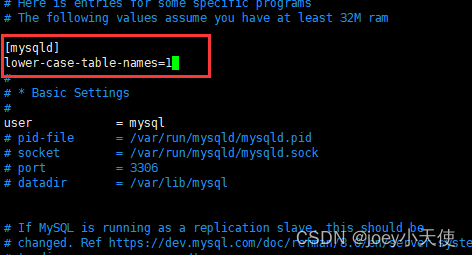
mysql优化 和 mysql优化之索引 两篇文章有大量的实验性的内容,我暂时没时间理解,把八股部分总结到这篇文章中,方便记忆
我们为什么要对sql进行优化
我们开发项目上线初期,由于业务数据量相对较少,一些SQL的执行效率对程序运行效率的影响不太明显,而开发和运维人员也无法判断SQL对程序的运行效率有多大,故很少针对SQL进行专门的优化;
而随着时间的积累,业务数据量的增多,SQL的执行效率对程序的运行效率的影响逐渐增大,此时对SQL的优化就很有必要。
sql性能下降原因
- 查询语句写的烂
- 索引(单值索引、复合索引)失效
- 关联查询太多join(设计缺陷或不得已的需求)
数据库优化
读写分离
大型网站会有大量的并发访问,如果还是传统的数据结构,或者只是单单靠一台服务器扛,如此多的数据库连接操作,数据库必然会崩溃,数据丢失的话,后果更是不堪设想。这时候,我们需要考虑如何减少数据库的联接。
我们发现一般情况对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大,这样分析可以采用数据库集群的方案。其中一个是主库,负责写入数据,我们称为写库;其它都是从库,负责读取数据,我们称为读库。这样可以缓解一台服务器的访问压力
从库监听主库的二进制日志(保存着mysql中所有的写操作),主库发生改变,从库会执行一遍二进制日志。

数据库集群
如果访问量非常大,虽然使用读写分离能够缓解压力,但是一旦写操作一台服务器都不能承受了,这个时候我们就需要考虑使用多台服务器实现写操作。
例如可以使用MyCat搭建MySql集群,对ID求3的余数,这样可以把数据分别存放到3台不同的服务器上,由MyCat负责维护集群节点的使用。
数据库表的优化
表拆分
表结构越大,查询效率越低。
- 将表垂直拆分,拆分的是表结构。
- 将表水平拆分,拆分的是表的数据量。

其他
-
为列选择合适的数据类型(尽量选择占据空间小的数据类型)
-
在varchar和char中选择时,应尽量选择char,定长字段查询比可变长度字段快,简言之就是空间换时间
同时VARCHAR的长度只分配真正需要的空间 -
能用TINYINT就不用SMALLINT,能用SMALLINT就不用INT,磁盘和内存消耗越小越好
-
尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
-
-
在可以确定只存在一个查询结果或者判断库中有无符合条件数据时,时间
limit 1来限定查询结果,limit 1会在查询到一条信息后停止查询返回结果,而不是继续往后查询下一条符合条件的数据,既使用select 1 from table where condition limit 1,来代替select count -
尽量将表字段定义为NOT NULL约束,这时由于在MySQL中含有空值的列很难进行查询优化,NULL值会使索引以及索引的统计信息变得很复杂。
-
单表不要有太多字段,建议在20以内
-
在合适的场景使用反范式。
-
mysql分区(todo 这个不明白,有机会再说)
使用分区是大数据处理后的产物。比如系统用户的注册推广等等,会产生海量的日志,当然也可以按照时间水平拆分,建立多张表。但在实际操作中,容易发生忘记切换表导致数据错误。
分区适用于例如日志记录,查询少。一般用于后台的数据报表分析。对于这些数据汇总需求,需要很多日志表去做数据聚合,我们能够容忍1s到2s的延迟,只要数据准确能够满足需求就可以。MySQL主要支持4种模式的分区:range分区、list预定义列表分区,hash 分区,key键值分区
数据库优化面试题
执行数据库查询时,如果要查询的数据有很多,假设有1000万条,用什么办法可以提高查询速率?


- 数据库设计
- 建立索引
- 分区(MySQL,比如按时间分区)
- 使用合适的字段,例如将varchar换成char
- 多表关联查询设置冗余字段
- 在SQL语句方面:
- 优化SQL语句,减少比较次数;
- 使用limit进行分页查询
- 其他
- 使用缓存
- 读写分离,主备集群
- 尽量一条sql获取所需要的数据,在后端进行数据的操作。
- 读写分离,主备集群
什么是分库分表?什么时候进行分库分表?有没有配合es使用经验?
这块儿暂时先不看,因为微服务本身就是分库分表的,在这儿想表达的意思是在微服务已经分库分表的情况下,在各微服务继续分库分表么?等有时间再来看这个
这里暂时只做一个简短的介绍,并没有深入,没时间
分库分表的代价是很高的,如果没有在项目中有深刻的体会的话,尽可能和面试官先说,数据量比较大的话可以先尝试一下其他的方案去存储、优化查询,尽量先不去做分库分表的操作。
分库分表的操作意味着性能的急剧下降和后续sql执行的复杂度会直线上升。
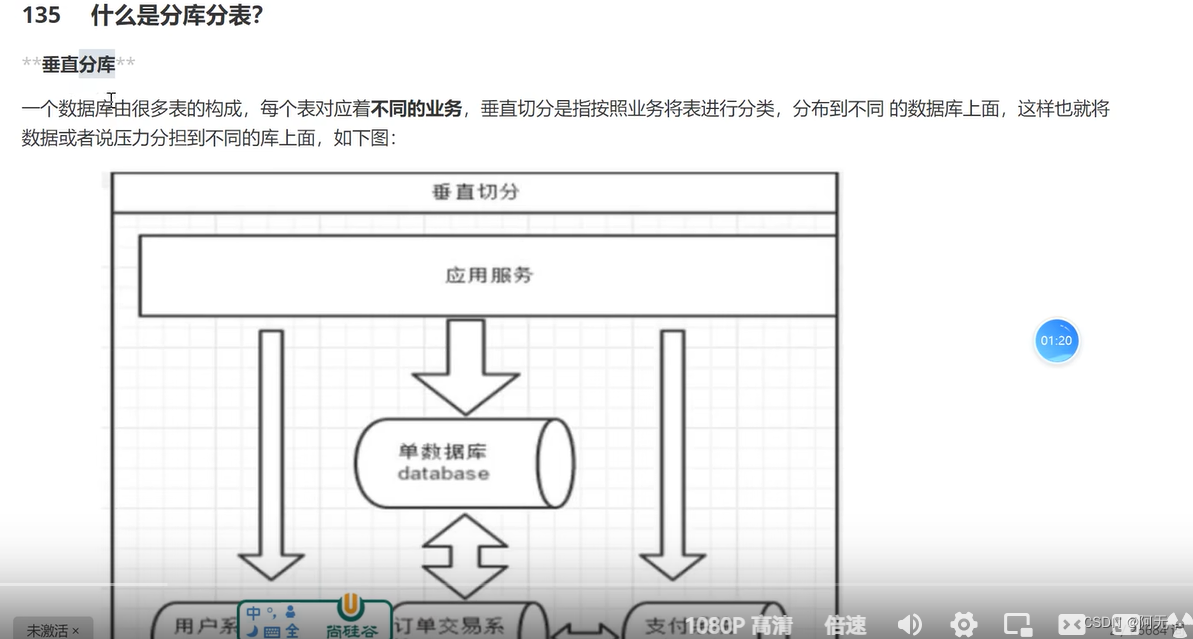
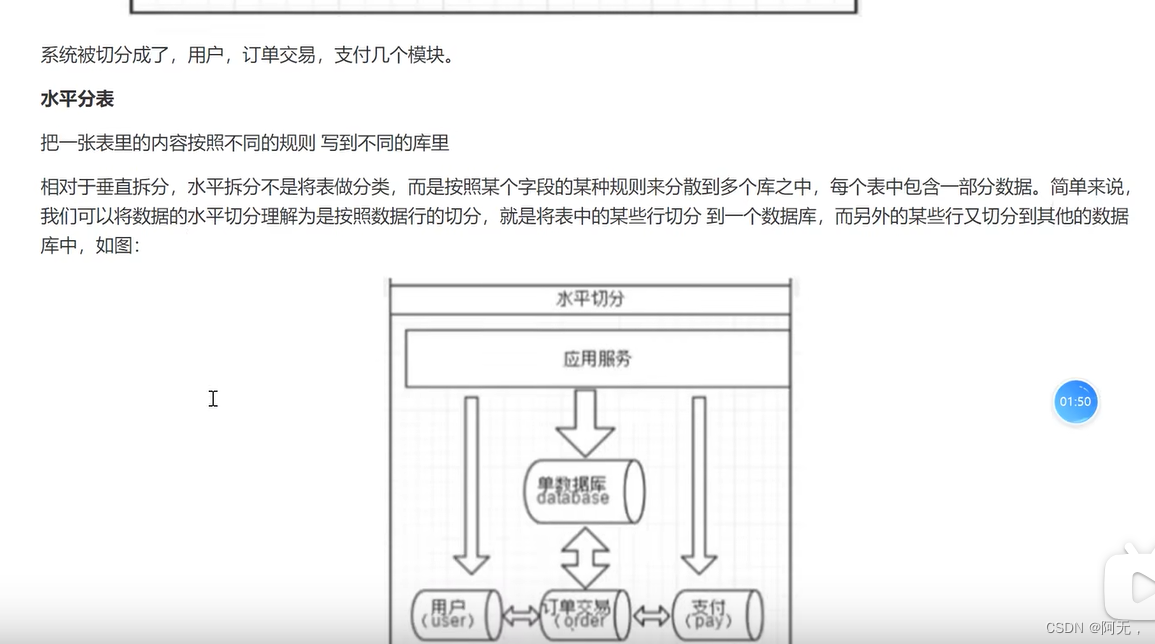

索引优化
索引官方定义:索引是帮助mysql高效获取数据的数据结构。
索引的目的在于提高查询效率
可以简单理解为:排好序的快速查找的数据结构
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这种数据结构以某种方式(引用)指向数据。
这样就可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引。
例如将id加索引,在mysql数据库里开辟一块存储空间来存放索引数据,查询的时候如果根据id去查询,就要走这个索引库,在索引库找到之后,就能定位这条数据,因为索引库的每一项和数据库的物理地址是绑定的,你能找到这条索引,就能找到这条数据所对应的物理地址,就可以直接获取这条数据。
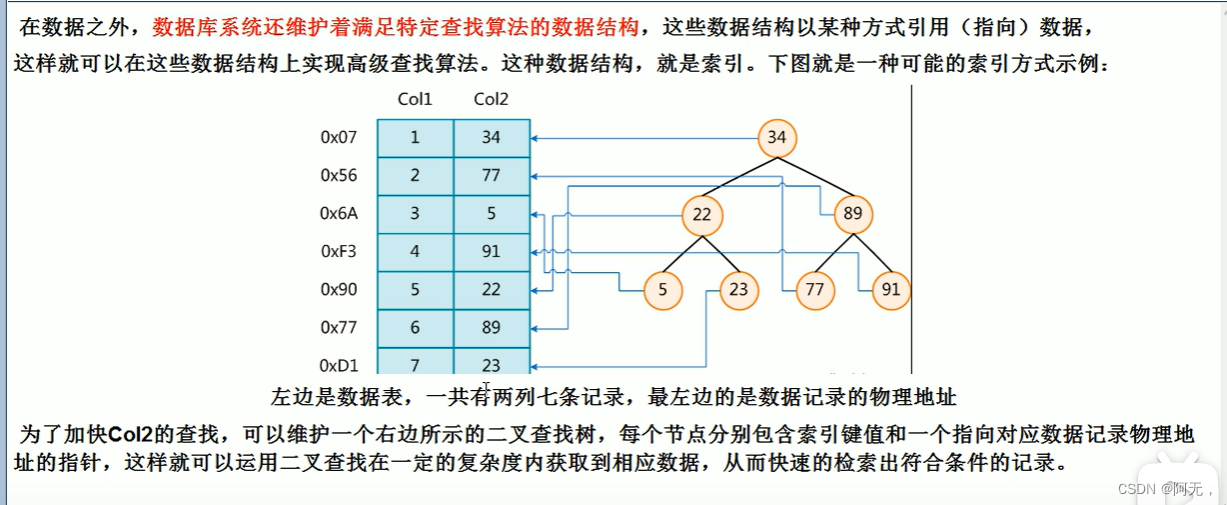
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。
索引结构
我们平常所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不一定是二叉的)结构组织的索引。
其中聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引。
当然,除了B+树这种类型的索引外,还有哈希索引等。
BTree索引、hash索引、full-text全文索引、R-Tree索引,我们只关注BTree索引
B+Tree(B+)索引检索原理(mysql默认的索引结构)
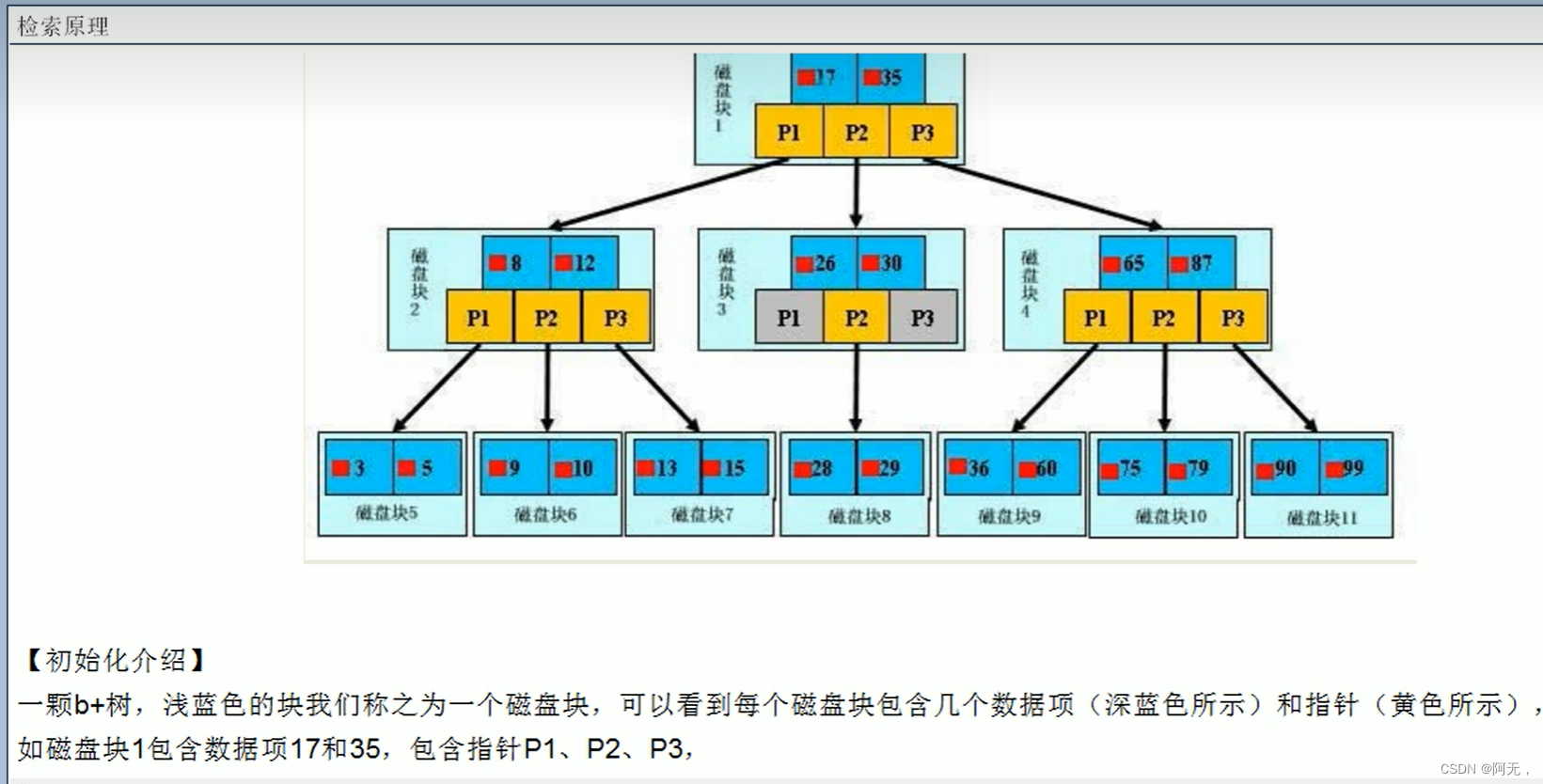

索引的优缺点
- 优点
- 提高数据检索的效率,降低数据库的io成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低了cpu的消耗
- 缺点
- 实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的
索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。 - 虽然索引大大提高了查询速度,却会降低更新表的速度,如对表进行增删改。
因为更新表时,mysql不仅要保存数据,还要更新添加了索引列的字段,也会调整因为更新所带来的键值变化后的索引信息
什么时候需要/不需要创建索引?
需要创建索引
- 频繁作为查询条件的字段应该创建索引
- 查询中排序、统计、分组的字段
- 查询中与其他表关联的字段,外键关系建立的字段
不需要创建索引
- 表记录太少
- 更新非常频繁的字段不适合创建索引
除了更新数据本身外还需要更新BTree树,数据量大的话是很耗费资源的。 - Where,分组,排序里用不到的字段不创建索引
- 唯一性太差(字段好多都是同一个值)(在查询的时候会索引失效)的字段不适合单独(可以使用联合索引)创建索引,即使频繁作为查询条件;
索引能够极大的提高数据检索效率,也能够改善排序分组操作的性能,但是我们不能忽略的一个问题就是索引是完全独立于基础数据之外的一部分数据,更新数据会带来的IO量和调整索引所致的计算量的资源消耗。
避免索引失效
索引失效导致的结果就是全表扫描
- 遵守最左匹配原则
如果是复合索引(索引了多列),就要遵守最左匹配原则,
指的是查询从索引的最左列开始并且不跳过中间索引中的列
如果跳过了,最左边的列依然会走索引,右边的列就不会走索引了 - 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
- 在使用!=或者<>无法使用索引会导致全表扫描,可以使用union all
- is null 和 is not null 也无法使用索引,可以设置default值,避免null值
- like以通配符开头 例如%abc ,索引失效导致全表扫描
如果在实际业务中必须把%放在前面,我们可以使用覆盖索引
使用覆盖索引查询时,只查询覆盖索引中的一个字段或全部,都会用到索引 - 少用or,会引起索引失效
少用 in 和 not in,因为in 实际上等同于 or - 唯一性太差,会引起索引失效。(例如一个字段有好多内容是相同的)
- 类型转换导致索引失效
只是我常常觉得很多话无从说起。就像在平时,见到一些陌生人,一些熟悉和欢喜的人,不知道与之说些什么。也很少对身边的人谈论自己。所有的时间和记忆,都可以交付给书写。不可能再说得更多。有些在书中说过多次,却似乎并未说出真正想表达的意思。有些从无提起过,它们在黑暗中更显得郑重端庄。有些事是不能轻易说起的。书写可以,但那也是不足够的。
素年锦时
安妮宝贝