵:直观地展示了模型的分类情况,但不直接提供数值评价指标。
Python实现模型评价
接下来,将使用Python实现常见的模型评价方法,并通过可视化展示评价
结果。
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_curve, auc, confusion_matrix# 创建示例数据集
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 使用逻辑回归模型进行训练
model = LogisticRegression()
model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1]# 计算评价指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)# 绘制ROC曲线
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
roc_auc = auc(fpr, tpr)plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()# 绘制混淆矩阵
conf_mat = confusion_matrix(y_test, y_pred)
plt.imshow(conf_mat, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('Confusion Matrix')
plt.colorbar()
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()# 输出评价结果
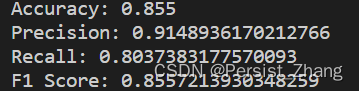
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
print("F1 Score:", f1)


总结
模型评价是机器学习中至关重要的一环,它能够帮助我们全面理解和评估模型的性能,为模型的改进和优化提供指导。在选择合适的评价方法时,需要根据具体问题和数据特点进行综合考虑,综合利用不同的评价指标,以全面客观地评价模型的性能。通过本文的介绍和示例代码,希望读者能够更加深入地理解模型评价的概念、方法和应用。