目录
概述
1. Cortex-M3类型MCU
1.1 MCU 架构
1.2 实时性系统概念
1.3 处理器命名法
1.4 MCU的一些知识
2. Cortex-M3 概览
2.1 Cortex-M3综述
2.2 寄存器组
2.3 操作模式和特权极别
2.4 内建的嵌套向量中断控制器
2.5 存储器映射
2.6 总线接口
2.7 存储器保护单元( MPU)
2.8 指令集
2.9 中断和异常
2.10 低功耗与高能效
2.11 调试支持
3 Contex-M3基础
3.1 寄存器组
3.2 操作模式
3.3 栈内存操作
3.4 Cortex-M3 的堆栈实现
3.8 复位序列
4. 存储器系统
5. 详细的框图
概述
本文主要介绍ARM Contex-CM3相关的知识,包括内核架构,寄存器组,和指令集等内容。
1. Cortex-M3类型MCU
1.1 MCU 架构
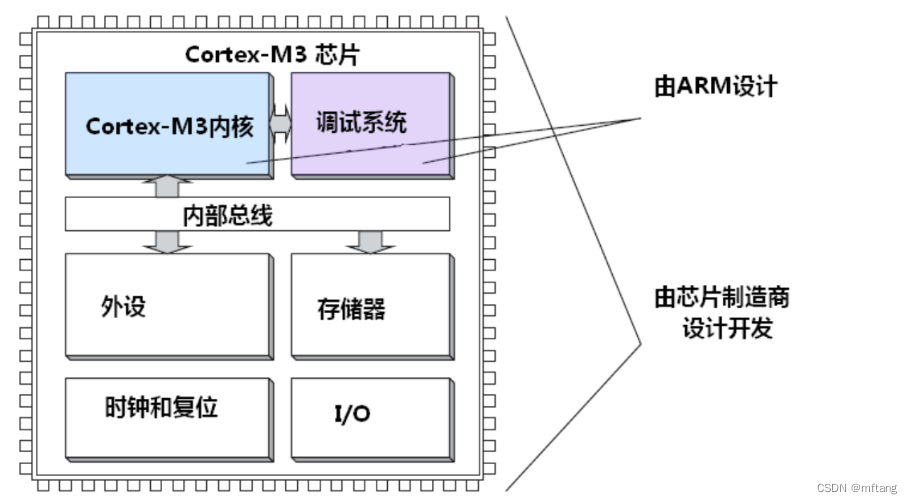
历史:
-
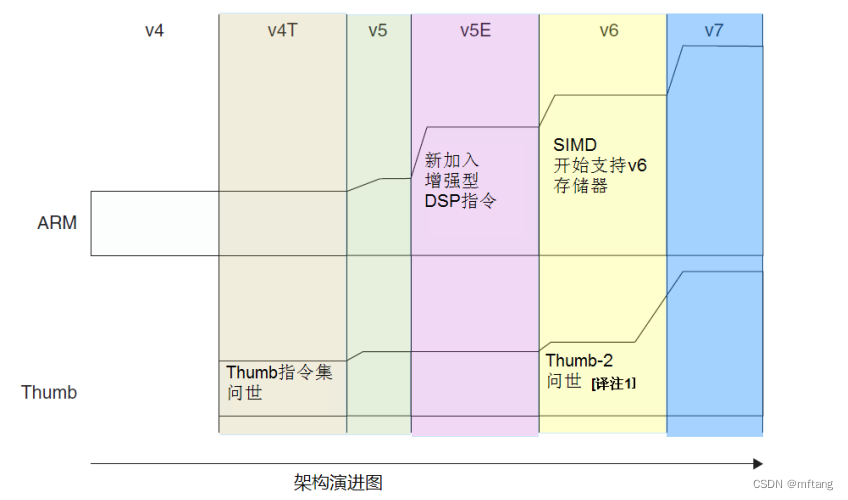
ARMv4T架构: ARM7TDMI(T表示支持“Thumb指令”)
-
ARMv5TE架构: ARM9E处理器 , ARM9E家族成员包括ARM926E-S和ARM946E-S ,
特点: ARMv5TE架构添加了“服务于多媒体应用增强的DSP指令”
-
ARMv6架构 : ARM1136J(F)-S, ARM1156T2(F)-S,以及 ARM1176JZ(F)-S
特点: 1)单指令流多数据流(SIMD)指令也是从v6开始首次引入的;2)优化Thumb-2指令集
-
ARMv7架构 :
| 类型 | 描述 |
|---|---|
| 款式A | 设计用于高性能的“开放应用平台”——越来越接近电脑,特点:支持大型嵌入式操作系统 |
| 款式R | 用于高端的嵌入式系统,尤其是那些带有实时要求的——又要快又要实时。 特点: 硬实时且高性能的处理器。标的是高端实时 |
| 款式M | 用于深度嵌入的,单片机风格的系统中。认准了旧世代单片机的应用而量身定制。在这些应用中,尤其是对于实 时控制系统,低成本、低功耗、极速中断反应以及高处理效率,都是至关重要的。 |
ARM处理器架构进化史

1.2 实时性系统概念
从定义的角度讲,“实时”就是指系统必须在给定的死线(deadline,亦称作“最后期限” )内做出响应。在一个以ARM处理器为核心的系统中,决定能否达到“实时”这个目标的,有很多因素,主要如下:
1)中断延迟
2)存储器延时
3)当时处理器是否在运行更高优先级的中断服务例程
1.3 处理器命名法
一个demo:

1.4 MCU的一些知识
1. MMU(储器管理单元)
用于实现虚拟内存和内存的分区保护,这是应用处理器与嵌入式处理器的分水岭。电脑和数码产品所使用的处理器几乎清一色地都带MMU。 但是MMU也引入了不确定性,这有时是嵌入式领域——尤其是实时系统不可接受的。然而对于安全关键(safety-critical)的嵌入式系统, 还是不能没有内存的分区保护的。为解决矛盾, 于是就有了MPU。 可以把MPU认为是MMU的功能子集,它只支持分区保护,不支持具有“定位决定性”的虚拟内存机制。
2. 指令集
ARM处理器一直支持两种形式上相对独立的指令集,在程序的执行过程中,处理器可以动态地 在两种执行状态之中切换。Thumb指令集在功能上是ARM指令集的一个子集它们分别是 :
32位的ARM指令集,对应处理器状态: ARM状态 16位的Thumb指令集,对应处理器状态: Thumb状态
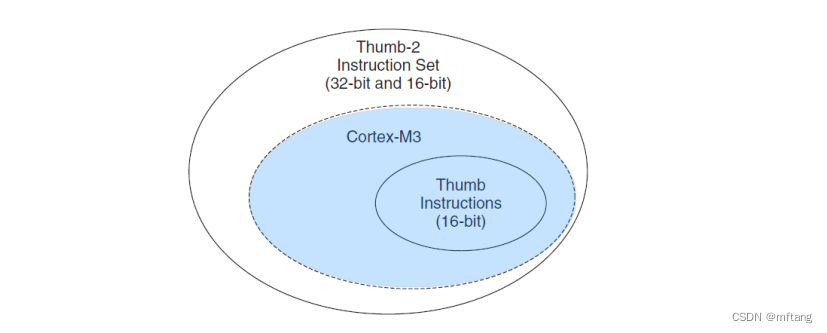
3. Thumb-2 指令集体系体系结构
Thumb-2是16位Thumb指令集的一个超集,在Thumb-2中, 16位指令首次与32位指令并存,结果在Thumb状态下可以做的事情一下子丰富了许多,同样工作需要的指令周期数也明显下降。
2. Cortex-M3 概览
2.1 Cortex-M3综述
Cortex-M3 是一个 32 位处理器内核。内部的数据路径是 32 位的,寄存器是 32 位的,存储器 接口也是 32 位的。 CM3 采用了哈佛结构,拥有独立的指令总线和数据总线,可以让取指与数据访 问并行不悖。这样一来数据访问不再占用指令总线,从而提升了性能。为实现这个特性, CM3 内部 含有好几条总线接口,每条都为自己的应用场合优化过,并且它们可以并行工作。但是另一方面, 指令总线和数据总线共享同一个存储器空间(一个统一的存储器系统)。换句话说,不是因为有两 条总线,可寻址空间就变成 8GB 了。
特点:
-
Cortex-M3 是 32 位处理器内核,其内部路径和寄存器都是32位
-
采用哈佛结构:拥有独立的指令总线和数据总线
-
支持大端和小端模式

2.2 寄存器组
Cortex-M3 处理器拥有 R0-R15 的寄存器组。其中 R13 作为堆栈指针 SP。 SP 有两个,但在同 一时刻只能有一个可以看到,这也就是所谓的“banked”寄存器。

R0-R12 通用寄存器
R0-R12 都是 32 位通用寄存器,用于数据操作。
但是注意:
绝大多数 16 位 Thumb 指令只能访问 R0-R7,而 32 位 Thumb-2 指令可以访问所有寄存器。
Banked 和 R13: 两个堆栈指针
Cortex-M3 拥有两个堆栈指针,然而它们是 banked,因此任一时刻只能使用其中的一个。
| 参数名称 | 描述 |
|---|---|
| 主堆栈指针(MSP) | 复位后缺省使用的堆栈指针,用于操作系统内核以及异常处理例程(包 括中断服务例程) |
| 进程堆栈指针(PSP) | 由用户的应用程序代码使用 |
R14连接寄存器
当呼叫一个子程序时,由 R14 存储返回地址
R15:程序计数寄存器
指向当前的程序地址。如果修改它的值,就能改变程序的执行流
特殊功能寄存器
Cortex-M3 还在内核水平上搭载了若干特殊功能寄存器,包括: 1) 程序状态字寄存器组(PSRs) 2) 中断屏蔽寄存器组(PRIMASK, FAULTMASK, BASEPRI) 3) 控制寄存器(CONTROL)

寄存器及其功能

2.3 操作模式和特权极别
Cortex-M3 处理器支持两种处理器的操作模式,还支持两级特权操作。
处理器的操作模式: 处理者模式 和线程模式
特权操作: 特权级和用户级

注意点:
主应用程序时(线程模式),既可以使用特权级,也可以使用用户级; 异常服务例程必须在特权级下执行。 复位后,处理器默认进入线程模式,特权极访问。在特权级下,程序可以访问所有范围的存储器(如果有 MPU,还要在 MPU 规定的禁地之外),并且可以执行所有指令。

2.4 内建的嵌套向量中断控制器
Cortex-M3 在内核水平上搭载了一颗中断控制器——嵌套向量中断控制器 NVIC(Nested Vectored Interrupt Controller)。它与内核有很深的“亲密接触” ——与内核是紧耦合的。
NVIC 提供如下的功能:
1)可嵌套中断支持
2)向量中断支持
3)动态优先级调整支持
4)中断延迟大大缩短
5)中断可屏蔽
可嵌套中断支持
当一个异常发生时,硬件会自动比较该异常的优先级是否比当前的异常优先级更高。如果发现来了更高优先级的异常,处理器就会中断当前的中断服务例程(或者是普通程序),而服务新来的异常——即立即抢占
向量中断支持
当开始响应一个中断后, CM3 会自动定位一张向量表,并且根据中断号从表中找出 ISR 的入口地址,然后跳转过去执行。不需要像以前的 ARM 那样, 由软件来分辨到底是哪个中断发生了,也无需半导体厂商提供私有的中断控制器来完成这种工作。这么一来,中断延迟时间大为缩短。
动态优先级调整支持
软件可以在运行时期更改中断的优先级。如果在某ISR中修改了自己所对应中断的优先级,而且这个中断又有新的实例处于悬起中(pending),也不会自己打断自己,从而没有重入(reentry)风险
所谓的重入:就是指某段子程序还没有执行完,就因为中断或者是多任务操作系统的调度原因,导致该子程序在一个新的寄存器上下文中被执行(请不要把重入与递归混淆,它们有本质的区别)。这种情况常常会闹乱子,因此有“可重入性”的研究。
中断延迟大大缩短
Cortex-M3 为了缩短中断延迟,引入了好几个新特性。包括自动的现场保护和恢复,以及其它的措施,用于缩短中断嵌套时的 ISR 间延迟。详情请见后面关于“咬尾中断”和“晚到中断”的讲述。
中断可屏蔽
既可以屏蔽优先级低于某个阈值的中断/异常[译注 8](设置BASEPRI寄存器),也可以全体封杀(设置PRIMASK和FAULTMASK寄存器)。这是为了让时间关键( time-critical)的任务能在死线 (deadline,或曰最后期限)到来前完成,而不被干扰 。
2.5 存储器映射

2.6 总线接口
Cortex-M3 内部有若干个总线接口,以使 CM3 能同时取址和访内(访问内存),它们是: 指令存储区总线(两条) 系统总线 私有外设总线
有两条代码存储区总线负责对代码存储区的访问,分别是 I-Code 总线和 D-Code 总线。前者用于取指,后者用于查表等操作,它们按最佳执行速度进行优化。 系统总线用于访问内存和外设,覆盖的区域包括 SRAM,片上外设,片外 RAM,片外扩展设备,以及系统级存储区的部分空间。 私有外设总线负责一部分私有外设的访问,主要就是访问调试组件。它们也在系统级存储区。
2.7 存储器保护单元( MPU)
可以对特权级访问和用户级访问分别施加不同的访问限制。当检测到犯规(violated)时, MPU 就会产生一个 fault 异常,可以由fault 异常的服务例程来分析该错误,并且在可能时改正它。
MPU作用:
(1) 由操作系统使用 MPU,以使特权级代码的数据,包括操作系统本身的数据不被其它用户程序弄坏。
(2) MPU 在保护内存时是按区管理的
(3) 它可以把某些内存 region 设置成只读,从而避免了那里的内容意外被更改;还可以在多任务系统中把不同任务之间的数据区隔离。
2.8 指令集
Cortex-M3 只使用 Thumb-2 指令集 ,同时兼容 32 位指令和 16 位指令
2.9 中断和异常
CM3 的所有中断机制都由 NVIC 实现。除了支持 240 条中断之外, NVIC 还支持 16-4-1=11 个内部异常源,可以实现 fault 管理机制。结果, CM3 就有了 256 个预定义的异常类型。

2.10 低功耗与高能效
-
节能模式上,它提供: 睡眠模式和深度睡眠模式
-
精简电路设计
-
程序密度高,节约执行时间
2.11 调试支持
Cortex-M3 在内核水平上搭载了若干种调试相关的特性。最主要的就是程序执行控制,包括停机(halting)、单步执行(stepping)、指令断点、数据观察点、寄存器和存储器访问、性能速写(profiling)以及各种跟踪机制。
此外, CM3 还能挂载一个所谓的“嵌入式跟踪宏单元(ETM)”。 ETM 可以不断地发出跟踪信息,这些信息通过一个被称为“跟踪端口接口单元(TPIU)”的模块而送到内核的外部,再在芯片外面使用一个“跟踪信息分析仪”,就可以把 TIPU 输出的“已执行指令信息”捕捉到,并且送给调试主机——也就是 PC。
3 Contex-M3基础
3.1 寄存器组
CM3 拥有通用寄存器 R0-R15 以及一些特殊功能寄存器。 R0-R12 是最“通用目的”的,但是绝大多数的 16 位指令只能使用 R0-R7(低组寄存器),而 32 位的 Thumb-2 指令则可以访问所有通用寄存器。特殊功能寄存器有预定义的功能,而且必须通过专用的指令来访问。

特殊功能寄存器:

堆栈指针 R13
R13 是堆栈指针。在 CM3 处理器内核中共有两个堆栈指针,于是也就支持两个堆栈。当引用 R13(或写作 SP)时,引用到的是当前正在使用的那一个,另一个必须用特殊的指令来访问(MRS,MSR指令)。这两个堆栈指针分别是:
主堆栈指针( MSP): 或写作 SP_main。这是缺省的堆栈指针,它由 OS 内核、异常服务例程 以及所有需要特权访问的应用程序代码来使用。
进程堆栈指针( PSP): 或写作 SP_process。用于常规的应用程序代码(不处于异常服用例 程中时)。

连接寄存器 R14
R14 是连接寄存器(LR)。在一个汇编程序中,你可以把它写作 both LR 和 R14。
作用: LR 用于在调用子程序时存储返回地址。
程序计数器 R15
R15 是程序计数器,在汇编代码中一般我们都都叫它的外号“PC”。因为 CM3 内部使用了指令流水线,读 PC 时返回的值是当前指令的地址+4。
3.2 操作模式
Cortex-M3 支持 2 个模式和两个特权等级:
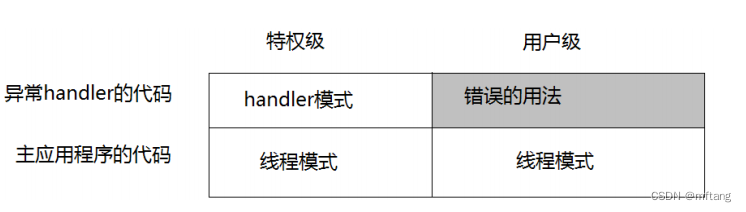
当 CONTROL[0]=0 时,在异常处理的始末,只发生了处理器模式的转换,如下图所示:

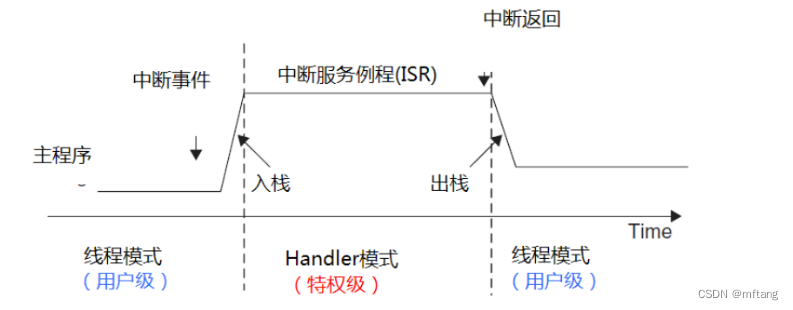
若 CONTROL[0]=1(线程模式+用户级),则在中断响应的始末, 处理器模式和特权等极都要发生变化,如下图所示:
3.3 栈内存操作
堆栈操作就是对内存的读写操作,但是访问地址由 SP 给出 。 寄存器的数据通过 PUSH操作存入堆栈,以后用 POP 操作从堆栈中取回。 在 PUSH 与 POP 的操作中, SP 的值会按堆栈的使用法则自动调整,以保证后续的 PUSH 不会破坏先前 PUSH 进去的内容。

3.4 Cortex-M3 的堆栈实现
Cortex-M3 使用的是“向下生长的满栈”模型。堆栈指针 SP 指向最后一个被压入堆栈的 32 位数值。 在下一次压栈时, SP 先自减 4,再存入新的数值。
在进入 ESR 时, CM3 会自动把一些寄存器压栈,这里使用的是发生本异常的瞬间正在使用的 SP指针(MSP 或者是 PSP)。离开 ESR 后,只要 ESR 没有更改过 CONTROL[1],就依然使用发生本次异常的瞬间正在使用的 SP 指针来执行出栈操作。
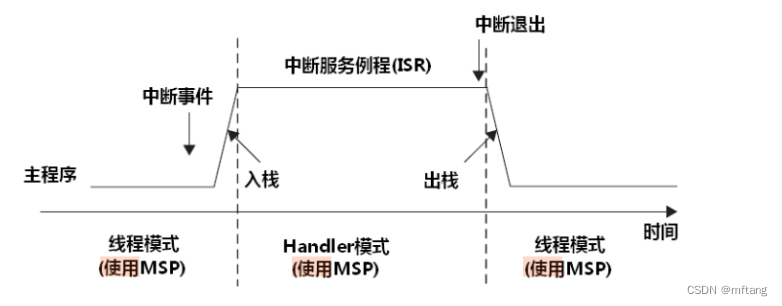
CM3 的堆栈是分为两个:主堆栈和进程堆栈, CONTROL[1]决定如何选择。
当 CONTROL[1]=0 时,只使用 MSP,此时用户程序和异常 handler 共享同一个堆栈。这也是复位后的缺省使用方式。
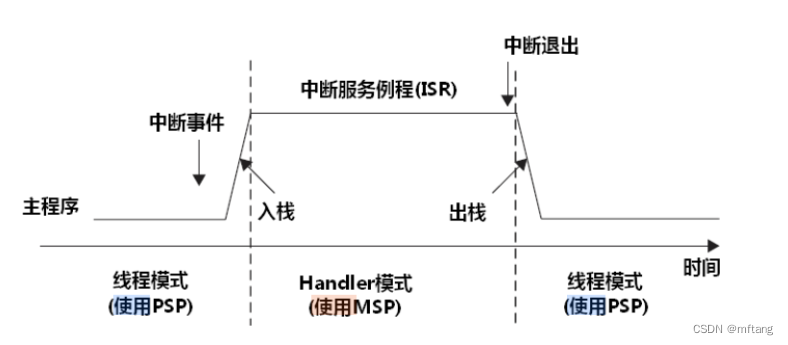
当 CONTROL[1]=1 时,线程模式将不再使用 MSP,而改用 PSP(handler 模式永远使用 MSP)。 在特权级下,可以指定具体的堆栈指针,而不受当前使用堆栈的限制,示例代码如下: MRS R0, MSP ; 读取主堆栈指针到 R0 MSR MSP, R0 ; 写 R0 的值到主堆栈中 MRS R0, PSP ; 读取进程堆栈指针到 R0 MSR PSP, R0 ; 写 R0 的值到进程堆栈中 通过读取 PSP 的值, OS 就能够获取用户应用程序使用的堆栈,进一步地就知道了在发生异常时,被压入寄存器的内容,而且还可以把其它寄存器进一步压栈(使用 STMDB 和 LDMIA 的书写形式)。OS 还可以修改 PSP,用于实现多任务中的任务上下文切换。
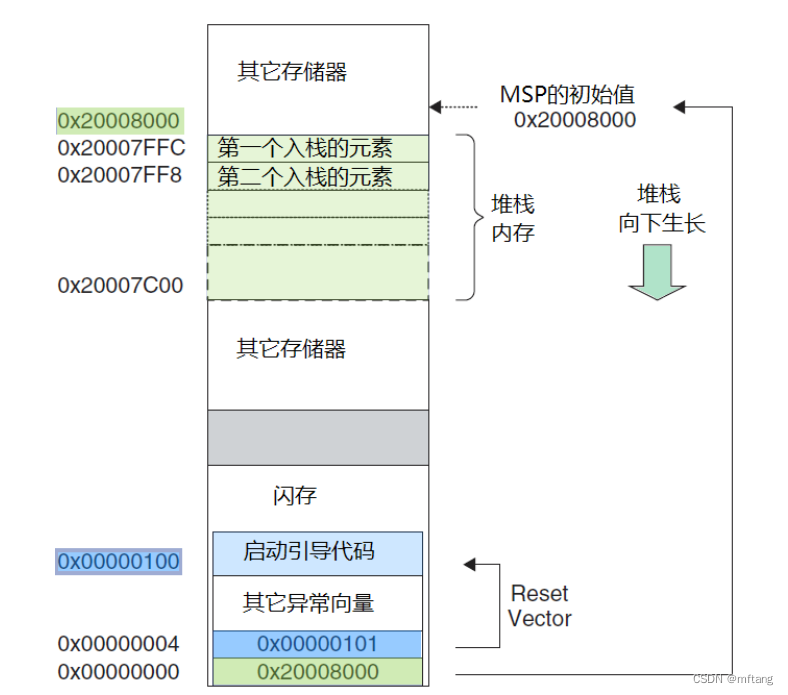
3.8 复位序列
在离开复位状态后, CM3 做的第一件事就是读取下列两个 32 位整数的值 :
1)从地址 0x0000,0000 处取出 MSP 的初始值。
2) 从地址 0x0000,0004 处取出 PC 的初始值——这个值是复位向量, LSB 必须是 1。 然后从这 个值所对应的地址处取指。

请注意,这与传统的 ARM 架构不同——其实也和绝大多数的其它单片机不同。传统的 ARM 架构总是从 0 地址开始执行第一条指令。它们的 0 地址处总是一条跳转指令。 在 CM3 中,在 0 地址处提供 MSP 的初始值,然后紧跟着就是向量表(向量表在以后还可以被移至其它位置——译注)。 向量表中的数值是 32 位的地址,而不是跳转指令。向量表的第一个条目指向复位后应执行的第一条指令。
4. 存储器系统

当使用位带功能时,要访问的变量必须用 volatile 来定义。因为 C 编译器并不知道同一个比特可以有两个地址。所以就要通过 volatile,使得编译器每次都如实地把新数值写入存储器,而不再会出于优化的考虑,在中途使用寄存器来操作数据的复本,直到最后才把复本写回——这会导致按不同的方式访问同一个位会得到不一致的结果
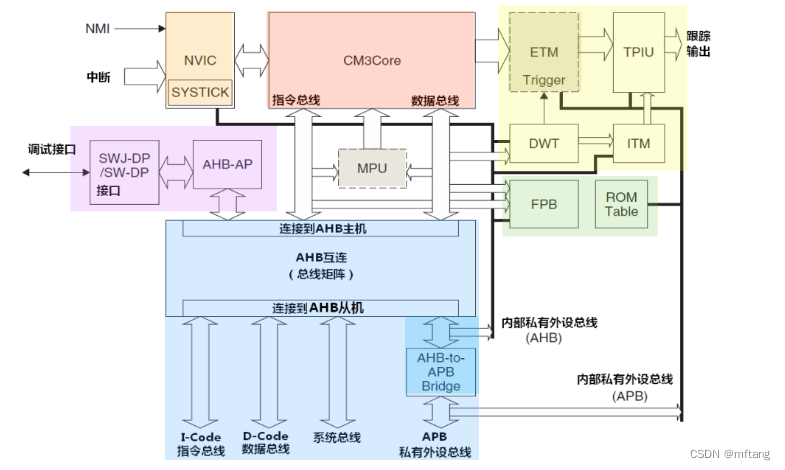
5. 详细的框图







![[大模型]Qwen-7B-hat Transformers 部署调用](https://img-blog.csdnimg.cn/direct/f2b5108b8f8e4ff3894d7c9a53fcf574.png#pic_center)