目录
1. 实现代码
2. Reactor 模式
3. 分析服务器的实现具体细节
3.1. Connection 结构
3.2. 服务器的成员属性
3.2. 服务器的构造
3.3. 事件轮询
3.4. 事件派发
3.5. 连接事件
3.6. 读事件
3.7. 写事件
3.8. 异常事件
4. 服务器上层的处理
5. Reactor 总结
1. 实现代码
EventLoop 服务器实现代码已上传到gitee中。
https://gitee.com/qiange-c/linux-daily-testing-code/tree/0a25822f5ded574a70a2eb65ed6b32d963343bed/2024_4_22/Reactor![]() https://gitee.com/qiange-c/linux-daily-testing-code/tree/0a25822f5ded574a70a2eb65ed6b32d963343bed/2024_4_22/Reactor
https://gitee.com/qiange-c/linux-daily-testing-code/tree/0a25822f5ded574a70a2eb65ed6b32d963343bed/2024_4_22/Reactor
2. Reactor 模式
Reactor 也称之为反应堆模式, 其核心思想就是将事件的产生和处理解耦,通过事件轮询和事件处理器来实现事件的分发和处理,从而提高服务器的并发性能和可扩展性。
3. 分析服务器的实现具体细节
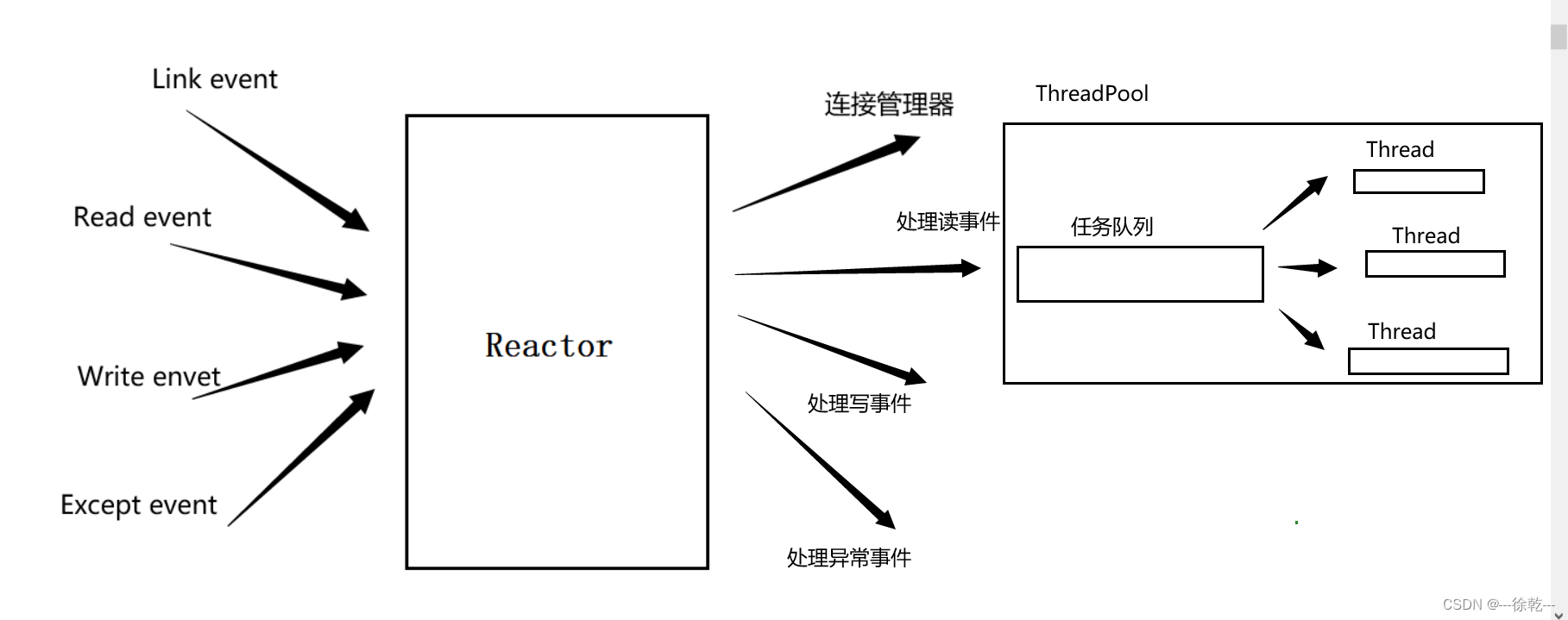
实现大致思路如下:
3.1. Connection 结构
我们写过 epoll 服务器的代码,说过一个问题,由于 TCP 是面向字节流的,服务器调用read/recv 后,无法保证获得的就是一个完整报文,因此,上层需要定制协议,诸如序列化和反序列化过程,判断能否构成一个完整报文 (解决粘包问题) 等等,可是,如果服务端收到的数据不能构成一个完整报文,那么这些数据是不是服务器自身应该保存起来,如果能构成一个完整报文,服务器在将构成完整报文的那一部分数据在清除,在进行后续处理,同时,服务器未来会为众多客户端提供服务,即会有众多的服务套接字,因此:
- 为了保证每个服务套接字的数据正确处理,其实每一个套接字都要有属于自己的发送缓冲区和接收缓冲区,可是如果这个缓冲区是一个局部的临时变量,是不符合需求的,因此,我们将服务套接字套接字和缓冲区 (还包含其他字段) 封装到一起;
- 其次,我们知道,未来服务套接字都需要处理读事件、写事件、异常事件,而对于监听套接字而言,它只需要关心读事件 (即获取新连接),因此,我们可以将它们统一看待,认为每个套接字都需要关读事件、写事件、异常事件,而监听套接字特殊处理即可,那么如何表示这三个事件呢? 我们通过三个回调函数表示读、写、异常事件,如果相应的事件发生,就调用相应的事件回调;
- 再然后,我们需要一个回指指针,在这里无法说清楚,只能在后面代码解释;
- 最后,我们增加了一个地址信息,这个用来描述客户端的地址信息,服务端采用默认值 (服务端的无意义);
具体字段如下:
// 处理IO的回调函数类型
using IoCallBack = std::function<void(Connection*)>;
// 上层处理的回调函数
using UserCallBack = std::function<void(Connection*)>;class User
{
public:void SetUserInfo(const std::string& ip = "0.0.0.0", uint16_t port = 0){_ip = ip;_port = port;}uint16_t _port;std::string _ip;
};class Connection
{
public:Connection(int sock, TcpServer* back_ptr):_sock(sock), _back_ptr(back_ptr){}// 设置回调void SetIOEventCallBack(IoCallBack read_call_back, IoCallBack write_call_back, IoCallBack except_call_back){_read_call_back = read_call_back;_write_call_back = write_call_back;_except_call_back = except_call_back;}// 这里用public, 主要是不想写太多的Get和Set方法
public:// 监听套接字 + 服务套接字int _sock;// 每个套接字需要有自己的接收缓冲区和发送缓冲区std::string _inbuffer; // 接收缓冲区std::string _outbuffer; // 发送缓冲区// 每个套接字需要有自己的回调, 用来处理读、写、异常事件IoCallBack _read_call_back; // 处理读时间的回调IoCallBack _write_call_back; // 处理写事件的回调IoCallBack _except_call_back; // 处理异常事件的回调TcpServer* _back_ptr; // 回值指针, 指向服务器User _user; // 客户端地址信息
};3.2. 服务器的成员属性
服务器的成员属性如下:
class TcpServer
{private:// 作为服务器, 自然需要端口uint16_t _port;// 也需要监听套接字int _listensock;// 套接字对象, 封装了套接字的接口Sock _sock;// epoll 模型Epoll _epoll;// 将文件描述符和Connection以哈希表组织起来std::unordered_map<int, Connection*> _Fd_Connection_Map;// 就绪事件的最大值int _revents_num;// 存放就绪事件的数组struct epoll_event* _revents;// 上层业务的回调函数UserCallBack _OnUserCallBack;
};作为一款服务器,端口和监听套接字是必要的,当然,因为这款服务器是基于 epoll 的,因此,也需要一个 epoll 模型,不再多说,更重要的是下面的思路。
上面说了,我们需要将套接字封装到 Connection 这个结构,换言之,未来的套接字不会单独出现,而是以 Connection 为载体出现的。
而服务端面对的是众多客户端,因此,自然会有众多的服务套接字,那么服务器是需要将它们进行管理起来的,写了这么久,我们一提到管理两个字,就应该能想到,管理,就需要先描述再组织,很碰巧,Connection 这个结构不就是一个描述的过程吗? 因此,我们只需要在进行组织即可,STL 为我们提供了这个便利,因此我们通过哈希表,将文件描述符和Connection对象组织起来。
至于这个上层业务的回调函数,该如何理解呢?
我们说过,当服务端收到数据后,无法直接对这些数据做处理,而应该交给上层 (一层中间软件层) ,让上层自己判断,服务端读到的数据,能否组成一个完整报文,如果可以,那么这层中间软件层,在将数据交给上层业务处理,否则,直接返回,不做任何处理,因此,服务器需要一个字段,这个字段指向上层定义的方法。
3.2. 服务器的构造
服务器的构造具体思路:
- 第一步:作为服务器,毫无疑问,需要监听套接字。 过程就是:创建监听套接字、绑定、监听;
- 第二步: 作为基于 epoll 的服务器,肯定是需要一个 epoll 模型的。 通过这个 epoll 模型,用户告诉内核,哪些文件描述符的哪些事件需要被内核关心 (epoll_ctl), 以及, 内核告诉用户,哪些文件描述符的哪些事件已经就绪 (epoll_wait),具体细节,就不论述了;
- 第三步:
- 首先,Reactor 模式的服务器的工作方式是ET的,因此,需要将套接字设置为非阻塞状态;
- 其次,因为套接字是以Connection呈现的,因此需要构建Connection对象,并需要用户设置相应的回调;
- 然后,我们需要让内核关心这些套接字,没有内核的参与,上层再怎么设计,也是无用之功,那么如何关心? 本质是将这个套接字及其关心的是间添加到epoll模型中;
- 接着,我们要将这个套接字,及其刚刚构建的Connection对象组合起来并添加到映射表中;
- 最后,将服务套接字对应的客户端的地址信息也设置一下,对于监听套接字而言,采用默认值 (无意义的);
- 实际上,关于上面这几步,我们会封装成为一个函数,让所有的套接字 (监听套接字和服务套接字) 都通过这个接口完成第三步。
- 上面的三大步,就是服务器的构造函数的具体实现思路,代码如下:
// 默认端口
const static uint16_t g_port = 8080;
// revents数组的默认大小
const static int g_revents_num = 64;
// read/recv 缓冲区的默认大小
const static int g_buffer_num = 1024;TcpServer(uint16_t port = g_port, UserCallBack OnUserCallBack = nullptr)
:_port(port)
, _revents_num(g_revents_num)
, _OnUserCallBack(OnUserCallBack)
{// 创建套接字, 绑定, 监听_sock.Socket();_sock.Bind("", _port);_sock.Listen();_listensock = _sock._sock;// 创建 epoll 模型, 返回一个 epfd_epoll.Create_Epoll();// 将套接字封装到了Connection里// 本质上是将套接字和Connection强关联到了一起, 即是一个先描述的过程// 因此, 未来不会有单独的套接字, 而是以一个整体Connection 出现// 而作为一个服务器, 是会为大量的客户端提供服务的// 换言之, 服务器会存在大量的套接字, 即Connection对象, 因此服务器// 就需要将所有的Connection对象管理起来. // 如何管理, 先描述, 再组织, 前者的工作已经就绪// 现在只需要用一个数据结构将其组织起来即可// 因此, 用一个哈希映射表, 将文件描述符和connection 对象映射,并管理起来// 监听套接字 默认为 "0.0.0.0" 和 0;AddFdConnectionToMap(_listensock, std::bind(&TcpServer::Accepter, this, std::placeholders::_1), nullptr, nullptr, "0.0.0.0", 0);// 定义数组, 用于存储就绪事件_revents = new struct epoll_event[_revents_num];LogMessage(DEBUG, "server init success");
}void AddFdConnectionToMap(int sock, IoCallBack read_call_back, IoCallBack write_call_back, IoCallBack except_call_back,const std::string& client_ip, uint16_t client_port)
{// step 0: 将所有套接字都设置为非阻塞状态Xq::Sock::SetNonBlock(sock);// step 1: 创建Connection对象Connection* connection = new Connection(sock, this);connection->SetIOEventCallBack(read_call_back, write_call_back, except_call_back);// step 2: 将套接字添加到Epoll模型中// 任何多路转接服务器, 一般默认只会打开对读事件的关心, 写事件会按需打开// 且该服务器的工作模式是ET模式, 故需要添加EPOLLET_epoll.AddIoEvent_Epoll(sock, EPOLLIN | EPOLLET);// step 3: 将套接字和connection对象添加到映射表中_Fd_Connection_Map[sock] = connection;// step 4: 设置地址信息connection->_user.SetUserInfo(client_ip, client_port);
}3.3. 事件轮询
作为一款服务器,肯定是需要启动服务器的接口,而对于 Reactor 模式的服务器而言,它是基于事件轮询 (Event Loop) 的,其负责监听事件,当事件就绪时,根据相应回调进行处理事件;
在每一次轮询过程中,就需要调用 EventDispatch 接口,即事件派发,当事件就绪后,根据不同的事件,做不同的处理。
// 事件轮询
void EventLoop(void)
{// 阻塞式int timeout = -1;while (true){LoopOnce(timeout);}
}void LoopOnce(int timeout)
{// 事件派发EventDispatch(timeout);
}3.4. 事件派发
事件派发的处理思路很简单,通过 epoll 模型提供的 epoll_wait 接口,获得就绪的事件,处理这些就绪的事件即可;
不过需要注意的是:
- 对于异常事件的处理,如果出现了事件异常,我们将其统一转化为读写事件,此时进行读写时,就会读写错误,因而触发读写中的异常处理,换言之,我们将所有异常情况都会统一在一起,当发生异常时,调用统一的接口,统一处理异常情况;
- 因此,有了统一处理异常情况的前提,服务器只需要处理读写事件即可,根据 Connection 对象以及事件的类型,调用 Connection 中的回调,进而处理事件;
- 最后,为了严谨性,在执行相应的回调时,我们需要判断这个Connection对象是否还存在,如果存在,在根据相应的事件,调用相应的回调。
代码如下:
void EventDispatch(void)
{int num = _epoll.Wait_Epoll(_revents, _revents_num, timeout);if (num < 0) {LogMessage(ERROR, "errno: %d, error message: %s", errno, strerror(errno));}else if (num == 0) {LogMessage(NORMAL, "time out...");}else{for (int pos = 0; pos < num; ++pos){int sock = _revents[pos].data.fd;uint32_t events = _revents[pos].events;// 把异常事件统一转化成读写事件if (events & EPOLLERR)events |= (EPOLLIN | EPOLLOUT);if (events & EPOLLHUP)events |= (EPOLLIN | EPOLLOUT);// 只需要处理 EPOLLIN 和 EPOLLOUT// 读事件就绪if (IsConnectionExist(sock) && (events & EPOLLIN)){_Fd_Connection_Map[sock]->_read_call_back(_Fd_Connection_Map[sock]);}// 写事件就绪if (IsConnectionExist(sock) && (events & EPOLLOUT)){_Fd_Connection_Map[sock]->_write_call_back(_Fd_Connection_Map[sock]);}}}
}bool IsConnectionExist(int sock)
{return _Fd_Connection_Map.find(sock) != _Fd_Connection_Map.end();
}3.5. 连接事件
因为服务器是根据事件派发中的相应回调,调用这个函数的,因此,走到这里,不会存在阻塞的情况,换言之,此时,底层是一定有就绪的连接,等待上层 accept 的;
此外,因为是ET的工作模式,故需要轮询accept:
- 如果返回值小于0,代表accept 失败了,此时就需要根据 errno 这个全局变量,来判断,是底层没有连接了 (EWOULDBLOCK 或者 EAGAIN),还是这次的 accept 被信号中断了 (EINTR),还是真的 accept 出错了呢?
- 如果返回值大于0,代表成功获取连接,那么也要做下面这几件事情:
- 首先,Reactor 模式的服务器的工作方式是ET的,因此,需要将套接字设置为非阻塞状态;
- 其次,因为套接字是以Connection呈现的,因此需要构建Connection对象,并需要用户设置相应的回调;
- 然后,我们需要让内核关心这些套接字,没有内核的参与,上层再怎么设计,也是无用之功,那么如何关心? 本质是将这个套接字及其关心的是间添加到epoll模型中;
- 接着,我们要将这个套接字,及其刚刚构建的Connection对象组合起来并添加到映射表中;
- 最后,将服务套接字对应的客户端的地址信息也设置一下,对于监听套接字而言,采用默认值 (无意义的);
- 很明显,为了降低复杂度和解耦,我们是需要将上面这几个过程封装为一个接口的。
- 这就是连接事件处理的具体过程,思路很清晰,应该很好理解。
代码如下:
void Accepter(Connection* connection)
{// 如果服务器走到这里, 绝不会被阻塞// 因此可以直接获取新连接// 可是, 对于服务器而言, 可能底层会有很多完成三次握手过程的连接// 即底层不止一个链接需要被accept// 因此, 服务器通过监听套接字获取新连接, 也要以轮询的方案获取// 保证将底层的所有连接获取上来while (true){std::string clientip;uint16_t clientport;// 在轮询的过程中, 当accept失败时, 会有下面三种情况三种情况:// case 1: errno == EAGAIN || errno == EWOULDBLOCK, 代表底层连接已全部获取, 跳出循环即可;// case 2: errno == EINTR, 代表此次accept被信号中断, 重新accept获取连接即可// case 3: errno 等于其他值, 代表真的出错了;int sock = _sock.Accept(connection->_sock, clientip, &clientport);if (sock == -1){if (errno == EAGAIN || errno == EWOULDBLOCK){// 代表底层连接获取完, 跳出循环即可break;}else if (errno == EINTR){// 代表accept被某个信号中断了, 重新accept即可continue;}else{LogMessage(ERROR, "errno: %d, errno message: %s", errno, strerror(errno));break;}}else{// 获取新连接成功, 需要做三件事情:// 0. 将这个套接字设置为非阻塞状态// 1. 用得到的套接字构造 Connection 对象// 2. 将该套接字添加到epoll模型中// 3. 将套接字和Connection对象 Load 到映射表中// 4. 设置地址信息// 这几件事情不就是AddFdConnectionToMap 吗?AddFdConnectionToMap(sock, std::bind(&TcpServer::Reader, this, std::placeholders::_1), \std::bind(&TcpServer::Writer, this, std::placeholders::_1), \std::bind(&TcpServer::Excepter, this, std::placeholders::_1), \clientip, clientport);LogMessage(DEBUG, "连接成功: %d", sock);}}
}3.6. 读事件
与连接事件一样,走到这里,说明是通过回调执行到这里的,因此,此时底层一定有数据就绪,等待服务器读取数据。
不过,在这之前,在强调一下,由于TCP是面向字节流的,因此,当服务器调用 read/recv 时,根本就无法保证获得的数据能否构成一个完整的报文,因此,是需要上层定制协议的,进行序列化和反序列化,解决粘包问题。
因此,服务器数据读取成功后,首先是需要将这部分数据保存起来,让上层进行验证 (通过设置的上层回调):
- 如果上层验证后,可以得到一个完整报文,服务器再将保存数据中的这部分数据移除掉;
- 如果上层验证后,没有完整报文,此时上层不会做任何处理,但不影响,因为这部分数据被服务器保存起来了,后续可以继续处理。
此外,服务器的工作模式是ET模式,因此必须要以轮询式读取数据,这个就不解释了。
最后,当服务器读取失败时,是需要根据 errno 做判断的:
- 如果 errno == EWOULDBLOCK 或者 errno == EAGAIN,代表底层数据读完了,跳出循环即可;
- 如果 errno == EINTR,代表此次读取数据被信号中断了,重新读即可;
- 如果是其他情况,那么代表是异常事件,执行这个Connection的异常回调,服务器返回即可。
当然,如果服务器读取返回0,那么代表对端关闭连接了,此时服务器也将这种情况按异常事件处理,执行这个Connection的异常回调;
代码如下:
// 读回调
void Reader(Connection* connection)
{// 当服务套接字的读事件就绪后, 代表底层有数据了// 上层可以读取, 并且要以非阻塞读取, 为什么呢?// 因为服务器是ET工作模式, 底层只会通知一次// 上层必须在一次处理过程中将数据全部拷贝到应用层, 因此, 必须以非阻塞轮询式读取while (true){char buffer[g_buffer_num] = { 0 };ssize_t real_size = read(connection->_sock, buffer, sizeof buffer - 1);if (real_size == -1){if (errno == EAGAIN || errno == EWOULDBLOCK){// 说明接收缓冲区的数据全部拷贝到应用层, 此次读取 donebreak;}else if (errno == EINTR){// 说明这次读取被某个信号中断了, 继续读即可continue;}else{// 真正的读取错误了// 采用统一的方式处理异常情况connection->_except_call_back(connection);LogMessage(ERROR, "errno: %d, errno message: %s", errno, strerror(errno));return;}}else if (real_size == 0){// 如果对端连接关闭// 将这种情况也认为是异常事件, 调用这个Connection的异常回调LogMessage(NORMAL, "client close the link");connection->_except_call_back(connection);break;}else{// 读取成功, 上面说了, 这部分读取的数据不能直接交付给上层业务// 而应该先放在这个连接对象Connection 中的接收缓冲区里buffer[real_size] = 0;connection->_inbuffer += buffer;}if (IsConnectionExist(connection->_sock)){// 上层回调// 用于判断此时的_inbuffer里面的数据能否构成一个完整报文// 如果可以, 再进行上层业务处理// 如果不可以, 啥也不做_OnUserCallBack(connection);}}
}3.7. 写事件
对于 select/poll/epoll 而言,写事件是经常就绪的,因为对于服务器而言, 发送缓冲区经常是有空间的,因此,如果服务器设置对 EPOLLOUT 的关心,那么所有的服务套接字的写事件每次都会就绪,导致 epoll 的 epoll_wait 频繁返回,这是不利的(比如浪费CPU资源),因此, 对于读事件EPOLLIN,默认设置关心,对于写事件 EPOLLOUT,服务器应该按需设置,不可以默认设置。
什么是按需设置呢? 就是如果发送缓冲区还有数据,就设置,没有就不设置;
因此,EPOLLOUT 是动态设置的。当服务器走到了这里,说明这个 conn 连接的发送缓冲区一定有数据,因此,直接发送。
又因为,这个服务器的工作模式是ET模式,因此也要轮询式的发送数据;直至将 outbuffer 的数据写完,或者服务器底层缓冲区没有能力在接受数据:
- 如果是前者,即发送缓冲区没数据了,那么此时就去掉这个Connection中对写事件 (EPOLLOUT) 的关心;
- 如果是后者,即发生缓冲区还有数据,那么对这个Connection设置对写事件 (EPOLLOUT) 的关心;
void Writer(Connection* conn)
{while (true){ssize_t real_size = send(conn->_sock, conn->_outbuffer.c_str(), conn->_outbuffer.size(), 0);if (real_size < 0){// 写入失败, 也要分析情况if (errno == EAGAIN || errno == EWOULDBLOCK){// 代表服务器底层的缓冲区已被写满, 暂时不能再写了break;}else if (errno == EINTR){// 此次send被信号中断, 重新写即可continue;}else{// 真正的写错了, 统一交给异常处理conn->_except_call_back(conn);return;}}else if (real_size == 0){break;}else{// send success// 将写入的这部分数据, 从outbuffer里面移除conn->_outbuffer.erase(0, real_size);if (conn->_outbuffer.empty()) break;}}// 跳出循环, 两种情况// 第一种发送缓冲区没数据了, 那么去掉对这个连接写事件的关心if (conn->_outbuffer.empty())SetReadAndWriteConcern(conn, true, false);// 如果outbuffer还有数据, 那么让这个套接字关心写事件// 下次epoll_wait时, 写事件就绪, 自动调用WriterelseSetReadAndWriteConcern(conn, true, true);
}void SetReadAndWriteConcern(Connection* conn, bool ReadEvent, bool WriteEvent)
{uint32_t events = 0;// 无论如何, 都是ET工作模式events |= EPOLLET;ReadEvent == true ? (events |= EPOLLIN) : events |= 0;WriteEvent == true ? (events |= EPOLLOUT) : events |= 0;_epoll.ModIoEvent_EPoll(conn->_sock, events);
}3.8. 异常事件
对于异常事件,我们进行统一处理,因为服务器要关闭这个连接了。
实现如下:
void Excepter(Connection* conn)
{// 走到这里, 说明这个连接出现异常事件了// 但服务器不需要判别是什么原因// 因为服务器要关闭这个连接了int sock = conn->_sock;// 关闭连接分四个过程// step 1: 将这个连接中的套接字从epoll模型中删除_epoll.DelIoEvnet_Epoll(conn->_sock);// step 2: 将连接中的套接字closeclose(conn->_sock);// step 3: 将套接字和conn构成的节点从映射表中移除_Fd_Connection_Map.erase(sock);LogMessage(DEBUG, "the sock %d closed", sock);// step 4: 释放这个节点delete conn;
}4. 服务器上层的处理
当服务器读 (read / recv) 到数据后,服务器首先需要将数据保存起来,然后,调用上层回调,让上层自己根据协议判断,这些数据是否能够构成一个完整报文,如果可以,上层接下来就可以处理业务逻辑;如果不可以,上层直接返回,不做任何业务逻辑处理。
大致过程如图所示:
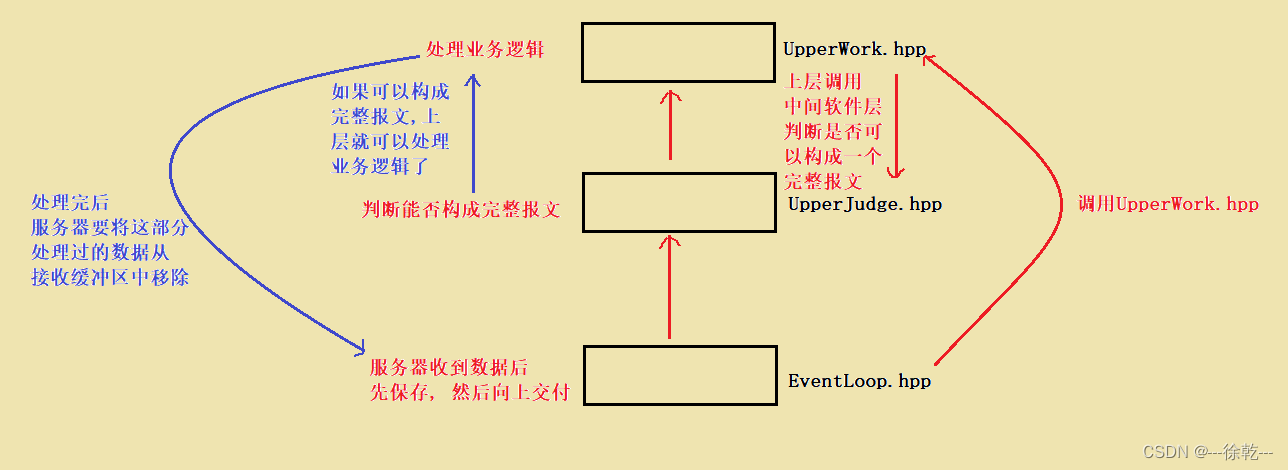
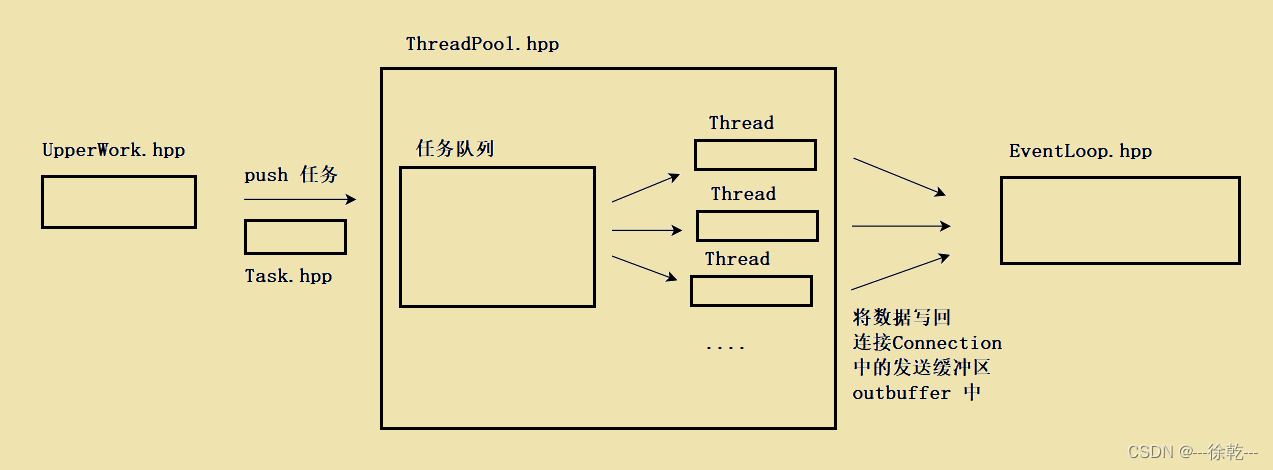
当上层获得了若干个完整报文后,它就会自动将这些完整报文构成一个一个的任务,并将这些任务 push 进线程池中的任务队列中,线程池中的线程会自动处理这个任务,并将任务结果构成一个响应,并对其进行序列化,然后,将序列化后的数据push进这个连接中的发送缓冲区中 (outbuffer),此时上层业务逻辑就完成了。
大致过程如图所示:
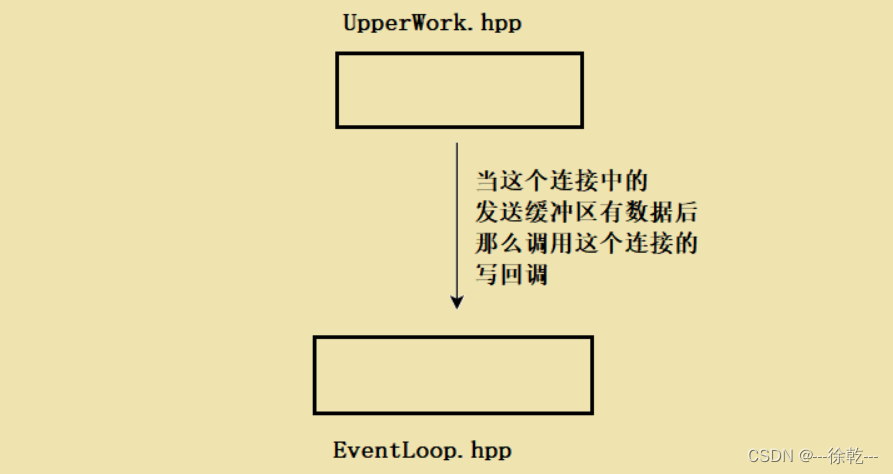
当服务器中的发送缓冲区数据就绪,此时,上层业务可以直接通过Connection对象中的写回调,向服务器的对端发送数据,因为此时服务器中的发送缓冲区有数据。
在调用写回调过程中,服务器是需要根据写的结果来判定这个套接字后续是否还要关心写事件,如果这个连接的发送缓冲区还有数据,那么这个套接字应该要关心写事件,如果没有数据了,那么去掉对这个套接字的写事件的关心。
大致过程如下:
上述过程就是上层处理的全部过程。
至于其中的具体细节,包括,序列化和反序列化、分割报文、任务的封装、线程的封装、线程池的封装、锁的封装等等工作,如果有兴趣,可以看下代码,当然,你也可以自己实现,对于上层的实现并不是固定的,我们的重心并不是上层如何处理的,而是理解 Reactor 模式服务器的具体思路和过程。
5. Reactor 总结
总结: Reactor服务器是一种常见的网络服务器架构,通常用于处理大量并发连接和请求。其核心思路就在于 Reactor 将事件的产生和处理进行分离,它包含如下模块 :
- 事件轮询:Reactor服务器采用了事件驱动的架构模式,其中包括一个主事件循环(Event Loop),负责监听和派发事件;
- 多路复用:Reactor服务器通常使用多路复用技术来监听多个I/O通道的事件。这样可以在单进程中同时处理多个连接,提高服务器的性能和吞吐量;
- 事件处理器:Reactor服务器通过事件处理器来处理不同类型的事件。每个事件处理器通常负责特定类型的事件,例如获取连接、读取数据、发送数据、异常事件等。通过将事件处理器分离开来,可以使服务器代码更易于管理和扩展;
- ET 工作模式:为了提高服务器的性能,Reactor 服务器一般采用 ET 工作模式,即所有的套接字的工作模式是非阻塞的。因为ET模式会减少IO的次数,提高效率,且ET模式会要求一次处理过程将数据全部读取,因此可以给对端发送一个更大的窗口大小,因此,对端就有可能存在更大的滑动窗口,发送的数据就更多,进而提高网络吞吐量。
总的来说,Reactor 服务器是一种高效的并发服务器架构,通过事件轮询、多路复用、事件处理器、ET工作模式等技术,能够有效地处理大规模并发请求,适用于许多网络应用的场景。