5.1 SoC系统功能仿真
按照上一章的设计方案,采用verilog HDL语言,在玄铁E906处理器平台中分别采用延迟验证和批处理验证方法完成了二级硬件堆栈的RTL级硬件描述。为了验证二级硬件堆栈的正确性,采用斐波那契数列进行验证,设置RAB大小为4,对添加二级硬件堆栈后的玄铁E906进行功能仿真,并利用Xilinx XC7- A100T器件对整个系统进行FPGA验证。
为了验证加入二级硬件堆栈后玄铁E906处理器还能否正常运行,以及二级硬件堆栈是否有效,在处理器中运行斐波那契数列进行验证[17],采用C语言编写的斐波那契数列是一种典型的递归程序,在程序运行时会调用多次子函数,能够很好的验证程序中调用的返回地址的正确性。计算前12个斐波那契数列的C语言程序为:
int Fbi(int i)
{
if( i < 2 )
return i == 0 ? 0 : 1;
return Fbi(i - 1) + Fbi(i - 2);
}
int main()
{
int i;
int a[40];
printf(“start fibonacci\n”);
a[0]=0;
a[1]=1;
printf(“%d “,a[0]);
printf(”%d “,a[1]);
for(i = 2;i < 12;i++)
{
a[i] = a[i-1] + a[i-2];
printf(”%d “,a[i]);
}
printf(”\n”);
printf(“end fibonacci show:\n”);
for(i = 0;i < 12;i++)
printf("%d ", Fbi(i));
return 0;
}
使用RISC-V gcc编译工具链对该程序编译产生二进制文件,分别使用延迟验证实现与批处理验证实现的玄铁E906处理器运行该程序,运行输出的结果如图5.1所示,表明加入二级硬件堆栈后处理器能够正常执行程序。
在延迟验证中,运行仿真斐波那契数列后延迟验证模块主要信号的仿真波形如图5.2所示。sw_ra与lw_ra_1信号检测返回地址保存和调用,由图可见当检测到相关指令时相应的信号保持一个高电平脉冲,同时front指针加1或减1。
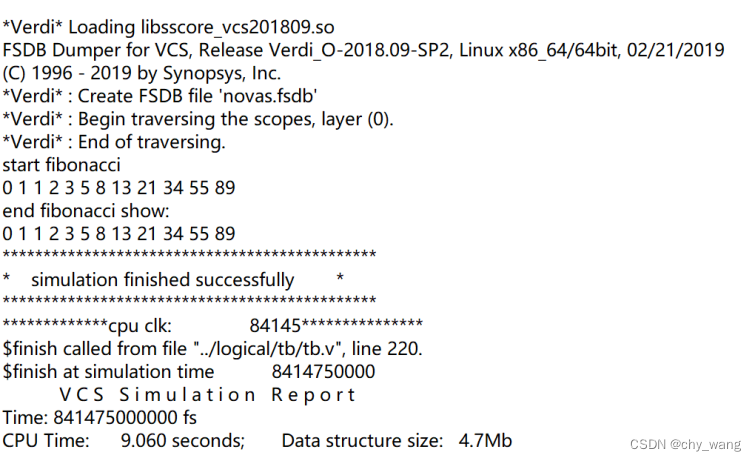
图5.1 斐波那契数列在玄铁E906中运行仿真输出

图5.2 延迟验证功能仿真
在仿真波形中b1、b2、b3、b4为RAB中的返回地址,m表示RAB中的消息验证码,mm表示MAC存储单元中保存的消息验证码,由仿真波形图可以看出在检测到相应指令后,RAB中相应条目的返回地址和MAC被改变,将MAC保存到MAC存储单元或读取MAC,mac_pointer指针也同时加1或减1,同时在系统中rear指针所指的返回地址不断送入MAC计算单元进行计算,aes_ld信号出现高电平脉冲。
在批处理验证中,运行仿真斐波那契数列后批处理验证模块主要信号的仿真波形如图5.3所示。在保存返回地址sw_ra为一个高电平时front加1,在调用返回地址lw_ra_1为高电平时front减1,在需要计算RAB中返回地址的MAC并且aes_same为0时aes_ld信号被置1。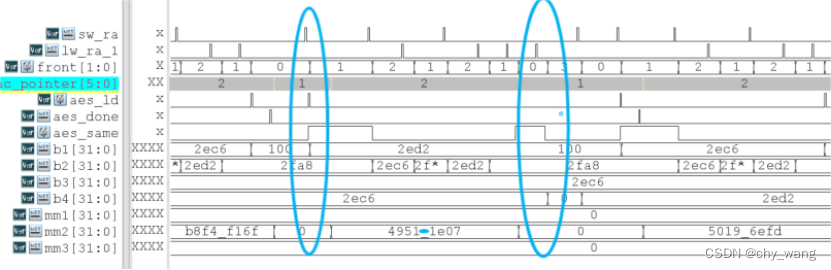
图5.3 批处理验证功能仿真
5.2 FPGA验证实现
对添加二级硬件堆栈后的玄铁E906处理器建立Vivado工程,如图5.4所示,对工程进行相应的时序约束和引脚约束后进行综合实现产生可在FPGA中运行的bit文件。
分别将延迟验证实现与批处理验证实现的玄铁E906处理器下载到FPGA型号为XC7A100T的FPGA开发板中,如图5.5所示,使用RISC-V gcc编译斐波那契数列生成elf文件,使用玄铁E906的JTAG接口通过RISC -V gdb调试工具将elf下载到处理器内存中并运行[26],如图5.6所示,通过串口调试工具查看运行结果,运行结果如图5.7,在FPGA平台中,玄铁E906增加二级硬件堆栈后仍然能成功运行斐波那契数列。

图5.5 下载玄铁E906 SoC到FPGA开发板中

图5.6 下载elf文件到玄铁E906并运行

图5.7 FPGA中玄铁E906运行斐波那契数列输出
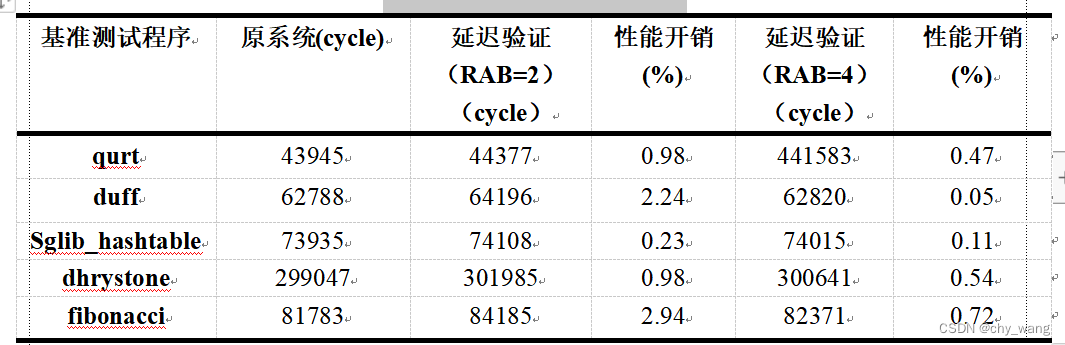
表5.1 延迟验证性能开销
5.3 系统性能测试
为了测试在添加二级硬件堆栈后对系统性能的影响,在原平台和添加硬件堆栈的处理器中运行典型测试基准程序,通过查看处理器运行时钟周期以及需要进行MAC验证的返回地址数量来统计系统性能开销。在本文中分别测试RAB大小为2和RAB大小为4时系统的性能开销,运行5个典型测试程序:qurt是一种二次方程求根程序;duff是用于串行复制的程序;sglib_hashtable是一种哈希表访问程序;dhrystone是测量处理器运算能力的基准测试程序之一,能够综合测试处理器的运算能力;fibonacci是一种典型的循环递归程序。
表5.2 延迟验证中消除不必要MAC验证的比例
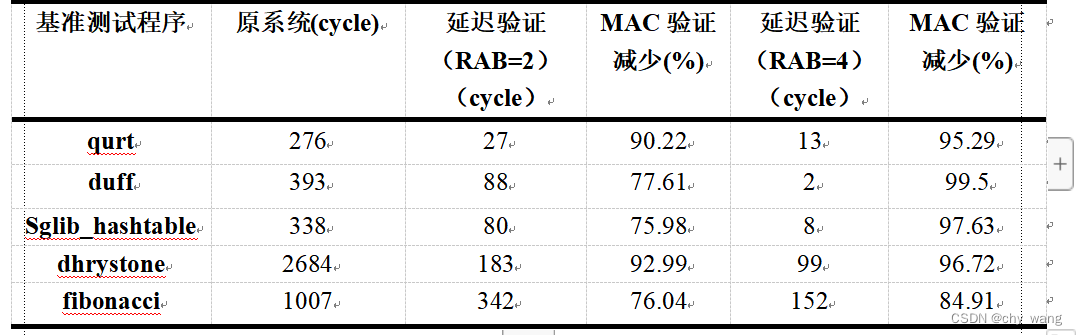
在延迟验证中,分别设置RAB大小为2和4,运行测试程序后系统性能开销如表5.1所示,展示了运行原系统以及添加二级硬件堆栈后处理器运行时钟周期。延迟验证中,使用两个条目的RAB性能开销最多不到3%,当使用四个条目的RAB时,性能开销不到1%,在一定程度上不影响处理器的实时性,RAB中存储的返回地址越多性能开销就越少,在表中4个条目的RAB比2个条目的RAB性能开销上至少减少一半。表5.2显示了延迟验证在减少MAC验证方面具有显著的效果,如果没有二级硬件堆栈,子函数每次返回时都需要进行验证,
当RAB为2个条目时平均能够减少85%以上的验证,RAB为4个条目时平均能减少95%以上的验证。如果在一个程序中子函数的调用深度小于RAB中能存储返回地址的数目,则不需要进行验证。
表5.3 批处理验证性能开销
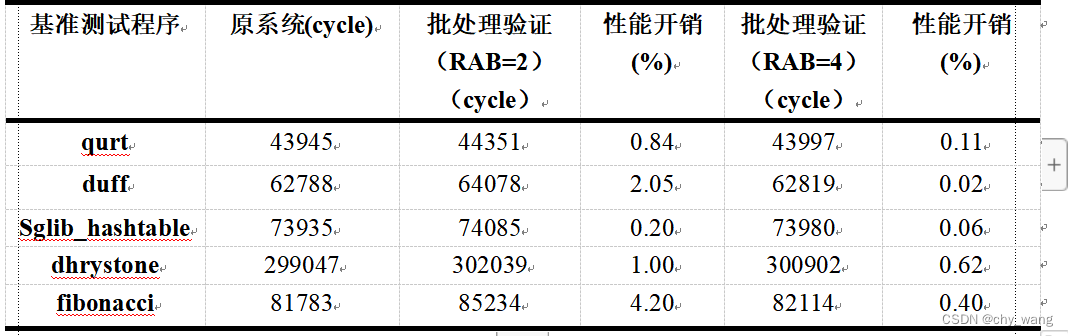
批处理验证中RAB中的所有返回地址生成一个MAC,表5.3表示了批处理验证中运行测试程序后系统的性能开销,当RAB大小为2时只有在连续两次子函数返回时才需要进行MAC验证,对于像sglib_hashtable这种调用子函数深度较少程序几乎没有性能开销。当设置RAB大小为4时只有在连续四次子函数返回时才需要MAC验证,系统性能开销更低,对于fibonacci这种调用子函数较多的递归程序性能开销也不到1%。表5.4为批处理验证减少MAC验证的比例,当RAB大小为4时,对于大多数程序能够减少95%以上的MAC验证。
在陈立伟等人设计的链式堆栈中[4],采用改进的基于MAC验证方法提高了安全性,但带来了23%的巨大的性能开销;张军等人提出的RAGuard进行了优化,但也带来了6%以上的性能开销[8]。使用本文设计二级片内堆栈,当RAB大小为4时,两种验证方法的性能开销都小于1%,并且设置RAB越大,性能开销会更低。
表5.4 批处理验证中消除不必要MAC验证的比例

5.4 系统硬件开销
在二级硬件堆栈RAB大小为4时,通过vivado2019.2工具对设计进行综合实现,两种验证方法在xc7a100t FPGA芯片中的硬件开销如表5.5所示。
表5.5 二级硬件堆栈在FPGA中的硬件资源消耗
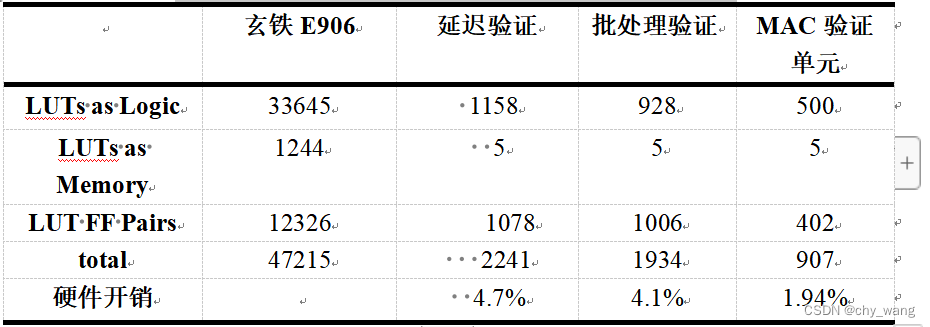
由表5.5可知,RAB大小为4时延迟验证大约增减4.7%的硬件开销,批处理验证大约增加4.1%的硬件开销,其中大约40%的硬件开销来源于消息码计算单元AES,由于批处理验证RAB不需要存储MAC并且MAC存储单元可以更小,所以批处理验证占用的硬件资源更少,同时存储MAC也会占用大量的片上硬件资源。
5.5 本章小结
本章主要对加入二级硬件堆栈后的玄铁E906处理器进行了功能验证和性能分析,以及在FPGA中的硬件资源开销。首先在加入两种验证方法后的处理器中分别运行典型的递归程序斐波那契数列,进行仿真以及FPGA实现,验证功能的正确性,并通过分析仿真波形,验证设计的二级硬件堆栈真正其作用并且正常工作了。之后采用典型公认的处理器性能测试程序,统计了加入二级硬件堆栈之后系统的性能开销并与其他研究者的设计进行了比较。最后分析了两种验证方法的硬件资源开销。