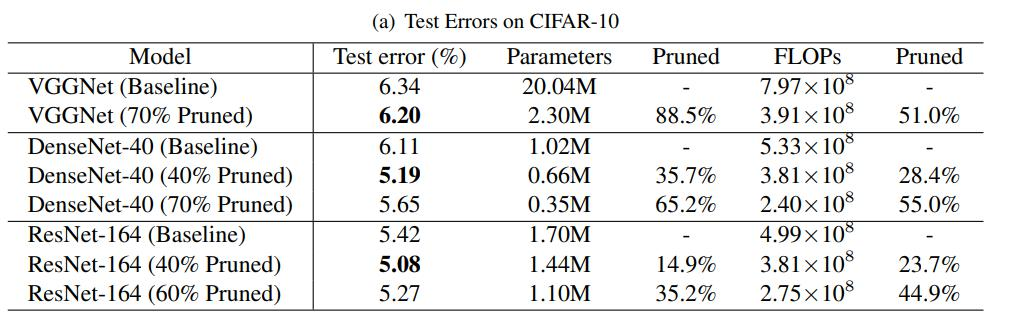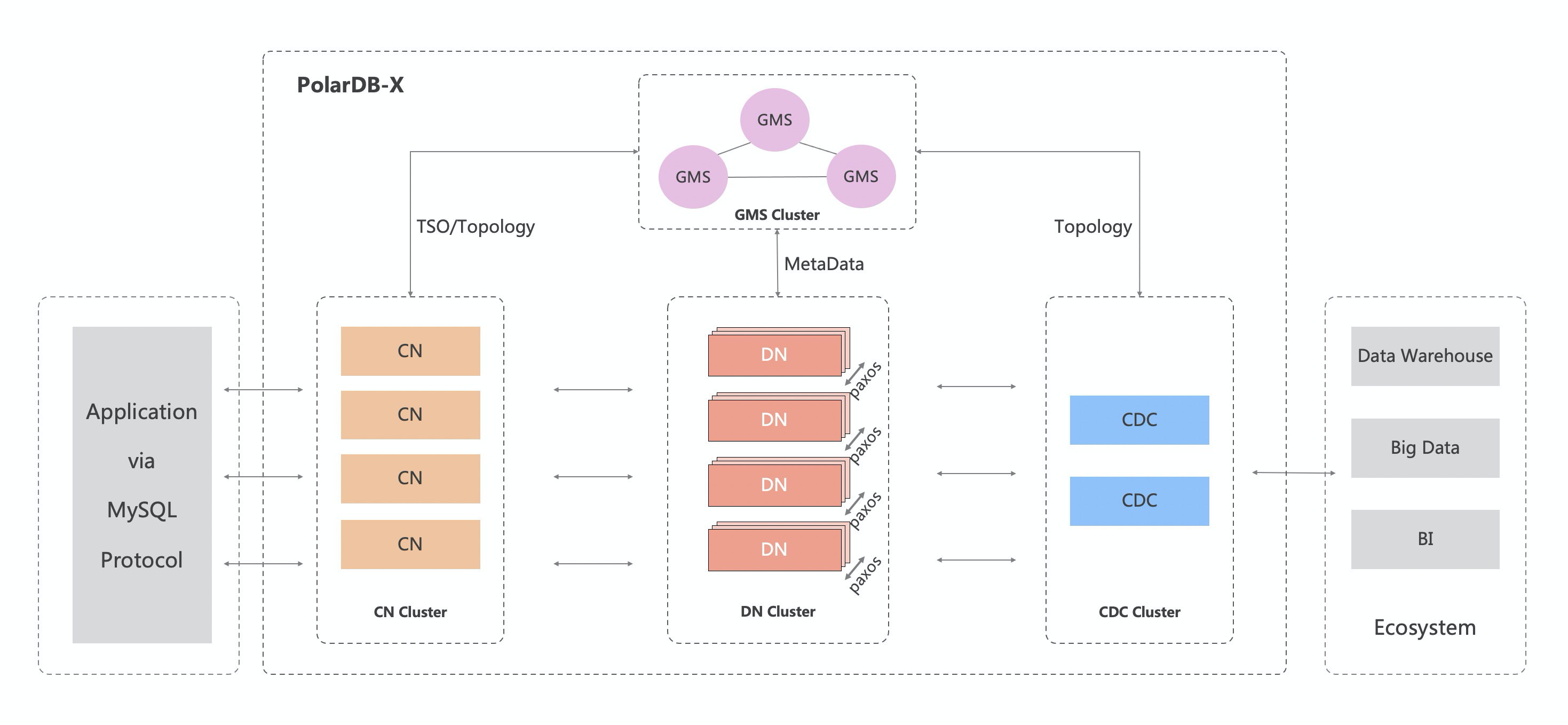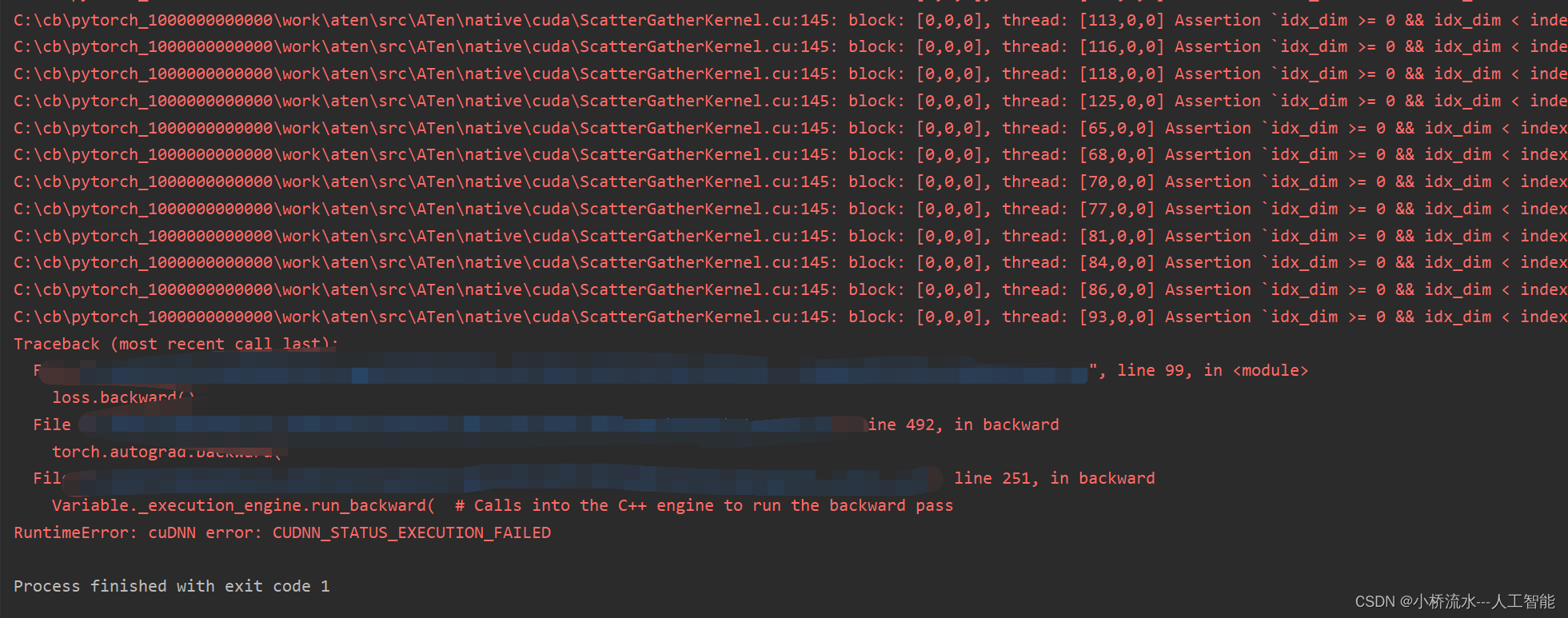
下图说明在一瞬间我的GPU就被占满了

我的模型在训练过程中遇到了 CUDA 相关的错误,这是由于 GPU资源问题或内存不足导致的。这类错误有时候也可能是由于某些硬件兼容性问题或驱动程序问题引起的。
为了解决这个问题,可以尝试以下几个解决方案:
- 降低批次大小:减小批次大小可以减少每次迭代对 GPU 内存的需求,有助于避免内存不足的问题。
- 确保足够的 GPU 内存:确保在训练开始前没有其他应用程序占用大量 GPU 内存。您可以使用命令如
nvidia-smi来检查 GPU 的使用情况。 - 更新或回滚 PyTorch 和 CUDA:有时候软件更新(或者反过来,回滚到早期的稳定版本)可以解决兼容性问题。
- 设置环境变量:如错误提示中所述,设置
CUDA_LAUNCH_BLOCKING=1环境变量可以帮助确切地定位问题发生的位置,这对调试非常有用。
根据您提供的信息,我建议从调整批次大小开始,看看是否能解决问题。同时,也可以尝试设置 CUDA_LAUNCH_BLOCKING=1 来更精确地定位问题。以下是调整批次大小的代码片段:
# 数据加载器
batch_size = 16 # Reduced batch size
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)