目录
- 1 简介
- 2 内容
- (1)书生浦语大模型发展历程
- (2)体系
- (3)亮点
- (4)全链路体系构建
- a.数据
- b 预训练
- c 微调
- d 评测
- e.模型部署
- f.agent 智能体
- 3 相关论文解读
- 4 ref
1 简介
-
书生·浦语 InternLM介绍
InternLM 是在过万亿 token 数据上训练的多语千亿参数基座模型。通过多阶段的渐进式训练,InternLM 基座模型具有较高的知识水平,在中英文阅读理解、推理任务等需要较强思维能力的场景下性能优秀,在多种面向人类设计的综合性考试中表现突出。在此基础上,通过高质量的人类标注对话数据结合 RLHF 等技术,使得 InternLM 可以在与人类对话时响应复杂指令,并且表现出符合人类道德与价值观的回复 -
2024.1.17 InternLM V2.0 已经升级成为v2.0 (笔记更新时间2024.4)
-
重要链接汇总
官方github地址 | 官方网址 | 【模型中心-OpenXLab 实战营优秀项目】 | 常见问题QA
2 内容
(1)书生浦语大模型发展历程

(2)体系

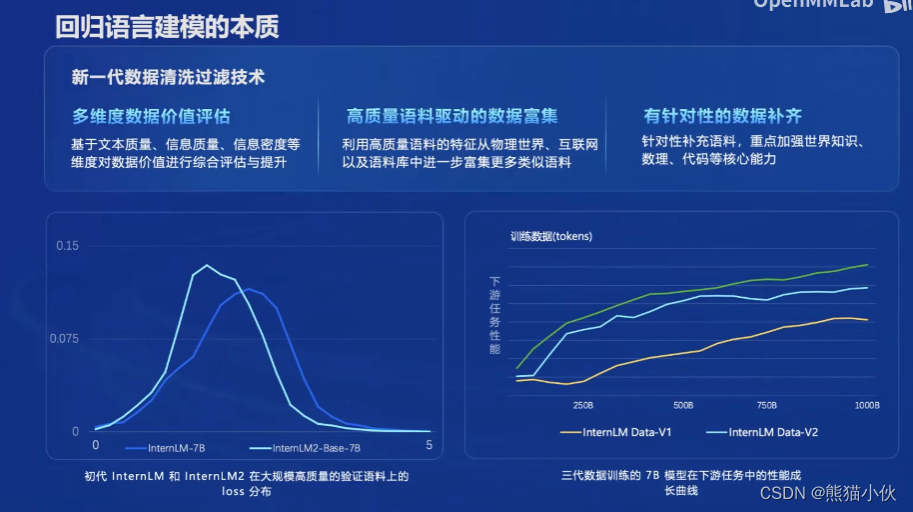
(3)亮点
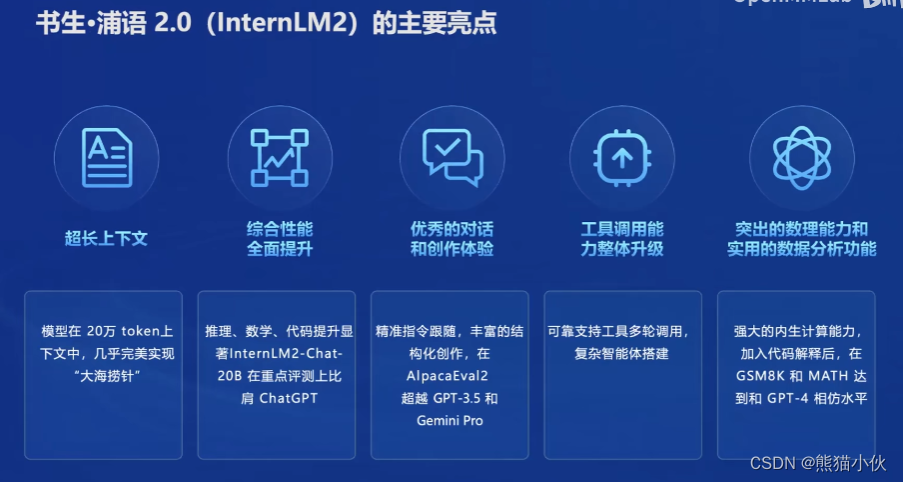
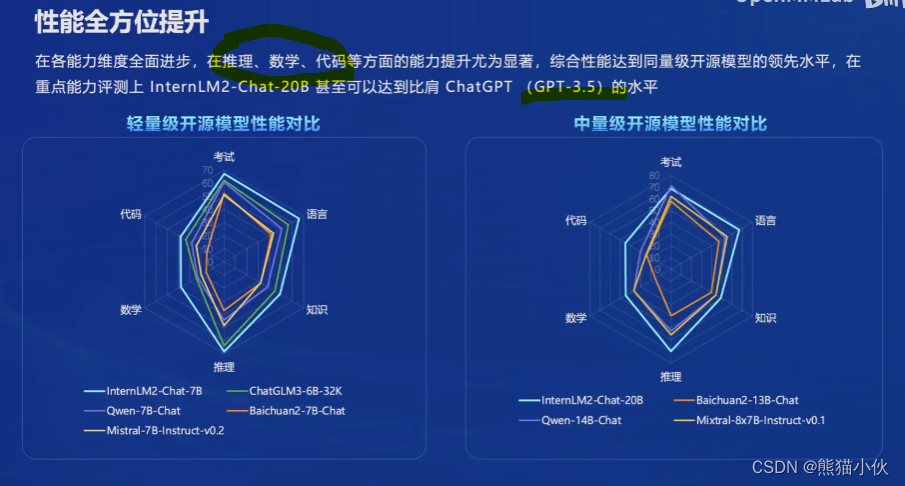 主要表现在:
主要表现在:

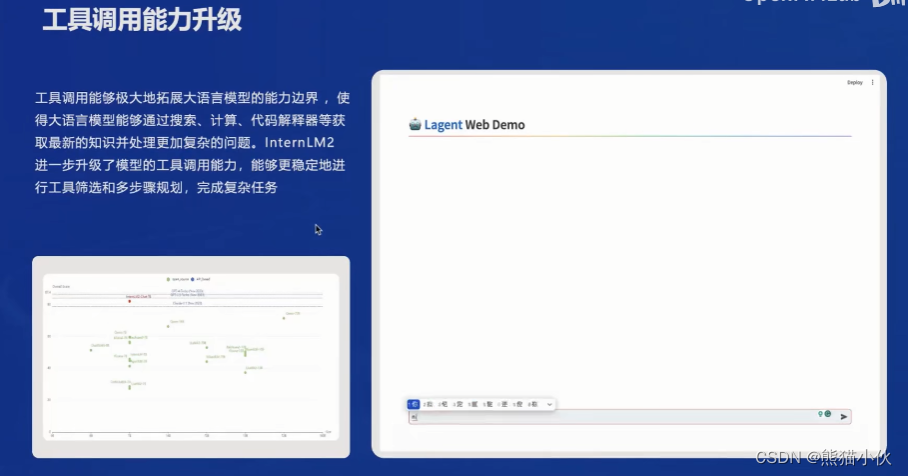
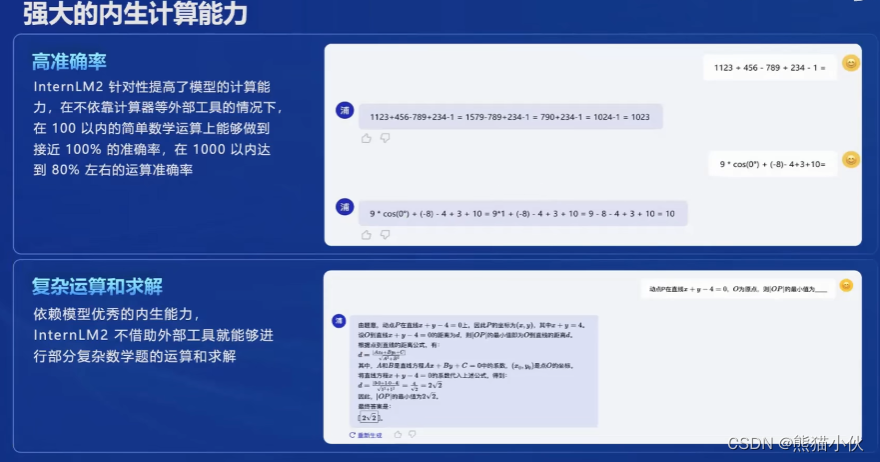
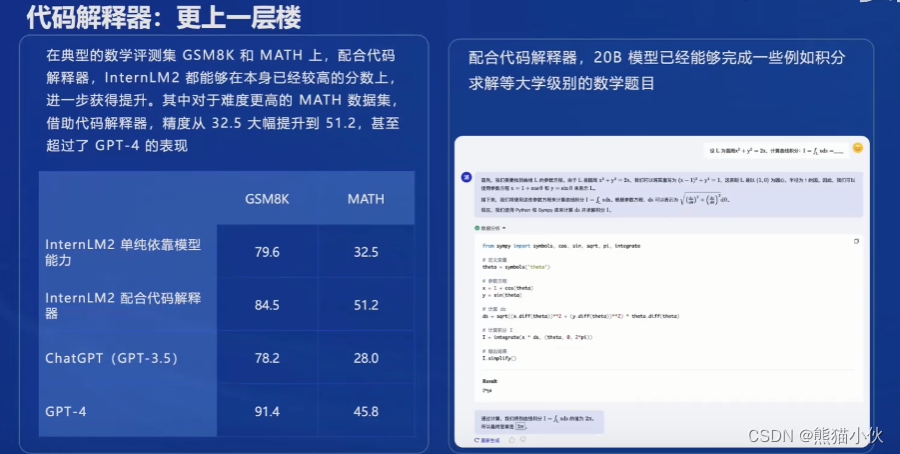
(4)全链路体系构建
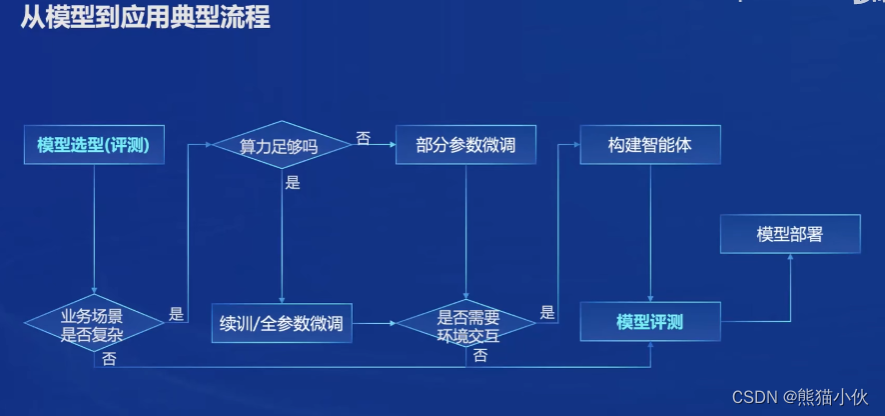

a.数据
万卷 : 官方地址
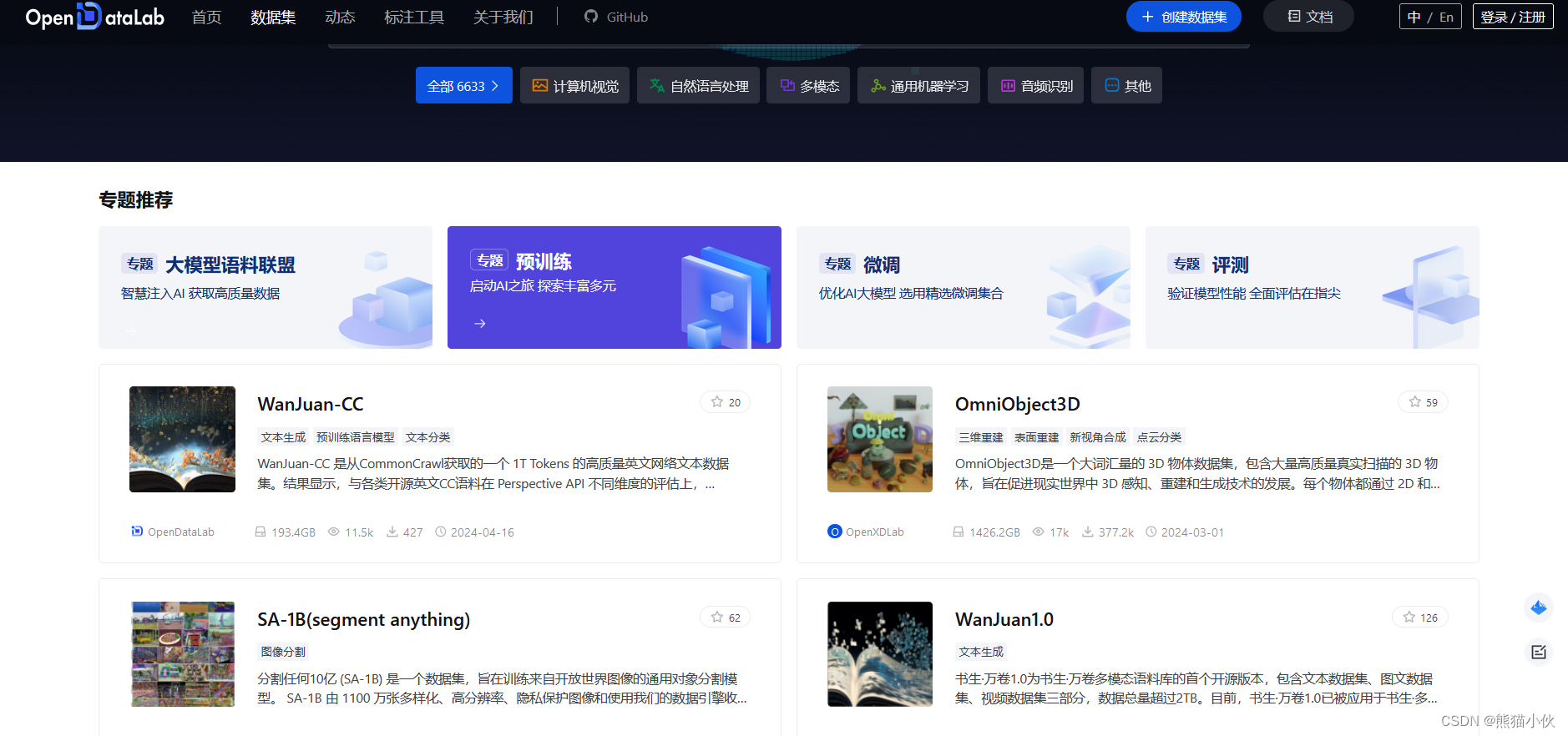
上海人工智能实验室(上海AI实验室)于2023年8月14日宣布开源发布“书生·万卷” 1.0多模态预训练语料。
据了解,“书生·万卷”的主要构建团队——OpenDataLab旨在建设面向人工智能开发者的超大规模、高质量、多模态开放数据服务平台,致力于打造国内公开数据资源的基础建设。
目前,该平台已建立共享的多模态数据集5500个,涵盖超过1万亿token文本语料、60亿张图像、8亿个视频片段和100万个3D模型。

b 预训练

c 微调

xtuner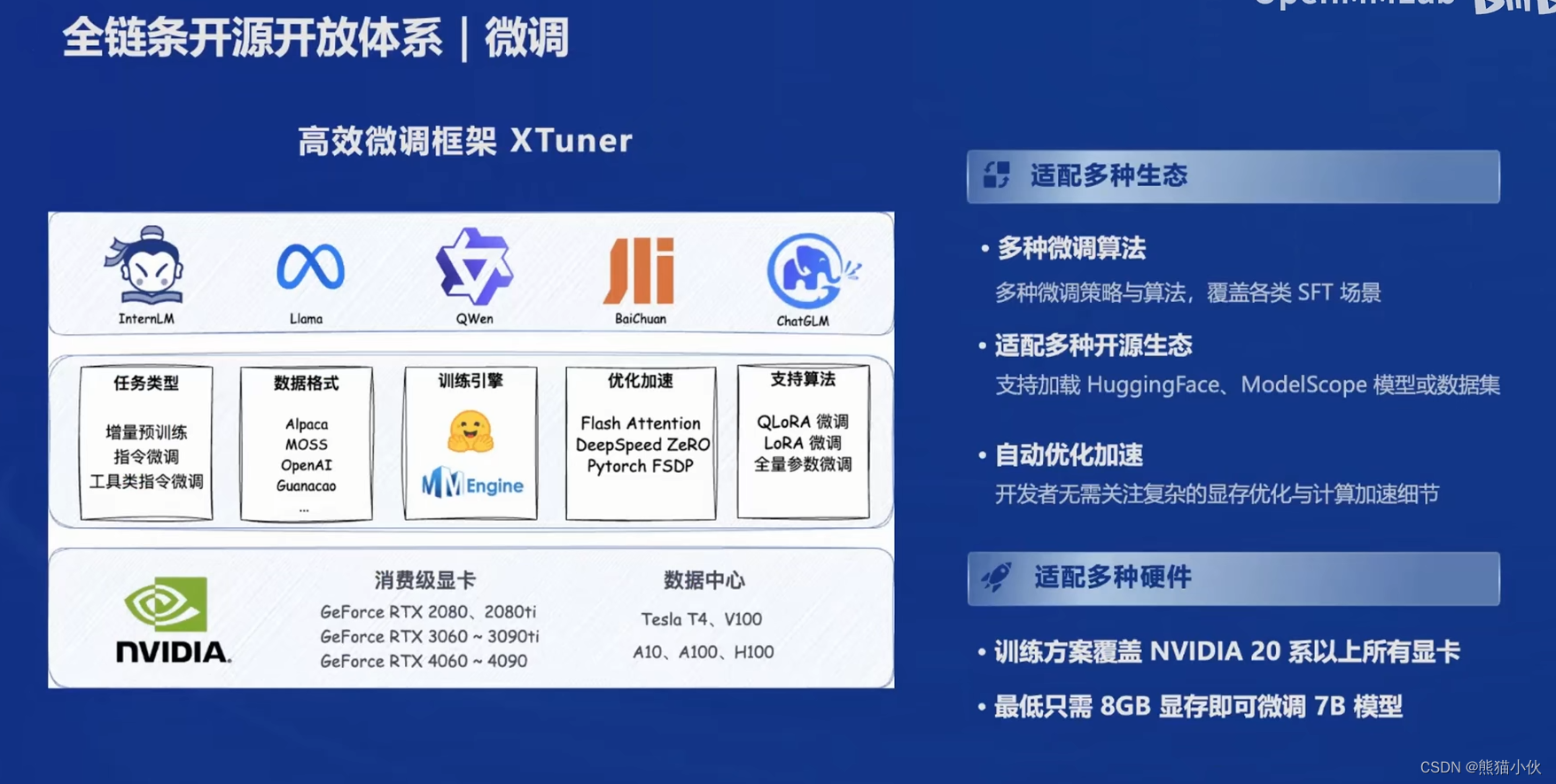
d 评测
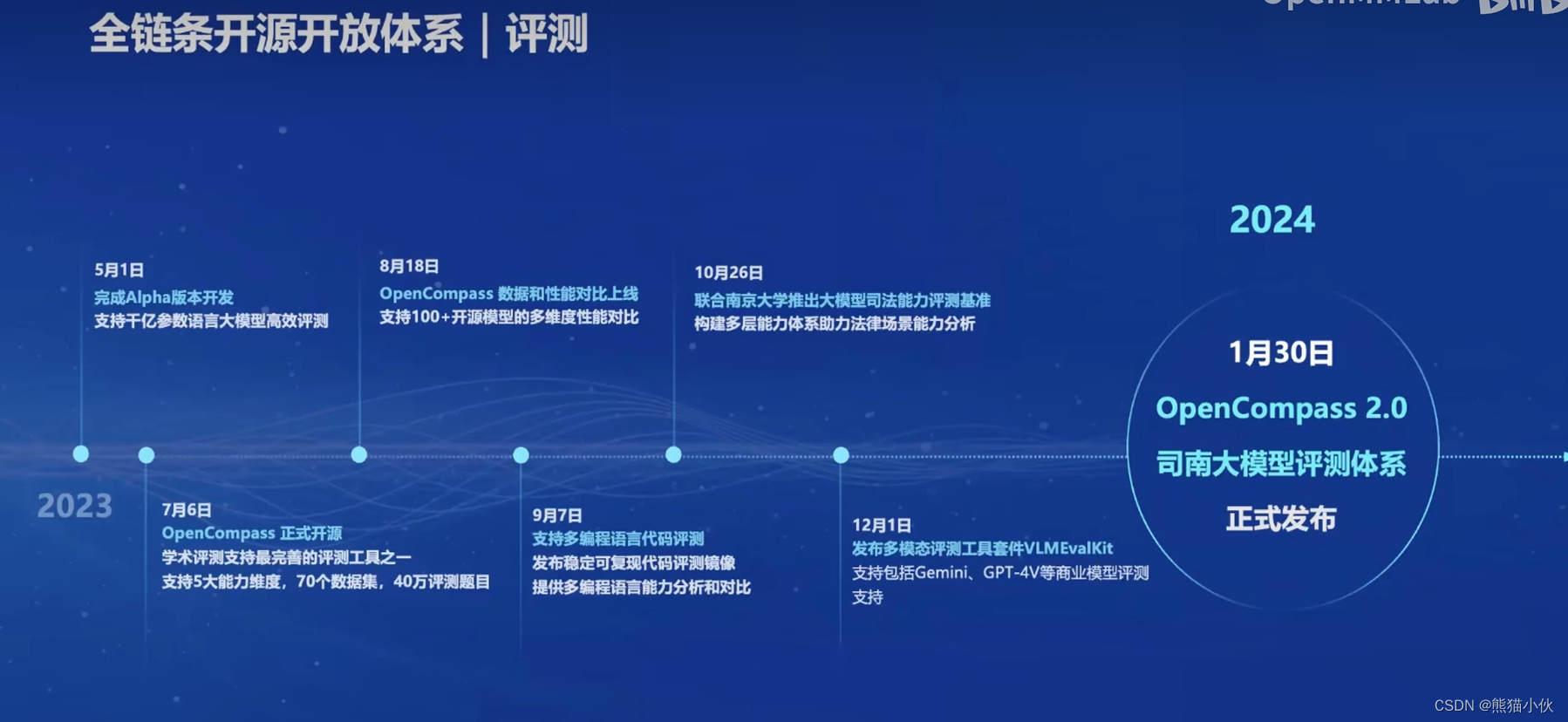

-
重要链接和地址
司南OpenCompass2.0评测体系官网:https://opencompass.org.cn/
GitHub主页:https://github.com/open-compass/OpenCompass/ -
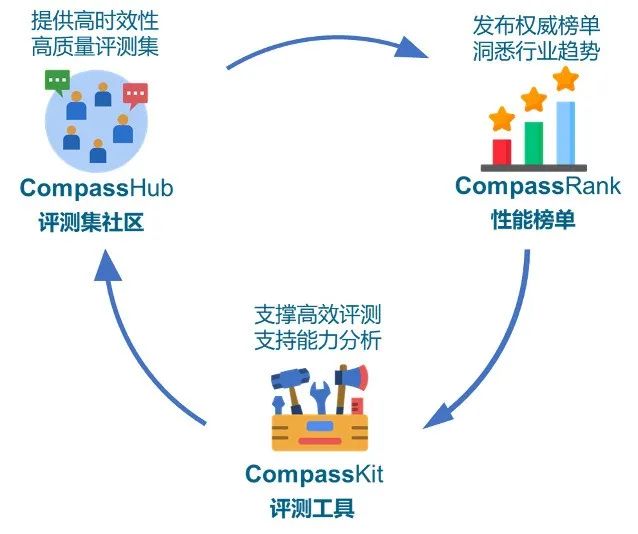
本次发布的OpenCompass2.0,首次推出支撑大模型评测的“铁三角”:
权威评测榜单CompassRank
高质量评测基准社区CompassHub
评测工具链体系CompassKit
基于全新升级的能力体系和工具链,OpenCompass2.0构建了一套高质量的中英文双语评测基准,涵盖语言与理解、常识与逻辑推理、数学计算与应用、多编程语言代码能力、智能体、创作与对话等多个方面对大模型进行评测分析。通过高质量、多层次的综合性能力评测基准,OpenCompass2.0创新了多项能力评测方法,实现了对模型真实能力的全面诊断。
- CompassRank:中立全面的性能榜单
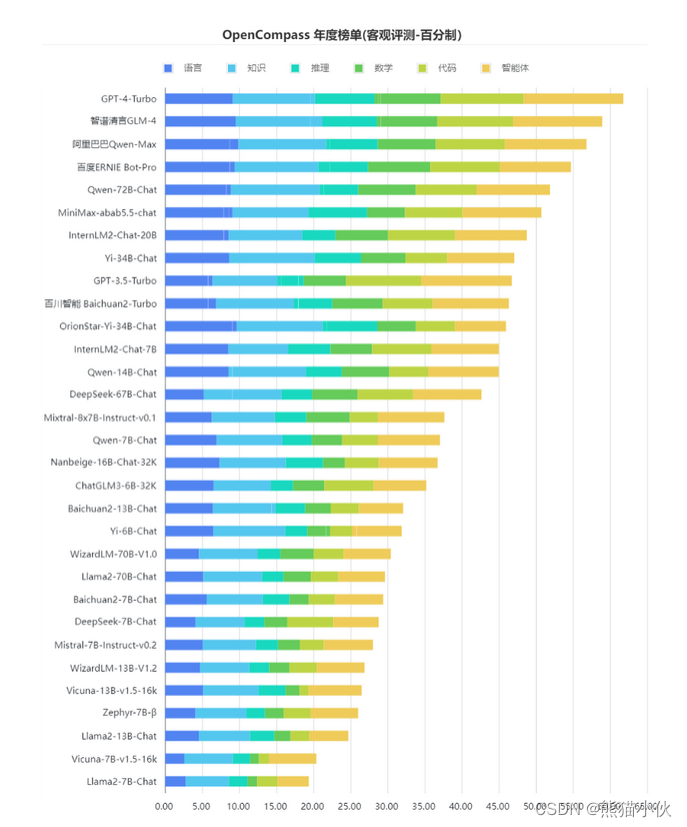
作为OpenCompass2.0中各类榜单的承载平台,CompassRank不受任何商业利益干扰,保持中立性。同时,依托CompassKit工具链体系中的各类评测手段,保证了CompassRank的客观性。CompassRank不仅覆盖多领域、多任务下的模型性能,还将定期更新,提供动态的行业洞察。与此同时,OpenCompass团队将在榜单中提供专业解读,进一步帮助从业者理解技术深意,优化模型选择。
CompassRank 榜单地址:https://rank.opencompass.org.cn/home
- CompassHub:高质量评测基准社区
CompassHub是面向大模型能力评测开源开放的基准社区,提供海量的面向不同能力维度和行业场景的评测基准。OpenCompass2.0欢迎评测用户在CompassHub上传各自构建的高质量评测基准,发布相应的性能榜单,汇聚社区力量助力大模型社区整体快速发展。
CompassHub社区地址:https://hub.opencompass.org.cn/home
- CompassKit:大模型评测全栈工具链
OpenCompass2.0对广受欢迎的初代评测工具库进行了全面优化,推出大模型评测全栈工具链CompassKit,不仅提供完整的开源可复现评测代码,更提供了丰富的模型支持和高效的分布式评测策略。
CompassKit工具链地址:https://github.com/open-compass
CompassKit中包含:
• OpenCompass升级版大语言模型评测工具:提供全面的大模型评测功能,包括广泛模型支持、高效评测速度、主观评测能力、数据污染检查和丰富的长文本评测能力。
• VLMEvalKit多模态大模型评测工具:一站式多模态评测工具,支持主流多模态模型和数据集,助力社区比较不同多模态模型在各种任务上的性能。
• Code-Evaluator代码评测服务工具:提供基于docker的统一编程语言评测环境,确保代码能力评测的稳定性和可复现性。
• MixtralKit MoE模型入门工具:为MoE模型初学者提供学习资料、模型架构解析、推理与评测教程等入门工具。
e.模型部署

f.agent 智能体

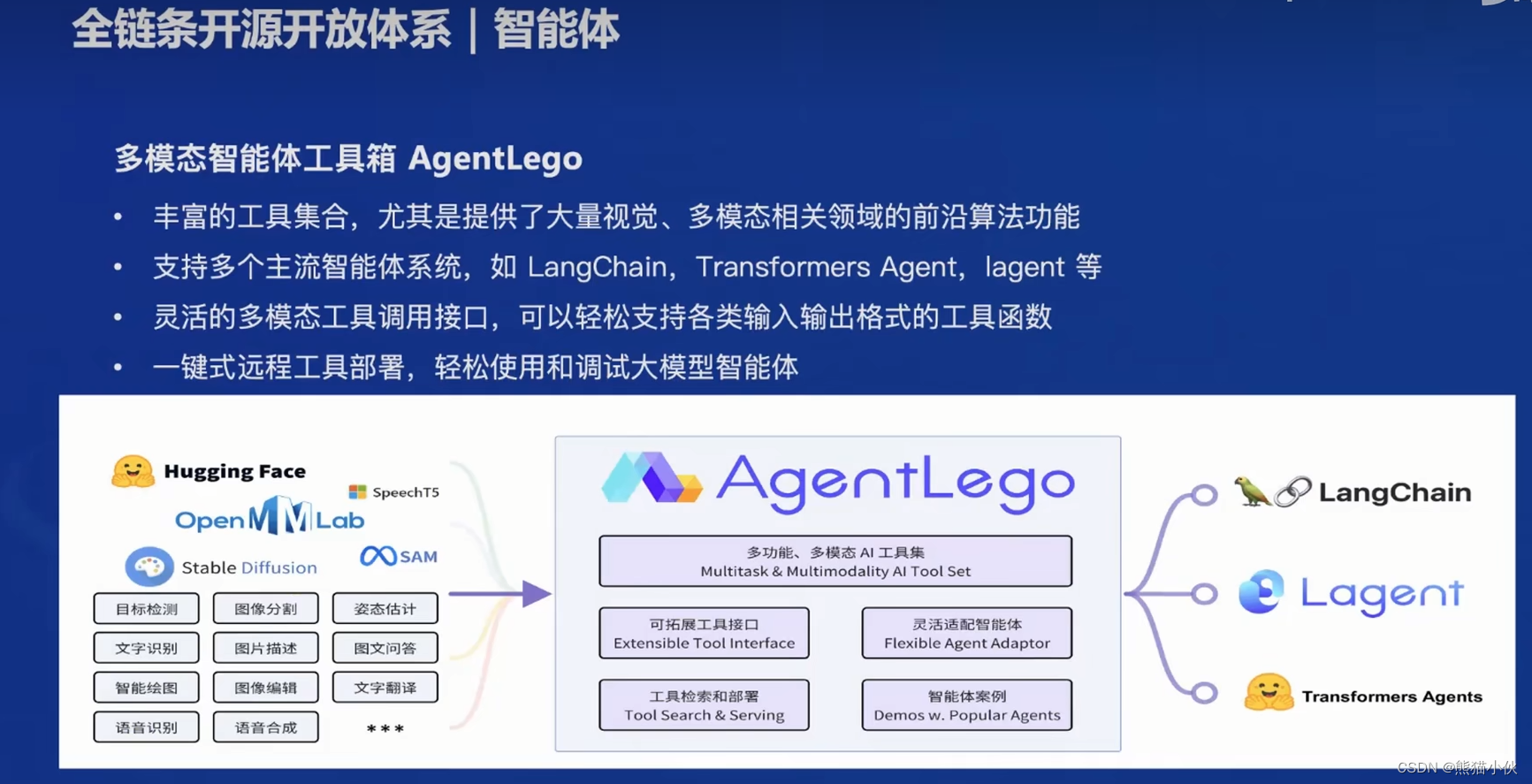
agentlego : 多功能、多模态的AI工具箱
3 相关论文解读
InternLM2 技术报告: https://arxiv.org/pdf/2403.17297.pdf
通义千问 - 文档解读
-
摘要翻译:
随着诸如ChatGPT和GPT-4这样的大型语言模型(LLMs)的发展,引发了关于通用人工智能(AGI)到来的讨论。然而,在开源模型中复制此类进展颇具挑战性。本文介绍了一款名为InternLM2的开源LLM,它通过创新的预训练和优化技术,在六个维度、三十个基准测试以及长程建模和开放式主观评估方面超越了其前身。InternLM2的预训练过程详尽阐述,突出了包括文本、代码及长程数据在内的多种数据类型的准备。该模型在预训练和微调阶段初始以4k令牌进行训练,随后提升至32k令牌,展现出在20万字符级别的“大海捞针”测试中的卓越性能。进一步地,通过监督精细调整(Supervised Fine-Tuning, SFT)和新颖的基于人类反馈的条件在线强化学习策略(Conditional Online Reinforcement Learning from Human Feedback, COOL RLHF),InternLM2解决了人类偏好冲突和奖励破解问题,并实现了对模型的校准。通过发布不同训练阶段和模型规模的InternLM2模型,我们为社区提供了有关模型演进的深入见解。 -
各标题内容翻译:
1.引言
讨论大型语言模型的进步与开源领域面临的挑战,引出InternLM2模型的推出及其优势。
2.基础设施
描述InternLM2的研发基础设施,如InternEvo平台和模型结构设计。
3.预训练
细致说明预训练数据的来源与处理,包括文本数据、代码数据和长程上下文数据的准备。
4.性能评估与分析
提供全面的语言模型在多个领域和任务上的表现评估与分析。
a.下游任务性能
b.全面评估:在一系列涵盖人文科学、社会科学、STEM等多个学科领域的多选题数据集(如MMLU)上进行基准测试。
c.语言与知识应用
d.推理与数学能力验证:涉及WinoGrande、HellaSwag和BigBench Hard等推理与数学相关的多项选择题数据集。
e.多编程语言编码能力
f.长程建模性能
g.工具利用能力
- 文档内容相关亮点与优点分析:
InternLM2模型的主要亮点在于:
(1) 开源性:作为一款开源LLM,InternLM2在各种综合评测和基准测试中表现出优于前代模型的能力,这有利于学术界和产业界共同推进AI技术的发展和应用。
(2)预训练技术创新:采用多样化的预训练数据类型,并有效捕捉长程依赖关系,提升了模型在长文本理解和生成、跨领域知识运用等方面的表现。
(3)强化学习与校准:通过SFT和COOL RLHF策略对模型进行进一步校准,解决了大规模预训练模型在处理复杂情境下的人类偏好表达和奖励机制安全问题。
(4)表现优异:在阅读理解、开放域问答、多语言翻译等多种NLP下游任务上取得突出成绩,显示出强大的语言理解和知识应用能力。
- 这篇技术报告的主要贡献有两个方面:
1.开源高性能的InternLM2模型:团队发布了各种规模的InternLM2模型,包括1.8B、7B和20B参数量级的版本,并且这些模型在主观和客观评价中均表现出色。为了便于社区分析SFT(监督微调)和RLHF(基于人类反馈的强化学习)训练阶段的变化,他们还提供了不同训练阶段的模型版本。
2.针对长上下文场景的设计与实践:InternLM2针对长序列上下文信息处理进行了特别优化,能够在一个200k的上下文窗口中近乎完美地识别“Needle-in-a-Haystack”测试中的目标元素。研究人员详尽介绍了在整个预训练、SFT以及RLHF各个阶段训练长上下文LLM的经验和方法。
3.全面的数据准备指南:团队详细记录了为LLM准备不同类型数据的过程,包括预训练数据、领域特异性增强数据、SFT数据以及RLHF数据,这将有助于社区更有效地训练大型语言模型。
通过上述贡献,InternLM2项目不仅展示了在众多基准任务上的优越性能,而且为如何分阶段地进行大规模语言模型的研发提供了一套完整的解决方案。
4 ref
1.书生·浦语大模型全链路开源开放体系(视频)
2.一文读懂司南大模型评测体系OpenCompass
3.通义千问