为什么要使用消息队列?
优点:解耦、异步、流量削峰
缺点:可用性降低、复杂性提高、一致性问题
为什么选择了RabbitMQ而不是其它的MQ?
kafka是以吞吐量高而闻名,不过其数据稳定性一般,而且无法保证消息有序性。我们公司的日志收集也有使用,业务模块中则使用的RabbitMQ。
阿里巴巴的RocketMQ基于Kafka的原理,弥补了Kafka的缺点,继承了其高吞吐的优势,其客户端目前以Java为主。但是我们担心阿里巴巴开源产品的稳定性,所以就没有使用。
RabbitMQ基于面向并发的语言Erlang开发,吞吐量不如Kafka,但是对我们公司来讲够用了。而且消息可靠性较好,并且消息延迟极低,集群搭建比较方便。支持多种协议,并且有各种语言的客户端,比较灵活。Spring对RabbitMQ的支持也比较好,使用起来比较方便,比较符合我们公司的需求。
综合考虑我们公司的并发需求以及稳定性需求,我们选择了RabbitMQ。
| activeMQ | RabbitMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 性能 | 6000/单机 | 12000/单机 | 10万/单机 | 100万/单机 |
| 持久化 | 都支持(性能会下降) | 都支持(性能会下降) | 天生支持 | 天生支持 |
| 多语言支持 | 主流都支持 | 主流都支持 | 只支持Java | 主流都支持 |
| 优缺点 | 缺乏大规模运用,不推荐 | 消息可靠性高,功能全面,吞吐量比较低,消息积累会影响性能 | 高吞吐,高性能,高可用,功能全面。 | 缺点:会丢数据、功能单一 |
| 使用场景 | 缺乏大规模运用,不推荐 | 企业内部小规模系统调用 | 几乎全场景,特别适合金融级mq场景 | 日志分析、大数据采集 |
RabbitMQ一个queue中存放的message是否有数量限制?
默认情况下一般无限制。
但是可以通过x-max-length对队列中消息的条数进行限制;
x-max-length-bytes对队列中消息的总量进行限制,比如200mb。
RabbitMQ事务机制?
RabbitMQ事务机制和确认机制
public class RabbitMqTransactionExample {private static final String QUEUE_NAME = "queue_name";public static void main(String[] args) {try {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");Connection connection = factory.newConnection();Channel channel = connection.createChannel();// 开启事务channel.txSelect();String message = "Hello, RabbitMQ!";// 发布消息到队列channel.basicPublish("", QUEUE_NAME, null, message.getBytes());// 提交事务channel.txCommit();System.out.println("Message sent successfully");} catch (Exception e) {// 回滚事务channel.txRollback();System.out.println("Failed to send message");e.printStackTrace();}}
}
RabbitMQ确保消息可靠性传输?
Rabbitmq 的持久化分为队列持久化、消息持久化和交换机持久化。
1,队列持久化
在定义队列时的通过 durable 参数来决定的
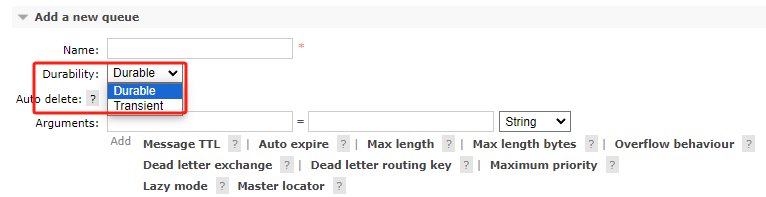
2,交换机持久化
durable:持久话标志位, durable 设置为 true 表示持久化, 反之为非持久,与队列持久化相同
3,消息持久化
deliveryMode=1 代表不持久化,deliveryMode=2 代表持久化
@Component
public class MessageSender {@Autowiredprivate RabbitTemplate rabbitTemplate;public void sendMessage(String message) {MessageProperties properties = new MessageProperties();properties.setDeliveryMode(MessageDeliveryMode.PERSISTENT); // 设置消息持久化Message rabbitMessage = new Message(message.getBytes(), properties);rabbitTemplate.send("exchangeName", "routingKey", rabbitMessage);}
}
4,主从备份
消息到达队列后,MQ宕机也可能导致丢失消息,RabbitMQ提供了持久化功能,集群的主从备份功能
5,生产者消息确认:publisher confirm机制、publisher return机制
5.1,修改publisher服务中的application.yml文件
spring:rabbitmq:username: guestpassword: guestvirtual-host: /host: 123.123.123.123port: 5672publisher-confirm-type: simplepublisher-returns: truelistener:simple:acknowledge-mode: auto # 手动应答prefetch: 1 #每次从队列中取一个,轮询分发,默认是公平分发retry:enabled: true # 开启重试initial-interval: 1000 # 初识的失败等待时长为1秒multiplier: 2 # 失败的等待时长倍数max-attempts: 5 # 重试次数publish-confirm-type:开启publisher-confirm,这里支持两种类型:
simple:同步等待confirm结果,直到超时
correlated:异步回调,定义ConfirmCallback,MQ返回结果时会回调这个ConfirmCallbackpublish-returns:开启publish-return功能,同样是基于callback机制,不过是定义ReturnCallback
template.mandatory:定义消息路由失败时的策略。true,则调用ReturnCallback;false:则直接丢弃消息
5.2,ReturnCallback,交换机到队列
@Slf4j
@Configuration
public class CommonConfig implements ApplicationContextAware {@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {// 获取RabbitTemplateRabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class);// 设置ReturnCallback//alt+enter 可以将匿名内部类改成lamda表达式rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {// 投递失败,记录日志//当发送时设置错误的routingKey;成功到交换机但未到队列// 消息成功投递到交换机!消息ID: 4ccec7ec-a95e-4660-afe3-1370bcde7904// 消息发送到队列失败,响应码:312, 失败原因:NO_ROUTE, 交换机: amq.topic, 路由key:ssimple.testlog.info("消息发送失败,应答码{},原因{},交换机{},路由键{},消息{}",replyCode, replyText, exchange, routingKey, message.toString());// 如果有业务需要,可以重发消息});}
}
5.3,定义ConfirmCallback,发送端到交换机
@Component
public class RabbitMQMessageSender implements MQMessageSender, RabbitTemplate.ConfirmCallback{private final RabbitTemplate rabbitTemplate;Log log = LogFactory.getLog(RabbitMQMessageSender.class);@Autowiredpublic RabbitMQMessageSender(RabbitTemplate rabbitTemplate) {this.rabbitTemplate = rabbitTemplate;}@PostConstructpublic void init(){rabbitTemplate.setConfirmCallback(this);}@Overridepublic void confirm(CorrelationData correlationData, boolean ack, String cause) {if(!ack){log.error("消息接收失败" + cause);// 我们这里要做一些消息补发的措施System.out.println("id="+correlationData.getId());}}public void send(String routingKey, MQMessage msg) {String jsonString = JsonConverter.bean2Json(msg);if (jsonString != null) {try {rabbitTemplate.convertAndSend(routingKey, jsonString);} catch (Exception e) {// 连接异常,发送日志log.error("Failed to send message RabbitMQ Exception: " + e.getMessage());}}}
}
6,消费者消息确认机制
spring:rabbitmq:username: guestpassword: guestvirtual-host: /host: 123.123.123.123port: 5672publisher-confirm-type: simplepublisher-returns: true# 消费者确认机制listener:simple:# 将消费者确认机制设置成auto,会利用aop原理,当mq消息发送失败时重试acknowledge-mode: autoprefetch: 1 #每次从队列中取一个,轮询分发,默认是公平分发retry:enabled: true # 开启重试initial-interval: 1000 # 初识的失败等待时长为1秒multiplier: 2 # 失败的等待时长倍数max-attempts: 5 # 重试次数
6.1,消费失败重试机制
# 重试达到最大次数后,Spring会返回ack,消息会被丢弃
spring:rabbitmq:listener:simple:prefetch: 1acknowledge-mode: autoretry:enabled: true # 开启消费者失败重试initial-interval: 1000 # 初识的失败等待时长为1秒multiplier: 2 # 失败的等待时长倍数,下次等待时长 = multiplier * last-interval,相当于第1秒重试,第3秒重试,第7秒重试max-attempts: 3 # 最大重试次数stateless: true # true无状态;false有状态。如果业务中包含事务,这里改为false
6.2,达到最大重试次数后,失败策略
多次重试失败后将消息投递到异常交换机(死信交换机),交由人工处理
| 失败策略 | 详解 |
|---|---|
| RejectAndDontRequeueRecoverer | 重试耗尽后,直接reject,丢弃消息。默认就是这种方式 |
| ImmediateRequeueMessageRecoverer | 重试耗尽后,返回nack,消息重新入队 |
| RepublishMessageRecoverer | 重试耗尽后,将失败消息投递到指定的交换机 |
RabbitMQ交换机类型?
| 交换机类型 | 解释 | 举例 |
|---|---|---|
| Fanout广播模式 | 将消息交给所有绑定这个交换机的队列 | 不同queue绑定一个Exchange |
| Direct定向模式 | 把消息交给符合指定routing key的队列 | 比如一个消费端key = {“red”, “blue”},另一个消费端key = {“red”, “yellow”},当发送端rabbitTemplate.convertAndSend(exchangeName, “red”, message)时,两个消费端都可以收到消息 |
| Topic通配符模式 | 判断routing key的规则是模糊匹配模式 | 消费端1:key = “china.#” 消费端2:key = “#.news”,发送端:rabbitTemplate.convertAndSend(exchangeName, “china.news”, message); #:代表0个或多个词*:代表1个词 |
RabbitMQ是否可以直接将消息推送到队列?
可以,但不推荐,丧失灵活性
RabbitMQ如何避免消息堆积?
消息堆积问题产生的原因往往是因为消息发送的速度超过了消费者消息处理的速度。因此解决方案无外乎以下三点:
1,提高消费者处理速度 2,增加更多消费者 3,增加队列消息存储上限
1,提高消费者处理速度
消费者处理速度是由业务代码决定的,所以我们能做的事情包括:
尽可能优化业务代码,提高业务性能
接收到消息后,开启线程池,并发处理多个消息
优点:成本低,改改代码即可
缺点:开启线程池会带来额外的性能开销,对于高频、低时延的任务不合适。适合任务执行周期较长的业务。
2,增加更多消费者
一个队列绑定多个消费者,共同争抢任务,自然可以提供消息处理的速度。
优点:能用钱解决的问题都不是问题。实现简单粗暴
缺点:问题是没有钱。成本太高
3,增加队列消息存储上限
在RabbitMQ的1.8版本后,加入了新的队列模式:Lazy Queue惰性队列
这种队列不会将消息保存在内存中,而是在收到消息后直接写入磁盘中,理论上没有存储上限。可以解决消息堆积问题。
优点:磁盘存储更安全;存储无上限;避免内存存储带来的Page Out问题,性能更稳定;
缺点:磁盘存储受到IO性能的限制,消息时效性不如内存模式,但影响不大。
RabbitMQ如何保证消息的有序性?
其实RabbitMQ是队列存储,天然具备先进先出的特点,只要消息的发送是有序的,那么理论上接收也是有序的。不过当一个队列绑定了多个消费者时,可能出现消息轮询投递给消费者的情况,而消费者的处理顺序就无法保证了。
因此,要保证消息的有序性,需要做的下面几点:
保证消息发送的有序性
保证一组有序的消息都发送到同一个队列
保证一个队列只包含一个消费者
如何防止MQ消息被重复消费?
消息重复消费的原因多种多样,不可避免。所以只能从消费者端入手,只要能保证消息处理的幂等性就可以确保消息不被重复消费。
而幂等性的保证又有很多方案:
给每一条消息都添加一个唯一id,在本地记录消息表及消息状态,处理消息时基于数据库表的id唯一性做判断
同样是记录消息表,利用消息状态字段实现基于乐观锁的判断,保证幂等
基于业务本身的幂等性。比如根据id的删除、查询业务天生幂等;新增、修改等业务可以考虑基于数据库id唯一性、或者乐观锁机制确保幂等。本质与消息表方案类似。
如何保证RabbitMQ的高可用?
要实现RabbitMQ的高可用无外乎下面两点:
做好交换机、队列、消息的持久化
搭建RabbitMQ的镜像集群,做好主从备份。当然也可以使用仲裁队列代替镜像集群。
使用MQ可以解决那些问题?
RabbitMQ能解决的问题很多,例如:
解耦合:将几个业务关联的微服务调用修改为基于MQ的异步通知,可以解除微服务之间的业务耦合。同时还提高了业务性能。
流量削峰:将突发的业务请求放入MQ中,作为缓冲区。后端的业务根据自己的处理能力从MQ中获取消息,逐个处理任务。流量曲线变的平滑很多
延迟队列:基于RabbitMQ的死信队列或者DelayExchange插件,可以实现消息发送后,延迟接收的效果。
RabbitMQ模型?
以下两种模型一条消息,只能被一个consumer消费
| 队列类型 | 解释 | 举例 |
|---|---|---|
| BasicQueue 简单队列模型 | 只有1个消费者 | |
| WorkQueue任务模型 | 多个消费者 但是只有1个消费者消费消息 | 多个消费端绑定一个queue,@RabbitListener(queues = “simple.queue”) listener1和@RabbitListener(queues = “simple.queue”) listener2 |
发布/订阅(以下三种模式可以多个消费者同时消费)
| 交换机类型 | 解释 | 举例 |
|---|---|---|
| Fanout广播模式 | 将消息交给所有绑定这个交换机的队列 | 不同queue绑定一个Exchange |
| Direct定向模式 | 把消息交给符合指定routing key的队列 | 比如一个消费端key = {“red”, “blue”},另一个消费端key = {“red”, “yellow”},当发送端rabbitTemplate.convertAndSend(exchangeName, “red”, message)时,两个消费端都可以收到消息 |
| Topic通配符模式 | 判断routing key的规则是模糊匹配模式 | 消费端1:key = “china.#” 消费端2:key = “#.news”,发送端:rabbitTemplate.convertAndSend(exchangeName, “china.news”, message); #:代表0个或多个词*:代表1个词 |