【README】
0. 先说结论:一般用inner join来改写in和exist,用left join来改写not in,not exist;(本文会比较内连接,包含in子句的子查询,exist的性能 )
1. 本文总结自高性能mysql 6.5.1章节【关联子查询】
2. 数据库表及数据特征:
- wn_film_tbl: 电影表, 50w数据量;
- wn_actor_tbl: 演员表, 50w数据量;
- wn_file_actor_rel_tbl: 电影演员关联表, 10w数据量;
3. ddl如下:
CREATE TABLE `wn_film_tbl` (`film_id` varchar(20) COLLATE utf8mb4_general_ci NOT NULL COMMENT '电影id',`film_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '电影名称',`release_year` int(11) NOT NULL COMMENT '上映年份',`remark` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '备注',`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,`last_modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`film_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='电影表'CREATE TABLE `wn_actor_tbl` (`actor_id` varchar(20) COLLATE utf8mb4_general_ci NOT NULL COMMENT '演员id',`actor_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '演员名称',`remark` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '备注',`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,`last_modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`actor_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='演员表'CREATE TABLE `wn_film_actor_rel_tbl` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',`film_id` varchar(20) COLLATE utf8mb4_general_ci NOT NULL COMMENT '电影id',`actor_id` varchar(20) COLLATE utf8mb4_general_ci NOT NULL COMMENT '演员id',`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,`last_modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`),KEY `idx_film_id` (`film_id`) COMMENT '电影id索引',KEY `idx_actor_id` (`actor_id`) COMMENT '演员id索引'
) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='电影与演员关联表'【1】查询某演员参演的电影清单
1. 具体的,查询 演员0420AAAID000099参演的电影清单,通过造数,该演员参演的电影有 15000部;
2. 几种不同的实现方式:
- 方案1: 使用 包含in()子句的子查询(性能非常低,作为反例,供各位看官参考);
- 方案2:使用内连接;
- 方案3:使用exists;
【1.1】使用包含in()子句的子查询
1. sql如下(为了方便打印执行计划,这里仅查询一条#limit 1):
select sql_no_cache *
from wn_film_tbl film
where film_id in (select film_id from wn_film_actor_rel_tbl where actor_id='0420AAAID000099')
limit 1
;2. 查看其执行计划及查询成本:
- explain 查看执行计划;
- show status like 'last_query_cost' 查询上一个sql的执行成本;(成本的最小单位是随机读取1个大小为4K的数据页 )
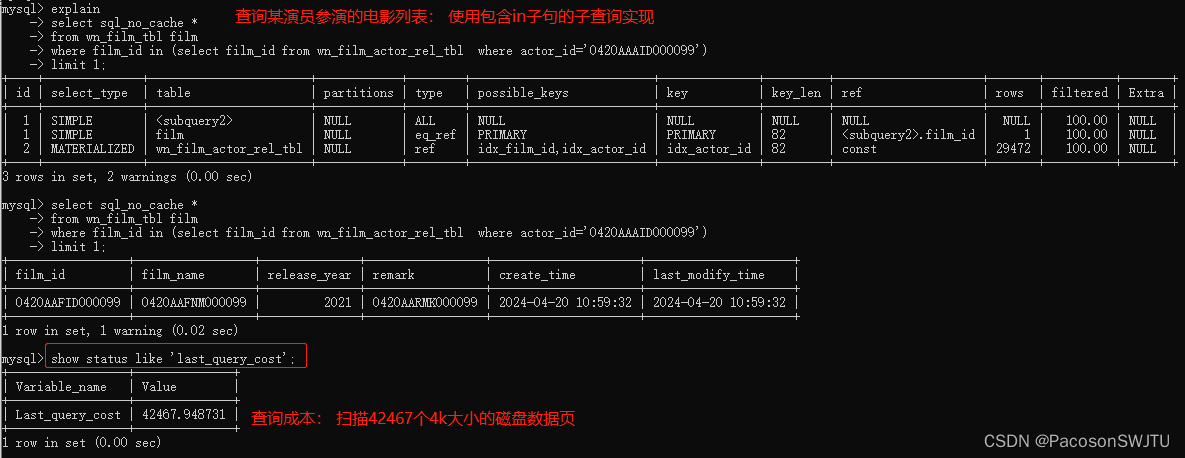
3. 执行计划剖析(执行计划列的含义,参见
mysql_explain执行计划字段解析-CSDN博客):
4. 关联表执行步骤:
- 第1步: 扫描film_actor_rel_tbl 表的普通索引 idx_actor_id ,查询 actor_id 等于0420AAAID000099 的 电影演员关联记录,得到列表 result_list
- 第2步:全表扫描查询结果result_list(猜测是在内存中,因为extra没有 using temporary);
- 第3步:扫描film表的主键索引树,查询film表中film_id(主键) 等于 result_list#film_id 字段值的记录并返回;
5. 对于上述步骤的总结:mysql对任何关联都执行嵌套循环关联操作(即先查询 rel表,然后全表扫描rel表,循环遍历rel表,再在单次遍历中循环遍历 film表 );
- 有个问题: 为什么不反着来? 先查询 film表,再在循环遍历film过程中,遍历rel表(动脑筋的时候到了);
- 小表驱动大表原则; 为什么小表驱动大表,大表驱动小表不行吗?(如果理解了上面的问题,就可以推导出小表驱动大表的依据)
6. 嵌套循环关联查询步骤如下:
- 查询外层表的数据行, 并构建外层表的迭代器;
- 遍历外层表迭代器,获取单个外层表数据行(第1层循环);
- 根据单个外层表数据行,查询内层表的数据行,并构建内层表迭代器;
- 遍历内层表迭代器,获取单个内层表数据行(第2层循环);
- 合并外层与内层表数据行,构建输出结果;
- 内层表迭代器滑动;
- 外层表迭代器滑动;

【1.2】使用内连接
sql如下:
select sql_no_cache film.*
from wn_film_tbl film
inner join wn_film_actor_rel_tbl rel on film.film_id = rel.film_id
where rel.actor_id='0420AAAID000099'
limit 1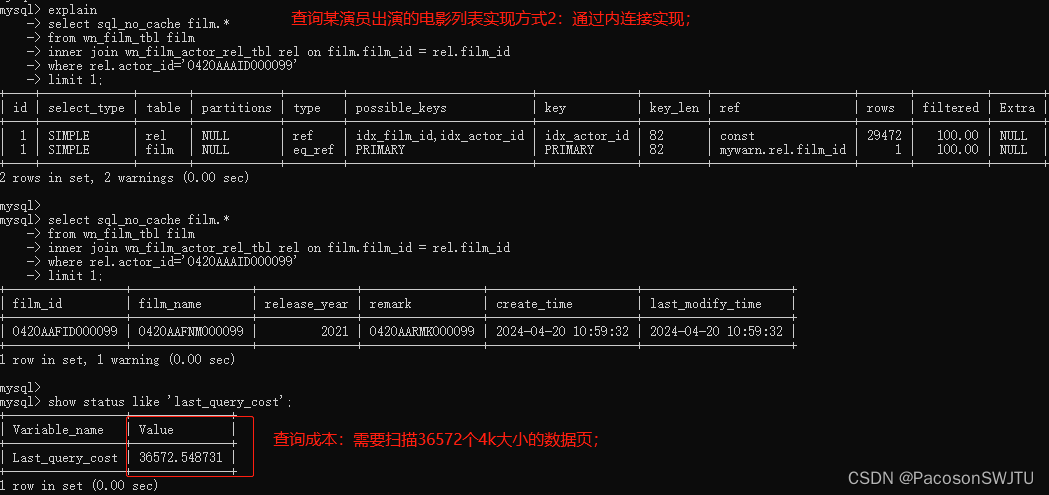
【敲黑板】
- 显然,根据执行计划,我们看到,mysql先查询了rel 表,然后再查询了 film表,为什么?(id相同,则按照从上到下的顺序执行)
- 为什么不是先查询film表,再查询rel表;
【1.3】使用exists
sql如下:
select sql_no_cache film.*
from wn_film_tbl film
where exists (select * from wn_film_actor_rel_tbl rel where rel.actor_id='0420AAAID000099'and rel.film_id = film.film_id
)
limit 1;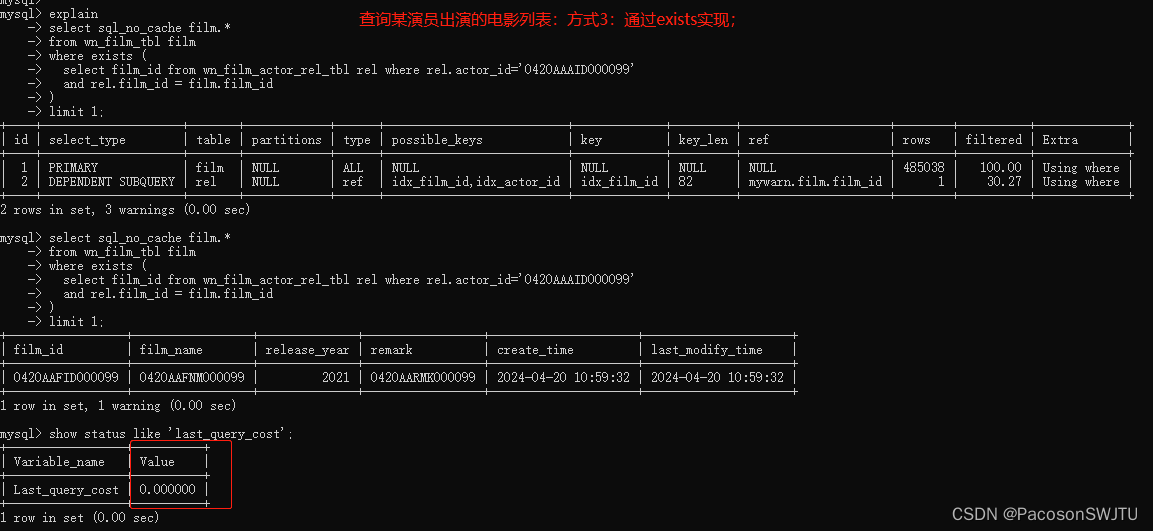
【2】总结:
1. 根据 last_query_cost 可以看到: 内连接需要扫描 36572个数据页;in子句的子查询需要扫描42467个数据页,所以内连接性能 【优于】 in子句的子查询;
2. 从扫描行数来看: 内连接性能优于 in子句的子查询, in子句的子查询 优于 exists;
问题:为什么 exits子查询的 last_query_cost结果显示为0呢?没懂;



![[华为OD] 给航天器一侧加装长方形或正方形的太阳能板 100](https://img-blog.csdnimg.cn/direct/51754d605de44c40aec2e6d0fecada95.png)