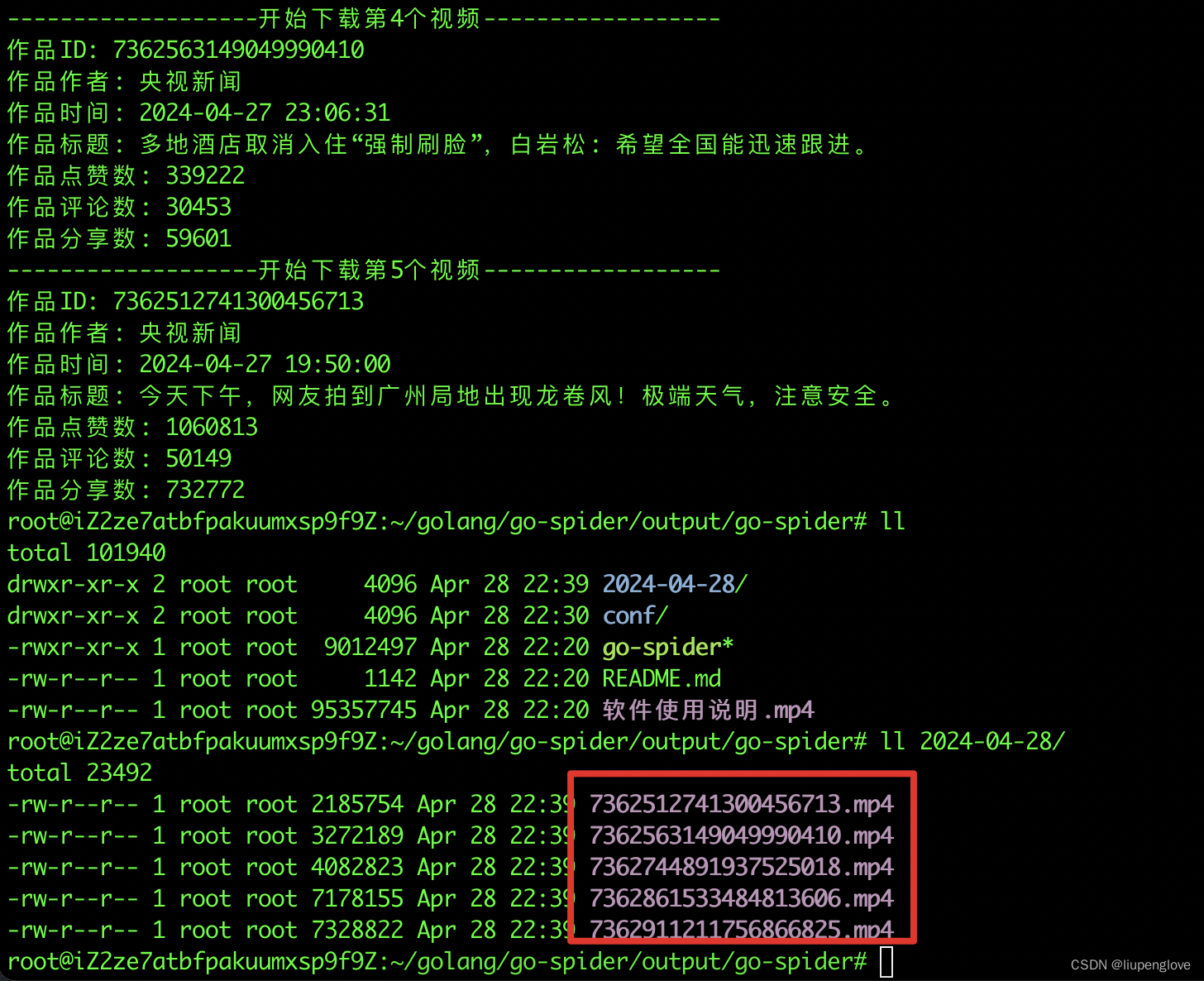
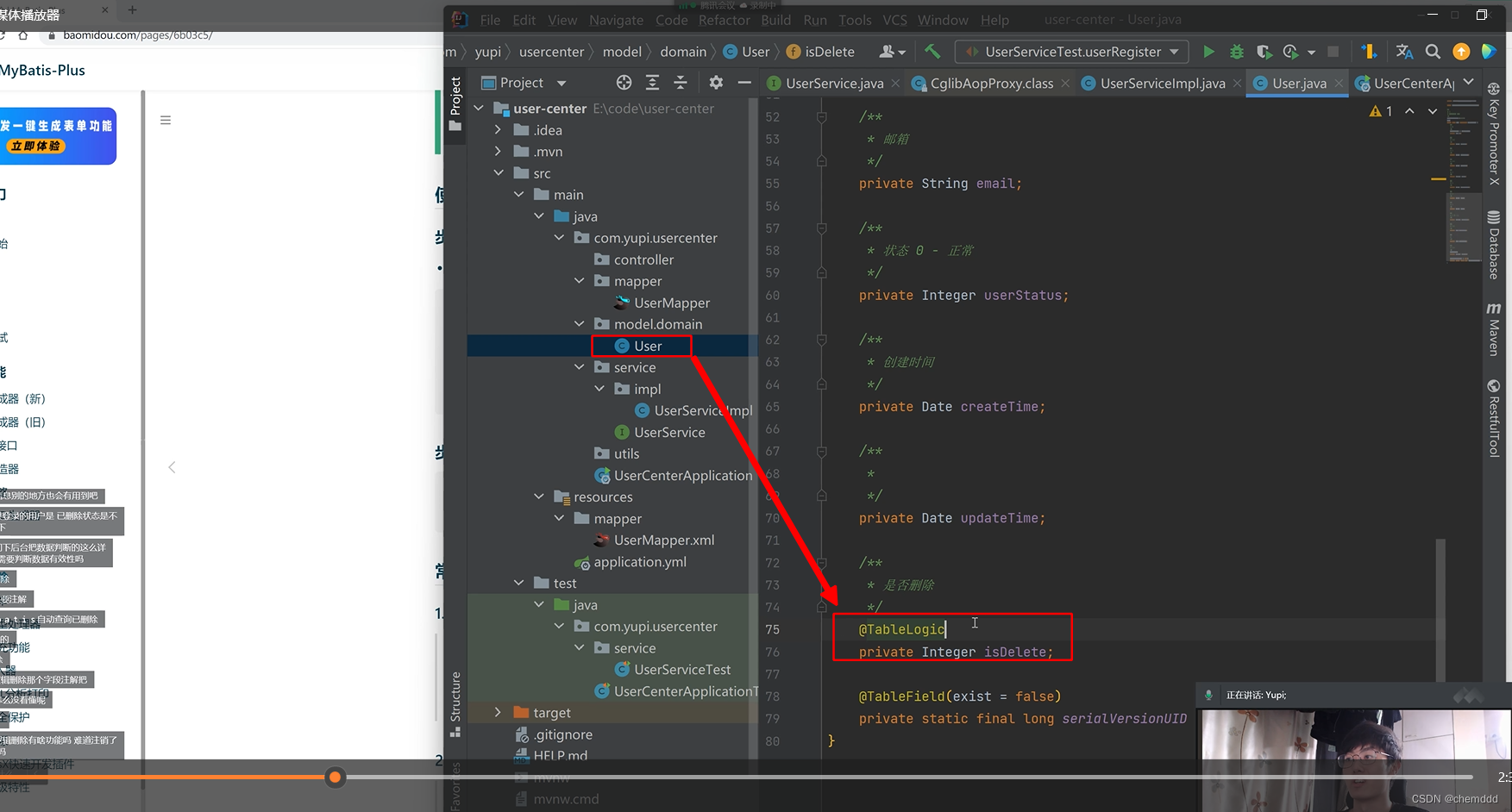
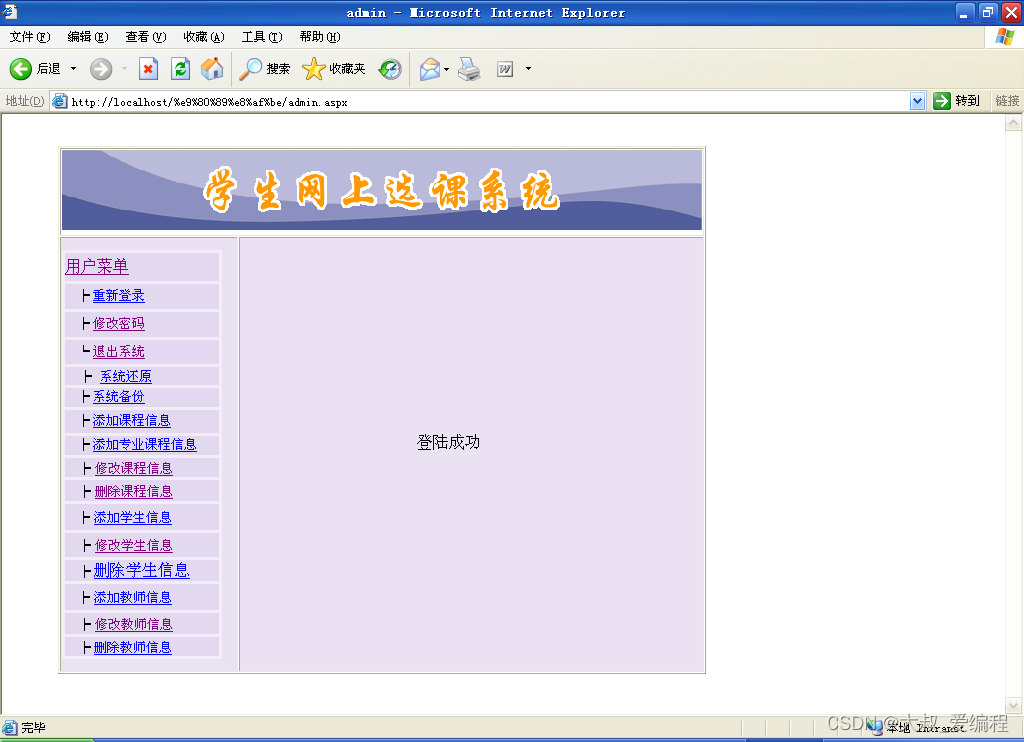
简介:这个代码可以用于时间序列修复和生成。使用transformer提取单变量或者多变时间窗口的趋势分布情况。然后使用GAN生成分布类似的时间序列。
此外,还实现了基于prompt的数据生成,比如指定生成某个月份的数据、某半个月的数据、某一个星期的数据。
1、模型架构
如下图所示,生成器和鉴别器都使用Transformer的编码器部分提取时间序列的特征,然后鉴别器使用这些进行二分类、生成器使用这些特征生成伪造的数据。
重点:在下面的图的基础上,我还添加了基于提示的生成代码,类似于AI提示绘画一样,因此可以指定生成一月份、二月份等任意指定周期的数据。
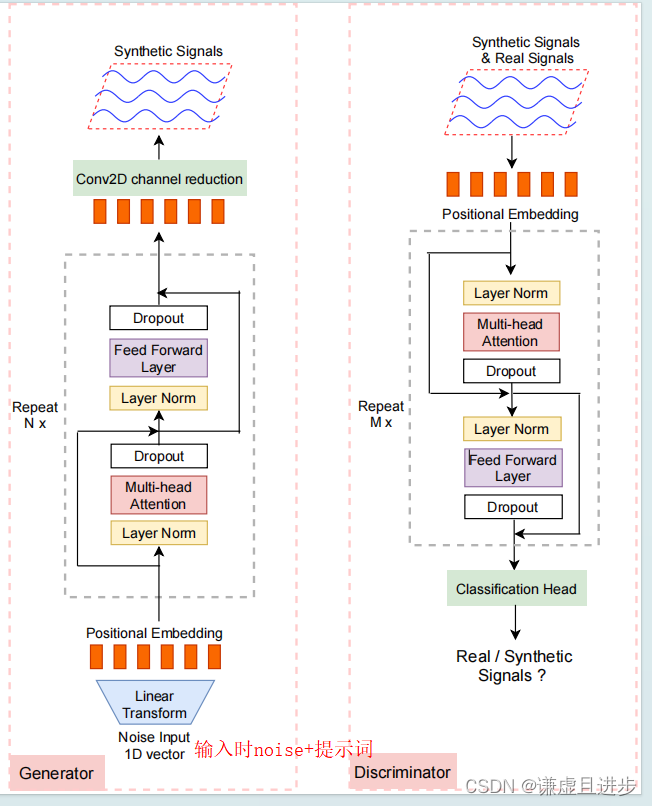
2、训练GAN的代码
下面是GAN的训练部分。
# 训练GAN
num_epochs = 100
for epoch in range(num_epochs):for real_x,x_g,zz in loader: # 分别是真实值real_x、提示词信息x_g、噪声zzreal_data = real_xnoisy_data = x_g# Train Discriminatoroptimizer_D.zero_grad()out = discriminator(real_data)real_loss = criterion(discriminator(real_data), torch.ones(real_data.size(0), 1))fake_data = generator(noisy_data,zz)fake_loss = criterion(discriminator(fake_data.detach()), torch.zeros(fake_data.size(0), 1))d_loss = real_loss + fake_lossd_loss.backward()optimizer_D.step()# Train Generatoroptimizer_G.zero_grad()g_loss = criterion(discriminator(fake_data), torch.ones(fake_data.size(0), 1))g_loss.backward()optimizer_G.step()print(f'Epoch [{epoch+1}/{num_epochs}], D Loss: {d_loss.item()}, G Loss: {g_loss.item()}')3、生成器代码
class Generator(nn.Module):def __init__(self, seq_len=8, patch_size=2, channels=1, num_classes=9, latent_dim=100, embed_dim=10, depth=1,num_heads=5, forward_drop_rate=0.5, attn_drop_rate=0.5):super(Generator, self).__init__()self.channels = channelsself.latent_dim = latent_dimself.seq_len = seq_lenself.embed_dim = embed_dimself.patch_size = patch_sizeself.depth = depthself.attn_drop_rate = attn_drop_rateself.forward_drop_rate = forward_drop_rateself.l1 = nn.Linear(self.latent_dim, self.seq_len * self.embed_dim)self.pos_embed = nn.Parameter(torch.zeros(1, self.seq_len, self.embed_dim))self.blocks = Gen_TransformerEncoder(depth=self.depth,emb_size = self.embed_dim,drop_p = self.attn_drop_rate,)self.deconv = nn.Sequential(nn.Conv2d(self.embed_dim, self.channels, 1, 1, 0))def forward(self, z):x = self.l1(z).view(-1, self.seq_len, self.embed_dim)x = x + self.pos_embedH, W = 1, self.seq_lenx = self.blocks(x)x = x.reshape(x.shape[0], 1, x.shape[1], x.shape[2])output = self.deconv(x.permute(0, 3, 1, 2))output = output.view(-1, self.channels, H, W)return output4、生成数据和真实数据分布对比
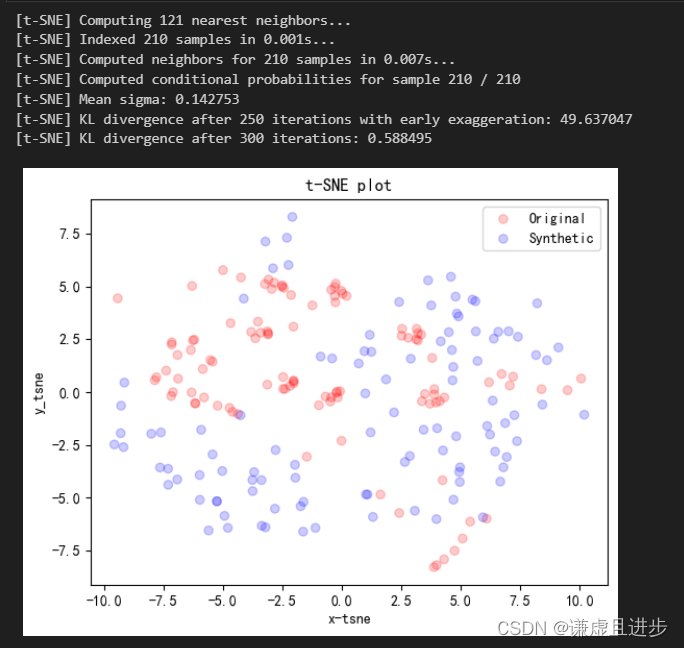
使用PCA和TSNE对生成的时间窗口数据进行降维,然后scatter这些二维点。如果生成的真实数据的互相混合在一起,说明模型学习到了真东西,也就是模型伪造的数据和真实数据分布是一样的,美滋滋。从下面的PCA可以看出,两者的分布还是近似的。
进一步的,可以拟合两个二维正态分布,然后计算他们的KL散度作为一个评价指标。

5、生成数据展示
上面是真实数据、下面是伪造的数据。由于只有几百个样本,以及参数都没有进行调整,但是效果还不错。

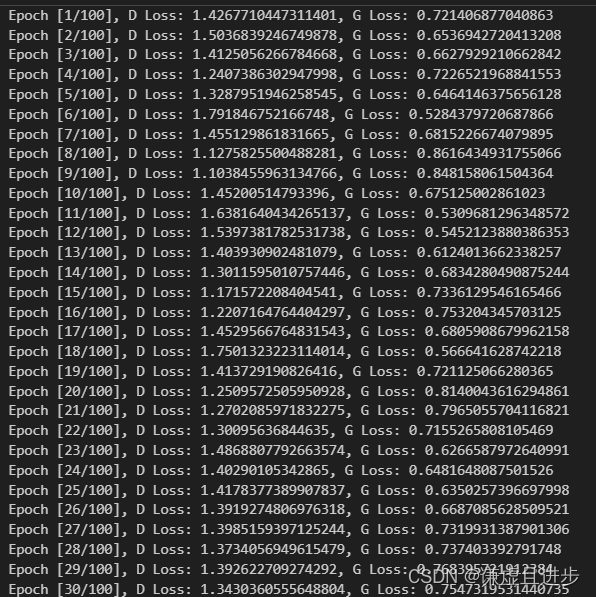
6、损失函数变化情况
模型还是学习到了一点东西的。





![[图解]软件开发中的糊涂用语-04-为什么要追究糊涂用语](https://img-blog.csdnimg.cn/direct/464e3f6116b54b5086302c30131b707b.png)