目录
- 零、版本说明
- 一、环境准备
- 1.1.规划
- 1.2.准备
- 二、安装
- 配置hadoop
- 三、启动
零、版本说明
- centos
[root@node1 ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
- jdk
[root@node1 ~]# java -version
java version "1.8.0_311"
Java(TM) SE Runtime Environment (build 1.8.0_311-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.311-b11, mixed mode)
- hadoop
[root@node1 ~]# hadoop version
Hadoop 3.3.0
Source code repository Unknown -r Unknown
Compiled by root on 2021-07-15T07:35Z
Compiled with protoc 3.7.1
From source with checksum 5dc29b802d6ccd77b262ef9d04d19c4
This command was run using /export/server/hadoop-3.3.0/share/hadoop/common/hadoop-common-3.3.0.jar
一、环境准备
1.1.规划
| IP | 说明 |
|---|---|
| 192.168.1.60 | node1 |
| 192.168.1.61 | node2 |
| 192.168.1.62 | node3 |
1.2.准备
所有机器上执行
sed -i "s/timeout=5/timeout=1/" /boot/grub2/grub.cfgmkdir -p /export/{server,software,data}cd /export/server/tar -zxf jdk-8u311-linux-x64.tar.gzln -s jdk1.8.0_311/ jdktar zxf hadoop-3.3.0-Centos7-64-with-snappy.tar.gzln -s hadoop-3.3.0 hadoopcat >> /etc/profile << EOF
export JAVA_HOME=/export/server/jdk
export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
EOFsource /etc/profilecat >> /etc/hosts << EOF
192.168.1.60 node1
192.168.1.61 node2
192.168.1.62 node3
EOFyum install -y ntpdate# 添加 0 */1 * * * ntpdate ntp4.aliyun.com
crontab -esystemctl stop firewalld.service
systemctl disable firewalld.service
二、安装
所有机器上执行
配置hadoop
- hadoop-env.sh
cat >> /export/server/hadoop/etc/hadoop/hadoop-env.sh << EOF
export JAVA_HOME=/export/server/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
EOF
- core-site.xml
cat > /export/server/hadoop/etc/hadoop/core-site.xml << EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property><name>fs.defaultFS</name><value>hdfs://node1:8020</value>
</property><!-- 设置Hadoop本地保存数据路径 -->
<property><name>hadoop.tmp.dir</name><value>/export/data/hadoop</value>
</property><!-- 设置HDFS web UI用户身份 -->
<property><name>hadoop.http.staticuser.user</name><value>root</value>
</property><!-- 整合hive 用户代理设置 -->
<property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property><property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property><!-- 文件系统垃圾桶保存时间 -->
<property><name>fs.trash.interval</name><value>1440</value>
</property>
</configuration>
EOF
- hdfs-site.xml
cat > /export/server/hadoop/etc/hadoop/hdfs-site.xml << EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 设置SNN进程运行机器位置信息 --><property><name>dfs.namenode.secondary.http-address</name><value>node2:9868</value></property>
</configuration>
EOF
- mapred-site.xml
cat > /export/server/hadoop/etc/hadoop/mapred-site.xml << EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- MR程序历史服务地址 --><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value></property><!-- MR程序历史服务器web端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
</configuration>
EOF
- yarn-site.xml
cat > /export/server/hadoop/etc/hadoop/yarn-site.xml << EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>yarn.resourcemanager.hostname</name><value>node1</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 是否将对容器实施物理内存限制 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><!-- 是否将对容器实施虚拟内存限制。 --><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property><!-- 开启日志聚集 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置yarn历史服务器地址 --><property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value></property><!-- 历史日志保存的时间 7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
</configuration>
EOFcat > /export/server/hadoop/etc/hadoop/workers << EOF
node1
node2
node3
EOF
三、启动
node1上执行
hdfs namenode -formatstart-all.sh
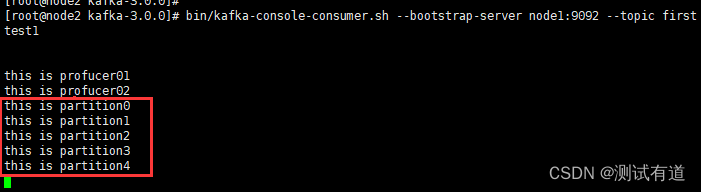
- 查看效果
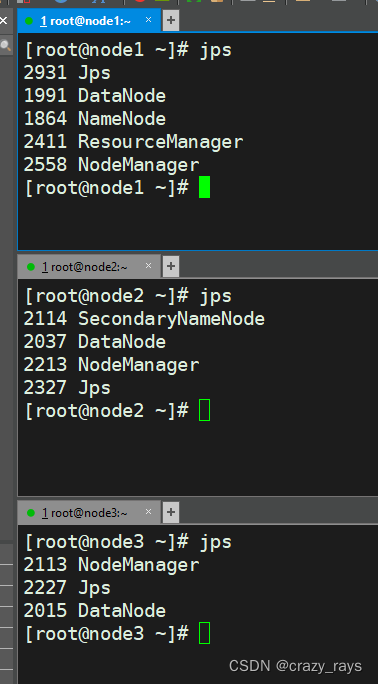
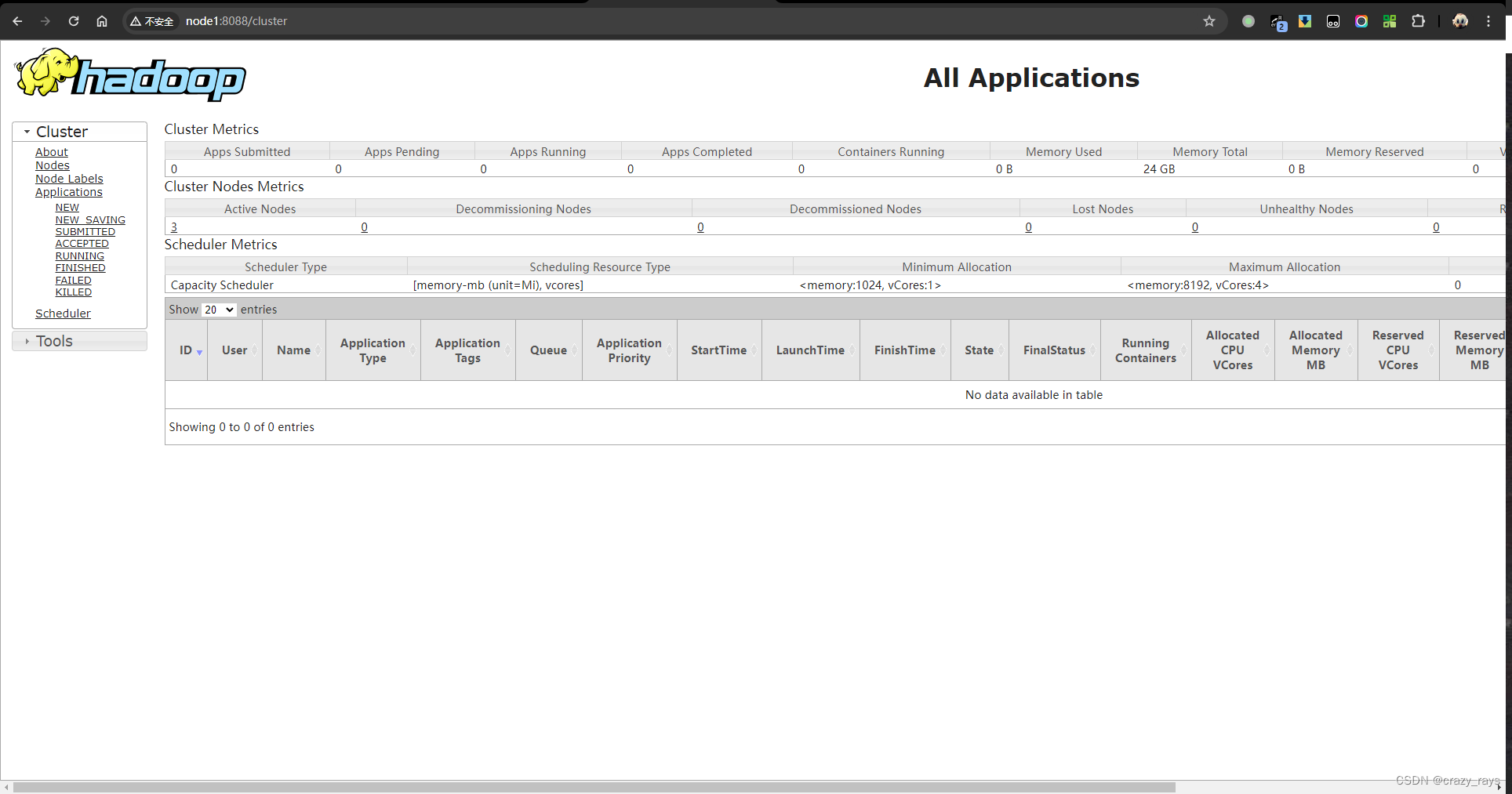
- 使用9870访问HDFS webui
- 使用8088 访问yarn web-ui