1. unordered系列关联式容器
STL提供了底层为红黑树结构的一系列关联式容
这里介绍 unordered_set 和 unordered_map
a. unordered_map
- unordered_map 是存储<key, value>键值对的关联式容器,其允许通过 key 快速的索引到与
其对应的 value
- unordered_map 容器通过 key 访问单个元素要比 map 快,但它通常在遍历元素子集的范围迭
代方面效率较低
- unordered_map 实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问value
- 它的迭代器至少是前向迭代器
- 重复数据可以去重
b. unordered_set
- unordered_set 允许通过 key 快速的索引是否存在
- 重复数据可以去重
- 删除,查找,插入,效率都很快
2. unordered_map 的接口说明
a. unordered_map 的容量
函数声明
1. bool empty() const
2. size_t size() const
功能介绍
1. 检测unordered_map是否为空
2. 获取unordered_map的有效元素个数
b. unordered_map 的迭代器
函数声明
1. iterator begin()
2. iterator end()
3. iterator cbegin() const
4. iterator cend() const
功能介绍
1. 返回 unordered_map 第一个元素的迭代器
2. 返回 unordered_map 最后一个元素下一个位置的迭代器
3. 返回 unordered_map 第一个元素的const迭代器
4. 返回 unordered_map 最后一个元素下一个位置的const迭代器
c. unordered_map 的元素访问
函数声明
1. K& operator[]
功能介绍
1. 返回与 key 对应的 value ,允许被修改
d. unordered_map 的查询
函数声明
1. iterator find(const K& key)
2. size_t count(const K& key)
功能介绍
1. 返回key在哈希桶中的位置
2. 返回哈希桶中关键码为key的键值对的个数
注意:
unordered_map 中 key 是不能重复的,因此 count函数的返回值最大为 1
e. unordered_map 的桶操作
函数声明
1. size_t bucket_count() const
2. size_t bucket_size(size_t n) const
3. size_t bucket(const K& key)
功能介绍
1. 返回哈希桶中桶的总个数
2. 返回n号桶中有效元素的总个数
3. 返回元素key所在的桶号
注意:
unordered_set 用法差不多,就不介绍了
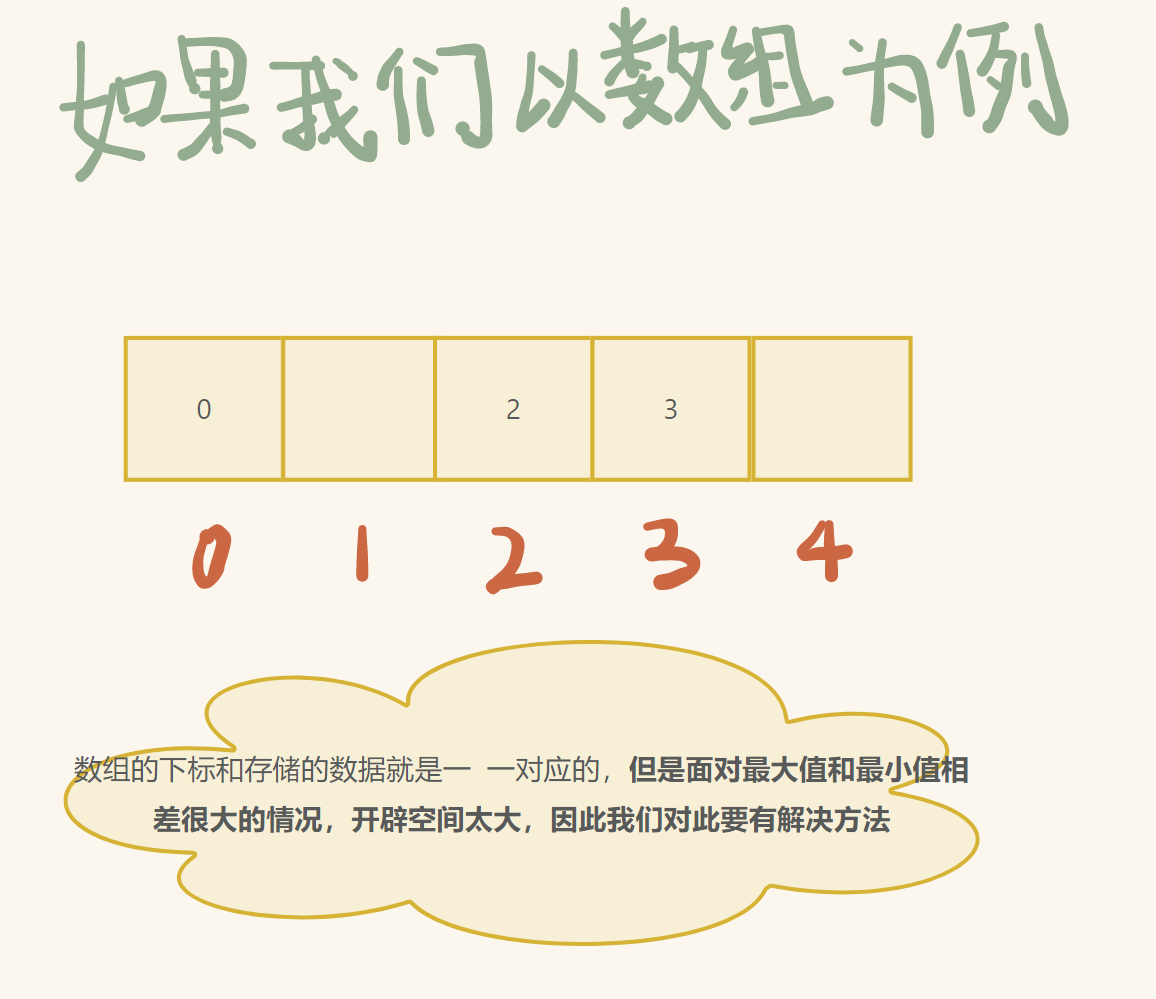
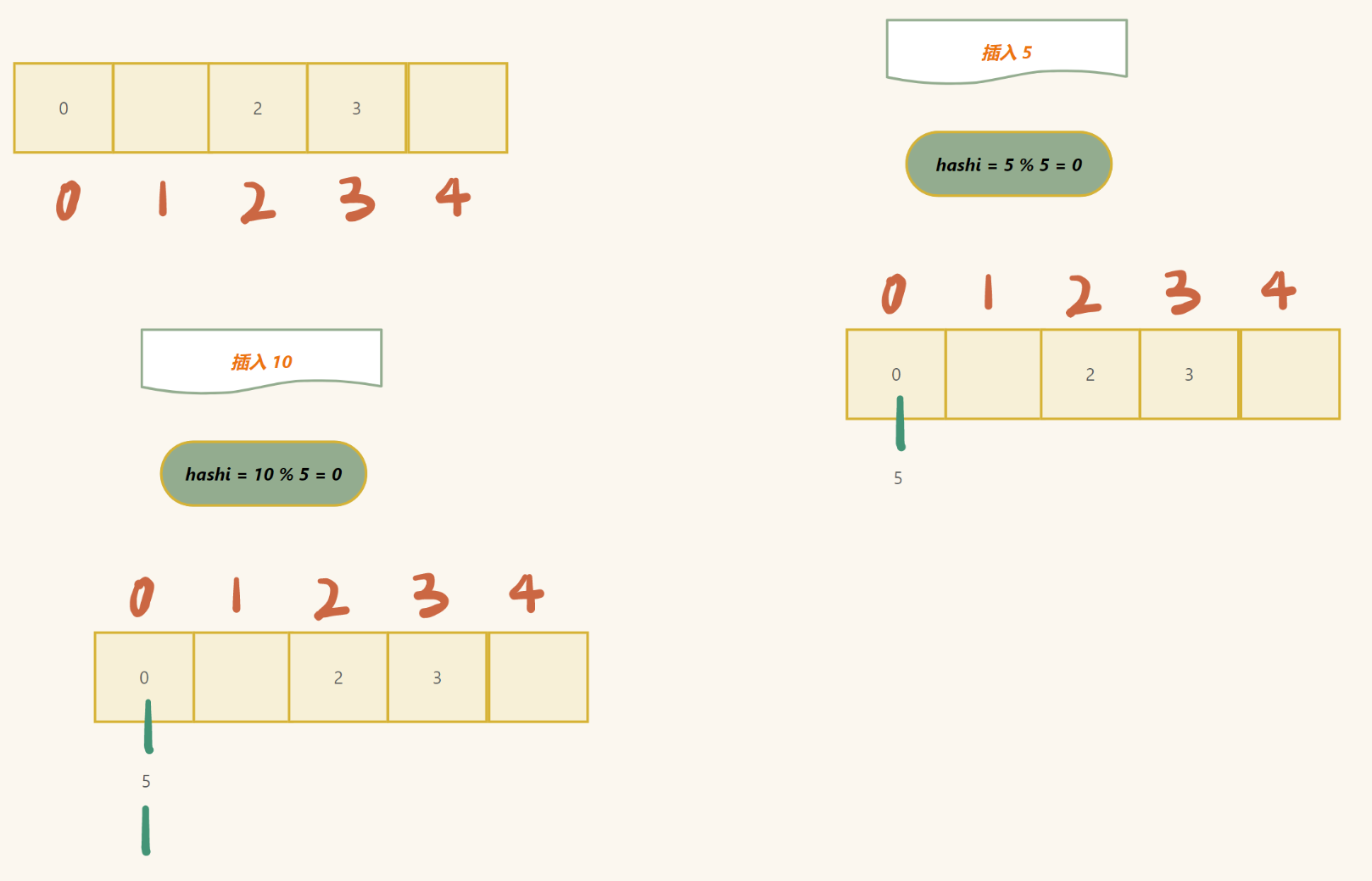
3. 哈希概念
通过位置关系找到对应的 key
a. 哈希冲突解决
先说上述问题的解决:
设插入的值为 key,n 为数组的大小
hashi (数组下标) = key % n (若 key 不为整数, 另做处理)
但是在插入的过程中,我们容易遇到以下问题:
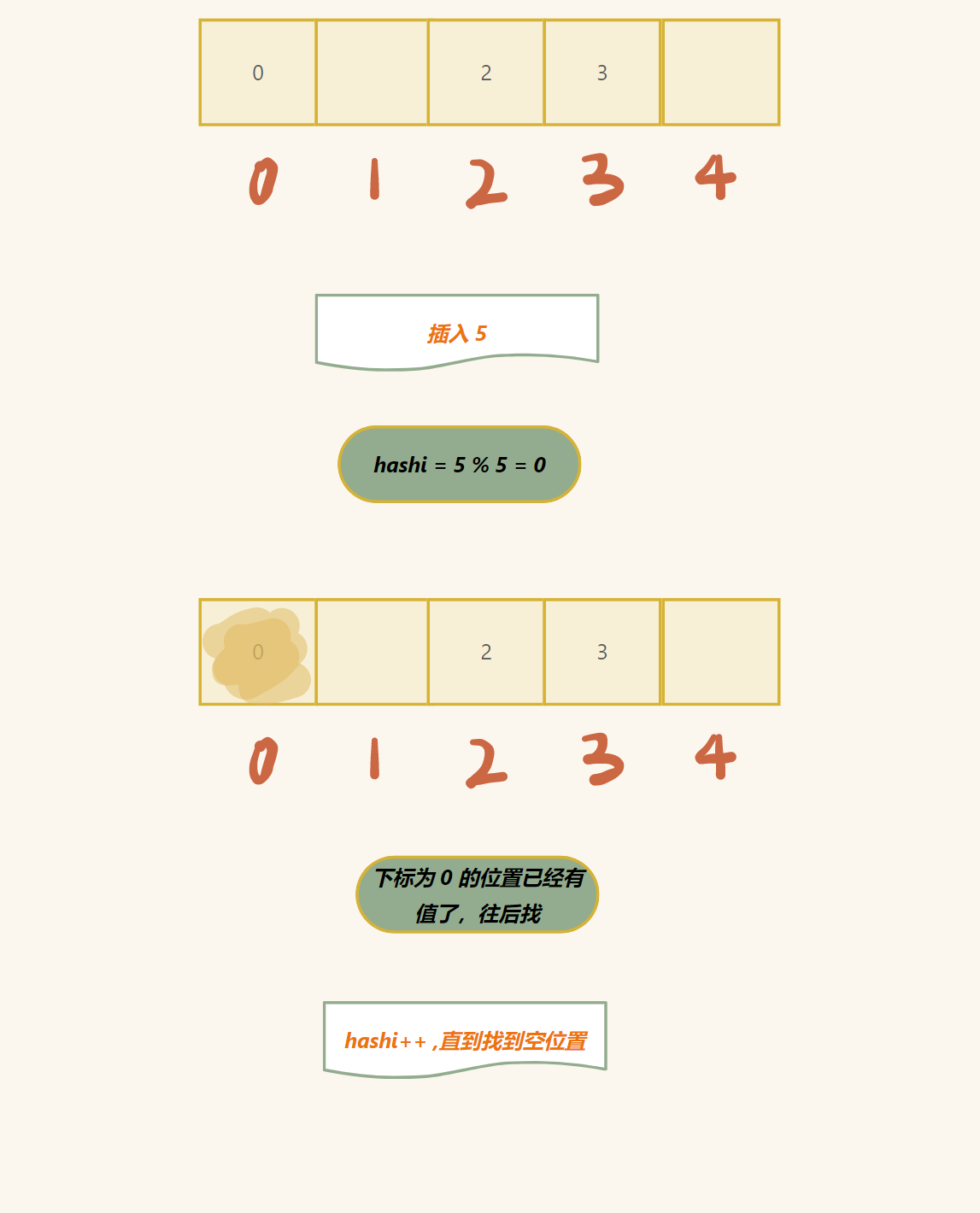
- hashi 已经有数值存入 (这种问题又叫 哈希冲突 )
第一种方法:(闭散列)
如果是这种情况,直接往后找,直到遇到空位置 (数组里面存入什么值都很难表示这个位置的状态,所以我们自己可以加入)
2. 所有的位置都有没有位置了
这种问题一定要涉及到空间的开辟 (但是这里我们需要谈论的是什么时候扩空间比较好)
注意:
这种分情况,后面实现再讲
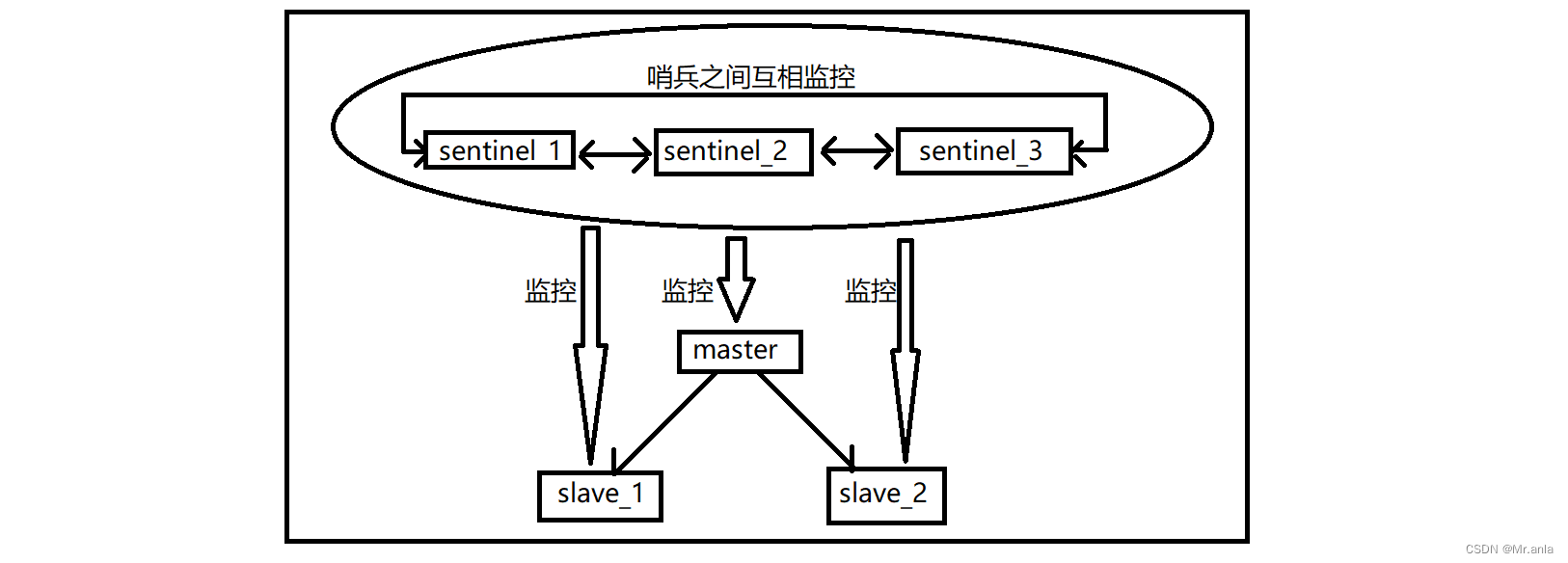
另外一种方法解决(开散列):
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地
址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链
接起来,各链表的头结点存储在哈希表中
4. 闭散列实现
代码
enum State
{Empty,Exist,Delete
};
template<class K,class V>
struct HashTable
{pair<K,V> _table;State _state = Empty;
};
template<class K, class V>
class Hsah
{
public:bool insert(const pair<K, V>& kv){if (_t.size() == 0 || n * 10 / _t.size() >= 7){Hsah<K, V> x;size_t size = _t.size() == 0 ? 10 : _t.size() * 2;x._t.resize(size);for (auto i : _t){if (i._state == Exist){x.insert(i._table);}}_t.swap(x._t);}size_t hashi = kv.first % _t.size();int index = hashi;size_t i = 1;while (_t[index]._state != Empty){index = hashi + i;index %= _t.size();i++;}_t[index]._table = kv;_t[index]._state = Exist;n++;return true;}HashTable<K, V>* find(const K& key){if (_t.size() == 0){return nullptr;}size_t hashi = key % _t.size();int index = hashi;size_t i = 1;while (_t[index]._state != Empty){if (_t[index]._table.first == key){if (_t[index]._state == Delete){return nullptr;}return &_t[index];}index = hashi + i;index %= _t.size();i++;if (index == hashi){break;}}return nullptr;}bool Erase(const K& key){HashTable<K, V>* t = find(key);if (t == nullptr || t->_state == Delete){return false;}t->_state = Delete;}
private:size_t n = 0;vector<HashTable<K,V>> _t;
};5. 开散列实现
代码
template<class K, class V>
struct HashNode
{HashNode(const pair<K, V>& kv):_kv(kv),next(nullptr){}HashNode<K, V>* next;pair<K, V> _kv;
};
template<class K, class V>
class HashBucket
{
public:typedef HashNode<K, V> Node;void insert(const pair<K, V>& kv){if (n == _hash.size()){size_t newsize = _hash.size() == 0 ? 10 : _hash.size() * 2;vector<Node*> newnode(newsize, nullptr);for (auto cur : _hash){while (cur){int hashi = cur->_kv.first % newsize;Node* prev = newnode[hashi];newnode[hashi] = cur;cur->next = prev;cur = cur->next;}}_hash.swap(newnode);}int hashi = kv.first % _hash.size();Node* cur = new Node(kv);Node* _next = _hash[hashi];_hash[hashi] = cur;cur->next = _next;n++;}bool find(const K& key){if (_hash.size() == 0){return false;}int hashi = key % _hash.size();Node* cur = _hash[hashi];while (cur){if (cur->_kv.first = key){return true;}cur = cur->next;}return false;}Node* erase(const K& key){int hashi = key % _hash.size();Node* prev = nullptr;Node* cur = _hash[hashi];while (cur){if (cur->_kv.first = key){if (prev == nullptr){_hash[hashi] = cur->next;}else{prev->next = cur->next;}delete cur;break;}prev = cur;cur = cur->next;}return nullptr;}
private:size_t n = 0;vector<Node*> _hash;
};//这里插入选择了头插
6. unordered_map , unordered_set 底层实现
代码
“test.h” :
#pragma once
template<class K>
struct Compare
{size_t operator()(const K& key){return key;}
};
template<>
struct Compare<string>
{size_t operator()(const string& k){size_t x = 0;for (auto i : k){x += i;x *= 31;}return x;}
};
namespace unordered
{template<class K, class T>struct HashNode{HashNode(const T& data):_data(data), next(nullptr){}HashNode<K, T>* next;T _data;};template<class K, class T, class Key0f, class compare>class HashBucket;template<class K, class T,class Ref,class Ptr, class Key0f, class compare>struct HashIterator{typedef typename HashIterator<K, T,Ref,Ptr, Key0f, compare> Self;typedef HashNode<K, T> Node;HashIterator(Node* hash,const HashBucket<K, T, Key0f, compare>* x):_node(hash),p(x){}Self& operator++(){if (_node->next){_node = _node->next;}else{Key0f kf;int hashi = compare()(kf(_node->_data)) % (p->_hash.size());++hashi;while (hashi < p->_hash.size()){if (p->_hash[hashi]){_node = p->_hash[hashi];break;}else{++hashi;}}if (hashi == p->_hash.size()){_node = nullptr;}}return *this;}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}bool operator!=(const Self& ptr){return _node != ptr._node;}const HashBucket<K, T, Key0f, compare>* p;Node* _node;};template<class K, class T, class Key0f, class compare>class HashBucket{template <class K, class T,class Ref,class Ptr, class Key0f, class compare>friend class HashIterator;public:typedef HashNode<K, T> Node;typedef typename HashBucket<K, T, Key0f, compare> Self;typedef typename HashIterator<K, T,T& ,T* ,Key0f, compare> Iterator;typedef typename HashIterator<K,T,const T&, const T*, Key0f, compare> const_Iterator;Iterator begin(){for (int i = 0; i < _hash.size(); i++){if (_hash[i]){return Iterator(_hash[i], this);}}return end();}const_Iterator begin() const{for (int i = 0; i < _hash.size(); i++){if (_hash[i]){return const_Iterator(_hash[i], this);}}return end();}Iterator end(){return Iterator(nullptr, this);}const_Iterator end() const{return const_Iterator(nullptr, this);}pair<Iterator,bool> insert(const T& data){Key0f kf;Iterator it = find(kf(data));if (it != Iterator(nullptr,this)){return make_pair(it, false);}if (n == _hash.size()){size_t newsize = _hash.size() == 0 ? 10 : _hash.size() * 2;vector<Node*> newnode(newsize, nullptr);for (auto cur : _hash){while (cur){int hashi = compare()(kf(cur->_data)) % newsize;Node* prev = newnode[hashi];newnode[hashi] = cur;cur->next = prev;cur = cur->next;}}_hash.swap(newnode);}int hashi = compare()(kf(data)) % _hash.size();Node* cur = new Node(data);Node* _next = _hash[hashi];_hash[hashi] = cur;cur->next = _next;n++;return make_pair(Iterator(cur,this), true);}Iterator find(const K& key){Key0f kf;if (_hash.size() == 0){return Iterator(nullptr,this);}int hashi = compare()(key) % _hash.size();Node* cur = _hash[hashi];while (cur){if (kf(cur->_data) == key){return Iterator(cur, this);}cur = cur->next;}return Iterator(nullptr, this);}T* erase(const K& key){Key0f kf;int hashi = compare()(key) % _hash.size();Node* prev = nullptr;Node* cur = _hash[hashi];while (cur){if (kf(cur->_data) == key){if (prev == nullptr){_hash[hashi] = cur->next;}else{prev->next = cur->next;}delete cur;break;}prev = cur;cur = cur->next;}return nullptr;}private:size_t n = 0;vector<Node*> _hash;};}
"my_map.h" :
#pragma once
#include "test.h"
template<class K,class V,class Hash = Compare<K>>
class map
{struct MapOf{const K& operator()(const pair<K,V>& _key){return _key.first;}};
public:typedef typename unordered::HashBucket<K, pair<const K, V>, MapOf, Hash>::const_Iterator Iterator;typedef typename unordered::HashBucket<K, pair<const K, V>, MapOf, Hash>::const_Iterator const_Iterator;pair<const_Iterator, bool> insert(const pair<K, V>& data){return pair<const_Iterator, bool>(const_Iterator(key.insert(data).first._node,&key), key.insert(data).second);}Iterator find(const K& data){return key.find(data);}pair<K, V>* erase(const K& data){return key.erase(data);}const_Iterator begin() const{return key.begin();}const_Iterator end() const{return key.end();}V& operator[](const K& k){pair<const_Iterator, bool> ret = key.insert(make_pair(k,V()));return ret.first->second;}
private:unordered::HashBucket<K, pair<const K, V>, MapOf,Hash> key;
};
"my_set.h" :
#pragma once
#include "test.h"
template<class K,class Hash = Compare<K>>
class set
{struct SetOf{const K& operator()(const K& _key){return _key;}};
public:typedef typename unordered::HashBucket<K, const K ,SetOf, Hash>::const_Iterator Iterator;typedef typename unordered::HashBucket<K, const K, SetOf, Hash>::const_Iterator const_Iterator;pair<const_Iterator,bool> insert(const K& data){return pair<const_Iterator, bool>(const_Iterator(key.insert(data).first._node,&key), key.insert(data).second);}Iterator find(const K& data){return key.find(data);}const K* erase(const K& data){return key.erase(data);}const_Iterator begin() const{return key.begin();}const_Iterator end() const{return key.end();}
private:unordered::HashBucket<K, const K, SetOf,Hash> key;
};
仿函数实现分析
”test.h“ 中:
其中:
这个完成了偏特化,将 string 可以变成 整型数,方便计算下标 hashi


细节注意
”my_map.h“ 中 :
”my_set.h“ 中 :
确保 map 和 set 都可以使用,
如果类型是 map ,得到的就是 pair<K,V>里面的 K 类型
如果类型是 set ,得到的就是 K 类型


迭代器问题分析
由于在operator++过程中,需要访问HashBucket的成员变量,所以需要友元
且在构造时需要HashBucket类,则需要前置声明
(前置声明)
迭代器注意:
pair<const_Iterator, bool> insert(const pair<K, V>& data){return pair<const_Iterator, bool>(const_Iterator(key.insert(data).first._node,&key), key.insert(data).second);}// return pair<const_Iterator, bool>(key.insert(data)) 是错误的
key.insert(data)是 pair<Iterator, bool> 类型,普通迭代器不能转换成 const迭代器