HTTP 最新的版本应该是 HTTP/3.0
目前大规模使用的版本 HTTP/1.1
使用 HTTP 协议的场景
1.浏览器打开网站 (基本上)
2.手机 APP 访问对应的服务器 (大概率)
学习 HTTP 协议, 重点学习 HTTP 的报文格式
前面的 TCP/IP/UDP 和这些不同, HTTP 的报文格式,要分两个部分来看待.
请求
响应HTTP 协议,是一种"一问一答"结构模型的协议,
请求和响应的协议格式,是有所差异的~~【一问一答(访问网站)
多问一答(上传文件)
一问多答 (下载文件)
多问多答(串流/远程桌面)】
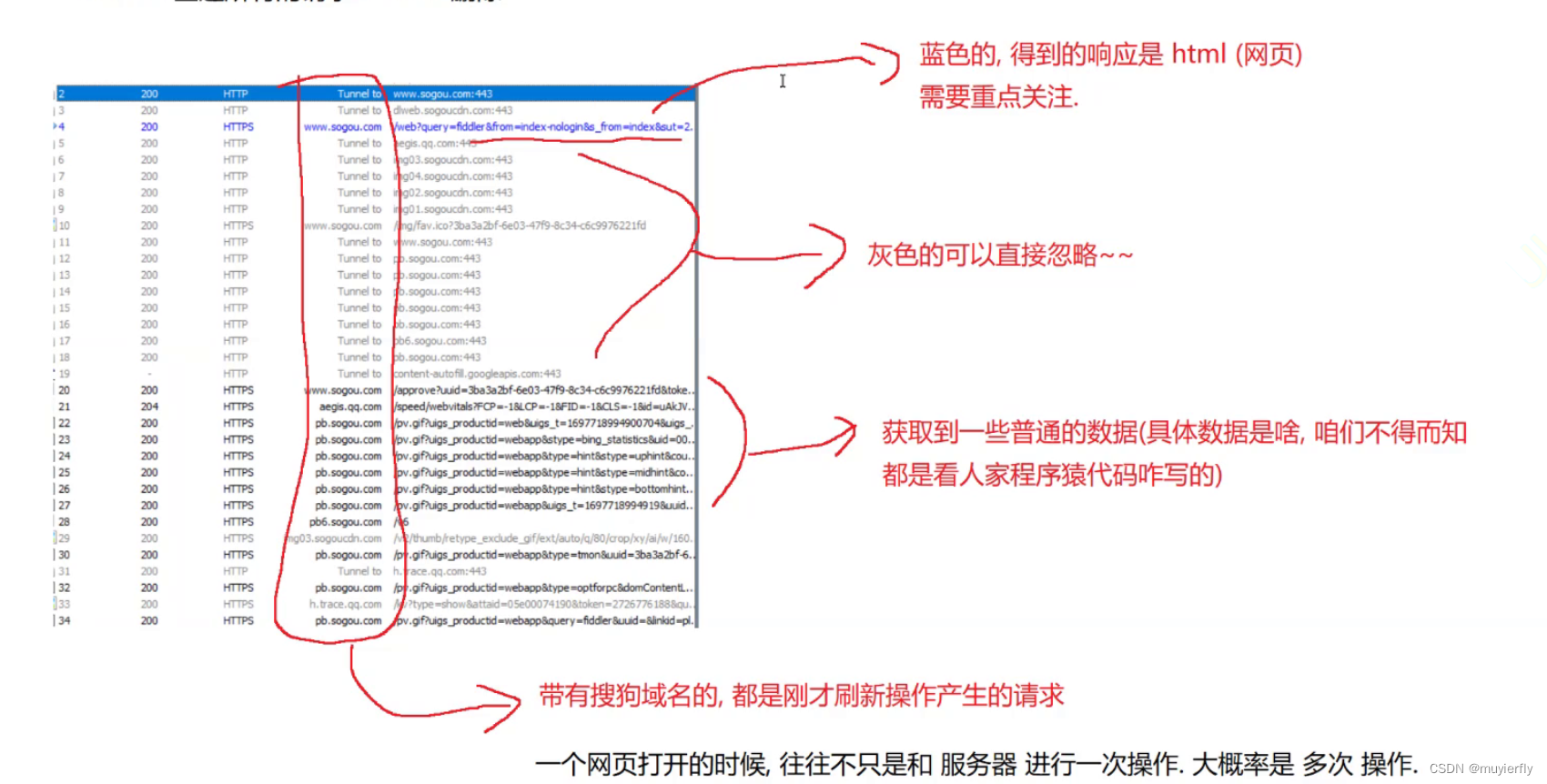
1.fiddler
使用fiddler进行抓包
postman 是构造请求
fiddler 抓取/显示已有的请求.
ctrl +a全选所有的请求. delete 删除
关注蓝色的
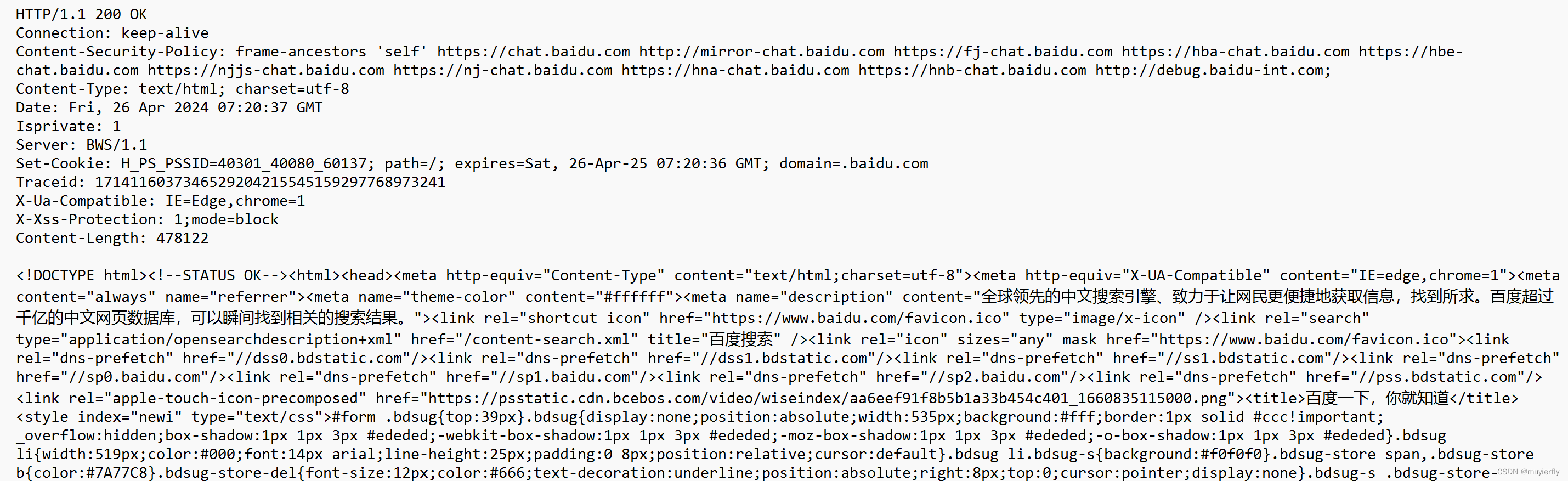
HTTP 协议是文本格式的协议!(协议里的内容都是字符串).
TCP,UDP,IP.... 都是二进制格式的协议.HTTP 响应也是文本的.直接査看,往往能看到二进制的数据.(压缩后的)
HTTP 响应经常会被压缩. 压缩之后,体积变小,传输的时候, 节省网络带宽.(一台服务器, 最贵的硬件资源, 就是网络带宽!!!)
但是, 压缩和解压缩,是需要消耗额外的 cpu 和 时间的.



2.请求和响应的格式
【请求】
【响应】


2.1 URL
URL 计算机中的非常重要的概念.不仅仅是在 HTTP 中涉及到
idbc
设置数据源
setUrl("jdbc:mysql://127.0.0.1:3306/java109?characterEncoding=utf8&useSSL=false");【URL, 描述了某个资源在网络上的所属位置.数据库也算是一种"资源"】

#ch1 片段标识符
有的网页内容比较长,就可以分成多个"片段”,通过片段标识符,就可以完成页面内部的跳转(技术文档经常会这么搞)
urencode
后面使用 ur| 的时候,要记得针对 query string 的内容进行好 urlencode 工作~~如果不处理好,有些浏览器就可能会解析失败,导致请求无法正常进行.

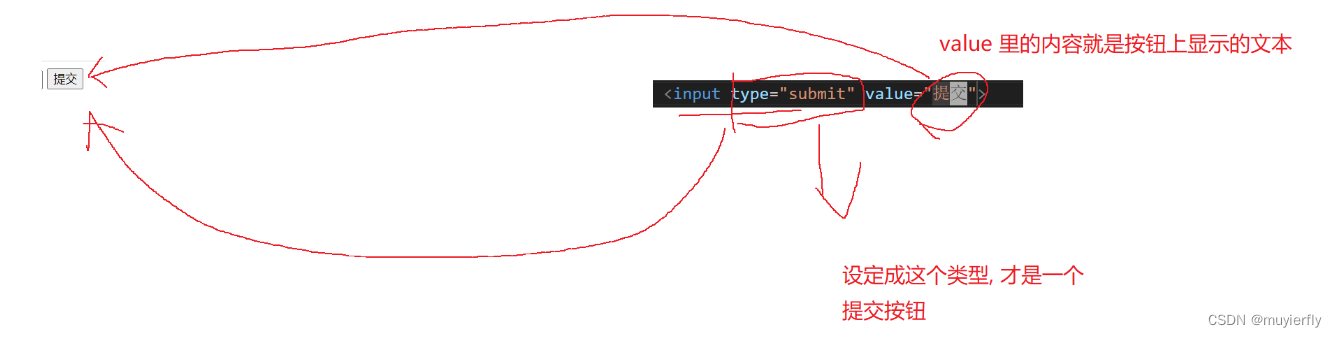
2.2 方法
- 最常见的方法get,其次是post
- GET 请求,通常会把要传给服务器的数据, 加到 ur 的 query string 中
- POST 请求,通常把要传给服务器的数据, 加到 body 中
- 只是习惯用法,不是硬性规定
出现没有抓到这里的返回页面的请求是因为命中了浏览器缓存
浏览器显示的网页,其实是从服务器这边下载的 html.html内容可能比较多,体积可能比较大,通过网络加载,消耗的时间就可能会比较多浏览器一般都会自己带有缓存. 就会把之前加载过的页面,保存在本地硬盘上.
下次访问直接读取本地硬盘的数据即可

这些 HTTP 请求, 最初的初心, 就是为了表示不同的"语义
在实际的使用过程中,初心,已经被遗忘了
HTTP 的各种请求,目前来说已经不一定完全遵守自己的初心了
实际上程序员如何使用,更加随意的,
POST 和 PUT 目前来说,可以理解成 没有任何区别!!!(任何使用 POST 的场景, 换成 PUT 完全可以. 反之亦然)

【经典面试题】平时一般在谈 GET 和 POST 的区别
开篇, 先盖棺定论, GET 和 POST 没有本质区别!!!(双方可以替换对方的场景)
虽然没有本质区别,但是在使用习惯上,还是存在一些差异的~~.1.使用习惯上的差距
GET 经常是把传递给服务器的数据放到 query string 中;
POST 则是经常放到 body 中.(使用习惯上最大的差别)(上述情况并非绝对,GET 也可以使用 body,POST 也可以使用 query string:使用的前提是客户端/服务器都得按照一样的方式来处理代码)当然,一般还是建议大家要遵守上述的约定俗称的习惯.
2.语义上的差异(虽然语义上 HTTP 的使用是比较混乱的,但是相比之下,GET 和 POST 还是比较明确的)GET 大多数还是用来获取数据
POST 大多数还是用来提交数据 (登录 + 上传)
【有问题的说法】
GET 和 POST 之间的差别,有些说法, 需要大家来注意~
1.GET 请求能传递的数据量有上限,POST 传递的数据量没有上限.(错误)
这个说法是一个"历史遗留”
早期版本的浏览器(硬件资源非常匮乏),针对 GET 请求的 URL的长度做出了限制实际上,RFC 标准文档中并没有明确规定 URL 能有多长.
目前的浏览器和服务器的实现过程中,URL 可以非常长的.(甚至说可以使用 URL 传递一些图片这样的数据)2.GET 请求传递数据不安全. POST 请求传递数据更安全(错误)
依据是: 如果使用 GET 请求来实现登录,
点击登录的时候,就会把用户名和密码放到 ur 中,进一步的显示到浏览器地址栏里,(不就被别人看到了吗)相比之下,POST 则是在 body 中,不会在界面上显示出来,所以就更安全【不放在界面上显示,只是忽悠一下小白.对于黑客来说获取成本并不高~~】【通常说的"安全"指的是你传递的数据,不容易被黑客获取或者被黑客获取到之后,不容易被破解.】【post的密码其实一抓包就被获取了。但是,由于这个密码是加密的, 即使拿到了,也不容易破解!此处的安全性,和 post 无关. 关键在于 加密.】
3. GET 只能给服务器传输 文本数据. POST 可以给服务器传输文本 和 二进制数据(错误)
1)GET 也不是不能使用 body (body 中是可以直接放二进制的)2)GET 也可以把 二进制的数据进行 base64 转码,放到 ur 的 query string 中
【不完全错误的说法】
1. GET 请求是幂等的.POST 请求不是幂等的[不够准确, 但是也不是完全错]
幂等 数学概念.->输入相同的内容,输出是稳定的GET 和 POST 具体是否是幂等,取决于代码的实现
GET 是否幂等,也不绝对.只不过 RFC 标准文档上建议 GET 请求实现成幂等的
【典型的不幂等的情况:广告数据,每回打开的广告都不一样】
2.GET 请求可以被浏览器缓存,POST 不可以被缓存(幂等性的延续.如果请求是幂等,自然就可以缓存)
3.GET 请求可以被浏览器收藏夹收藏,POST 不能 (收藏的时候可能会丢失 body)
这种说法也 ok, 和技术关系不大.看用户需求
2.3 header
host
Content-type
后续给服务器提交给请求,不同的 Content-Type, 服务器处理数据的逻辑是不同的
服务器返回数据给浏览器,也需要设置合适的 Content-Type,浏览器也会根据不同的 Content-Type 做出不同的处理
user-Agent
refer
【question】是否可能存在一种情况,有人把 Referer给改了,本来是搜狗的 referer,改成了别的广告平台的 referer?
存在这样的问题
如何解决?
使用 HTTPS 来代替 HTTP
HTTP 最大的问题在于"明文传输",明文传输就容易被第三方获取并篡改
HTTPS 针对 HTTP 数据进行了加密 (header 和 body 都加密了).第三方想要获取或者篡改,就没那么容易了
通过这个手段,就可以有效遏制运营商劫持这样的情况~~
现在,网络上网站都是 HTTPS 为主了,很少见到 HTTP.
cookie
浏览器的数据来自于服务器.
浏览器后续的操作也是要提交给服务器的
服务器这边管理了一个网站的各种核心数据
但是程序运行过程中,也会有一些数据,需要在浏览器这边存储的,并且在后续请求的时候数据可能需要再发给服务器上次登陆时间.上次访问时间.用户的身份信息, 累计的访问次数....(临时性的数据.存储在浏览器比较合适的.)实际上更容易想到的是,把这样的数据直接存储到本地文件中~~
但是实际上不可行的,浏览器为了考虑到安全性,禁止网页直接访问你的电脑的文件系统.
网页代码中也就无法直接生成一个硬盘的文件来储数据了(怕你访问某个网站,结果
网页里有病毒,把你硬盘上的所有学习资料都给删掉了)为了保证安全性,又能进行存储数据,于是就引入了 Cookie(也是按照硬盘文件的方式保存的,但是浏览器把操作文件给封装了网页只能往 Cookie 中存储 键值对)(简单的字符串)






Cookie 往往是从服务器返回的数据(也可以是页面自己生成的)
Cookie 存储到浏览器所在主机的硬盘上, 并且是按照 域名 为维度来存储的,
(每个域名下可以存自己的 Cookie,彼此之间不影响)
Cookie 是按照键值对的形式来组织的,这里的键值对也都是程序猿自定义的 (和 query string 差不多)后续再请求这个服务器的时候,就会把 Cookie 中的内容自动代,入到请求中,发给服务器,服务器通过 Cookie 的内容做一些逻辑上的处理
1.200 OK
2.404 Not Found(没有找到资源. )
3.403
表示访问被拒绝. 有的页面通常需要用户具有一定的权限才能访问(登陆后才能访问). 如果用户没有登陆直接访问, 就容易见到 403.4. 405 Method Not Allowed我们已经学习了 HTTP 中所支持的方法 , 有 GET, POST, PUT, DELETE 等 .但是对方的服务器不一定都支持所有的方法 ( 或者不允许用户使用一些其他的方法 ).5.3开头的是重定向
301 临时重定向
302 永久重定向
(重定向的响应报文中,会带有 Location 字段描述出当前要跳转到哪个新的地址)
6.500 Internal Server Error(服务器挂了)服务器出现内部错误 . 一般是服务器的代码执行过程中遇到了一些特殊情况 ( 服务器异常崩溃 ) 会产生这个状态码.7.418彩蛋

键值对~~ HTTP 中存在很多种键值对~~
1) query string
2) header
3) cookie
4) body
form key1=value1&key2=value2json { key1: value1, key2: value2}
3.如何让客户端构造一个 HTTP 请求
如何让服务器处理一个 HTTP 请求 [重中之重] Servet/Spring
浏览器
1.直接在浏览器 地址栏 输入 ur, 此时构造了一个 GET 请求,
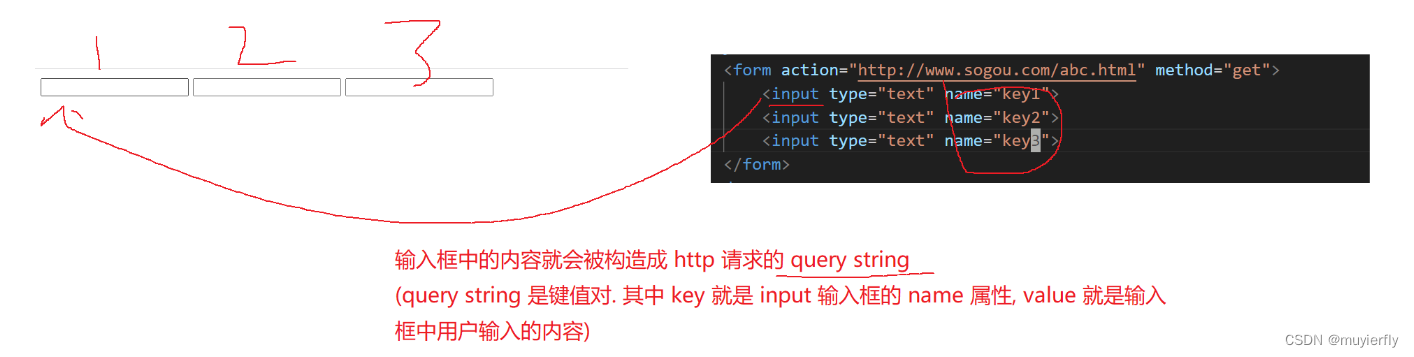
2. htm| 中, 一些特殊的 htm| 标签, 可能会触发 GET 请求,比如像 img, a, link, script ..3. 通过 form 表单来触发 GET/POST 请求
form 本质也是一个 HTML 标签~~
浏览器对于 html 来说具有一定的鲁棒性(容错能力)
即使给出了一个错误的 (不规范) 的 htm 代码,也是可以进行解析并显示的.(浏览器会尽可能的进行显示)form表单
对于 GET 来说, 这几个键值对,是在 ur 中
对于 POST 来说, 这几个键值对,就在 body 中了




ajax
form 有一些缺陷.
只支持 GET 和 POST,不支持其他方法.
form 会触发页面跳转,(有的时候不想跳转)
ajax.通过js 提供的 api 来构造 http 请求,针对拿到的响应,同样可以使用 js灵活处理,想要怎么处理都行,或者想跳转不跳转也都行.
给前端代码,带来了更多的可操作空间.
现在的网站,主体都是通过 aiax 的方式来进行交互的
浏览器原生提供了 ajax 的 api, 原生的 api 特别难用还有一些第三方库,封装了 ajax,就准备使用封装的版本来进行操作,我们使用的是 jquery 这个库,封装的 ajax1.引入 jquery 库.
(第三方库,是需要额外下载引入的)前端引入第三方库非常容易的,只要代码中写一个库的地址即可.
【js 和 java 之间有一定差别的.差别也不算很大。
差别主要体现在类型系统上.
基本的 变量定义,运算符, 表达式,条件,循环, 函数.... 大同小异,js 的数组和 java 差异比较大了(也是和类型系统有关)】https://www.bootcdn.cn/jquery/
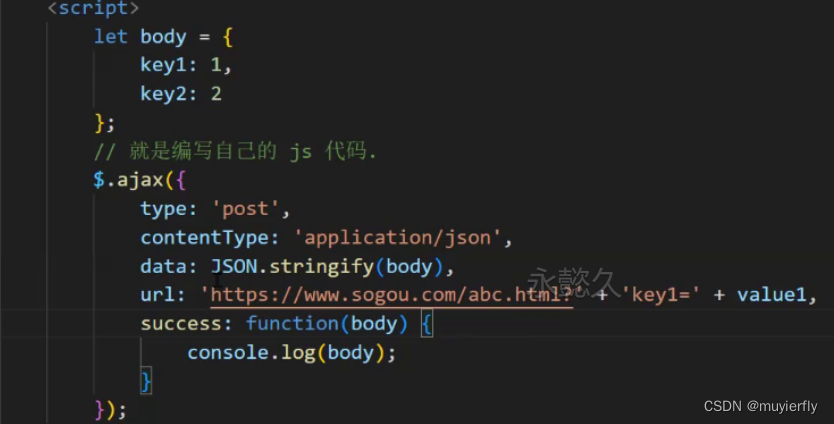
2. 编写代码
$.ajax();
$ 是一个变量名(全局变量,在jquery 中定义的)通过这个变量来调用一些方法,使用jquery 中的 api
js 中 {} 表示对象,
{}里面是使用 键值对 的方式来描述"属性名"和"属性值"的.
JsoN.stringify(body)
这个操作就可以把 js 对象转成 json 格式的字符串了

4.HTTPS
当前网络上,主要都是 HTTPS 了,很少能见到 HTTP.实际上 HTTPS 也是基于 HTTP.
(前面讲过的 HTTP 的各个方面的内容,对于 HTTPS 同样适用)
只不过 HTTPS 在 HTTP 的基础之上,引入了"加密"机制。
引入 HTTPS 防止你的数据被黑客篡改 (尤其是反针对 运营商劫持)
明文 + 密钥 => 密文
密文 +密钥 => 明文
在密码学中,使用密钥加密,有两种主要的方式
1.对称加密.
加密和解密,使用的密钥 是同一个密钥
设 密钥 为 key
明文 + key =>密文
密文 + key => 明文2.非对称加密.
有两个密钥(一对)这俩密钥,一个称为"公钥",一个称为"私钥"(公钥就是可以公开的,私钥就是自己藏好的)
明文 + 公钥 =>密文
密文 + 私钥 =>明文
或者
明文 + 私钥 =>密文
密文 + 公钥 =>明文
4.1 HTTPS 的工作过程.
目标, 针对 HTTP 这里的 header 和 body 进行加密~~
1.先引入对称加密
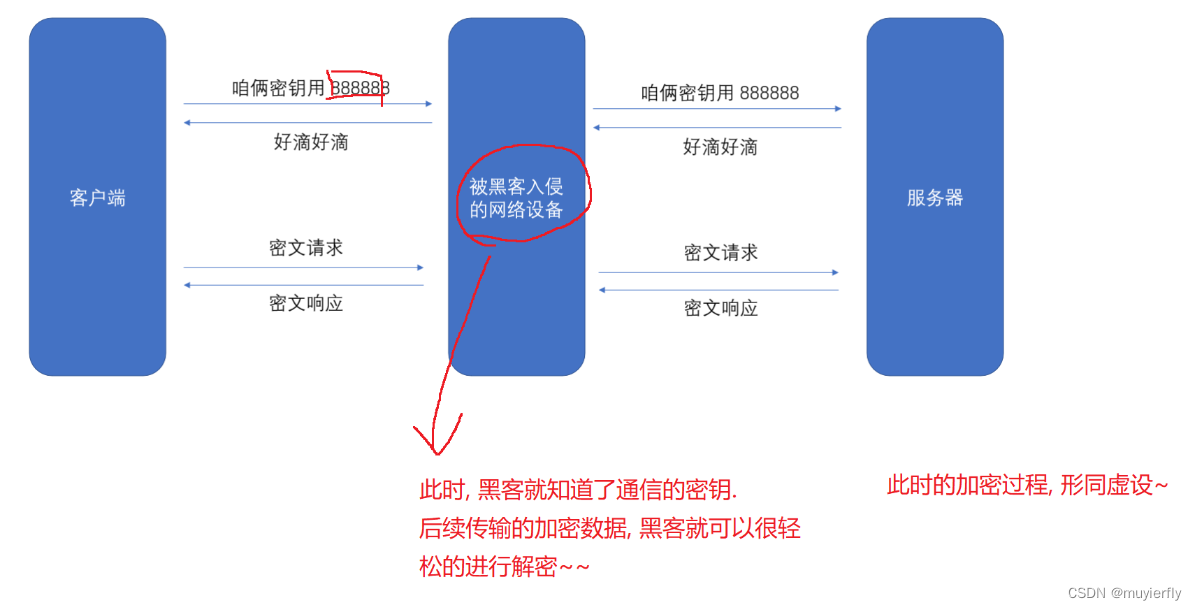
上面的模型存在一个重要问题,服务器不是只和一个客户端通信,而是和很多客户端通信.
这些客户端使用的 对称密钥 是相同的嘛?很明显,必须要求每个客户端的密钥都不相同,彼此之间才不知道对方的密钥是什么
此时要求每个客户端对应的密钥都不同,
现在就需要每个客户端,在和服务器建立连接的时候,就把密钥给生成出来 (涉及到一些随机数机制在里面,保证每个客户端生成的密钥都不同)
客户端再把自己的密钥通过网络传输给服务器(密钥可能会被黑客截获)【出现问题-黑客的操作】
2.为了解决上述安全传输密钥的问题, 引入了"非对称加密"
非对称加密中,有一对密钥.公钥 私钥.
可以使用公钥加密,私钥解密.
或者使用私钥加密,公钥解密:
理论上来说,黑客拿到公钥之后,也是有可能推算出私钥是什么.但是实际上这个推算过程,计算成本极高(计算量非常大,就算是用最牛逼的超算,也需要算好多年.....)
这个难度,还不如想办法黑如服务器来的更容易


既然已经引入了非对称加密,为啥还需要引入对称加密呢?直接使用非对称加密,来完成所有业务数据的加密传输即可?
进行非对称加密/解密,运算成本是比较高的.运算速度也是比较低的,对称加密,运算成本低,速度快,
使用非对称加密,只是用来进行这种关键环节(传输密钥)(一次性的工作,体积也不大),成本就比较可控后续要传输大量的业务数据,都使用效率更高的对称加密,比较友好的做法.
如果业务数据都使用非对称加密,整体的传输效率就会大打折扣了引入安全性,引入加密,也势必会影响到传输效率,我们也是希望让这样的影响能尽可能降到最低~~
上述 对称加密 + 非对称加密 过程就是 HTTPS 的基本盘~~但是光有这些还不够,上述流程中还存在一个严重的漏洞,黑客如果利用好这个漏洞,仍然可以获取到原始的明文数据
3.中间人攻击
如何解决中间人攻击问题???
之所以能进行中间人攻击,关键要点在于客户端没有"分辨能力!
客户端不知道当前这个公钥是不是黑客伪造的!!!
这里的“分辨"不能靠"自证"(谁都是说自己是真的)
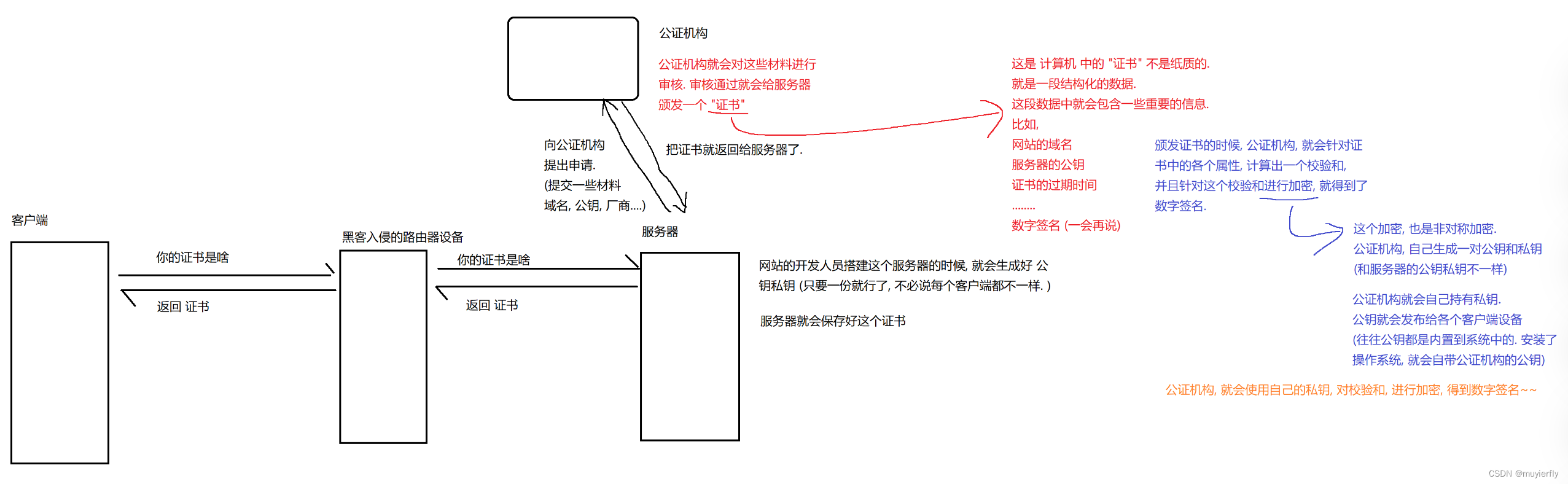
引入第三方的可以被大家都信任的"公证机构"公证机构说这个公钥是正确的,不是被伪造的,我们就是可以信任的~~
客户端拿到了证书,也就拿到了证书中的公钥~~
客户端就需要验证这个公钥是否是服务器最初的公钥(是否是被黑客篡改了??)
这个过程,就称为"证书的校验”
如何进行校验?核心机制,就是"数字签名"=>被 加密 后的校验和【拿着你数据的每个字节,带入公式,就能算出一个结果数字,称为校验和.
把这个数据和校验和一起发送给对方,
对方再按照同样的方式再算一遍校验和.如果对方自己算的校验和和收到的校验和一致,就认为数据在传输过程中,没有改变过~~】
此时, 客户端拿到了数字签名,就可以通过系统内置的公证机构的公钥,进行解密了.得到了最初的校验和.
客户端再 重新 计算一遍 这里的校验和,和解密出来的校验和进行对比如果校验和一致,就可以认为证书没有被篡改过,
公钥就是可信的(服务器原始的公钥)

在上述机制下,黑客就无法对证书内容进行篡改了,即使篡改,也很容易被发现
当黑客收到证书之后,如果直接修改里面的公钥,替换成自己的,客户端在进行证书校验的时候,就会发现校验和不一致了!!!客户端就可以认为是篡改过了.(客户端这边往往就会弹出一些对话框来警告用户,存在安全风险)那么黑客替换公钥之后,能否自己替换掉数字签名,自己算一个呢??
不能的!!! 校验和好算,针对校验和加密,需要使用 公证机构 的私钥,才能进行的.黑客没有这个私钥.如果黑客拿自己的私钥加密,客户端也就无法使用公证机构的公钥解密了公证机构的公钥是客户端系统自带的,黑客也无法替换..
结合上述过程,证书就是可信的.通过了校验,就说明公钥就是服务器原始的公钥了
黑客是否能自己也申请一个证书,完全替换掉,服务器的证书呢??行不通的!!申请证书,需要提交资料,其中就有网站的主域名~~认证机构自然就会认证这个域名是否是你所有的~~
https 加密:
1)对称加密,加密业务数据
2)非对称加密,加密对称密钥
3)防止中间人攻击,使用证书, 校验服务器的公钥
这三者相结合,保证最终 https 的安全性了