【Paddle】PCA线性代数基础及领域应用
- 写在最前面
- 一、PCA线性代数基础
- 1. PCA的算法原理
- 2. PCA的线性代数基础
- 2.1 标准差 Standard Deviation
- 2.2 方差 Variance
- 2.3 协方差 Covariance
- 2.4 协方差矩阵 The Covariance Matrix
- 2.5 paddle代码demo①:计算协方差矩阵
- 2.6 特征向量 Eigenvectors
- 标准化处理
- 2.7 paddle代码demo②:计算特征值和特征向量
- 2.8 选择主成分并生成特征向量 Choosing components and forming a feature vector
- 2.9 通过选择特征向量生成新的数据集 Deriving the New Data Set
- 二、【基于Paddle实现】PCA的人脸识别算法
- 1. 数据集
- 2. 安装库
- 3. paddle代码相关函数的实现
- 三、小结
- 四、参考文献

写在最前面
主成分分析(PCA,Principal Component Analysis)是一项在高维数据中,寻找最重要特征的降维技术,大大减少数据的维度,而不显著损失信息量。
本文将通过实际的 Paddle 代码示例,来展示所提供的高效、灵活的线性代数API,如何简化了机器学习和深度学习中的数据处理和分析工作,为高维数据集的处理和分析提供了有效工具。
将从以下两个板块展开介绍。
- PCA的算法原理:介绍PCA的数学基础,如何从线性代数的角度理解PCA,以及PCA算法的步骤。
- PCA在人脸识别中的应用:探索Paddle中PCA如何在人脸识别技术中使用,包括多个线性代数计算 API ,更好地支持科学计算类模型。
完整代码及数据集放到GitHub啦:https://github.com/lightrain-a/PCA-face-recognition
如果代码上有任何问题,欢迎留言交流 ~

一、PCA线性代数基础
1. PCA的算法原理
PCA的算法原理基于线性代数和统计学,旨在将原始的数据通过线性变换映射到一个新的坐标系统中,新坐标系的基是原始数据集的正交特征向量。这些新的坐标轴被称为主成分,它们按照能够解释原始数据集方差的大小排序。
2. PCA的线性代数基础
要理解PCA,首先需要掌握一些线性代数的数学概念,这是进行PCA分析的基础:
- 标准差(Standard Deviation)、方差(Variance)、协方差(Covariance)、特征向量(eigenvectors)、特征值(eigenvalues)
下面介绍PCA的线性代数基础,理解标准差、方差、协方差以及特征向量和特征值的概念,更好地掌握PCA的理论基础。
2.1 标准差 Standard Deviation
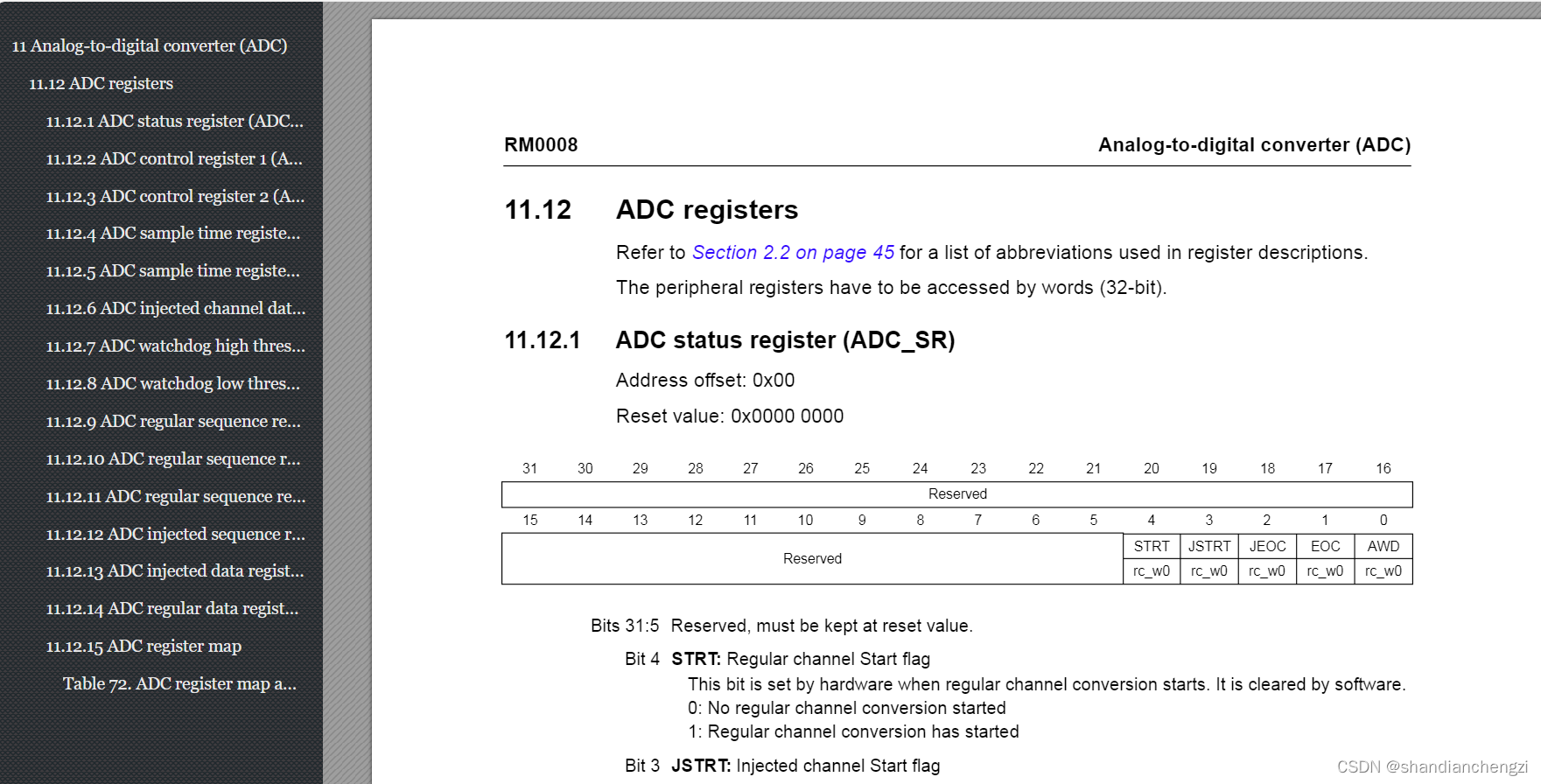
标准差是衡量数据分散程度的一个重要指标,它描述了数据点与数据集平均值的偏离程度。标准差越大,表示数据分布越分散;标准差越小,表示数据分布越集中。标准差的数学表达式为:
σ = 1 N ∑ i = 1 N ( x i − μ ) 2 \sigma = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2} σ=N1i=1∑N(xi−μ)2
其中, σ \sigma σ是标准差, N N N是样本数量, x i x_i xi是每个样本点,而 μ \mu μ是样本的平均值。当数据集是总体时,分母使用 N N N;当数据集是样本时,为了得到无偏估计,分母使用 N − 1 N-1 N−1。
2.2 方差 Variance
方差是衡量数据分散程度的另一个核心概念,它与标准差紧密相关,实际上,方差就是标准差的平方。方差给出了数据分布的平均偏差(距平均值的距离)的平方,用于描述数据的波动性。方差的数学表达式为:
Var ( X ) = 1 N ∑ i = 1 N ( x i − μ ) 2 \text{Var}(X) = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2 Var(X)=N1i=1∑N(xi−μ)2
这里, Var ( X ) \text{Var}(X) Var(X)表示方差,其余符号含义与标准差中相同。
2.3 协方差 Covariance
协方差是衡量两个变量之间线性关系强度及方向的统计量。正协方差表示两个变量同时增加或减少,负协方差表示一个变量增加时另一个变量减少。协方差的数学表达式为:
Cov ( X , Y ) = 1 N ∑ i = 1 N ( x i − μ x ) ( y i − μ y ) \text{Cov}(X,Y) = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu_x)(y_i - \mu_y) Cov(X,Y)=N1i=1∑N(xi−μx)(yi−μy)
其中, X X X和 Y Y Y是两个随机变量, μ x \mu_x μx和 μ y \mu_y μy分别是 X X X和 Y Y Y的平均值。协方差的值越大,表示两个变量之间的正线性关系越强;值越小(负值),表示负线性关系越强。
2.4 协方差矩阵 The Covariance Matrix
协方差矩阵主要是用于当数据的维度超过3或者更多的时候,我们可以通过一个矩阵来存储各个维度的协方差,这个矩阵就被称为“协方差矩阵”。
当想要表示一个具有 N N N个变量的数据集的协方差矩阵时,这个矩阵将包含每一对变量之间的协方差。如果有 N N N个变量,协方差矩阵将是一个 N × N N \times N N×N的矩阵,其中矩阵中的元素 Cov ( X i , X j ) \text{Cov}(X_i, X_j) Cov(Xi,Xj)表示变量 X i X_i Xi和 X j X_j Xj之间的协方差。对于变量 X 1 , X 2 , … , X N X_1, X_2, \ldots, X_N X1,X2,…,XN,协方差矩阵可以用下面的数学表达式表示:
Covariance Matrix = [ Cov ( X 1 , X 1 ) Cov ( X 1 , X 2 ) ⋯ Cov ( X 1 , X N ) Cov ( X 2 , X 1 ) Cov ( X 2 , X 2 ) ⋯ Cov ( X 2 , X N ) ⋮ ⋮ ⋱ ⋮ Cov ( X N , X 1 ) Cov ( X N , X 2 ) ⋯ Cov ( X N , X N ) ] \text{Covariance Matrix} = \begin{bmatrix} \text{Cov}(X_1, X_1) & \text{Cov}(X_1, X_2) & \cdots & \text{Cov}(X_1, X_N) \\ \text{Cov}(X_2, X_1) & \text{Cov}(X_2, X_2) & \cdots & \text{Cov}(X_2, X_N) \\ \vdots & \vdots & \ddots & \vdots \\ \text{Cov}(X_N, X_1) & \text{Cov}(X_N, X_2) & \cdots & \text{Cov}(X_N, X_N) \end{bmatrix} Covariance Matrix= Cov(X1,X1)Cov(X2,X1)⋮Cov(XN,X1)Cov(X1,X2)Cov(X2,X2)⋮Cov(XN,X2)⋯⋯⋱⋯Cov(X1,XN)Cov(X2,XN)⋮Cov(XN,XN)
在这个矩阵中,对角线上的元素 Cov ( X i , X i ) \text{Cov}(X_i, X_i) Cov(Xi,Xi)表示变量 X i X_i Xi与其自身的协方差,这实际上就是变量 X i X_i Xi的方差。而非对角线上的元素则表示不同变量之间的协方差,用于衡量这些变量之间的线性关系。这个协方差矩阵提供了一个全面的视角来观察数据集中所有变量之间的关系,是进行多变量统计分析时不可或缺的工具。
假设有一个包含三个维度(X, Y, Z)的数据集,那么这个数据集的协方差矩阵可以表示为:
Covariance Matrix = [ Cov ( X , X ) Cov ( X , Y ) Cov ( X , Z ) Cov ( Y , X ) Cov ( Y , Y ) Cov ( Y , Z ) Cov ( Z , X ) Cov ( Z , Y ) Cov ( Z , Z ) ] \text{Covariance Matrix} = \begin{bmatrix} \text{Cov}(X, X) & \text{Cov}(X, Y) & \text{Cov}(X, Z) \\ \text{Cov}(Y, X) & \text{Cov}(Y, Y) & \text{Cov}(Y, Z) \\ \text{Cov}(Z, X) & \text{Cov}(Z, Y) & \text{Cov}(Z, Z) \end{bmatrix} Covariance Matrix= Cov(X,X)Cov(Y,X)Cov(Z,X)Cov(X,Y)Cov(Y,Y)Cov(Z,Y)Cov(X,Z)Cov(Y,Z)Cov(Z,Z)
在这个矩阵中:
- 对角线上的元素( Cov ( X , X ) \text{Cov}(X, X) Cov(X,X), Cov ( Y , Y ) \text{Cov}(Y, Y) Cov(Y,Y), Cov ( Z , Z ) \text{Cov}(Z, Z) Cov(Z,Z))分别表示每个维度与自身的协方差,实际上就是该维度的方差。
- 非对角线上的元素(如 Cov ( X , Y ) \text{Cov}(X, Y) Cov(X,Y), Cov ( Y , Z ) \text{Cov}(Y, Z) Cov(Y,Z)等)表示不同维度之间的协方差,用于衡量这些维度之间的线性关系。
这个协方差矩阵提供了数据集中所有变量之间关系的一个全面视图,是进行多维数据分析和模式识别中不可或缺的工具。特别是在主成分分析(PCA)中,通过对协方差矩阵进行特征分解,我们可以提取出数据的主成分,从而用于降维、数据压缩或特征提取等目的。
2.5 paddle代码demo①:计算协方差矩阵
计算一下两个数据的协方差矩阵:
- x : ( 10 , 39 , 19 , 23 , 28 ) x:(10,39,19,23,28) x:(10,39,19,23,28)和 y : ( 43 , 13 , 32 , 21 , 20 ) y:(43,13,32,21,20) y:(43,13,32,21,20)
- x : ( 1 , − 1 , 4 ) x:(1, -1, 4) x:(1,−1,4)、 y : ( 2 , 1 , 3 ) y:(2, 1, 3) y:(2,1,3)和 z : ( 1 , 3 , − 1 ) z:(1, 3, -1) z:(1,3,−1)
使用paddle.linalg模块来计算协方差矩阵。PaddlePaddle的paddle.linalg.cov函数可以用来计算协方差矩阵。
import paddle# 初始化数据
x1 = paddle.to_tensor([10, 39, 19, 23, 28], dtype='float32')
y1 = paddle.to_tensor([43, 13, 32, 21, 20], dtype='float32')x2 = paddle.to_tensor([1, -1, 4], dtype='float32')
y2 = paddle.to_tensor([2, 1, 3], dtype='float32')
z2 = paddle.to_tensor([1, 3, -1], dtype='float32')# 计算协方差矩阵
# 注意: PaddlePaddle在计算协方差矩阵时,需要将数据组合成一个二维tensor,其中每行是一个变量的观测值
cov_matrix1 = paddle.linalg.cov(paddle.stack([x1, y1], axis=0))
cov_matrix2 = paddle.linalg.cov(paddle.stack([x2, y2, z2], axis=0))print("协方差矩阵1:")
print(cov_matrix1.numpy())
# 协方差矩阵1:
# [[ 115.70003 -120.54999]
# [-120.54999 138.70001]]print("\n协方差矩阵2:")
print(cov_matrix2.numpy())
# 协方差矩阵2:
# [[ 6.333333 2.4999995 -5. ]
# [ 2.5 1. -2. ]
# [-5. -2. 4. ]]计算两组数据的协方差矩阵得到的结果如下:
对于数据集 x : ( 10 , 39 , 19 , 23 , 28 ) x:(10,39,19,23,28) x:(10,39,19,23,28)和 y : ( 43 , 13 , 32 , 21 , 20 ) y:(43,13,32,21,20) y:(43,13,32,21,20),协方差矩阵为:
[ 115.7 − 120.55 − 120.55 138.7 ] \begin{bmatrix} 115.7 & -120.55 \\ -120.55 & 138.7 \end{bmatrix} [115.7−120.55−120.55138.7]
而对于数据集 x : ( 1 , − 1 , 4 ) x:(1, -1, 4) x:(1,−1,4)、 y : ( 2 , 1 , 3 ) y:(2, 1, 3) y:(2,1,3)和 z : ( 1 , 3 , − 1 ) z:(1, 3, -1) z:(1,3,−1),协方差矩阵为:
[ 6.33 2.5 − 5 2.5 1 − 2 − 5 − 2 4 ] \begin{bmatrix} 6.33 & 2.5 & -5 \\ 2.5 & 1 & -2 \\ -5 & -2 & 4 \end{bmatrix} 6.332.5−52.51−2−5−24
这两个协方差矩阵分别捕获了数据集中变量间的相互关系。在第一个矩阵中,我们可以看到 x x x和 y y y之间存在负相关关系,因为它们的协方差是负值。在第二个矩阵中,各变量间的正负协方差值揭示了它们之间更复杂的相互关系。
2.6 特征向量 Eigenvectors
在协方差矩阵的上下文中,特征向量和特征值揭示了数据结构的深层次信息。通过对协方差矩阵进行特征分解,可以找到几个关键的方向,这些方向是数据方差(也就是数据的变化)最大的方向。这正是PCA方法寻找主成分的基础。
特征向量的物理意义如下:
- 方差最大的方向:协方差矩阵的每个特征向量代表数据在某个特定方向上的分散程度最大。这意味着,如果你将数据点投影到这些特征向量上,那么投影点的分布将会有最大的方差,揭示了数据最重要的结构。
- 数据的主要变化方向:特征向量指向的方向是数据变化最显著的方向。在多维数据集中,第一个特征向量(对应最大特征值的特征向量)指向方差最大的方向,而其他特征向量则指向其他重要的、但方差较小的方向。
- 正交性:特别是在PCA中,协方差矩阵是对称的,所以它的特征向量是正交(或互相垂直)的。这表明了数据的不同主要变化方向是相互独立的。
标准化处理
为了方便处理和解释,通常需要将特征向量标准化。标准化的特征向量有一个单位长度,这使得它们在比较不同方向的重要性时处于同一尺度。标准化处理的数学表达式为:
α ^ = α ∥ α ∥ \hat{\alpha} = \frac{\alpha}{\|\alpha\|} α^=∥α∥α
其中, α \alpha α是原始的特征向量, ∥ α ∥ \|\alpha\| ∥α∥是特征向量的模长(也就是它的L2范数),而 α ^ \hat{\alpha} α^是标准化后的特征向量。
这种标准化处理确保了特征向量的长度为1,使得特征向量只表示方向,而不受其原始长度的影响。在PCA分析中,这有助于集中关注数据变化的方向,而不是特征向量的具体大小。
2.7 paddle代码demo②:计算特征值和特征向量
代码实现:计算一个二维数据的协方差矩阵以及该协方差矩阵的特征值和特征向量。
步骤如下:
- 计算x维和y维数据的平均值。
- 使用原始数据减去相应的平均值,得到更新后的数据。
- 使用飞桨计算协方差矩阵。
- 计算协方差矩阵的特征值和特征向量。
以下是相应的PaddlePaddle代码示例:
import paddle# 初始化数据
x = paddle.to_tensor([2.5, 0.5, 2.2, 1.9, 3.1, 2.3, 2, 1, 1.5, 1.1], dtype='float32')
y = paddle.to_tensor([2.4, 0.7, 2.9, 2.2, 3.0, 2.7, 1.6, 1.1, 1.6, 0.9], dtype='float32')# 计算平均值
means_X = paddle.mean(x)
means_Y = paddle.mean(y)
print("x 维的平均值为:", means_X.numpy())
print("y 维的平均值为:", means_Y.numpy())
# x 维的平均值为: 1.8099998
# y 维的平均值为: 1.9100001# 更新数据,减去平均值
update_x = x - means_X
update_y = y - means_Y# 合并更新后的数据
c = paddle.stack((update_x, update_y), axis=0)# 计算协方差矩阵
cov_c = paddle.linalg.cov(c)
print("协方差矩阵为:", cov_c.numpy())
# 协方差矩阵为: [[0.6165555 0.6154444]
# [0.6154444 0.7165556]]# 计算协方差矩阵的特征值和特征向量
eigenvalues, eigenvectors = paddle.linalg.eig(cov_c)
print("该协方差矩阵的特征值为:", eigenvalues.numpy())
print("该协方差矩阵的特征向量为:", eigenvectors.numpy())
# 该协方差矩阵的特征值为: [0.04908335+0.j 1.2840276 +0.j]
# 该协方差矩阵的特征向量为: [[-0.73517877+0.j -0.6778734 +0.j]
# [ 0.6778734 +0.j -0.73517877+0.j]]
请注意,在使用paddle.linalg.eig函数计算特征值和特征向量时,得到的结果是复数形式的,这是因为在数学上特征值和特征向量可能是复数。在实际应用中,特别是在PCA中,协方差矩阵是实对称矩阵,其特征值和特征向量应该是实数。如果你得到复数结果,它们的虚部通常应该非常接近于零,可以根据实际情况忽略。
2.8 选择主成分并生成特征向量 Choosing components and forming a feature vector
在进行PCA分析时,选择主成分(即特征向量)并形成特征向量是决定性的步骤,它直接影响到降维后数据的质量。
选择主成分的过程基于特征值的大小。特征值较大的特征向量对应的方向上,数据的方差较大,这意味着数据在这个方向上有更多的信息量。因此,选择特征值较大的特征向量作为主成分,可以保留数据最重要的信息。具体步骤如下:
- 特征值排序:将所有特征值按照大小降序排列。这样,最大的特征值会排在最前面,对应的特征向量代表了数据集中最主要的方差方向。
- 选择主成分数量:确定要保留的主成分数量。这通常基于特征值的累计贡献率,即前 k k k个最大特征值之和占所有特征值之和的比例。一种常见的选择方法是保留累计贡献率达到某个阈值(如85%、90%)的特征向量。
- 形成特征向量:根据选定的主成分数量,从排序后的特征向量集合中选择前 k k k个特征向量。这些特征向量构成了降维后数据的新基。
2.9 通过选择特征向量生成新的数据集 Deriving the New Data Set
生成新的数据集,即完成数据的降维,涉及以下关键步骤:
-
数据标准化:首先对原始数据集 X X X进行标准化处理,以确保每个维度的均值为0。对于由维度 x x x和 y y y组成的数据集,标准化的表达式为:
rowdataAdjust = [ x 1 − μ x x 2 − μ x ⋯ x n − μ x y 1 − μ y y 2 − μ y ⋯ y n − μ y ] T \text{rowdataAdjust} = \begin{bmatrix} x_1 - \mu_x & x_2 - \mu_x & \cdots & x_n - \mu_x \\ y_1 - \mu_y & y_2 - \mu_y & \cdots & y_n - \mu_y \end{bmatrix}^T rowdataAdjust=[x1−μxy1−μyx2−μxy2−μy⋯⋯xn−μxyn−μy]T
其中, μ x \mu_x μx和 μ y \mu_y μy分别代表 x x x和 y y y维度的平均值。
-
特征向量选择与构造:根据主成分分析(PCA)确定主要成分,并选取对应的特征向量。如果选择了前 P P P个主成分,则构造特征向量矩阵 W W W:
W = [ v ⃗ 1 , v ⃗ 2 , … , v ⃗ p ] W = [\vec{v}_1, \vec{v}_2, \ldots, \vec{v}_p] W=[v1,v2,…,vp]
其中, v ⃗ i \vec{v}_i vi代表第 i i i个特征向量。
-
降维:通过将标准化后的数据矩阵与特征向量矩阵相乘,计算降维后的数据集 Y Y Y:
FinalData = rowdataAdjust ⋅ W \text{FinalData} = \text{rowdataAdjust} \cdot W FinalData=rowdataAdjust⋅W
这里, FinalData \text{FinalData} FinalData是降维后的数据集,其中每一行代表原始数据点在新的特征空间中的坐标。
通过这个过程,原始的高维数据被有效地映射到了一个低维空间,同时尽可能保留了数据中最重要的结构信息。这种方法在数据压缩、特征提取、以及数据可视化等方面非常有用,能够帮助我们更好地理解和分析数据集的本质特性。
二、【基于Paddle实现】PCA的人脸识别算法
1. 数据集
本文使用的是ORL官方数据集,可以从一下网址下载到ORL下载链接
该数据集表示的是一共有40个人的人脸图像,其中每一个人有10张人脸图像。相应的PGM文件为说明。
2. 安装库
安装cv2的库:
pip install opencv-python
安装paddle的库:(cpu版本的即可)
pip install paddle
3. paddle代码相关函数的实现
首先定义一个函数用于将人脸图像矢量化为一个向量,向量的大小与图片的像素有关,代码如下:
# 图片矢量化def img2vector(self, image):img = cv2.imread(image, 0) # 读取图片imgVector = paddle.reshape(paddle.to_tensor(img, dtype='float32'), [1, -1]) # 重塑为1行多列return imgVector
接下来定义一个函数用来选取训练图片,并对每张图片进行前面定义过的矢量化处理
# 读入人脸库,每个人选择k张作为训练样本,剩下的作为测试样本def load_orl(self):'''对训练数据集进行数组初始化,用0填充,每张图片尺寸都定为112*92,现在共有40个人,每个人都选择k张,则整个训练集大小为40*k,112*92'''train_images = []train_labels = []test_images = []test_labels = []sample = np.random.permutation(10) + 1 # 生成随机序列for i in range(40): # 共有40个人people_num = i + 1for j in range(10): # 每人10张照片image_path = os.path.join(self.data_path, 's' + str(people_num), str(sample[j]) + '.jpg')img = self.img2vector(image_path) # 读取图片并进行矢量化if j < self.k: # 构成训练集train_images.append(img)train_labels.append(people_num)else: # 构成测试集test_images.append(img)test_labels.append(people_num)if self.train:return paddle.concat(train_images, axis=0), paddle.to_tensor(train_labels, dtype='int64')else:return paddle.concat(test_images, axis=0), paddle.to_tensor(test_labels, dtype='int64')
前期将所有训练图片矢量化之后,开始进行PCA算法的降维操作
def PCA(data, r): # 降低到r维data = paddle.cast(data, 'float32')rows, cols = data.shapedata_mean = paddle.mean(data, axis=0)A = data - paddle.tile(data_mean, repeat_times=[rows, 1])C = paddle.matmul(A, A, transpose_y=True) # 协方差矩阵eig_vals, eig_vects = paddle.linalg.eigh(C) # 特征值和特征向量eig_vects = paddle.matmul(A.T, eig_vects[:, :r])for i in range(r):eig_vects[:, i] = eig_vects[:, i] / paddle.norm(eig_vects[:, i])final_data = paddle.matmul(A, eig_vects)return final_data, data_mean, eig_vects
最后我们进行初次训练,随机选取每个人物的五张图片作为训练图片使用。将降低的维数设定为10维、20维、30维、40维,查看一下训练效果如何。
def face_recognize(data_path):for r in range(10, 41, 10):print(f"当降维到{r}时:")dataset_train = ORLDataset(data_path, k=7, train=True)dataset_test = ORLDataset(data_path, k=7, train=False)train_data, train_labels = paddle.to_tensor(dataset_train.images), paddle.to_tensor(dataset_train.labels, dtype='int64')test_data, test_labels = paddle.to_tensor(dataset_test.images), paddle.to_tensor(dataset_test.labels, dtype='int64')data_train_new, data_mean, V_r = PCA(train_data, r)temp_face = test_data - data_meandata_test_new = paddle.matmul(temp_face, V_r)true_num = 0for i in range(len(dataset_test)):diffMat = data_train_new - data_test_new[i]sqDiffMat = paddle.square(diffMat)sqDistances = paddle.sum(sqDiffMat, axis=1)sortedDistIndices = paddle.argsort(sqDistances)if train_labels[sortedDistIndices[0]] == test_labels[i]:true_num += 1accuracy = float(true_num) / len(dataset_test)print(f'当每个人选择7张照片进行训练时,The classify accuracy is: {accuracy:.2%}')
最终训练得到的结果如下:
当降维到10时:
当每个人选择7张照片进行训练时,The classify accuracy is: 67.50%
当降维到20时:
当每个人选择7张照片进行训练时,The classify accuracy is: 35.00%
当降维到30时:
当每个人选择7张照片进行训练时,The classify accuracy is: 67.50%
当降维到40时:
当每个人选择7张照片进行训练时,The classify accuracy is: 40.00%
三、小结
PaddlePaddle的paddle.linalg API为进行数据降维和特征提取提供了强大的支持,这对于机器学习和深度学习应用来说是非常重要的。特别是,paddle.linalg.eig和paddle.linalg.svd函数允许用户有效地计算数据的特征值和特征向量,这是执行主成分分析(PCA)和奇异值分解(SVD)等降维方法的关键。此外,paddle.linalg.matmul可以用于矩阵乘法,帮助将数据从高维空间映射到低维空间,保留了数据中最重要的信息。
这些功能的广泛应用不仅限于PCA相关的任务,还包括数据压缩、特征选择和提高学习算法的效率等领域。通过降维,可以显著减少模型训练的计算资源需求,提高模型的泛化能力,减少过拟合的风险。PaddlePaddle通过提供这些高效、灵活的线性代数API,极大地简化了机器学习和深度学习中的数据处理和分析工作,为高维数据集的处理和分析提供了有效工具。
四、参考文献
- 官网 paddle.linalg API 目录
- PCA-Principal-Components-Analysis
欢迎大家添加好友,持续发放粉丝福利!