1.sql优化-子查询改为外连接
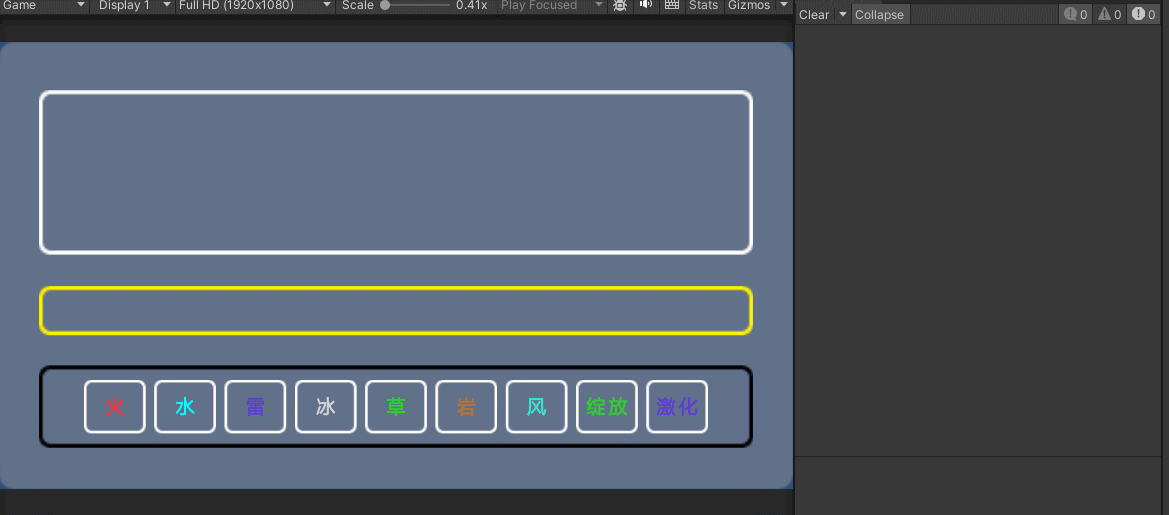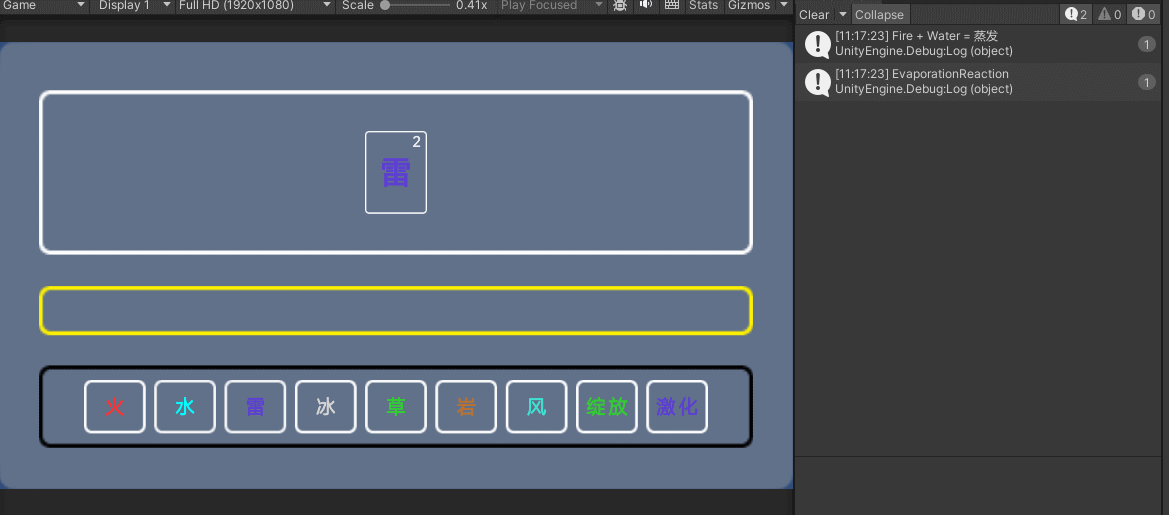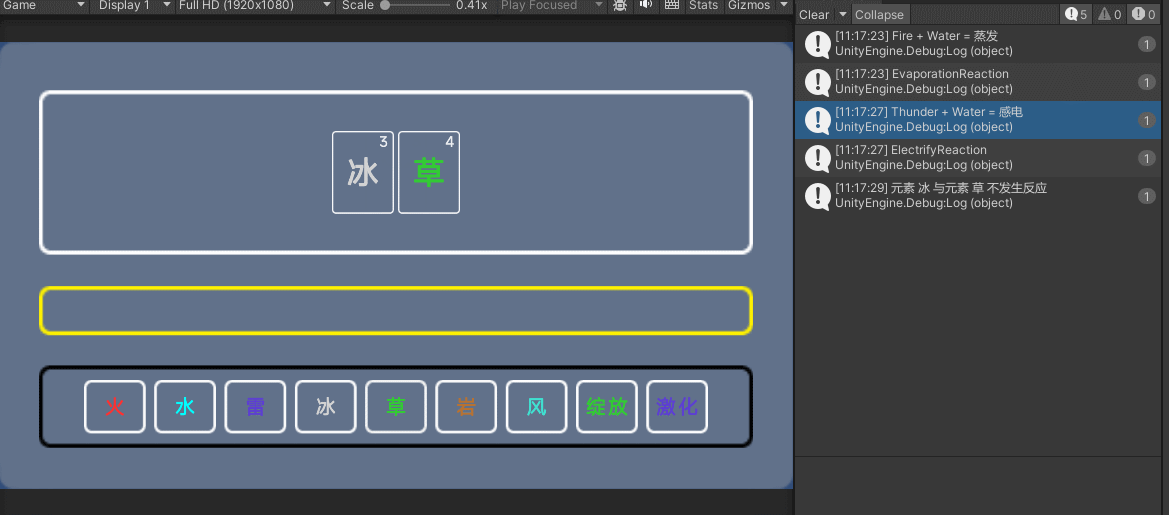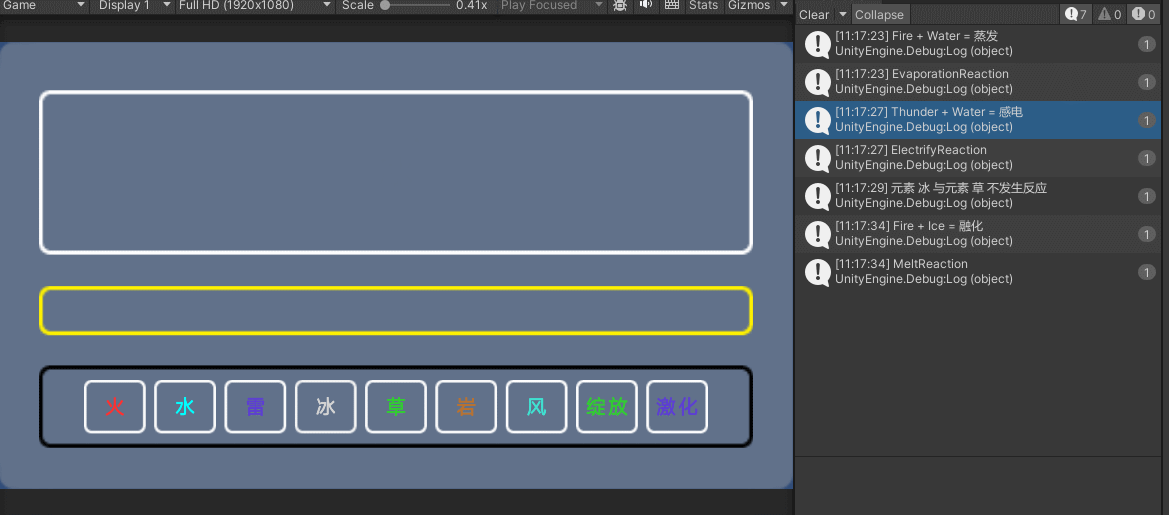
1.改之前
改之前是这样,那针对查出来的每一条数据,都要执行一次箭头所指的函数

执行的sql很慢
![]()
2.改之后
改之后是这样,整体做外连接,不用每一条都再执行一次查询

执行时间缩短了好几倍
![]()
2.Mybatis中不要有太多空行
正常人的操作肯定是sql在工具里执行没问题了,再粘贴到Mybatis中
但是有个奇怪的现象,mybatis一执行就报错,就算我把控制台打印的sql沾到工具里边执行也没问题
Caused by: java.util.concurrent.ExecutionException: net.sf.jsqlparser.parser.ParseException:
Encountered unexpected token: "AND" "and"at line 8, column 1.Was expecting:<EOF>然后把Mybatis中的空行删除之后,就好了
正常情况下 <if>标签是会去掉第一个and
个人觉得是因为接下来的<if>因为前边有空行,没办法识别and是否需要去掉

3.FIND_IN_SET函数
FIND_IN_SET( #{item}, a.sourceDatabaseName) > 0
FIND_IN_SET('子串','母串'),母串是逗号分割的,如果>0,说明子串是逗号分割后其中的一个元素
比如

子串是母串其中一个元素时候才返回true 如果子串是1,母串是11,就返回false了

母串和子串相等时候也返回true

4.GROUP_CONCAT(字段 SEPARATOR 分隔符 )函数
这个1中介绍过了,可以和group by一起用,也可以作为子查询时候使用
适用于把多个结果用符号分割拼一起
4.1子查询时候使用
select devInstance.inst_id as id,(SELECT GROUP_CONCAT(dbInput.source_database_name SEPARATOR ';') namefrom sys_data_develop_db_input dbInputwhere dbInput.task_id = devInstance.task_id) source
from sys_data_develop_instance devInstance
出来得结果就是
1 a;b;c
2 a;c;d
4.2.和group by一起使用
SELECT dbInput.task_id,GROUP_CONCAT(dbInput.source_database_name SEPARATOR ',') databaseName,GROUP_CONCAT(dbInput.source_table_name SEPARATOR ',') tableName
from sys_data_develop_db_input dbInput
group by dbInput.task_id5.pom.xml中得option

6. Mybatis传入了Map<Integer,List<String>>
/*** key是类型,value是该类型对应的id,不同表中id类型不同所以统一用string接收* */Map<Integer,List<String>> taskIdMap;mybatis,循环key时候用 OR 隔开
<if test="queryParams.taskIdMap != null and queryParams.taskIdMap.size()>0">and<foreach item="list" index="key" collection="queryParams.taskIdMap" open="(" separator=" OR " close=")">(a.taskType = #{key}and a.id in<foreach item="item" collection="list" open="(" separator="," close=")">#{item}</foreach>)</foreach></if>执行时控制台打印
AND ((a.taskType = ? AND a.taskId IN (?, ?)) OR(a.taskType = ? AND a.taskId IN (?)))7.Mybatis缓存
7.1一级缓存

一级缓存的作用域是同一个SqlSession,在同一个sqlSession中两次执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。当一个sqlSession结束后该sqlSession中的一级缓存也就不存在了。
Mybatis默认开启一级缓存。
一级缓存是SqlSession级别的缓存。在操作数据库时需要构造 sqlSession对象,在对象中有一个(内存区域)数据结构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。

7.2二级缓存
二级缓存是多个SqlSession共享的,其作用域是mapper的同一个namespace,
不同的sqlSession两次执行相同namespace下的sql语句且向sql中传递参数也相同即最终执行相同的sql语句,
第一次执行完毕会将数据库中查询的数据写到缓存(内存),
第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。
Mybatis默认没有开启二级缓存需要在setting全局参数中配置开启二级缓存。

二级缓存:根据命名namespace、查询语句方法名及查询参数等拼接的一个缓存key,value值是第一次从数据库查询出来的结果
但是避免使用二级缓存
会有脏数据存在。因为同一个namespace下发生删改查才会清缓存,但是别人的namespace下对这个表有修改 是不会删缓存的 所以往下执行的之后还是旧数据
8.同步异步 阻塞非阻塞
阻塞 非阻塞 指的是线程的状态


9.同样的sql在不同环境下,执行时间差异很大
数据量的问题
dev比test多了190万数据,把没用的数据删除了就好了
10.垃圾回收与资源利用
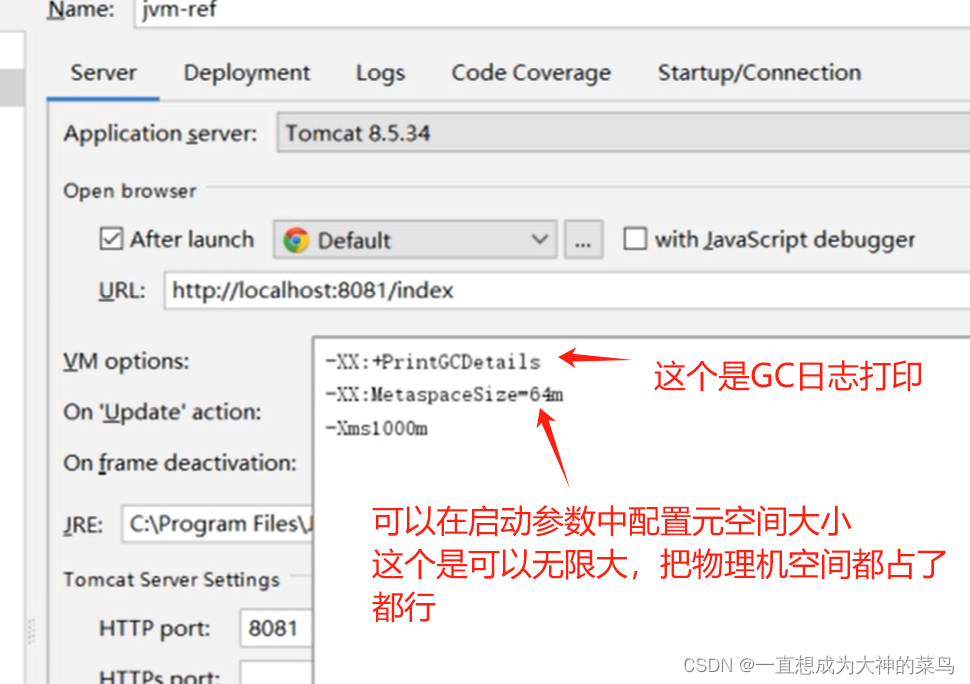
空间不够会GC,GC要stop the world,所以尽量减少GC
垃圾回收--堆
逃逸分析--栈
所以在栈中不断new 对象 可以避免垃圾回收



池化:数据库连接池,线程池

11.MapStruct把两个实体映射到同一个实体上
后端来源的表不同,对应的实体也不同。但是返回给前端的时候是几个表一起返回
这时候就涉及到多个实体去映射到一个实体上

12.Springboot内置的tomcat
在start下有tomcat

13.集群和微服务
集群和分布式概念不同
集群,每个服务器做的事情相同
分布式,每个子节点做的事情不同
分布式和集群可以整合
比如现在每个微服务都是多实例,每个微服务在整体业务系统中只负责自己一块的业务,这些个集群整合在一起才是一个完整的业务系统

14.发令枪
await() 方法是用来阻塞线程的,等待倒计锁被减到0的时候,才会唤醒该方法继续执行。也可以设置等待超时时间

15.Redis
1.IO多路复用

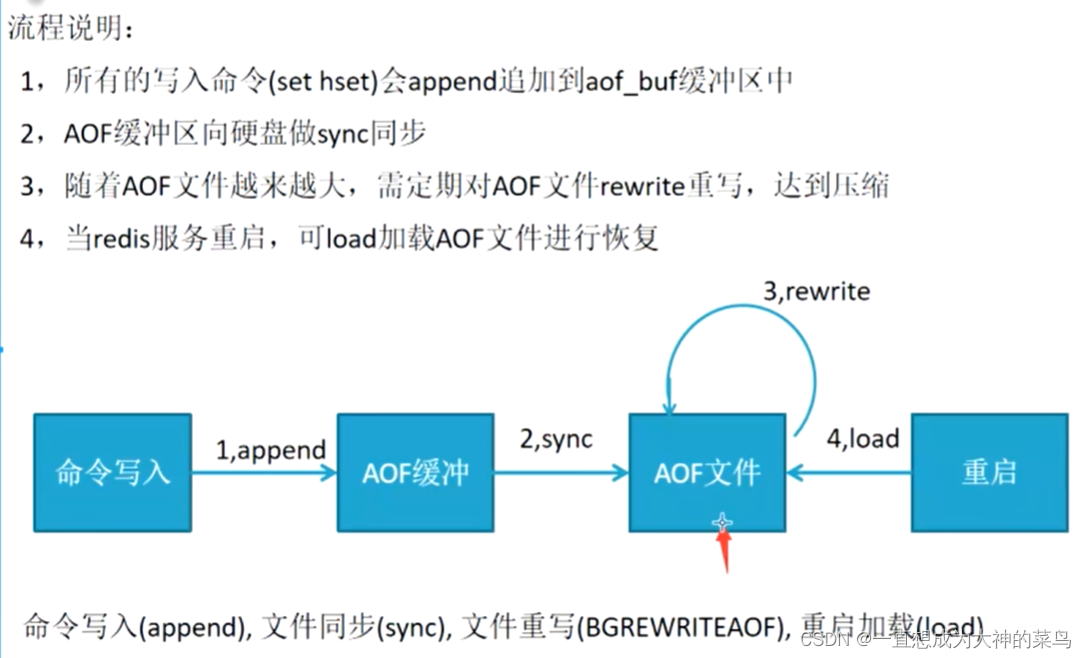
 2.备份
2.备份



3.生活中使用的Redis
1.redis计数
阅读量,访问量



2.购物车列表
那些图片可以写个接口异步加载,其他信息可以直接从redis取


3.公众号,最新发布的消息放在最前边
用redis命令实现,类似栈,先进先出

4.朋友圈点赞

4.慢查询


5.主从
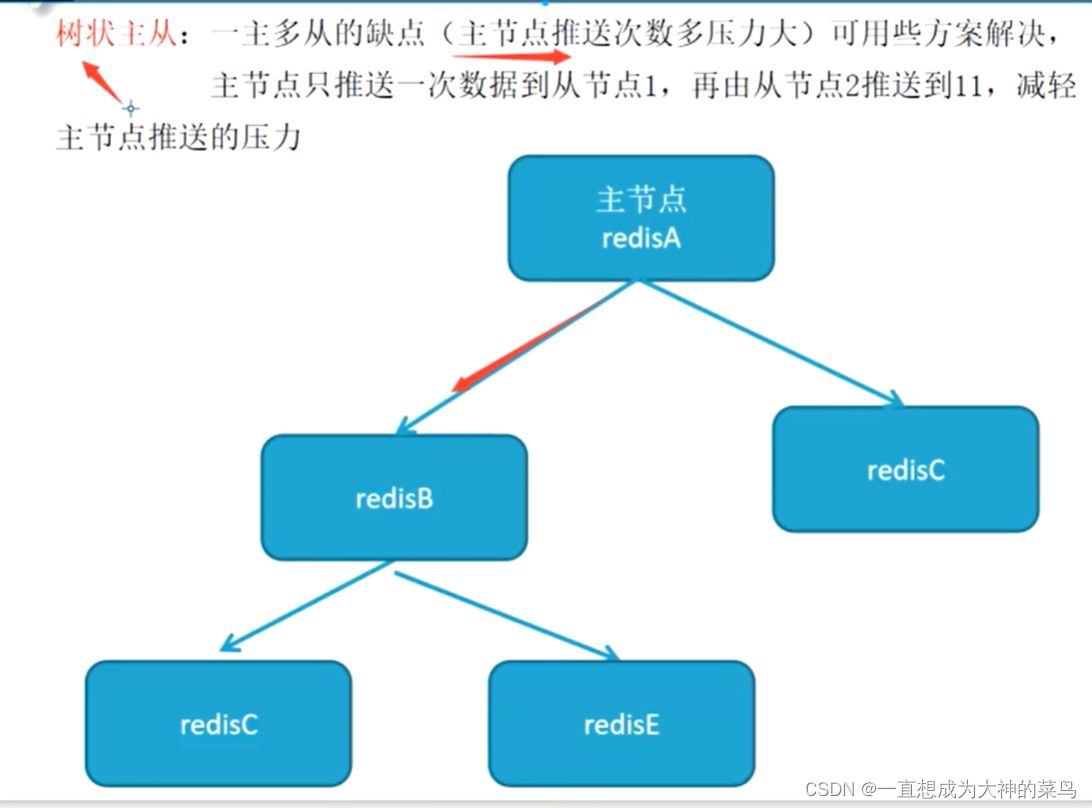




哨兵模式 先搭主从 再搭哨兵



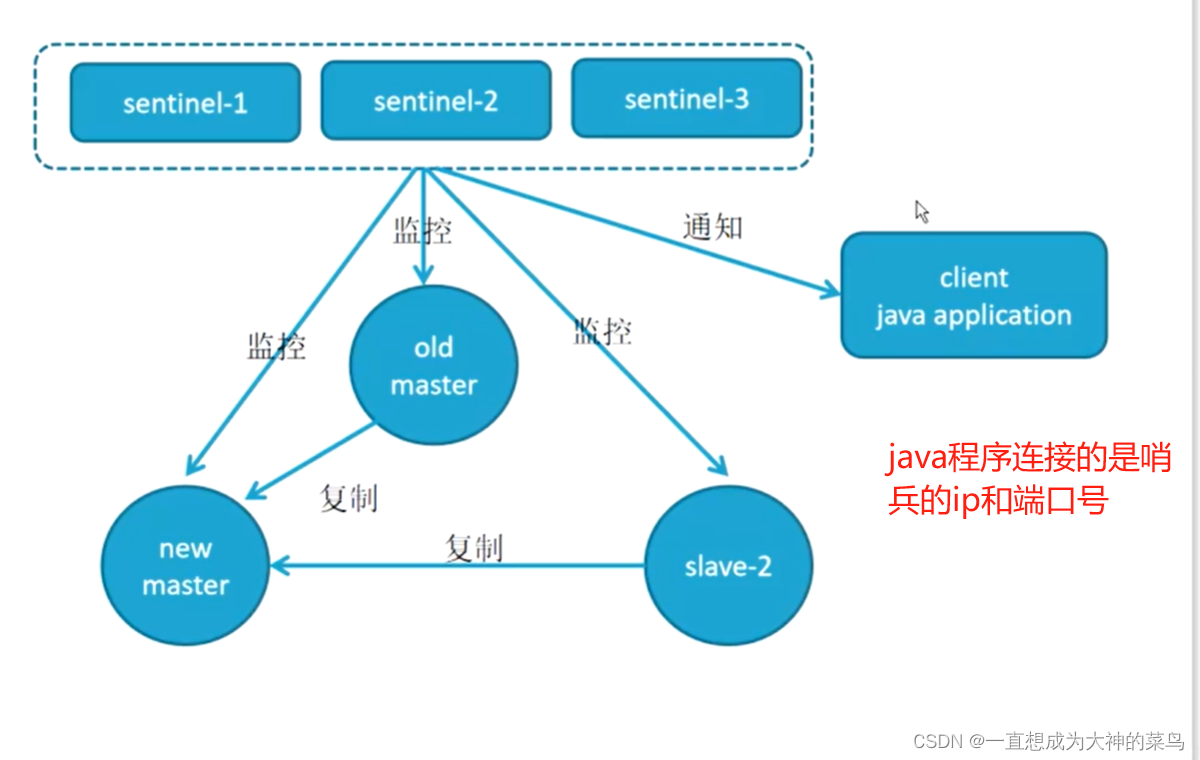
6.redis集群


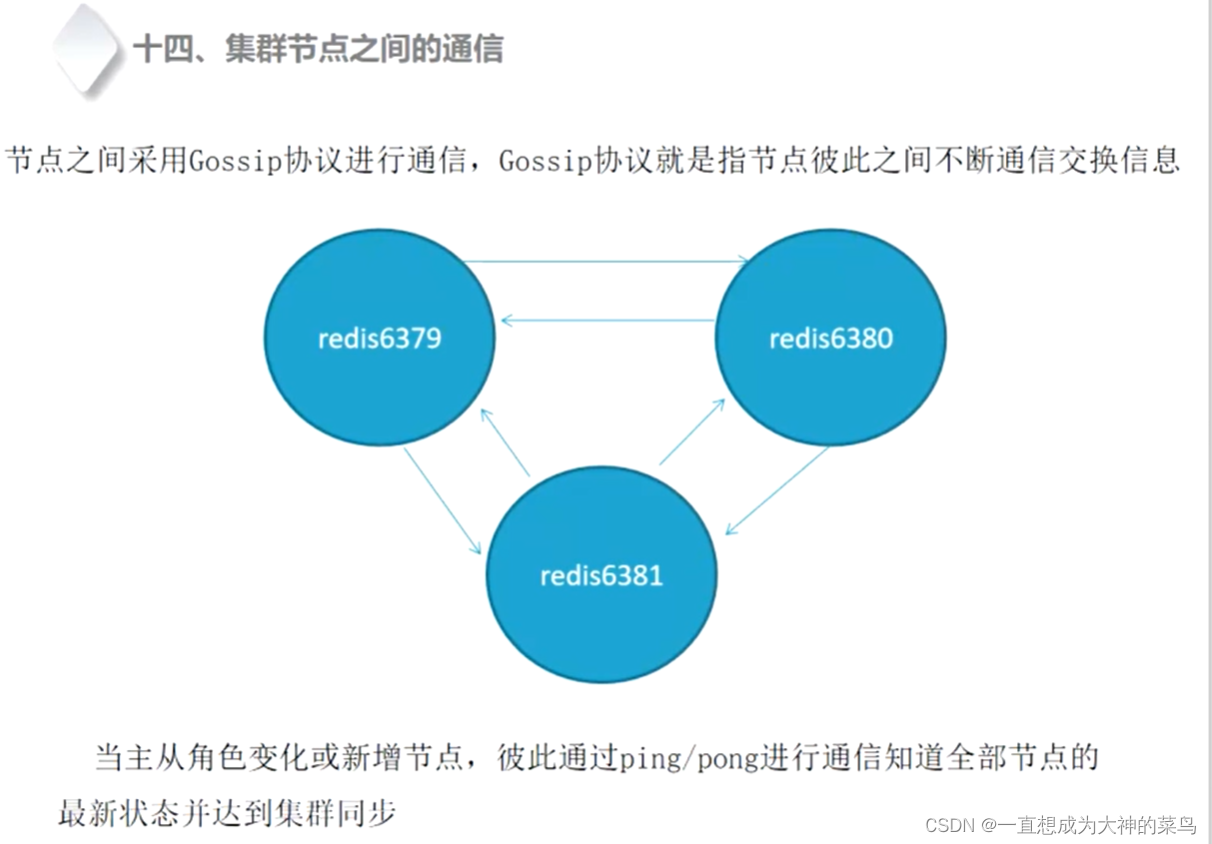

扩容之后需要重新分配槽点,以及转移 数据

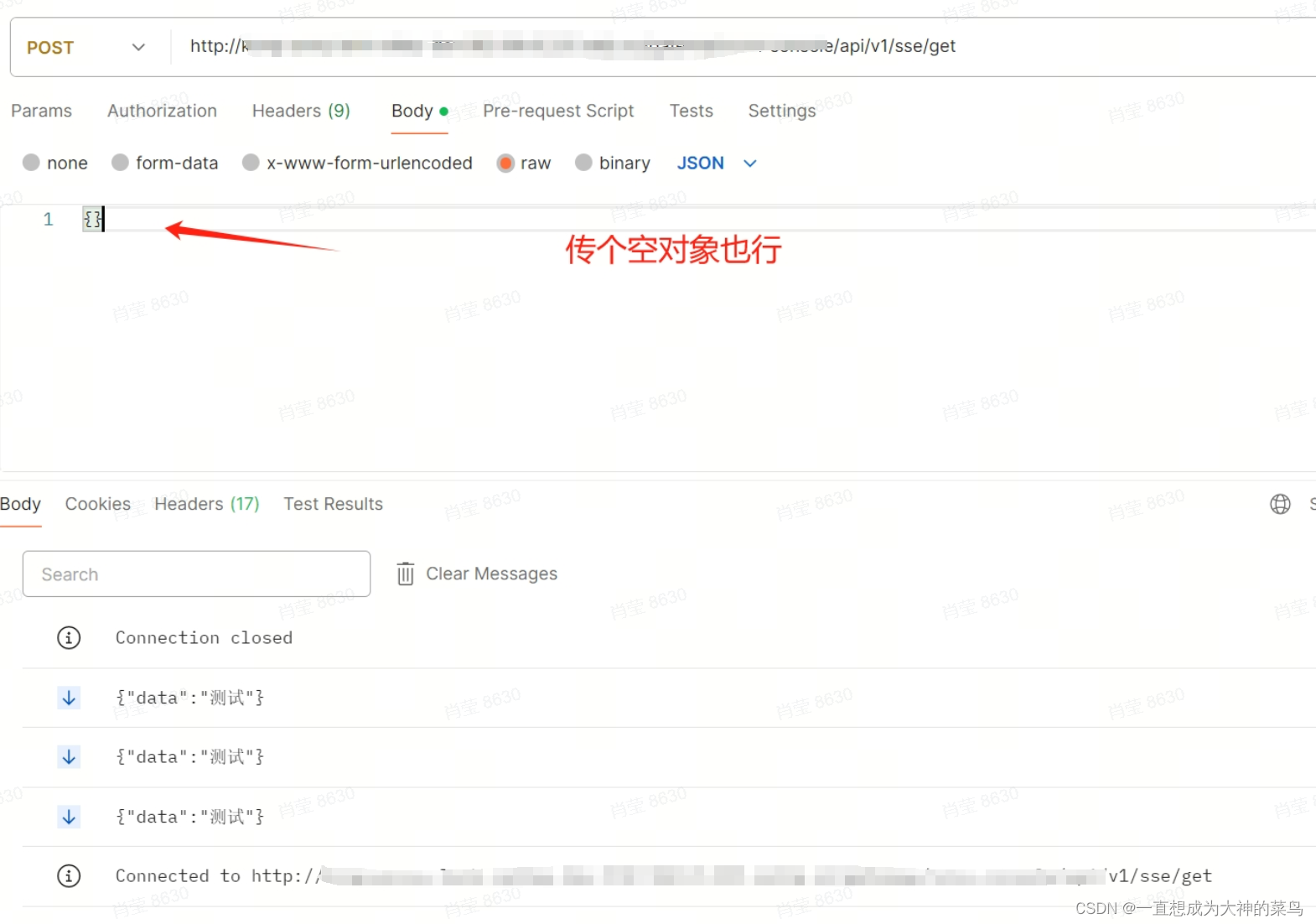
16.SSE
sse(Server Sent Event),直译为服务器发送事件,顾名思义,也就是客户端可以获取到服务器发送的事件
如果前端给后端发送一次消息后就不再发送消息,可以用SSE
比如我们项目的应用场景,前端把数据提交给后端之后,前端在页面上等待后端的返回信息
后端会持续不断的返回,每一种情况的校验结果
下面是我写的DEMO,分三种情况
全都测试过的,建议第二种第三种更好
@Api(tags = "sse测试")
@RestController
@RequestMapping("/api/v1/sse")
@RequiredArgsConstructor
@Slf4j
public class SSEController {private final SysDataCollectionOfflineTaskService service;/*** 测试通过的* @param response* @param collectionOfflineTaskForm*/@PostMapping(value = "/get")public void push(HttpServletResponse response, @RequestBody CollectionOfflineTaskForm collectionOfflineTaskForm) {//接收前端传来得参数String id = collectionOfflineTaskForm.getId();log.info(id);response.setContentType("text/event-stream");response.setCharacterEncoding("utf-8");PrintWriter pw = null;try {for (int i = 0; i < 3; i++) {Thread.sleep(1000);pw = response.getWriter();//todo 这里result是模拟业务逻辑处理得返回值Result<String> result = Result.success("测试");String json = JSONObject.toJSONString(result);//注意返回数据必须以data:开头,"\n\n"结尾//postman能看到返回的只有json数据 并没有前边得"data:"和后边的"\n\n"pw.write("data:" + json + "\n\n");pw.flush();//检测异常时断开连接if (pw.checkError()) {log.error("客户端断开连接");pw.close();return;}}} catch (Exception e) {//e.printStackTrace();log.error(e.getMessage());} finally {if (Objects.nonNull(pw)) {pw.close();}}}/*** 测试通过的* 返回类型必须SseEmitter* @param collectionOfflineTaskForm* @return*/@PostMapping("/events")public SseEmitter handleEvents(@RequestBody CollectionOfflineTaskForm collectionOfflineTaskForm) {//接收前端传来得参数String id = collectionOfflineTaskForm.getId();log.info(id);SseEmitter emitter = new SseEmitter();Result<String> result = Result.success("测试");//需要开启新线程 在一个新的线程中发送事件数据。这样可以确保主线程不会被阻塞,同时能够实现实时的事件流向客户端。new Thread(() -> {try {for (int i = 0; i < 3; i++) {emitter.send(SseEmitter.event().data(result));Thread.sleep(1000);}emitter.complete();} catch (IOException | InterruptedException e) {emitter.completeWithError(e);}}).start();return emitter;}/*** 测试通过* @Async异步* @param collectionOfflineTaskForm* @return*/@PostMapping("/test")public SseEmitter test(@RequestBody CollectionOfflineTaskForm collectionOfflineTaskForm) {//接收前端传来得参数String id = collectionOfflineTaskForm.getId();log.info(id);//需要开启新线程 在一个新的线程中发送事件数据。这样可以确保主线程不会被阻塞,同时能够实现实时的事件流向客户端。SseEmitter emitter = new SseEmitter();service.sseTest(emitter);return emitter;}
} @Override@Asyncpublic void sseTest(SseEmitter emitter) {Result<String> result = Result.success("测试");//需要开启新线程 在一个新的线程中发送事件数据。这样可以确保主线程不会被阻塞,同时能够实现实时的事件流向客户端。//new Thread(() -> {try {for (int i = 0; i < 3; i++) {emitter.send(SseEmitter.event().data(result));Thread.sleep(1000);}emitter.complete();} catch (IOException | InterruptedException e) {emitter.completeWithError(e);}//}).start();}postman测试结果如图