-
首先,代码导入了两个库:
requests和parsel。这些库用于处理HTTP请求和解析HTML内容。 -
然后,它定义了一个变量
url,指向网站’樱花2024年4月日历风景桌面壁纸_高清2024年4月日历壁纸_彼岸桌面’。 -
接下来,设置了一个HTTP请求的头部信息,模拟了一个Chrome浏览器的请求。
-
通过
requests.get()方法,发送一个GET请求到指定的URL,并将响应内容保存在response变量中。 -
使用
response.apparent_encoding来设置响应的编码方式。 -
创建一个
parsel.Selector对象,用于解析HTML内容。 -
从HTML中选择所有
<li>元素,这些元素包含了图片的信息。 -
遍历每个
<li>
元素:
-
提取
<b>标签内的文本作为图片的标题。 -
如果存在标题,提取
<img>标签的src属性,即图片的URL。 -
使用
requests.get()方法获取图片的内容。 -
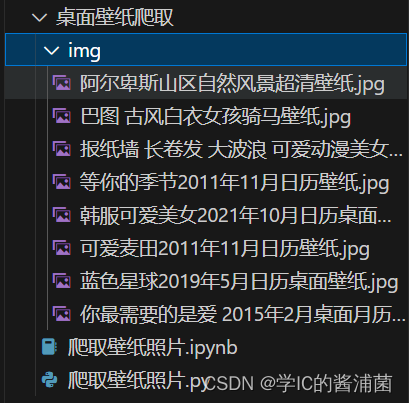
将图片内容写入到以标题命名的文件中(保存在
img文件夹下)。 -
打印图片的URL和标题。
-
-
最后,输出一条消息表示下载完成。
完整代码如下:
#http://www.netbian.com/desk/33413.htm
import requests
import parsel
url = 'http://www.netbian.com/desk/33413.htm'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
response.encoding = response.apparent_encoding
selector = parsel.Selector(response.text)
lis = selector.css('.list li')
print('====================')
print('开始下载:')
for li in lis:title = li.css('b::text').get()if title:li_url = li.css('img::attr(src)').get()img_content = requests.get(url = li_url).contentwith open('img\\' + title + '.jpg', mode = 'wb') as f:f.write(img_content)print(li_url, title)
print('下载完成!')
print('====================')运行效果如下:



![[Algorithm][链表][两数相加][两两交换链表中的节点][重排链表][合并K个升序链表][K个一组翻转链表] + 链表原理 详细讲解](https://img-blog.csdnimg.cn/direct/be48d7e25fb04aaba0863d1b0abda4b5.png)