在拿猿人学网站
https://www.python-spider.com/api/challenge58练习的时候发现请求头中少了
'content-type'之后结果全部不对了

当我设置headers如下时
headers = {# 'accept': 'application/json, text/javascript, */*; q=0.01','content-type': 'application/x-www-form-urlencoded; charset=UTF-8','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',}请求结果又正常了
查了一下资料
在HTTP协议消息头中,使用Content-Type来表示媒体类型信息。它被用来告诉服务端如何处理请求的数据,以及告诉客户端(一般是浏览器)如何解析响应的数据,比如显示图片,解析html或仅仅展示一个文本等。Post请求的内容放置在请求体中,Content-Type定义了请求体的编码格式。数据发送出去后,还需要接收端解析才可以。接收端依靠请求头中的Content-Type字段来获知请求体的编码格式,最后再进行解析。
转过来我们在说下这个网站,有个token参数需求处理

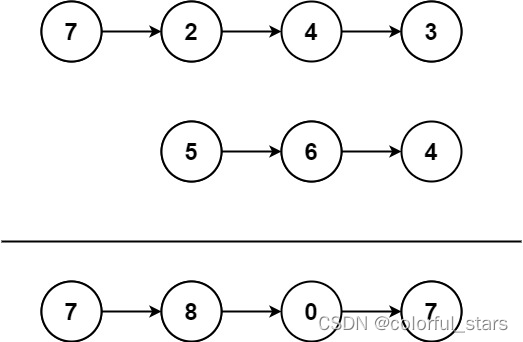
经过逆向可以看到这里是一个md5加密的参数
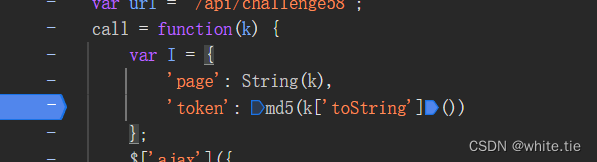
仔细观察可以发现他和标准的md5长度不一样,是截取了一部分,整体代码如下
import hashlibimport requestsif __name__ == '__main__':count = 0url = "https://www.python-spider.com/api/challenge58"for page in range(1, 101):token = hashlib.md5(str(page).encode()).hexdigest()token = (token[8:-8])# print(token)payload = f"page={str(page)}&token={token}"headers = {# 'accept': 'application/json, text/javascript, */*; q=0.01',# 'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',# 'cookie': 'Hm_lvt_337e99a01a907a08d00bed4a1a52e35d=1713308311; sessionid=w2ln1ezuso8zzsiyqc5ejvrp11oe4sav; Hm_lpvt_337e99a01a907a08d00bed4a1a52e35d=1713357816','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',}response = requests.request("POST", url, headers=headers, data=payload)print(response.json())for data_ in response.json()["data"]:result = int(data_["value"])count += resultprint(count)
经过计算可以得出结果了,分享一个简单的小案例,在写代码的过程一定要细心,少走一些弯路