Kafka 3.x.x 入门到精通(03)——对标尚硅谷Kafka教程
- 2. Kafka基础
- 2.1 集群部署
- 2.2 集群启动
- 2.3 创建主题
- 2.4 生产消息
- 2.4.1 生产消息的基本步骤
- 2.4.2 生产消息的基本代码
- 2.4.3 发送消息
- 2.4.3.1 拦截器
- 2.4.3.1.1 增加拦截器类
- 2.4.3.1.2 配置拦截器
- 2.4.3.2 回调方法
- 2.4.3.3 异步发送
- 2.4.3.4 同步发送
- 2.4.4 消息分区
- 2.4.4.1 指定分区
- 2.4.4.2 未指定分区⚠️
- 2.4.4.3 分区器
- 2.4.4.3.1 增加分区器类
- 2.4.4.3.2 配置分区器
- 2.4.5 消息可靠性
- 2.4.5.1 ACK = 0
- 2.4.5.2 ACK = 1
- 2.4.5.3 ACK = -1(ALL)(默认)
- 2.4.6 消息去重 & 有序
- 2.4.6.1数据重试
- 2.4.6.2数据乱序
- 2.4.6.3 数据幂等性
- 2.4.6.4数据事务
- 2.4.6.4.1 普通数据发送流程
- 2.4.6.4.2 事务数据发送流程
- 2.4.6.4.3 事务提交流程
- 2.4.6.4.4 事务操作代码
- 2.4.6.5 数据传输语义


本文档参看的视频是:
- [尚硅谷Kafka教程,2024新版kafka视频,零基础入门到实战](https://www.bilibili.com/video/BV1Gp421m7UN/? p=6&spm_id_from=pageDriver&vd_source=9beb0a2f0cec6f01c2433a881b54152c)
- 黑马程序员Kafka视频教程,大数据企业级消息队列kafka入门到精通
- 小朋友也可以懂的Kafka入门教程,还不快来学
本文档参看的文档是:
- 尚硅谷官方文档,并在基础上修改 完善!非常感谢尚硅谷团队!!!!
在这之前大家可以看我以下几篇文章,循序渐进:
❤️Kafka 3.x.x 入门到精通(01)——对标尚硅谷Kafka教程
❤️Kafka 3.x.x 入门到精通(02)——对标尚硅谷Kafka教程
2. Kafka基础
2.1 集群部署
❤️Kafka 3.x.x 入门到精通(02)——对标尚硅谷Kafka教程
2.2 集群启动
❤️Kafka 3.x.x 入门到精通(02)——对标尚硅谷Kafka教程
2.3 创建主题
❤️Kafka 3.x.x 入门到精通(02)——对标尚硅谷Kafka教程
2.4 生产消息
Topic主题已经创建好了,接下来我们就可以向该主题生产消息了,这里我们采用Java代码通过
Kafka Producer API的方式生产数据。
2.4.1 生产消息的基本步骤
(一)创建Map类型的配置对象,根据场景增加相应的配置属性。
(二)创建待发送数据
在kafka中传递的数据我们称之为消息(message)或记录(record),所以Kafka发送数据前,需要将待发送的数据封装为指定的数据模型:
下面的代码,我们很熟悉吧~ 包括topic、key、value
但是! 其实对于表述一份完整的Record 是不完整的!那完整的是什么样的呢~~

like this~


相关属性必须在构建数据模型时指定,其中主题和value的值是必须要传递的。如果配置中开启了自动创建主题,那么Topic主题可以不存在。value就是我们需要真正传递的数据了,而Key可以用于数据的分区定位。
(三)创建生产者对象,发送生产的数据:
根据前面提供的配置信息创建生产者对象,通过这个生产者对象向Kafka服务器节点发送数据,而具体的发送是由生产者对象创建时,内部构建的多个组件实现的,多个组件的关系有点类似于生产者消费者模式。

(1) 数据生产者(KafkaProducer):生产者对象,用于对我们的数据进行必要的转换和处理,将处理后的数据放入到数据收集器中,类似于生产者消费者模式下的生产者。这里我们简单介绍一下内部的数据转换处理:
- 如果配置拦截器栈(interceptor.classes),那么将数据进行拦截处理。某一个拦截器出现异常并不会影响后续的拦截器处理。
- 因为发送的数据为KV数据,所以需要根据配置信息中的序列化对象对数据中Key和Value分别进行序列化处理。
- 计算数据所发送的分区位置。
- 将数据追加到数据收集器中。
(2) 数据收集器(RecordAccumulator):用于收集,转换我们产生的数据,类似于生产者消费者模式下的缓冲区。为了优化数据的传输,Kafka并不是生产一条数据就向Broker发送一条数据,而是通过合并单条消息,进行批量(批次)发送,提高吞吐量,减少带宽消耗。
- 默认情况下,一个发送批次的数据容量为16K,这个可以通过参数batch.size进行改善。
- 批次是和分区进行绑定的。也就是说发往同一个分区的数据会进行合并,形成一个批次。
- 如果当前批次能容纳数据,那么直接将数据追加到批次中即可,如果不能容纳数据,那么会产生新的批次放入到当前分区的批次队列中,这个队列使用的是Java的双端队列Deque。旧的批次关闭不再接收新的数据,等待发送
(3) 数据发送器(Sender):线程对象,用于从收集器对象中获取数据,向服务节点发送。类似于生产者消费者模式下的消费者。因为是线程对象,所以启动后会不断轮询获取数据收集器中已经关闭的批次数据。对批次进行整合后再发送到Broker节点中
-
因为数据真正发送的地方是
Broker节点,不是分区。所以需要将从数据收集器中收集到的批次数据按照可用Broker节点重新组合成List集合。 -
将组合后的
<节点,List<批次>>的数据封装成客户端请求(请求键为:Produce)发送到网络客户端对象的缓冲区,由网络客户端对象通过网络发送给Broker节点。 -
Broker节点获取客户端请求,并根据请求键进行后续的数据处理:向分区中增加数据。

2.4.2 生产消息的基本代码

// TODO 配置属性集合
Map<String, Object> configMap = new HashMap<>();
// TODO 配置属性:Kafka服务器集群地址
configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// TODO 配置属性:Kafka生产的数据为KV对,所以在生产数据进行传输前需要分别对K,V进行对应的序列化操作
configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
// TODO 创建Kafka生产者对象,建立Kafka连接
// 构造对象时,需要传递配置参数
KafkaProducer<String, String> producer = new KafkaProducer<>(configMap);
// TODO 准备数据,定义泛型
// 构造对象时需要传递 【Topic主题名称】,【Key】,【Value】三个参数
ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key1", "value1"
);
// TODO 生产(发送)数据
producer.send(record);
// TODO 关闭生产者连接
producer.close();
两个线程
在生产者客户端中,主要通过两个线程协调运行:主线程和Sender线程
主线程
主线程负责创建消息,然后将消息传递给拦截器、序列化器和分区器,最后将消息缓存到消息累加器
Sender线程
sender线程负责从消息累加器中获取消息,然后进行组装成<Node, List< ProducerBatch>>, -> <Node,Request> ->Map<Nodeld, Deque<Request>>这样的形式发送到对应的broker中
ProducerBatch
ProducerBatch包含多个ProducerRecord,目的是为了消息更加紧凑,提高吞吐量
BufferPool
因为kafka内部是通过ByteBuffer创建和释放内存,ByteBuffer的创建 是很消耗资源的,为了解决这个问题,Kafka封装了BufferPool实现ByteBuffer重复使用,当然并不是所有大小的ByteBuffer都可以缓存 到BufferPoll中的,可以通过配置batch.size,如果小于等于这个大小则可以被缓存到pool中,默认16kb.ProducerBatch 也和这个参数关联。
2.4.3 发送消息
2.4.3.1 拦截器
生产者API在数据准备好发送给Kafka服务器之前,允许我们对生产的数据进行统一的处理,比如校验,整合数据等等。这些处理我们是可以通过Kafka提供的拦截器完成。因为拦截器不是生产者必须配置的功能,所以大家可以根据实际的情况自行选择使用。
但是要注意,这里的拦截器是可以配置多个的。执行时,会按照声明顺序执行完一个后,再执行下一个。并且某一个拦截器如果出现异常,只会跳出当前拦截器逻辑,并不会影响后续拦截器的处理。所以开发时,需要将拦截器的这种处理方法考虑进去。

接下来,我们来演示一下拦截器的操作
2.4.3.1.1 增加拦截器类
(1) 实现生产者拦截器接口ProducerInterceptor
package com.atguigu.test;import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;import java.util.Map;/*** TODO 自定义数据拦截器* 1. 实现Kafka提供的生产者接口ProducerInterceptor* 2. 定义数据泛型 <K, V>* 3. 重写方法* onSend* onAcknowledgement* close* configure*/
public class KafkaInterceptorMock implements ProducerInterceptor<String, String> {@Overridepublic ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {return record;}@Override public void onAcknowledgement(RecordMetadata metadata, Exception exception) {}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}(2) 实现接口中的方法,根据业务功能重写具体的方法
| 方法名 | 作用 |
|---|---|
| onSend | 数据发送前,会执行此方法,进行数据发送前的预处理 |
| onAcknowledgement | 数据发送后,获取应答时,会执行此方法 |
| close | 生产者关闭时,会执行此方法,完成一些资源回收和释放的操作 |
| configure | 创建生产者对象的时候,会执行此方法,可以根据场景对生产者对象的配置进行统一修改或转换。 |
2.4.3.1.2 配置拦截器
package com.atguigu.test;import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.Future;public class ProducerInterceptorTest {public static void main(String[] args) {Map<String, Object> configMap = new HashMap<>();configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configMap.put( ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());configMap.put( ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());configMap.put( ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, KafkaInterceptorMock.class.getName());KafkaProducer<String, String> producer = null;try {producer = new KafkaProducer<>(configMap);for ( int i = 0; i < 1; i++ ) {ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key" + i, "value" + i);final Future<RecordMetadata> send = producer.send(record);}} catch ( Exception e ) {e.printStackTrace();} finally {if ( producer != null ) {producer.close();}}}
}
2.4.3.2 回调方法
Kafka发送数据时,可以同时传递回调对象(Callback)用于对数据的发送结果进行对应处理,具体代码实现采用匿名类或Lambda表达式都可以。

package com.atguigu.kafka.test;import org.apache.kafka.clients.producer.*;import java.util.HashMap;
import java.util.Map;public class KafkaProducerASynTest {public static void main(String[] args) {Map<String, Object> configMap = new HashMap<>();configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> producer = new KafkaProducer<>(configMap);// TODO 循环生产数据for ( int i = 0; i < 1; i++ ) {// TODO 创建数据ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key" + i, "value" + i);// TODO 发送数据producer.send(record, new Callback() {// TODO 回调对象public void onCompletion(RecordMetadata recordMetadata, Exception e) {// TODO 当数据发送成功后,会回调此方法System.out.println("数据发送成功:" + recordMetadata.timestamp());}});}producer.close();}
}
2.4.3.3 异步发送
Kafka发送数据时,底层的实现类似于生产者消费者模式。对应的,底层会由主线程代码作为生产者向缓冲区中放数据,而数据发送线程会从缓冲区中获取数据进行发送。Broker接收到数据后进行后续处理。
如果Kafka通过主线程代码将一条数据放入到缓冲区后,无需等待数据的后续发送过程,就直接发送一下条数据的场合,我们就称之为异步发送。


package com.atguigu.kafka.test;import org.apache.kafka.clients.producer.*;import java.util.HashMap;
import java.util.Map;public class KafkaProducerASynTest {public static void main(String[] args) {Map<String, Object> configMap = new HashMap<>();configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> producer = new KafkaProducer<>(configMap);// TODO 循环生产数据for ( int i = 0; i < 10; i++ ) {// TODO 创建数据ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key" + i, "value" + i);// TODO 发送数据producer.send(record, new Callback() {// TODO 回调对象public void onCompletion(RecordMetadata recordMetadata, Exception e) {// TODO 当数据发送成功后,会回调此方法System.out.println("数据发送成功:" + recordMetadata.timestamp());}});// TODO 发送当前数据System.out.println("发送数据");}producer.close();}
}

2.4.3.4 同步发送
Kafka发送数据时,底层的实现类似于生产者消费者模式。对应的,底层会由主线程代码作为生产者向缓冲区中放数据,而数据发送线程会从缓冲区中获取数据进行发送。Broker接收到数据后进行后续处理。
如果Kafka通过主线程代码将一条数据放入到缓冲区后,需等待数据的后续发送操作的应答状态,才能发送一下条数据的场合,我们就称之为同步发送。所以这里的所谓同步,就是生产数据的线程需要等待发送线程的应答(响应)结果。
代码实现上,采用的是JDK1.5增加的JUC并发编程的Future接口的get方法实现。

package com.atguigu.kafka.test;import org.apache.kafka.clients.producer.*;import java.util.HashMap;
import java.util.Map;public class KafkaProducerASynTest {public static void main(String[] args) throws Exception {Map<String, Object> configMap = new HashMap<>();configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> producer = new KafkaProducer<>(configMap);// TODO 循环生产数据for ( int i = 0; i < 10; i++ ) {// TODO 创建数据ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key" + i, "value" + i);// TODO 发送数据producer.send(record, new Callback() {// TODO 回调对象public void onCompletion(RecordMetadata recordMetadata, Exception e) {// TODO 当数据发送成功后,会回调此方法System.out.println("数据发送成功:" + recordMetadata.timestamp());}}).get();// TODO 发送当前数据System.out.println("发送数据");}producer.close();}
}
2.4.4 消息分区
2.4.4.1 指定分区
Kafka中Topic是对数据逻辑上的分类,而Partition才是数据真正存储的物理位置。所以在生产数据时,如果只是指定Topic的名称,其实Kafka是不知道将数据发送到哪一个Broker节点的。我们可以在构建数据传递Topic参数的同时,也可以指定数据存储的分区编号。

for ( int i = 0; i < 1; i++ ) {ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", 0, "key" + i, "value" + i);final Future<RecordMetadata> send = producer.send(record, new Callback() {public void onCompletion(RecordMetadata recordMetadata, Exception e) {if ( e != null ) {e.printStackTrace();} else {System.out.println("数据发送成功:" + record.key() + "," + record.value());}}});
}
2.4.4.2 未指定分区⚠️
指定分区传递数据是没有任何问题的。Kafka会进行基本简单的校验,比如是否为空,是否小于0之类的,但是你的分区是否存在就无法判断了,所以需要从Kafka中获取集群元数据信息,此时会因为长时间获取不到元数据信息而出现超时异常。所以如果不能确定分区编号范围的情况,不指定分区还是一个不错的选择。
如果不指定分区,Kafka会根据集群元数据中的主题分区来通过算法来计算分区编号并设定:
- (1) 如果指定了分区,直接使用
- (2) 如果指定了自己的分区器,通过分区器计算分区编号,如果有效,直接使用
- (3) 如果指定了数据Key,且使用Key选择分区的场合,采用
murmur2非加密散列算法(类似于hash)计算数据Key序列化后的值的散列值,然后对主题分区数量模运算取余,最后的结果就是分区编号

- (4) 如果未指定数据Key,或不使用Key选择分区,那么Kafka会采用优化后的
粘性分区策略进行分区选择:- 没有分区数据加载状态信息时,会从分区列表中随机选择一个分区。

- 如果存在分区数据加载状态信息时,根据分区数据队列加载状态,通过随机数获取一个权重值

- 根据这个权重值在队列加载状态中进行二分查找法,查找权重值的索引值

- 将这个索引值加1就是当前设定的分区。

- 增加数据后,会根据当前粘性分区中生产的数据量进行判断,是不是需要切换其他的分区。判断地标准就是大于等于批次大小(16K)的2倍,或大于一个批次大小(16K)且需要切换。如果满足条件,下一条数据就会放置到其他分区。
- 没有分区数据加载状态信息时,会从分区列表中随机选择一个分区。
2.4.4.3 分区器
在某些场合中,指定的数据我们是需要根据自身的业务逻辑发往指定的分区的。所以需要自己定义分区编号规则,而不是采用Kafka自动设置就显得尤其必要了。Kafka早期版本中提供了两个分区器,不过在当前kafka版本中已经不推荐使用了。

接下来我们就说一下当前版本Kafka中如何定义我们自己的分区规则:分区器
2.4.4.3.1 增加分区器类
首先我们需要创建一个类,然后实现Kafka提供的分区类接口Partitioner,接下来重写方法。这里我们只关注partition方法即可,因为此方法的返回结果就是需要的分区编号。
package com.atguigu.test;import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;import java.util.Map;/*** TODO 自定义分区器实现步骤:* 1. 实现Partitioner接口* 2. 重写方法* partition : 返回分区编号,从0开始* close* configure*/
public class KafkaPartitionerMock implements Partitioner {/*** 分区算法 - 根据业务自行定义即可* @param topic The topic name* @param key The key to partition on (or null if no key)* @param keyBytes The serialized key to partition on( or null if no key)* @param value The value to partition on or null* @param valueBytes The serialized value to partition on or null* @param cluster The current cluster metadata* @return 分区编号,从0开始*/@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {return 0;}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
2.4.4.3.2 配置分区器
package com.atguigu.test;import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.Future;public class ProducerPartitionTest {public static void main(String[] args) {Map<String, Object> configMap = new HashMap<>();configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configMap.put( ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());configMap.put( ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());configMap.put( ProducerConfig.PARTITIONER_CLASS_CONFIG, KafkaPartitionerMock.class.getName());KafkaProducer<String, String> producer = null;try {producer = new KafkaProducer<>(configMap);for ( int i = 0; i < 1; i++ ) {ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key" + i, "value" + i);final Future<RecordMetadata> send = producer.send(record, new Callback() {public void onCompletion(RecordMetadata recordMetadata, Exception e) {if ( e != null ) {e.printStackTrace();} else {System.out.println("数据发送成功:" + record.key() + "," + record.value());}}});}} catch ( Exception e ) {e.printStackTrace();} finally {if ( producer != null ) {producer.close();}}}
}
2.4.5 消息可靠性
对于生产者发送的数据,我们有的时候是不关心数据是否已经发送成功的,我们只要发送就可以了。在这种场景中,消息可能会因为某些故障或问题导致丢失,我们将这种情况称之为消息不可靠。虽然消息数据可能会丢失,但是在某些需要高吞吐,低可靠的系统场景中,这种方式也是可以接受的,甚至是必须的。
但是在更多的场景中,我们是需要确定数据是否已经发送成功了且Kafka正确接收到数据的,也就是要保证数据不丢失,这就是所谓的消息可靠性保证。
而这个确定的过程一般是通过Kafka给我们返回的响应确认结果(Acknowledgement)来决定的,这里的响应确认结果我们也可以简称为ACK应答。根据场景,Kafka提供了3种应答处理,可以通过配置对象进行配置

2.4.5.1 ACK = 0
效率最高,可靠性低
当生产数据时,生产者对象将数据通过网络客户端将数据发送到网络数据流中的时候,Kafka就对当前的数据请求进行了响应(确认应答),如果是同步发送数据,此时就可以发送下一条数据了。如果是异步发送数据,回调方法就会被触发。

通过图形,明显可以看出,这种应答方式,数据已经走网络给Kafka发送了,但这其实并不能保证Kafka能正确地接收到数据,在传输过程中如果网络出现了问题,那么数据就丢失了。也就是说这种应答确认的方式,数据的可靠性是无法保证的。不过相反,因为无需等待Kafka服务节点的确认,通信效率倒是比较高的,也就是系统吞吐量会非常高。
2.4.5.2 ACK = 1
当生产数据时,Kafka Leader副本将数据接收到并写入到了日志文件后,就会对当前的数据请求进行响应(确认应答),如果是同步发送数据,此时就可以发送下一条数据了。如果是异步发送数据,回调方法就会被触发。

通过图形,可以看出,这种应答方式,数据已经存储到了分区Leader副本中,那么数据相对来讲就比较安全了,也就是可靠性比较高。之所以说相对来讲比较安全,就是因为现在只有一个节点存储了数据,而数据并没有来得及进行备份到follower副本,那么一旦当前存储数据的broker节点出现了故障,数据也依然会丢失。
2.4.5.3 ACK = -1(ALL)(默认)
效率最低,可靠性最高,最安全
当生产数据时,Kafka Leader副本和Follower副本都已经将数据接收到并写入到了日志文件后,再对当前的数据请求进行响应(确认应答),如果是同步发送数据,此时就可以发送下一条数据了。如果是异步发送数据,回调方法就会被触发。

通过图形,可以看出,这种应答方式,数据已经同时存储到了分区Leader副本和follower副本中,那么数据已经非常安全了,可靠性也是最高的。此时,如果Leader副本出现了故障,那么follower副本能够开始起作用,因为数据已经存储了,所以数据不会丢失。
不过这里需要注意,如果假设我们的分区有5个follower副本,编号为1,2,3,4,5

但是此时只有3个副本处于和Leader副本之间处于数据同步状态,那么此时分区就存在一个同步副本列表,我们称之为In Syn Replica,简称为ISR。此时,Kafka只要保证ISR中所有的4个副本接收到了数据,就可以对数据请求进行响应了。无需5个副本全部收到数据。

2.4.6 消息去重 & 有序
2.4.6.1数据重试
由于网络或服务节点的故障,Kafka在传输数据时,可能会导致数据丢失,所以我们才会设置ACK应答机制,尽可能提高数据的可靠性。但其实在某些场景中,数据的丢失并不是真正地丢失,而是“虚假丢失”,比如咱们将ACK应答设置为1,也就是说一旦Leader副本将数据写入文件后,Kafka就可以对请求进行响应了。

此时,如果假设由于网络故障的原因,Kafka并没有成功将ACK应答信息发送给Producer,那么此时对于Producer来讲,以为kafka没有收到数据,所以就会一直等待响应,一旦超过某个时间阈值,就会发生超时错误,也就是说在Kafka Producer眼里,数据已经丢了

所以在这种情况下,kafka Producer会尝试对超时的请求数据进行重试(retry)操作。通过重试操作尝试将数据再次发送给Kafka。

如果此时发送成功,那么Kafka就又收到了数据,而这两条数据是一样的,也就是说,导致了数据的重复。

可能导致数据重复
2.4.6.2数据乱序
数据重试(retry)功能除了可能会导致数据重复以外,还可能会导致数据乱序。假设我们需要将编号为1,2,3的三条连续数据发送给Kafka。每条数据会对应于一个连接请求

此时,如果第一个数据的请求出现了故障,而第二个数据和第三个数据的请求正常,那么Broker就收到了第二个数据和第三个数据,并进行了应答。

为了保证数据的可靠性,此时,Kafka Producer会将第一条数据重新放回到缓冲区的第一个。进行重试操作

如果重试成功,Broker收到第一条数据,你会发现。数据的顺序已经被打乱了。

数据乱序
2.4.6.3 数据幂等性
为了解决Kafka传输数据时,所产生的数据重复和乱序问题,Kafka引入了幂等性操作,所谓的幂等性,就是Producer同样的一条数据,无论向Kafka发送多少次,kafka都只会存储一条。注意,这里的同样的一条数据,指的不是内容一致的数据,而是指的不断重试的数据。
默认幂等性是不起作用的,所以如果想要使用幂等性操作,只需要在生产者对象的配置中开启幂等性配置即可
| 配置项 | 配置值 | 说明 |
|---|---|---|
| enable.idempotence | true | 开启幂等性 |
| max.in.flight.requests.per.connection | 小于等于5 | 每个连接的在途请求数,不能大于5,取值范围为[1,5] |
| acks | all(-1) | 确认应答,固定值,不能修改 |
| retries | >0 | 重试次数,推荐使用Int最大值 |
kafka是如何实现数据的幂等性操作呢,我们这里简单说一下流程:
(1) 开启幂等性后,为了保证数据不会重复,那么就需要给每一个请求批次的数据增加唯一性标识,kafka中,这个标识采用的是连续的序列号数字sequencenum,但是不同的生产者Producer可能序列号是一样的,所以仅仅靠seqnum还无法唯一标记数据,所以还需要同时对生产者进行区分,所以Kafka采用申请生产者ID(producerid)的方式对生产者进行区分。这样,在发送数据前,我们就需要提前申请producerid以及序列号sequencenum

(2) Broker中会给每一个分区记录生产者的生产状态:采用队列的方式缓存最近的5个批次数据。队列中的数据按照seqnum进行升序排列。这里的数字5是经过压力测试,均衡空间效率和时间效率所得到的值,所以为固定值,无法配置且不能修改。

(3) 如果Borker当前新的请求批次数据在缓存的5个旧的批次中存在相同的,如果有相同的,那么说明有重复,当前批次数据不做任何处理。

(4) 如果Broker当前的请求批次数据在缓存中没有相同的,那么判断当前新的请求批次的序列号是否为缓存的最后一个批次的序列号加1,如果是,说明是连续的,顺序没乱。那么继续,如果不是,那么说明数据已经乱了,发生异常。

(5) Broker根据异常返回响应,通知Producer进行重试。Producer重试前,需要在缓冲区中将数据重新排序,保证正确的顺序后。再进行重试即可。
(6) 如果请求批次不重复,且有序,那么更新缓冲区中的批次数据。将当前的批次放置再队列的结尾,将队列的第一个移除,保证队列中缓冲的数据最多5个。

从上面的流程可以看出,Kafka的幂等性是通过消耗时间和性能的方式提升了数据传输的有序和去重,在一些对数据敏感的业务中是十分重要的。但是通过原理,咱们也能明白,这种幂等性还是有缺陷的:
- 幂等性的producer仅做到单分区上的幂等性,即单分区消息有序不重复,多分区无法保证幂等性。
- 只能保持生产者单个会话的幂等性,无法实现跨会话的幂等性,也就是说如果一个producer挂掉再重启,那么重启前和重启后的producer对象会被当成两个独立的生产者,从而获取两个不同的独立的生产者ID,导致broker端无法获取之前的状态信息,所以无法实现跨会话的幂等。要想解决这个问题,可以采用后续的事务功能。
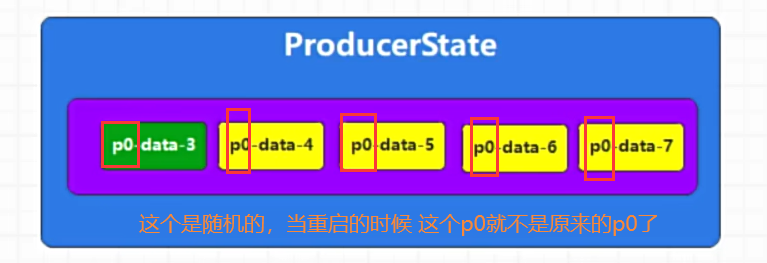
- 但是可以利用事务,去解决无法实现跨会话的幂等性。
2.4.6.4数据事务
对于幂等性的缺陷,kafka可以采用事务的方式解决跨会话的幂等性。基本的原理就是通过事务功能管理生产者ID,保证事务开启后,生产者对象总能获取一致的生产者ID。
为了实现事务,Kafka引入了**事务协调器(TransactionCoodinator)**负责事务的处理,所有的事务逻辑包括分派PID等都是由TransactionCoodinator负责实施的。TransactionCoodinator 会将事务状态持久化到该主题中。
事务基本的实现思路就是通过配置的事务ID,将生产者ID进行绑定,然后存储在Kafka专门管理事务的内部主题 __transaction_state中,而内部主题的操作是由 TransactionCoodinator 对象完成的,这个协调器对象有点类似于咱们数据发送时的那个副本Leader。其实这种设计是很巧妙的,因为kafka将事务ID和生产者ID看成了消息数据,然后将数据发送到一个内部主题中。这样,使用事务处理的流程和咱们自己发送数据的流程是很像的。接下来,我们就把这两个流程简单做一个对比。
2.4.6.4.1 普通数据发送流程

2.4.6.4.2 事务数据发送流程

通过两张图大家可以看到,基本的事务操作和数据操作是很像的,不过要注意,我们这里只是简单对比了数据发送的过程,其实它们的区别还在于数据发送后的提交过程。普通的数据操作,只要数据写入了日志,那么对于消费者来讲。数据就可以读取到了,但是事务操作中,如果数据写入了日志,但是没有提交的话,其实数据默认情况下也是不能被消费者看到的。只有提交后才能看见数据。
2.4.6.4.3 事务提交流程
Kafka中的事务是分布式事务,所以采用的也是二阶段提交
-
第一个阶段提交事务协调器会告诉生产者事务已经提交了,所以也称之预提交操作,事务协调器会修改事务为预提交状态

-
第二个阶段提交事务协调器会向分区Leader节点中发送数据标记,通知Broker事务已经提交,然后事务协调器会修改事务为完成提交状态

特殊情况下,事务已经提交成功,但还是读取不到数据,那是因为当前提交成功只是一阶段提交成功,事务协调器会继续向各个Partition发送marker信息,此操作会无限重试,直至成功。
但是不同的Broker可能无法全部同时接收到marker信息,此时有的Broker上的数据还是无法访问,这也是正常的,因为kafka的事务不能保证强一致性,只能保证最终数据的一致性,无法保证中间的数据是一致的。不过对于常规的场景这里已经够用了,事务协调器会不遗余力的重试,直至成功。
2.4.6.4.4 事务操作代码
package com.atguigu.test;import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.Future;public class ProducerTransactionTest {public static void main(String[] args) {Map<String, Object> configMap = new HashMap<>();configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configMap.put( ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());configMap.put( ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// TODO 配置幂等性configMap.put( ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);// TODO 配置事务IDconfigMap.put( ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-tx-id");// TODO 配置事务超时时间configMap.put( ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 5);// TODO 创建生产者对象KafkaProducer<String, String> producer = new KafkaProducer<>(configMap);// TODO 初始化事务producer.initTransactions();try {// TODO 启动事务producer.beginTransaction();// TODO 生产数据for ( int i = 0; i < 10; i++ ) {ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key" + i, "value" + i);final Future<RecordMetadata> send = producer.send(record);}// TODO 提交事务producer.commitTransaction();} catch ( Exception e ) {e.printStackTrace();// TODO 终止事务producer.abortTransaction();}// TODO 关闭生产者对象producer.close();}
}
2.4.6.5 数据传输语义
| 传输语义 | 说明 | 例子 |
|---|---|---|
| at most once | 最多一次:不管是否能接收到,数据最多只传一次。这样数据可能会丢失, | Socket, ACK=0 |
| at least once | 最少一次:消息不会丢失,如果接收不到,那么就继续发,所以会发送多次,直到收到为止,有可能出现数据重复 | ACK=1 |
| Exactly once | 精准一次:消息只会一次,不会丢,也不会重复。 | 幂等+事务+ACK=-1 |