冯诺依曼模型与计算机处理数据过程相关联:
- 冯诺依曼模型:
- 输入/输出设备
- 存储器
- 输出设备
- 运算器
- 控制器
- 处理过程:
- 提取阶段:输入设备传入原始数据,存储到存储器
- 解码阶段:由CPU的指令集架构ISA将数值解码成指令
- 执行阶段:控制器把需要计算或处理的数据调入运算器
- 最终阶段:由输出设备把运算结果返回
所以JVM是什么呢?
- 首先,将java文件编译成.class文件之后,JVM会对字节码文件进行解释,翻译成对应平台的机器指令开始执行。屏蔽了底层操作系统,实现跨平台运行。
.java文件是如何变成.class文件的?
类文件解读:
-
16进制
-
magic、版本号、常量池(62个字面量和符号引用)、字段表集合、方法表集合
-
符号引用就是类信息、修饰符,名称等等,不直接指向
类加载机制:
所谓的类加载机制就是将class文件加载进内存,并对数据进行校验,转换解析和初始化,形成JVM可以直接使用。
- 当字节码文件加载到内存的时候,是不是需要一个访问入口呀?
- 那如何将字节码文件加载进内存呢?
- 常见的从本地系统加载
- 动态代理技术,运算时计算而成
- 从jar包中加载
- 类加载过程:
- 装载:
- 通过类全限定名获取类的二进制字符流!
- 将字符流代表的静态存储结构转换为方法区的运行时数据结构
- 在堆中生成java.lang.class对象,作为对方法区中这些数据的访问入口
- 链接
- 验证:格式验证、字节码验证、符号引用验证。-Xverify:none 取消验证。
- 准备:为静态变量赋值,初始化成默认值。
- 这里不包含final修饰的static,final修饰的static都在编译的时候就分配了
- 不会为实例变量分配初始化,类变量在方法区中,实例变量随着对象在堆中(即在实例构造器方法中进行的)
- 解析
- 将符号引用转换成直接引用,直接指向目标的指针,或者间接定位到目标的句柄
- 对解析结果进行缓存
- 初始化
- 执行类构造器方法的过程,对比于准备阶段,这里是通过指定主观计划去初始化变量和其他资源。
- 对类变量设置初始值的两种方式:
- 直接声明
- static代码块
- 步骤
- 先装载和链接本类
- 然后初始化父类
- 初始化自己
- 什么时候初始化:(主动引用)
- 创建实例;
- 对静态变量赋值;
- 调用静态方法;
- 调用子类父类也会初始化;
- 标明启动类的类
- (被动引用)
- 定义类数组不会初始化
- 使用父类的静态变量,不会初始化
- static final不会初始化
- 卸载:
- 用完之后就卸载回收
- 包括类加载器,class对象,实例
- 用完之后就卸载回收
- 装载:
- 类加载器:
- 就是读取字节码,转换成java.lang.class类的一个实例的代码模块
- 一个类在同一个类加载器中具有唯一性,不同类加载器是允许同名类存在的,类加载器不同,就不会是同一个类。
- 分类:
- bootstrap classloader:负责java_home的所有class
- extension classloader:负责一些扩展的包
- app classloader:classpath中指定的包
- custom classloader:根据程序自定义类加载器
- 为什么要分层?
- 如果自己编写了一个java.lang.String类,如果只有一个的话无法判定究竟要加载哪个。所以分层对信任级别进行划分
- 三个特性:
- 全盘负责:
- 当一个类加载器加载某个class的时候,该class所依赖的和引用其他的class都由该类加载器负责载入。除非显式使用另一个类加载器
- 父类委托(双亲委派):
- 首先传入类的全限定名
- 从app层依次往上找是否加载过,然后又从上往下看谁能加载,最后还没有就抛异常。
- 可以重写loadclass打破双亲委派
- 打破:
- SPI,JDK提供了一套接口,定义实现类,在META-INF/services中注册实现类的相关信息,比如JDBC的DriverManager
- OSGI:热部署、热替换
- 如果怕打破可以重写findclass方法
- 缓存机制:
- 加载过的class文件在内存中(方法区)缓存
- 每一个类加载器都有自己的缓存
- 全盘负责:
运行时数据区:
- 常量池:
- 静态常量池:class文件的一部分,由字面量(文本、字符串以及final修饰的)和符号引用(描述信息)组成
- 运行时常量池:静态常量池被加载到内存后就变成了运行时常量池了,class文件内容落地到内存了
- 字符串常量池:现在在堆中
- 面试常问的:
-
String a ="aaaa";解析:最多创建一个字符串对象。先查找有没有这个,没有就创建一个,返回引用。
-
`String a =new String("aaaa");`
解析:最多会创建两个对象。常量池没有的话,就在堆中创建一个字符串对象(放字符串常量池里),再在堆中创建一个对象(独立出去),返回后面的引用。有没有都要多创建一个。
-
intern()
-
返回的是字符串常量池里的String s1 = new String("yzt"); String s2 = s1.intern(); System.out.println(s1 == s2); //false
-
-

- 方法区:
- 线程共享
- 堆的一个逻辑部分,但是也要和堆区分出来
- 存放虚拟机加载的类信息,常量、静态变量、JIT代码等等
- 当方法区无法满足内存分配的需求时,将抛出OOM异常
- 1.8后在系统内存(元空间)中,为了避免内存泄露和OOM
- 堆:
- 虚拟机管理内存中最大的一块,在虚拟机启动的时候被创建,线程共享
- 实例和数组都在堆上分配,注意java.class.class这个对象就是方法区中数据的访问入口
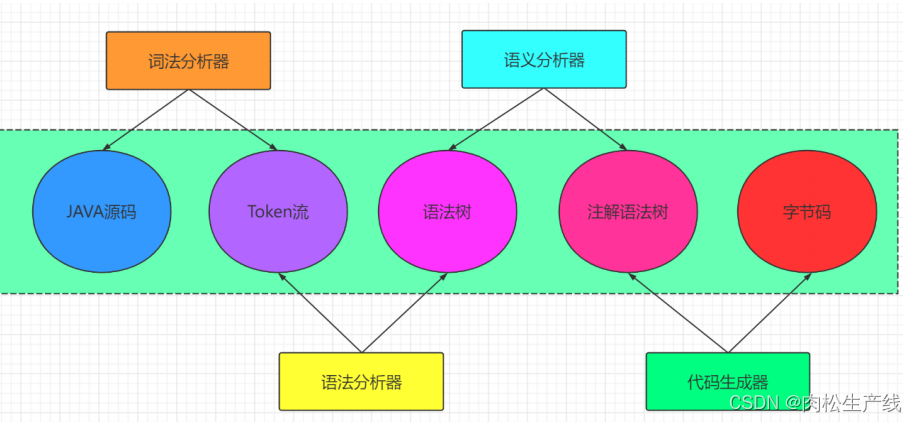
- 虚拟机栈:
- 假设现在已经初始化完成了要使用了,一个线程的运行状态就由虚拟机栈来保存,线程私有,随着线程的创建而创建。
- 线程执行的每一个方法,就是栈中的一个栈桢,可以看作是一个方法的运行空间。
- 程序计数器:
- 线程切换的时候,记录正在执行的字节码指令的地址
- 本地方法栈:
- 如果执行Native就在本地方法栈执行
- 如果在java方法执行的时候调用native方法,就是动态链接。
- 方法区:
- 面试常问的:
内存布局:
- 对象内存布局:
- 指针压缩:
- 在64位的操作系统中,一个指针一般是八个字节,在很多情况下,并不需要使用这么多的地址空间。压缩的主要是classpointer
- 减少内存消耗,压缩成4字节。对于大型应用,节省空间。
- 更好的缓存应用:能存放更多的对象
- 提高访问速度:较小的数据结构代表着读写能够更快的完成
- 减少垃圾回收开销:扫描和标记耗时变小
- 无效情况:
- 32位超过32G
- 怎么去理解?
- 第一种理解:对象长度一定是8的整数倍,所以只用存第一个,4G*8=32G
- 第二种理解:当存入64位寄存器的时候,左移三位,末尾三个0是不需要的,索引寻址空间提高了8倍;
- java采用的大端存储,便于符号判断,小端便于类型转换
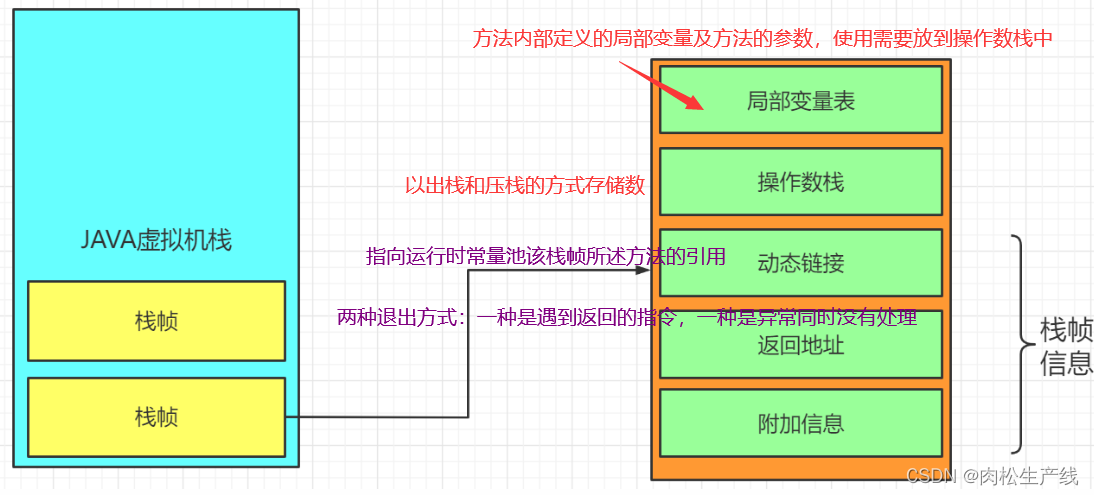
- classpointer设计:
- 句柄池访问:对象移动的时候只需要修改一个指针,但是多一次定位的时间开销
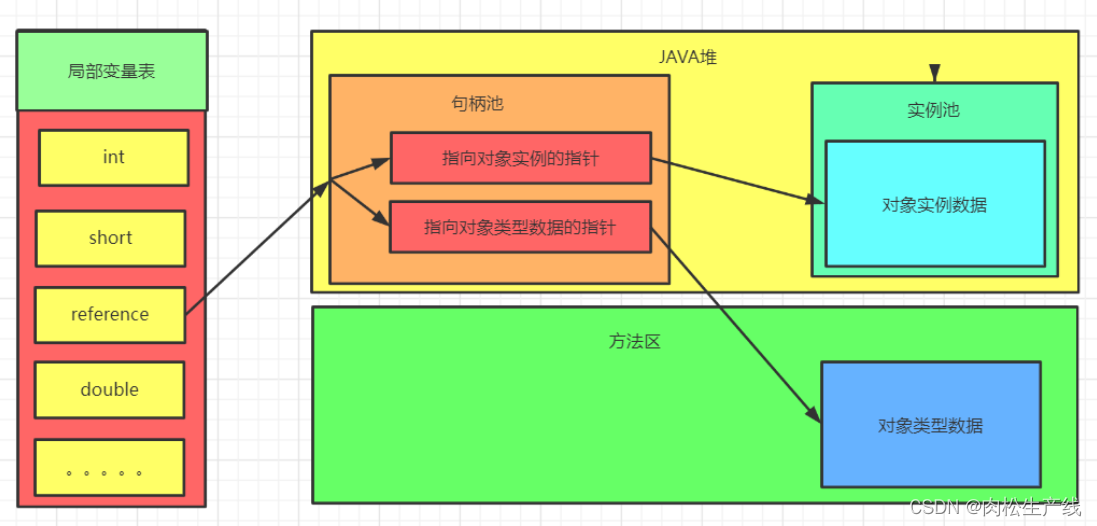
- 直接指针:节省了一次定位开下,在对象移动后,还需要修改引用
- 句柄池访问:对象移动的时候只需要修改一个指针,但是多一次定位的时间开销
- 对齐填充:
- 8字节,举个例子,如果针对开区域存储,那么就需要读两次内存,现在读一次就可以了。也可以选择策略
- 0:基本类型>填充类型>引用类型
- 1:引用类型>基本类型>填充类型
- 2:父类的引用类型和子类的引用类型放在一起,父类采用0,子类采用1,从而降低空间的开销。
- 8字节,举个例子,如果针对开区域存储,那么就需要读两次内存,现在读一次就可以了。也可以选择策略


运行时数据区:
- 根据GC的悲观策略,98%的对象不能达到分代年龄
- 内存担保机制:假设在young gc后,新生代仍然有大量的对象存活,就需要老年代进行分配担保。
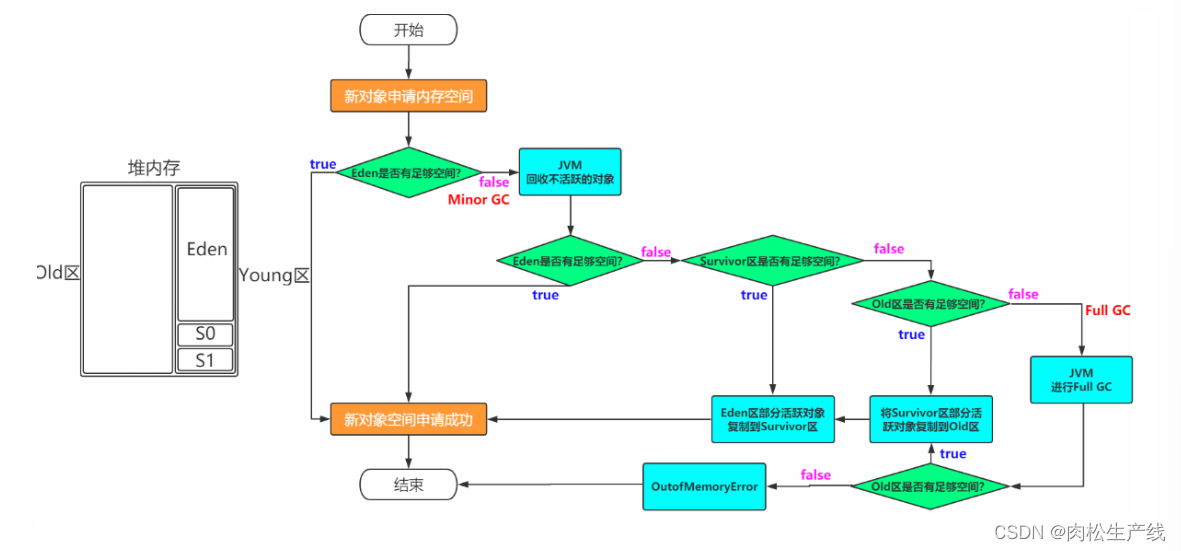
什么时候Full GC?
-
每次晋升的对象平均大小>剩余空间,基于历史水平计算
-
上面内存担保机制
-
元空间内存不足
-
System.GC
-
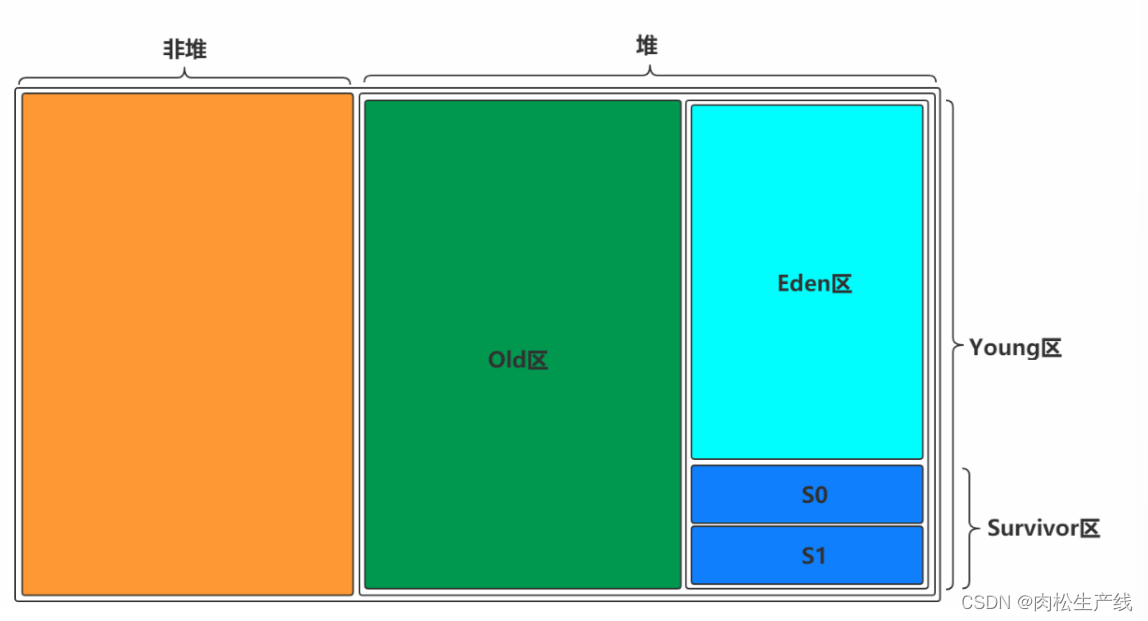
如何理解Minor/Major/Full GC
Minor GC:新生代 Major GC:老年代 Full GC:新生代+老年代
-
为什么需要Survivor区?只有Eden不行吗?
如果没有survivor区域,那么就会导致,每进行一次minor gc,存活的对象就要进入老年代,这样老年代就会很快填满,容易发生full gc,老年代空间又比较大。
如果没有Survivor,Eden区每进行一次Minor GC,存活的对象就会被送到老年代。 这样一来,老年代很快被填满,触发Major GC(因为Major GC一般伴随着Minor GC,也可以看做触发了Full GC)。 老年代的内存空间远大于新生代,进行一次Full GC消耗的时间比Minor GC长得多。 执行时间长有什么坏处?频发的Full GC消耗的时间很长,会影响大型程序的执行和响应速度。 可能你会说,那就对老年代的空间进行增加或者较少咯。 假如增加老年代空间,更多存活对象才能填满老年代。虽然降低Full GC频率,但是随着老年代空间加大,一旦发生Full GC,执行所需要的时间更长。 假如减少老年代空间,虽然Full GC所需时间减少,但是老年代很快被存活对象填满,Full GC频率增加。 所以Survivor的存在意义,就是减少被送到老年代的对象,进而减少Full GC的发生,Survivor的预筛选保证,只有经历16次Minor GC还能在新生代中存活的对象,才会被送到老年代。
-
为什么需要两个Survivor区?
最大的好处就是解决了碎片化。也就是说为什么一个Survivor区不行?第一部分中,我们知道了必须设置Survivor区。假设现在只有一个Survivor区,我们来模拟一下流程: 刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。这样继续循环下去,下一次Eden满了的时候,问题来了,此时进行Minor GC,Eden和Survivor各有一些存活对象,如果此时把Eden区的存活对象硬放到Survivor区,很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。 永远有一个Survivor space是空的,另一个非空的Survivor space无碎片。
-
新生代中Eden:S1:S2为什么是8:1:1?
新生代中的可用内存:复制算法用来担保的内存为9:1 可用内存中Eden:S1区为8:1 即新生代中Eden:S1:S2 = 8:1:1 现代的商业虚拟机都采用这种收集算法来回收新生代,IBM公司的专门研究表明,新生代中的对象大概98%是“朝生夕死”的
-
堆内存中都是线程共享的区域吗?
JVM默认为每个线程在Eden上开辟一个buffer区域,用来加速对象的分配,称之为TLAB,全称:Thread Local Allocation Buffer。 对象优先会在TLAB上分配,但是TLAB空间通常会比较小,如果对象比较大,那么还是在共享区域分配。