一、引入
上一篇了解了飞书 28 种数据类型通过接口读取到的数据结构,本文开始探讨如何将这些数据写入 MySQL 数据库。
这个工作流的起点是从 API 获取到的一个完整的数据,终点是写入 MySQL 数据表,表结构和维格表结构类似。在过程中可以有不同的工作流程,可以是将接口返回的所有数据作为一个值,直接写入 MySQL 表中,再使用 MySQL 对该值进行解析,处理成不同的列,然后再新建一张表单存储,这种方法入库比较简单粗暴,但是 MySQL 的处理会比较复杂,更侧重 MySQL 的对 json 结构的解析处理能力;也可以使用 Python 对接口数据进行进行处理,提取出各个数据列以及对应的值,再入库。
本文主要探讨后者。
虽然飞书的多维表提供了 28 中数据类型,但是本质上,很多数据类型记录的内容从 MySQL 的数据类型的角度上看是相似的,可能有点绕,举个例子:如下图,文本列和单选列虽然在飞书多维表是分为两个数据类型,但是它们的列值:单选1、单选2、这是文本111、这是文本222,本质上都是一个字符串,所以在入库处理时可以都设置为 MySQL 的 varchar 数据类型。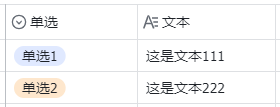
从 MySQL 的数据类型的角度上看,我们可以将飞书的这 28 中数据类型划分为五类,分别是字符串、数据、时间、列表和布尔值,参考如下:
| 类型描述 | MySQL 常用数据类型 | 飞书数据类型编码 | 飞书数据类型中文描述 |
|---|---|---|---|
| 字符串 | text、varchar、char | 1、3、11、13、15、22、23、1003、1004、1005 | 多行文本、条码、Email邮箱、单选、人员、电话号码、超链接、附件、地理位置、群组、创建人、修改人、自动编号 |
| 数字 | double、float、bigint、int | 2 | 数字、进度、货币、评分 |
| 布尔值 | bool | 7 | 复选框 |
| 时间 | datetime、date、timestamp | 5、1001、1002 | 日期、创建时间、最后更新时间 |
| 列表格式字符串 | json | 4、17、18、21、19、20 | 多选、附件、单向关联、双向关联、查找引用、公式 |
下面开始探讨相关的数据处理。
本文结构:先对每个数据类型进行处理,然后在 MySQL 创建数据表,最后将数据写入数据表。
二、使用 pandas 处理每个数据类型的数据
2.1 环境说明
Python 3.9.12,相关第三方库如下:
requests == 2.31.0
pandas == 1.3.5
SQLAlchemy == 1.4.32
jupyter == 1.0.0
MySQL 8.0
2.2 准备工作
由于飞书应用的限制,飞书多维表无法设置公开给任一应用读取使用,所以需要自行创建一个包含 28 种数据类型的多维表,然后给应用授权(参考《飞书API(3):Python 自动读取多维表所有分页数据的三种方法》的3、创建多维表,并设置应用操作多维表的权限)。
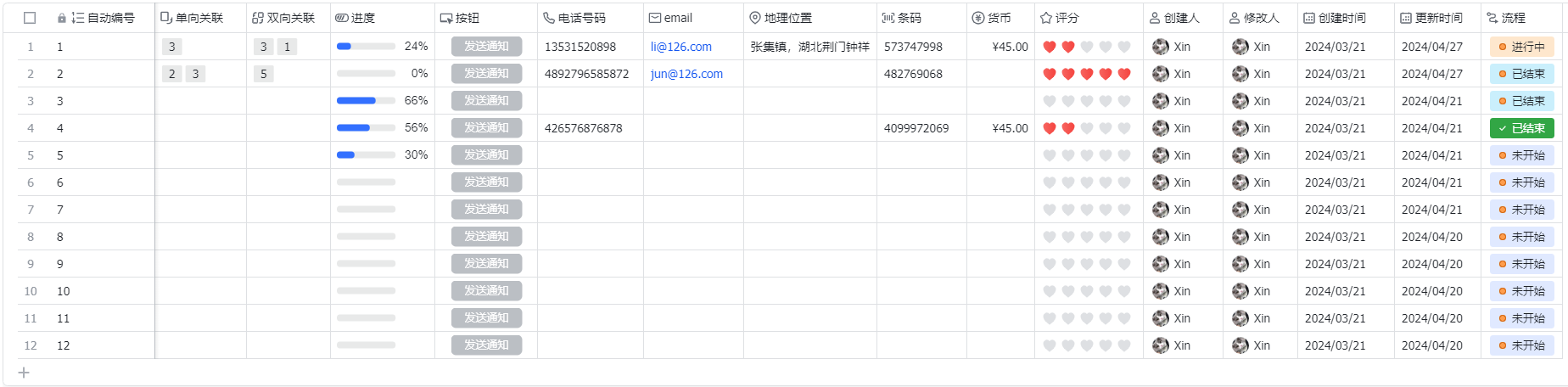
我用于测试的数据结构如下,可能你的和我的命名不同,所以以下代码的列名称根据你的列名进行修改即可。
我的测试数据为: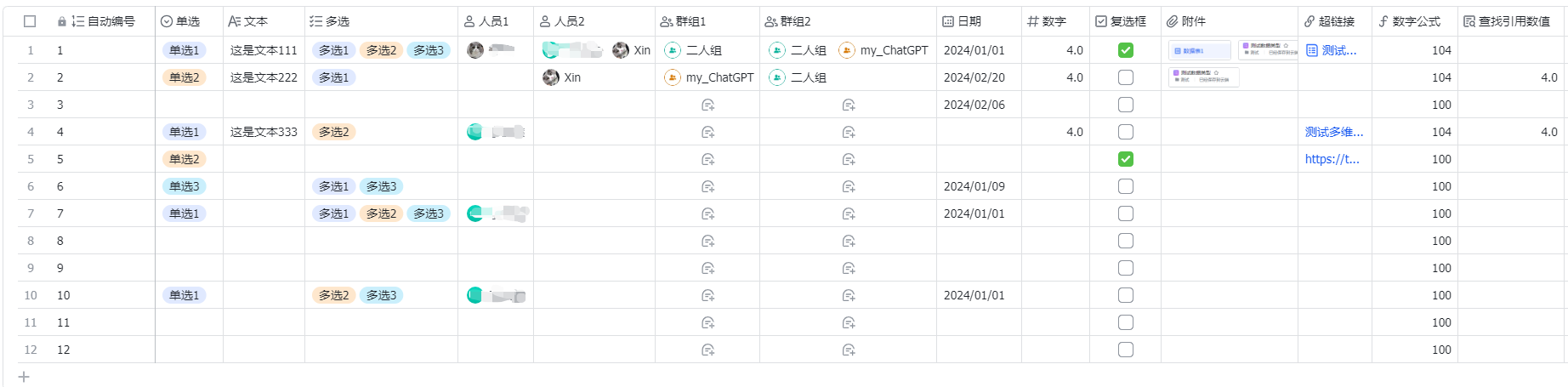
为了方便调试,本次使用 jupyter notebook 来做数据处理。
如果你未安装过 jupyter,可以考虑以下方案:
- 如果安装 Python 是使用 Anaconda 3 包,一般会自动安装 jupyter;
- 如果安装 Python 是使用官方的 Python 包,可以通过
pip install jupyter安装; - 不想安装,也可以直接跑 .py 文件;
- 当然也有替代方案,直接在命令行或终端输入
python回车调用 Python 的测试环境,或者输入ipython回车调用 ipython 来测试。
我们取《飞书API(3):Python 自动读取多维表所有分页数据的三种方法》的【2.1 while 循环读取分页数据】来读取所有的数据,代码如下。
import requests
import jsondef get_tenant_access_token(app_id, app_secret):url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"payload = json.dumps({"app_id": app_id,"app_secret": app_secret})headers = {'Content-Type': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)# print(response.text)return response.json()['tenant_access_token']def get_bitable_datas(tenant_access_token, app_token, table_id, page_token='', page_size=20):url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/records/search?page_size={page_size}&page_token={page_token}&user_id_type=user_id"payload = json.dumps({})headers = {'Content-Type': 'application/json','Authorization': f'Bearer {tenant_access_token}'}response = requests.request("POST", url, headers=headers, data=payload)# print(response.text)return response.json()def main():app_id = 'your_app_id'app_secret = 'your_app_secret'tenant_access_token = get_tenant_access_token(app_id, app_secret)app_token = 'your_app_token'table_id = 'your_table_id'page_token = ''page_size = 5has_more = Truefeishu_datas = []while has_more:response = get_bitable_datas(tenant_access_token, app_token, table_id, page_token, page_size)if response['code'] == 0:page_token = response['data'].get('page_token')has_more = response['data'].get('has_more')# print(response['data'].get('items'))# print('\n--------------------------------------------------------------------\n')feishu_datas.extend(response['data'].get('items'))else:raise Exception(response['msg'])return feishu_datasif __name__ == '__main__':feishu_datas = main()print(feishu_datas)
将代码放到 jupyter notebook 中运行,得到结果如下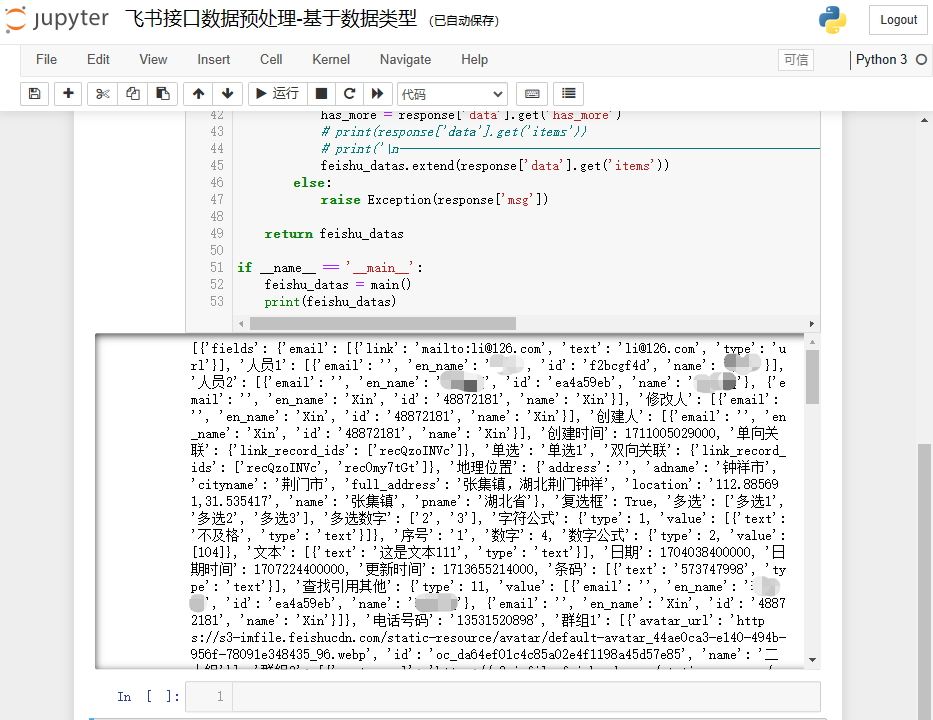
接下来将获取到的数据feishu_datas通过 Pandas 的 DataFrame 来处理。
import pandas as pd
feishu_df = pd.DataFrame(feishu_datas)
feishu_df
打印结果如下: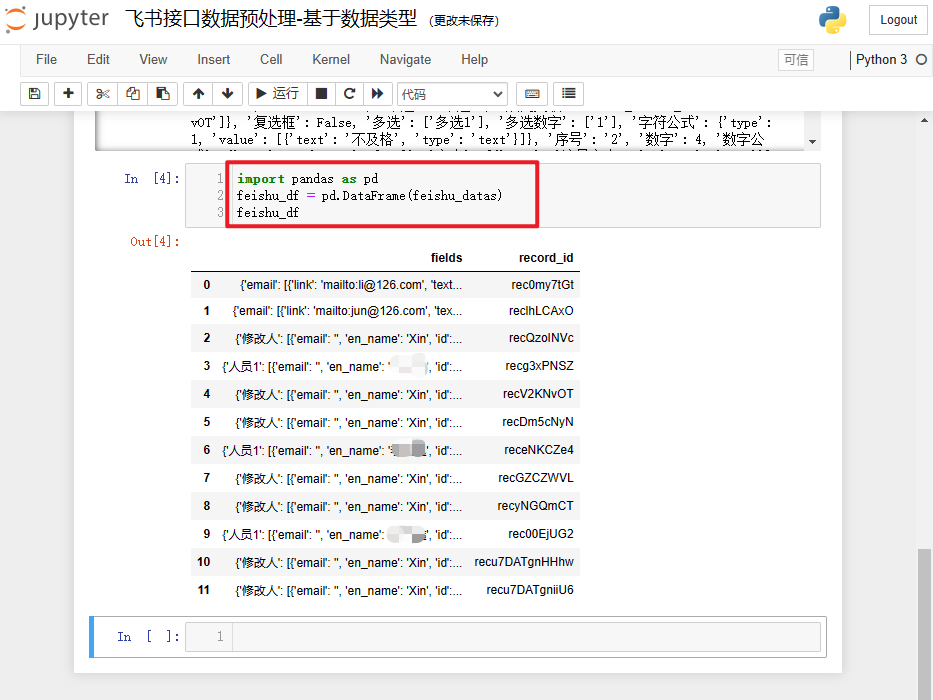
上篇,我们已经了解到每个飞书数据类型返回的数据结构,接下来就结合它来取值。
2.3 提取字符串数据列
2.3.1 多行文本、条码、Email邮箱
多行文本、条码、Email邮箱这三者的数据结构类型类似,可以统一处理,即取“text”的值。
| 数据类型编码 | 数据类型中文描述 | 数据类型对应英文描述 | 数据示例 |
|---|---|---|---|
| 1 | 多行文本、条码 | Text,Barcode | “多行文本”: [{“text”: “我是文本1”,“type”: “text”}] |
| 1 | Email邮箱 | “Email”: [{“link”: “mailto:ceshi@ceshi.com”,“text”: “ceshi@ceshi.com”,“type”: “url”}] |
但是,实际生产中的数据可能没有那么完美,会存在很多空值,直接取“text”即get("文本")[0].get("text")会报错:TypeError: ‘NoneType’ object is not subscriptable,大致意思就是空值类型不能索引。如果值不为空,正常返回列表,才可以通过[0]进行索引。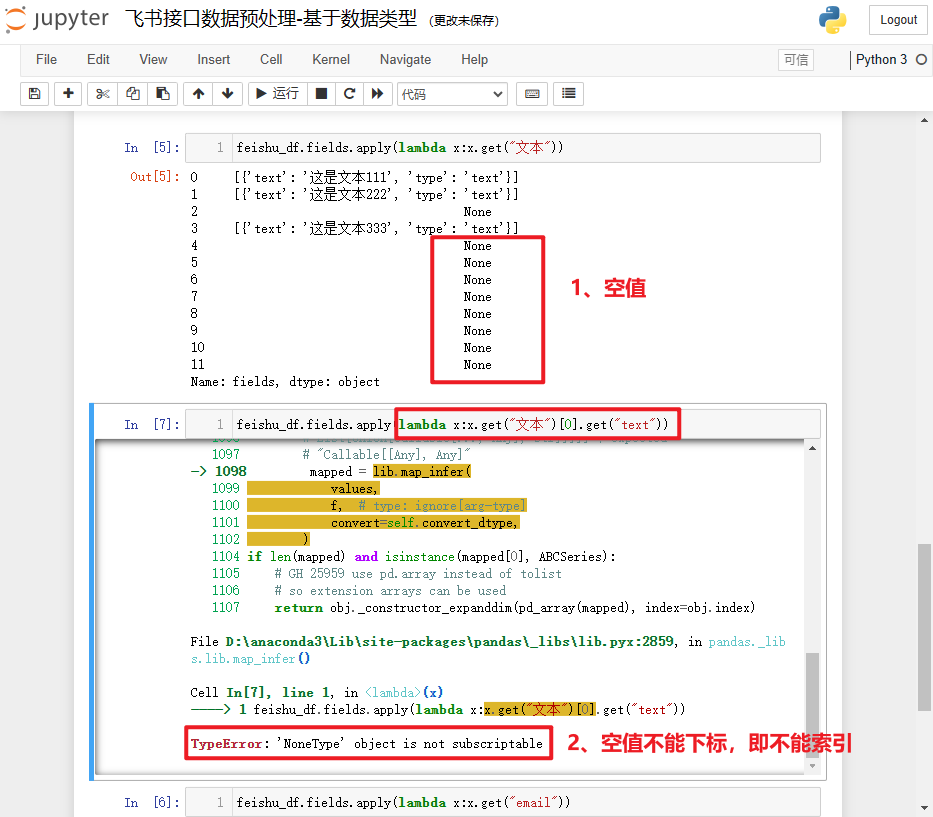
解决该问题,其实很简单,填充一个默认值即可,这个填充是在get()传递第二个参数,而不是对 pandas 列进行填充。该参数需要根据后面取值的结构进行适配,这里后面通过索引取一次,再根据键取一次,索引需要给一个嵌套字典的列表结构,即[{}]。
顺带说一下,为什么要使用
x.get("文本"),而不使用x["文本"]?
第一,前者兼容空值,即使是空值也不会报错,而是返回 None,后者则直接报错找不到对应的键;
第二,前者可以传递第二个参数,当对象是空值时,返回该参数,从而支持后续再次取值。
当然,对 pandas 列进行空值填充也是一种方案。代码示例如下:
feishu_df.fields.apply(lambda x:x.get("文本", [{}])[0].get("text"))
结果参考如下: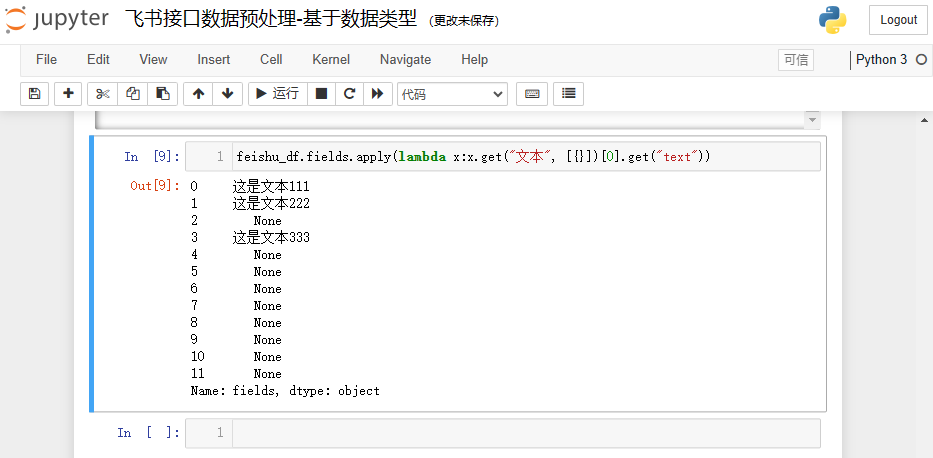
同理,可以对 Email邮箱 类型的列做同样的处理,将列名进行修改即可,示例如下: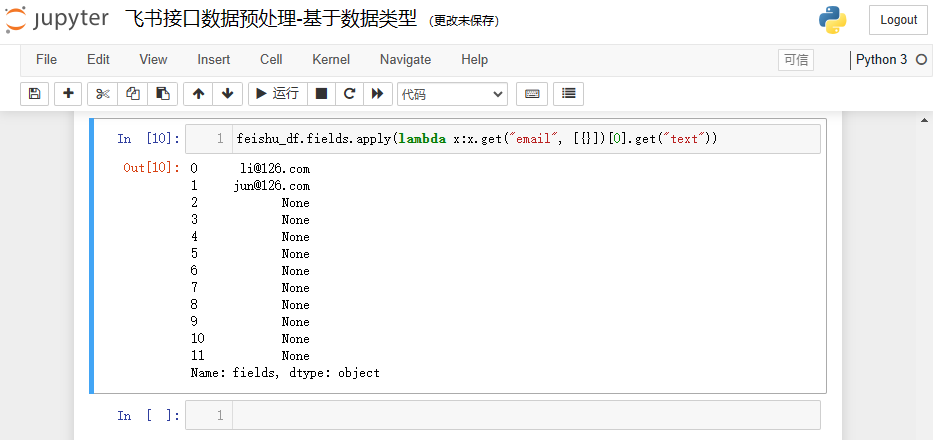
2.3.2 单选、电话号码、自动编号
单选、电话号码、自动编号这三者的数据结构类型类似,直接取列值即可,直接使用get()方法,可以不用考虑空值的问题。
| 数据类型编码 | 数据类型中文描述 | 数据类型对应英文描述 | 数据示例 |
|---|---|---|---|
| 3 | 单选 | SingleSelect | “单选”: “单选11” |
| 13 | 电话号码 | Phone | “电话号码”: “13549857286” |
| 1005 | 自动编号 | AutoNumber | “自动编号”: “1” |
参考如下
feishu_df.fields.apply(lambda x:x.get("单选"))
feishu_df.fields.apply(lambda x:x.get("电话号码"))
feishu_df.fields.apply(lambda x:x.get("自动编号"))
结果如下: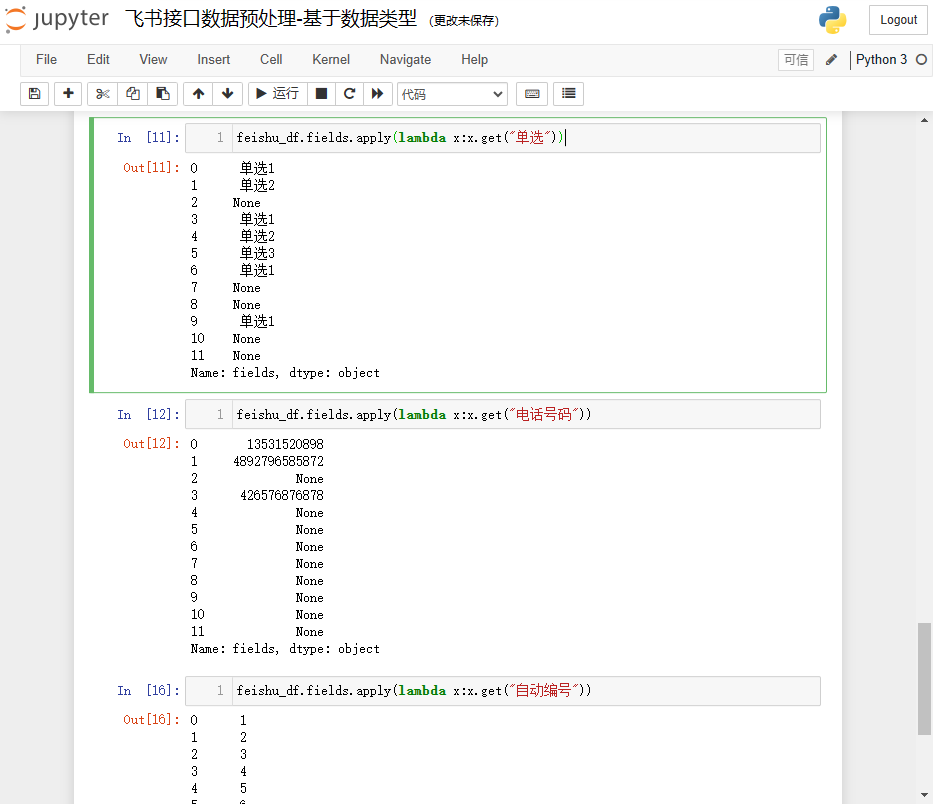
2.3.3 人员、群组、创建人、修改人
人员、群组、创建人、修改人这四者的数据结构类型类似,取值方法也打通小异。我们这里保留“name”的值,你可以根据实际的应用场景判断,是否改为保留“id”的值,或者二者都需要等。
| 数据类型编码 | 数据类型中文描述 | 数据类型对应英文描述 | 数据示例 |
|---|---|---|---|
| 11 | 人员 | User | “人员”: [{“email”: “”,“en_name”: “user1”,“id”: “ou_4007a8a82cc6e0874524edda12ce94b1”,“name”: “user1”}] |
| 23 | 群组 | GroupChat | “群组”: [{“avatar_url”: “https://s1-imfile.feishucdn.com/static-resource/avatar/default-avatar_9fb72564-d52a-49b0-9de8-f79071a02286_96.webp”,“id”: “oc_8b6ac124bd908dce5c5facfb41c4dd4e”,“name”: “(无主题)”}] |
| 1003 | 创建人 | CreatedUser | 同人员 |
| 1004 | 修改人 | ModifiedUser | 同人员 |
处理方式和文本类似,参考代码如下:
feishu_df.fields.apply(lambda x:x.get("人员1", [{}])[0].get("name"))
feishu_df.fields.apply(lambda x:x.get("群组1", [{}])[0].get("name"))
feishu_df.fields.apply(lambda x:x.get("创建人", [{}])[0].get("name"))
feishu_df.fields.apply(lambda x:x.get("修改人", [{}])[0].get("name"))
结果如下: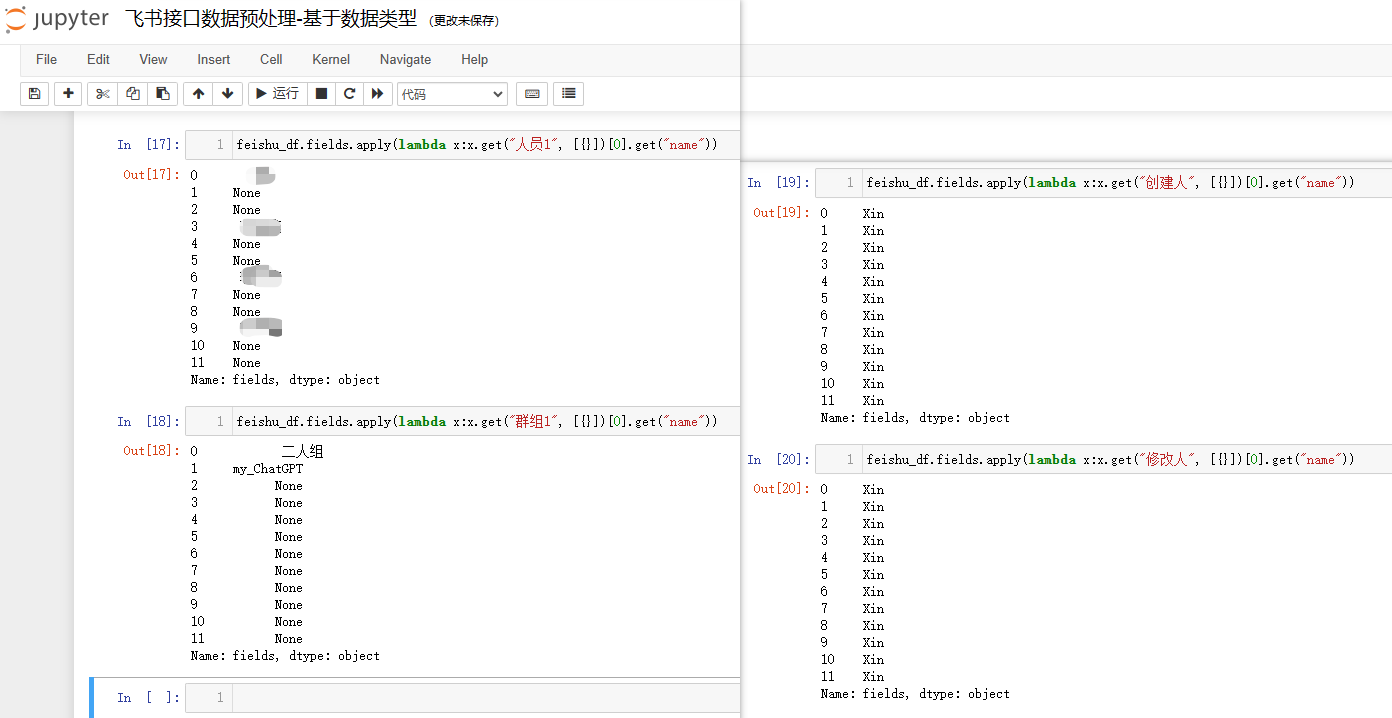
上面是单值的情况,如果是多值,还需要进行遍历取值。对于多值的情况,此处我的处理方法是把多个值通过逗号链接起来。比如选择了“张三”和“李四”,处理的结构为:张三,李四。
注意:这里的默认值需要做一层处理,因为 Nonetype 不能使用join()连接,空字符串才可以。
参考处理逻辑如下:
feishu_df.fields.apply(\lambda x: ','.join([val.get("name") for val in x.get("人员2", [{"name":""}])]))
feishu_df.fields.apply(\lambda x: ','.join([val.get("name") for val in x.get("群组2", [{"name":""}])]))
结果如下: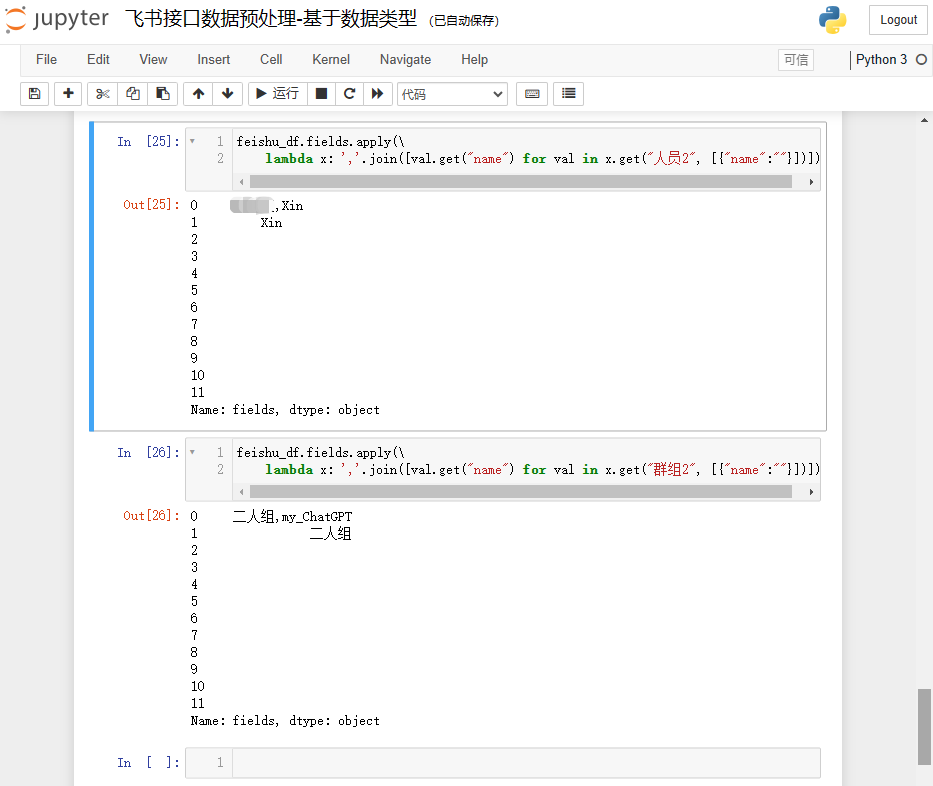
2.3.4 超链接
超链接和文本的取值差不多,只不过少了一层列表的取值,默认填充值也相应去掉列表层。
| 数据类型编码 | 数据类型中文描述 | 数据类型对应英文描述 | 数据示例 |
|---|---|---|---|
| 15 | 超链接 | Url | “超链接”: { “link”: “https://xxx.feishu.cn/base/PtRdbPjCFa5Og5sry0lcD1yPnKg?table=tbl3cvd797CmyEnN&view=vewdFnsmWn”, “text”: “测试数据类型” } |
这里保留原始的链接,即“link”的值,参考代码如下:
feishu_df.fields.apply(lambda x:x.get("超链接",{}).get("link"))
结果如下: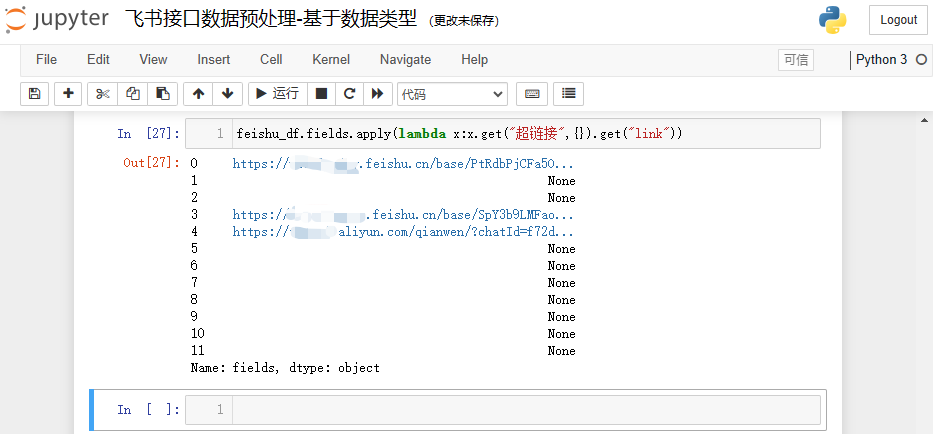
2.3.5 地理位置
地理位置的数据结构和超链接类似,取值方式改下关键字即可。
| 数据类型编码 | 数据类型中文描述 | 数据类型对应英文描述 | 数据示例 |
|---|---|---|---|
| 22 | 地理位置 | Location | “地理位置”: { “address”: “东长安街”, “adname”: “东城区”, “cityname”: “北京市”, “full_address”: “天安门广场,北京市北京市东城区东长安街”, “location”: “116.397755,39.903179”, “name”: “天安门广场”, “pname”: “北京市” } |
这里我保留“full_address”的值,参考代码如下:
feishu_df.fields.apply(lambda x:x.get("地理位置",{}).get("full_address"))
结果如下: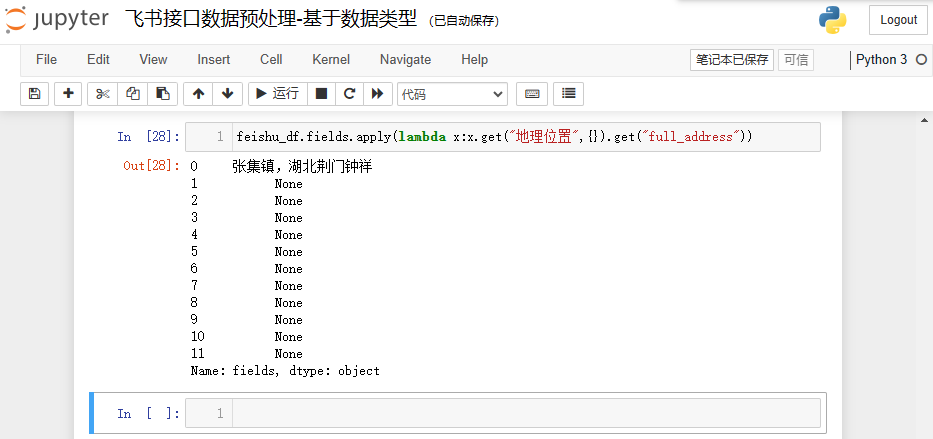
2.4 提取数字与布尔值数据列
2.4.1 数字、进度、货币、评分
数字、进度、货币、评分这四者的数据结构和单选类似,取值是修改一下列名即可。
| 数据类型编码 | 数据类型中文描述 | 数据类型对应英文描述 | 数据示例 |
|---|---|---|---|
| 2 | 数字、进度、货币、评分 | Number,Progress,Currency,Rating | “数字”: 1.33 |
参考代码:
feishu_df.fields.apply(lambda x:x.get("数字"))
feishu_df.fields.apply(lambda x:x.get("进度"))
feishu_df.fields.apply(lambda x:x.get("货币"))
feishu_df.fields.apply(lambda x:x.get("评分"))
结果如下: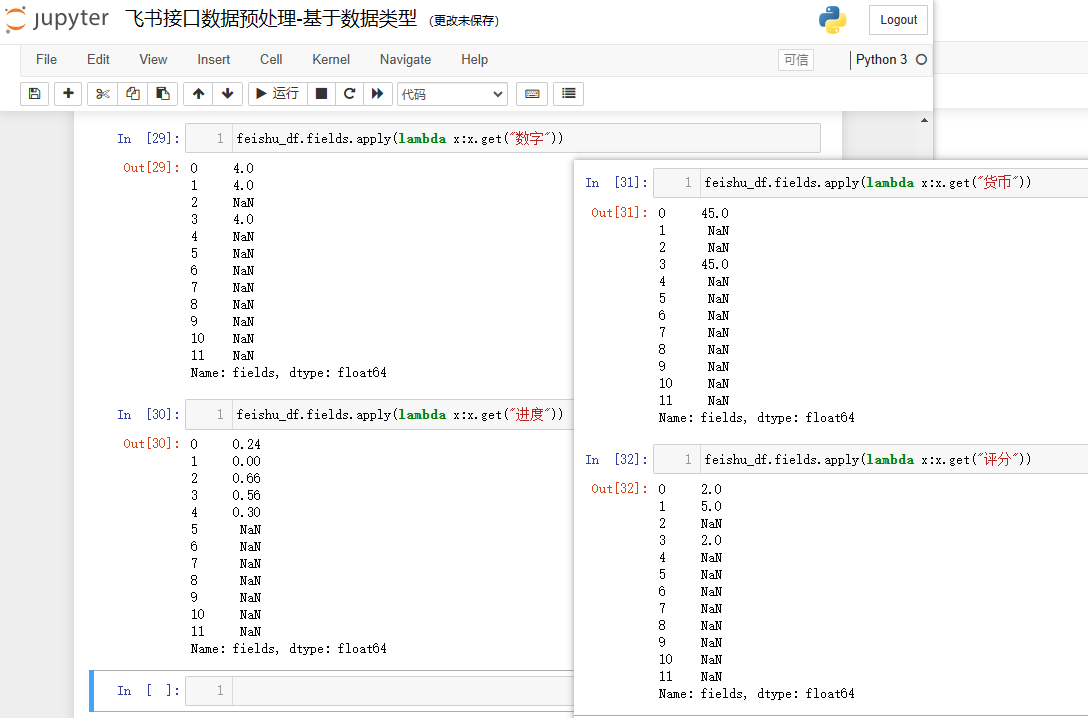
2.4.2 复选框
复选框取值方式和数字的取值方式一样。
| 数据类型编码 | 数据类型中文描述 | 数据类型对应英文描述 | 数据示例 |
|---|---|---|---|
| 7 | 复选框 | Checkbox | “复选框”: true |
参考代码:
feishu_df.fields.apply(lambda x:x.get("复选框"))
结果如下: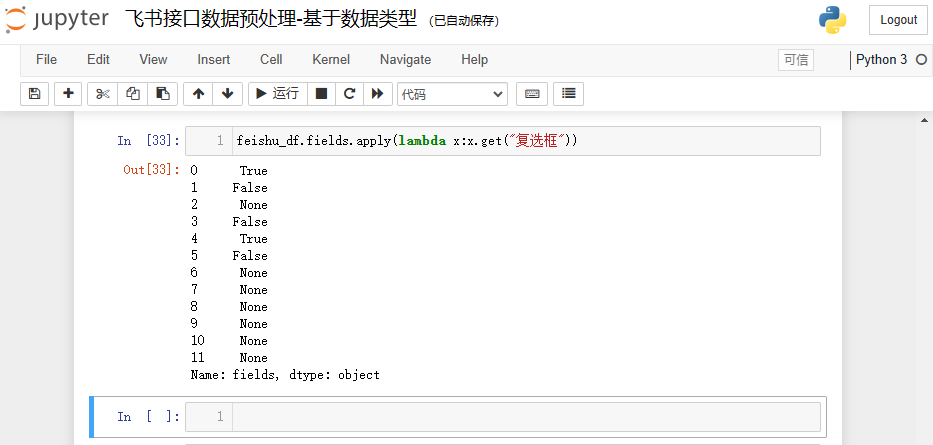
在实际的生产过程中,见到比较多表示布尔值的字段,可能是使用数字 0 和 1 来表示,如果要改为数字,可加一个三元表达式进行判断,参考代码如下:
feishu_df.fields.apply(\lambda x:1 if x.get("复选框") else(None if x.get("复选框") is None else 0))
结果如下: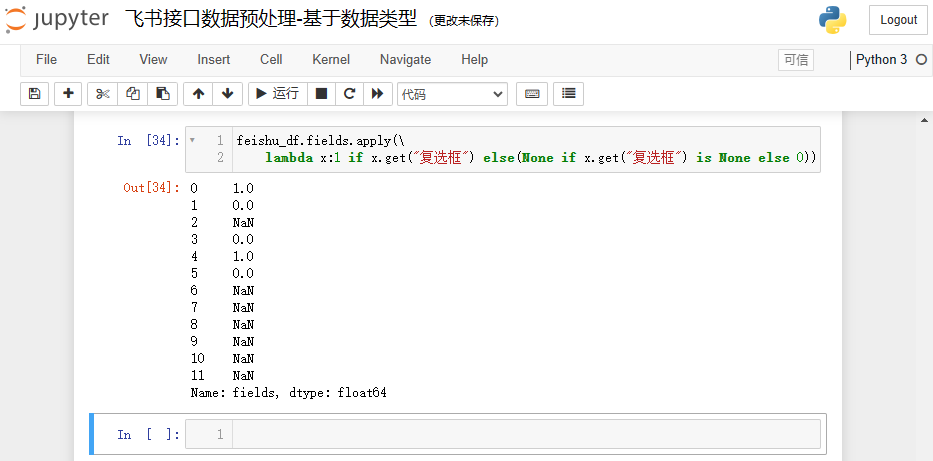
2.5 提取时间数据列
时间列的格式和数字一样,如果直接存时间戳,可以参考数字的取值逻辑,直接取即可,后续在读表的时候再进行格式转换。但是这种方式不够直观,可读性较差,这里我把它转为时间格式:年-月-日 时:分:秒。
| 数据类型编码 | 数据类型中文描述 | 数据类型对应英文描述 | 数据示例 |
|---|---|---|---|
| 5 | 日期 | DateTime | “日期”: 1711900800000 |
| 1001 | 创建时间 | CreatedTime | 同日期 |
| 1002 | 最后更新时间 | ModifiedTime | 同日期 |
由于三者一模一样,这里只取数据类型编码 5 来处理。
处理时间,特别是时间戳的转换,需要特别注意时区的问题。Pandas 默认是 0 时区,所以需要加上 8 小时(28800 秒),由于pd.to_datetime()方法不能处理 NoneType 对象,所以需要给默认值,我这里给 1000(飞书日期列的单位是毫秒,其他值也可以),最终反应为时间格式是“1970-01-01 08:00:01”。
feishu_df.fields.apply(lambda x:28800 + int(x.get('日期',1000)/1000))pd.to_datetime(feishu_df.fields.apply(lambda x:28800 + int(x.get('日期',1000)/1000)),unit='s')
结果如下: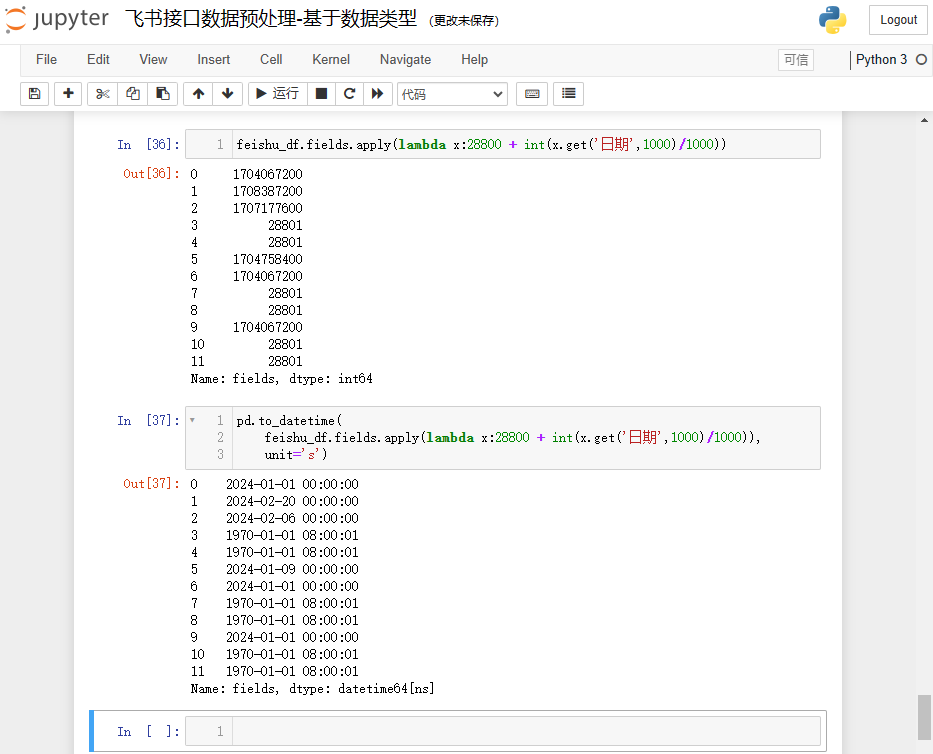
2.6 提取列表格式字符串数据列
注意:这是 json 并不是列表!需要使用 json 库将列表转为 json 格式。
2.6.1 多选
多选列存为列表,直接取列值即可。
| 数据类型编码 | 数据类型中文描述 | 数据类型对应英文描述 | 数据示例 |
|---|---|---|---|
| 4 | 多选 | MultiSelect | “多选”: [“多选11”,“多选22”] |
参考代码:
feishu_df.fields.apply(lambda x:json.dumps(x.get("多选")))
结果如下: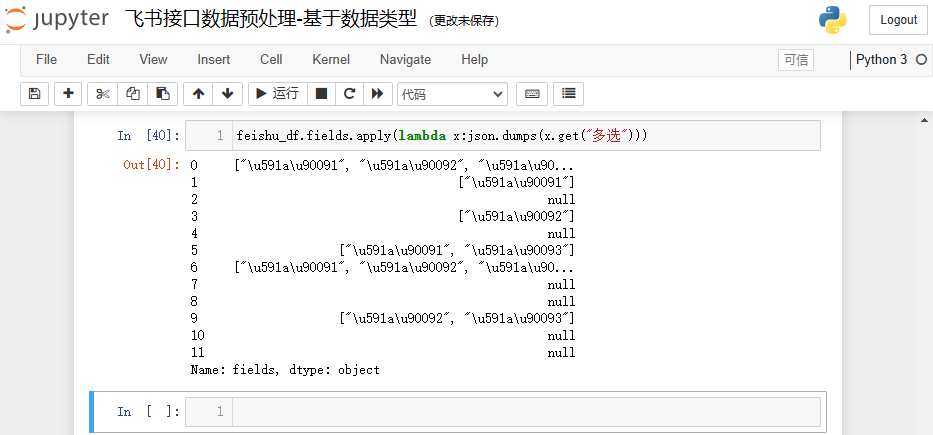
2.6.2 查找引用、公式
查找引用、公式这两个类型由于是可变的,这里暂时保留原数据,处理为列表格式字符串,实际生产过程可以根据列的特性进行定制修改。
| 数据类型编码 | 数据类型中文描述 | 数据类型对应英文描述 | 数据示例 |
|---|---|---|---|
| 19 | 查找引用 | Lookup | “查找引用”: {“type”: 1,“value”: [{“text”: “我是文本1”,“type”: “text”}]} |
| 20 | 公式 | Formula | “公式-数字”: {“type”: 2,“value”: [10]} “公式-文本”: {“type”: 1,“value”: [{“text”: “公式1”,“type”: “text”}]} |
直接取列值,转为字符串即可,参考代码如下:
feishu_df.fields.apply(lambda x:json.dumps(x.get("查找引用数值")))
feishu_df.fields.apply(lambda x:json.dumps(x.get("数字公式")))
结果如下: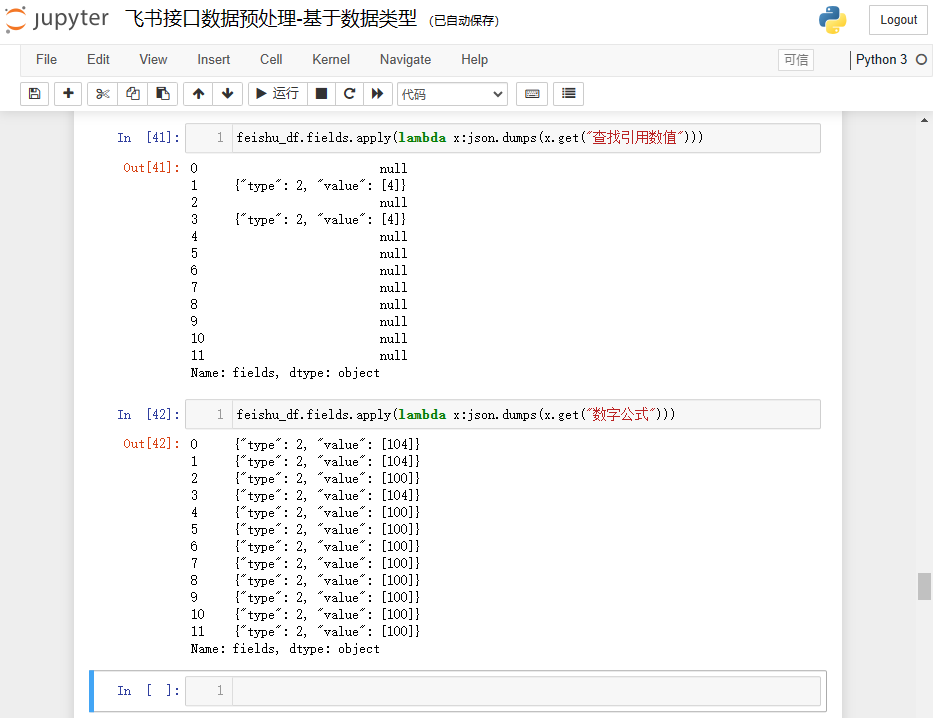
2.6.3 单向关联、双向关联
单向关联、双向关联的列表数据都在“link_record_ids”键中,处理逻辑一样。
| 数据类型编码 | 数据类型中文描述 | 数据类型对应英文描述 | 数据示例 |
|---|---|---|---|
| 18 | 单向关联 | SingleLink | “单向关联”: {“link_record_ids”: [“recuax3DpzWCW4”]} |
| 21 | 双向关联 | DuplexLink | “双向关联”: {“link_record_ids”: [“recuax3DpzWCW4”]} |
单向关联和双向关联会返回默认值{},所以不存在 None 值,get()方法不需要传递第二个参数。
参考代码:
feishu_df.fields.apply(lambda x:json.dumps(x.get("单向关联").get("link_record_ids")))
feishu_df.fields.apply(lambda x:json.dumps(x.get("双向关联").get("link_record_ids")))
结果如下: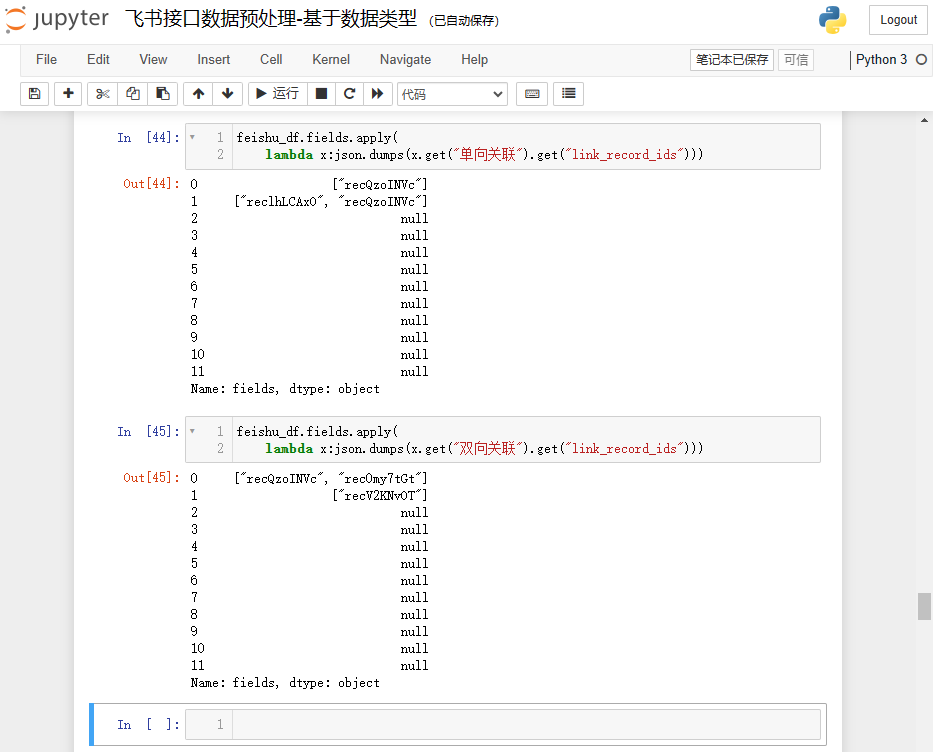
2.6.4 附件
附件可能有一个也可能有多个,其实和人员的取值逻辑差不多,不过这里把它处理为列表格式,存放所有图片的“url”。
注意:由于鉴权的限制,浏览器无法直接展示,需要使用飞书应用调用接口下载完图片才可以查看,在生产应用端的数据分析领域可能都不会使用该字段。
| 数据类型编码 | 数据类型中文描述 | 数据类型对应英文描述 | 数据示例 |
|---|---|---|---|
| 17 | 附件 | Attachment | “附件”: [{ “file_token”: “Cm3Vb8fe4oLPw4xgChZcOa2Mnhe”, “name”: “image.png”, “size”: 956, “tmp_url”: “https://open.feishu.cn/open-apis/drive/v1/medias/batch_get_tmp_download_url?file_tokens=Cm3Vb8fe4oLPw4xgChZcOa2Mnhe”, “type”: “image/png”, “url”: “https://open.feishu.cn/open-apis/drive/v1/medias/Cm3Vb8fe4oLPw4xgChZcOa2Mnhe/download”}] |
参考处理代码如下:
feishu_df.fields.apply(\lambda x: json.dumps([val.get("url") for val in x.get("附件", [{"url":""}])]))
结果如下: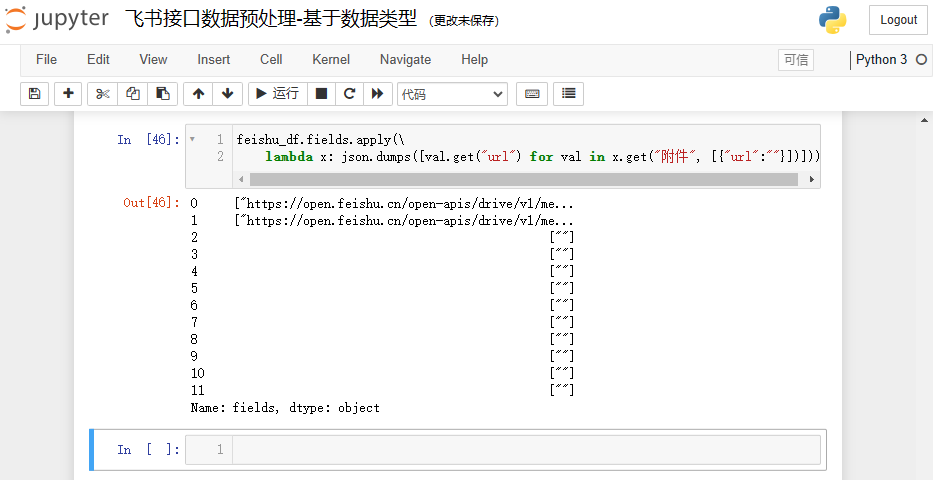
2.7 其他数据列
流程和按钮列没有返回值,所以不需要处理。
| 数据类型编码 | 数据类型中文描述 | 数据类型对应英文描述 | 数据示例 |
|---|---|---|---|
| 24 | 流程 | Stage | 无返回值 |
| 3001 | 按钮 | Button | 无返回值 |
2.8 数据类型预处理小结
目前上面处理好的数据,还没有保存起来,需要在feishu_df创建一个新列,将处理好的数据作为列值插入,后续直接把feishu_df数据入库即可。
创建新列,涉及到一个命名问题,需要给每个列起一个英文名,后续 MySQL 建表参考该英文名进行建表。
结合上面的处理逻辑,在feishu_df新建需要入库的字段,参考代码如下:
feishu_df['field_text'] = feishu_df.fields.apply(lambda x:x.get("文本", [{}])[0].get("text"))
feishu_df['field_email'] = feishu_df.fields.apply(lambda x:x.get("email", [{}])[0].get("text"))
feishu_df['field_select'] = feishu_df.fields.apply(lambda x:x.get("单选"))
feishu_df['field_mobile'] = feishu_df.fields.apply(lambda x:x.get("电话号码"))
feishu_df['field_no'] = feishu_df.fields.apply(lambda x:x.get("自动编号"))
feishu_df['field_member1'] = feishu_df.fields.apply(lambda x:x.get("人员1", [{}])[0].get("name"))
feishu_df['field_group1'] = feishu_df.fields.apply(lambda x:x.get("群组1", [{}])[0].get("name"))
feishu_df['field_creator'] = feishu_df.fields.apply(lambda x:x.get("创建人", [{}])[0].get("name"))
feishu_df['field_modifier'] = feishu_df.fields.apply(lambda x:x.get("修改人", [{}])[0].get("name"))
feishu_df['field_member2'] = feishu_df.fields.apply(\lambda x: ','.join([val.get("name") for val in x.get("人员2", [{"name":""}])]))
feishu_df['field_group2'] = feishu_df.fields.apply(\lambda x: ','.join([val.get("name") for val in x.get("群组2", [{"name":""}])]))
feishu_df['field_url'] = feishu_df.fields.apply(lambda x:x.get("超链接",{}).get("link"))
feishu_df['field_location'] = feishu_df.fields.apply(lambda x:x.get("地理位置",{}).get("full_address"))
feishu_df['field_number'] = feishu_df.fields.apply(lambda x:x.get("数字"))
feishu_df['field_progress'] = feishu_df.fields.apply(lambda x:x.get("进度"))
feishu_df['field_money'] = feishu_df.fields.apply(lambda x:x.get("货币"))
feishu_df['field_rating'] = feishu_df.fields.apply(lambda x:x.get("评分"))
feishu_df['field_bool'] = feishu_df.fields.apply(lambda x:x.get("复选框"))
feishu_df['field_date'] = pd.to_datetime(feishu_df.fields.apply(lambda x:28800 + int(x.get('日期',1000)/1000)),unit='s')
feishu_df['field_createdtime'] = pd.to_datetime(feishu_df.fields.apply(lambda x:28800 + int(x.get('创建时间',1000)/1000)),unit='s')
feishu_df['field_updatedtime'] = pd.to_datetime(feishu_df.fields.apply(lambda x:28800 + int(x.get('更新时间',1000)/1000)),unit='s')
feishu_df['field_mulselect'] = feishu_df.fields.apply(lambda x:json.dumps(x.get("多选")))
feishu_df['field_findnum'] = feishu_df.fields.apply(lambda x:json.dumps(x.get("查找引用数值")))
feishu_df['field_numformula'] = feishu_df.fields.apply(lambda x:json.dumps(x.get("数字公式")))
feishu_df['field_singleunion'] = feishu_df.fields.apply(lambda x:json.dumps(x.get("单向关联").get("link_record_ids")))
feishu_df['field_doubleunion'] = feishu_df.fields.apply(lambda x:json.dumps(x.get("双向关联").get("link_record_ids")))
feishu_df['field_file'] = feishu_df.fields.apply(\lambda x: json.dumps([val.get("url") for val in x.get("附件", [{"url":""}])]))# 查看前3行
feishu_df.head(3)
执行结果如下: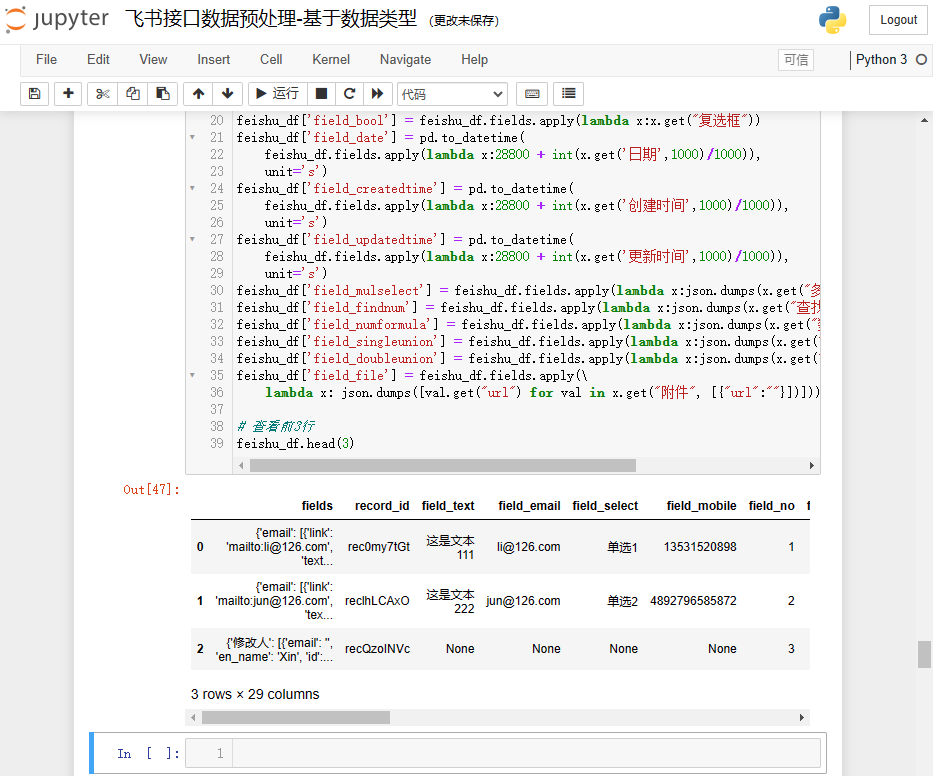
原本feishu_df带有2个列:“fields”和“record_id”,数据列已经解析出来了,可以把“fields”删除,保留“record_id”即可。
feishu_df.drop(['fields'],axis=1,inplace=True)
三、使用 sqlalchemy 写入 MySQL 数据库
为什么使用 sqlalchemy?
- 主要是因为 pandas 可以利用它直接将 DataFrame 数据写入 MySQL 数据库
3.1 MySQL 建表
建表可以在 MySQL 直接创建,也可以通过 Python 调用数据库创建,为了统一处理,此处使用后者。
Python 使用 sqlalchemy 库创建 MySQL 数据表的通用代码结构参考如下,修改 MySQL 的配置,并且传递 SQL 语句即可建表。
from sqlalchemy import create_engine, text# 创建 SQLAlchemy engine 对象,这里以 MySQL 为例
# engine = create_engine('mysql://username:password@host:port/dbname')
engine = create_engine('mysql://root:password@127.0.0.1:3306/test')# 定义一个建表的 SQL 语句
create_table_sql = ''''''# 使用 execute() 方法执行 SQL 语句
with engine.connect() as connection:connection.execute(text(create_table_sql))print('创建成功!')
建表语句:将建表语句传递给create_table_sql变量,执行之后便可以在数据库中建表。
create table if not exists test.feishu_data_type_test(record_id varchar(256) comment '飞书记录id',field_text varchar(256) comment '文本',field_email varchar(256) comment 'email',field_select varchar(256) comment '单选',field_mobile varchar(256) comment '电话号码',field_no varchar(256) comment '自动编号',field_member1 varchar(256) comment '人员1',field_group1 varchar(256) comment '群组1',field_creator varchar(256) comment '创建人',field_modifier varchar(256) comment '修改人',field_member2 varchar(256) comment '人员2',field_group2 varchar(256) comment '群组2',field_url varchar(256) comment '超链接',field_location varchar(256) comment '地理位置',field_number float comment '数字',field_progress float comment '进度',field_money float comment '货币',field_rating float comment '评分',field_bool bool comment '复选框',field_date datetime comment '日期',field_createdtime datetime comment '创建时间',field_updatedtime datetime comment '更新时间',field_mulselect json comment '多选',field_findnum json comment '查找引用数值',field_numformula json comment '数字公式',field_singleunion json comment '单向关联',field_doubleunion json comment '双向关联',field_file json comment '附件'
)
测试结果如下: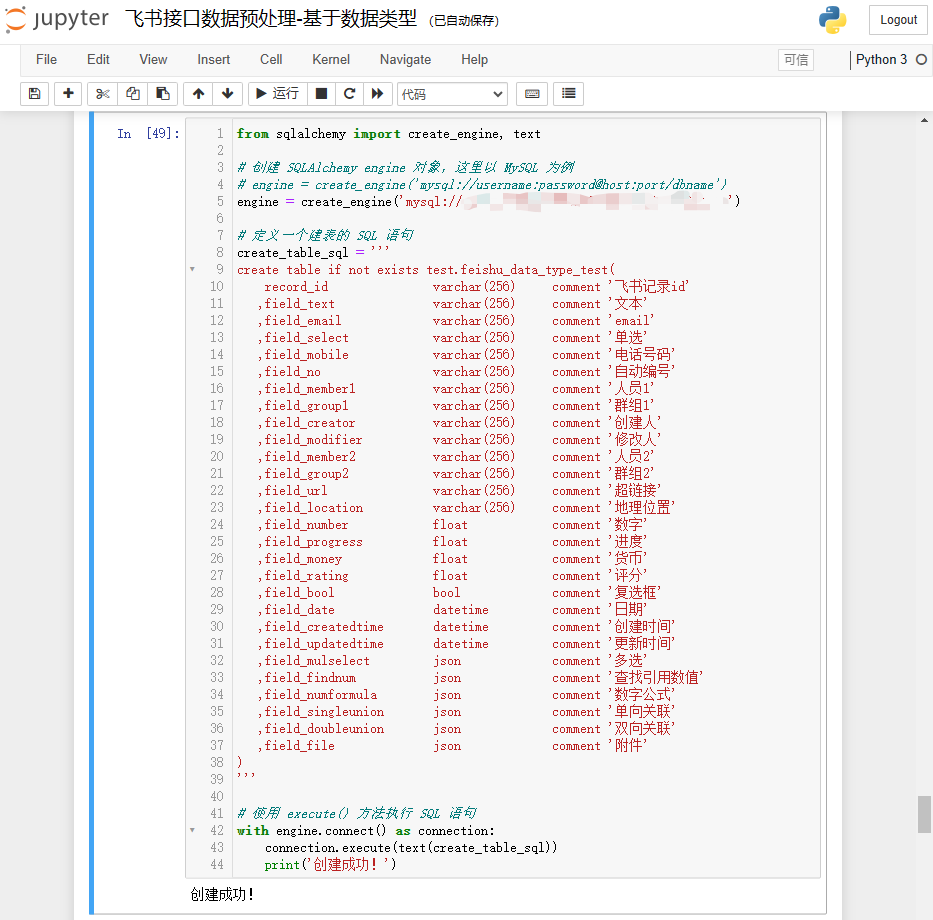
执行之后,可以登录数据库,查看相关的表单信息。截图如下: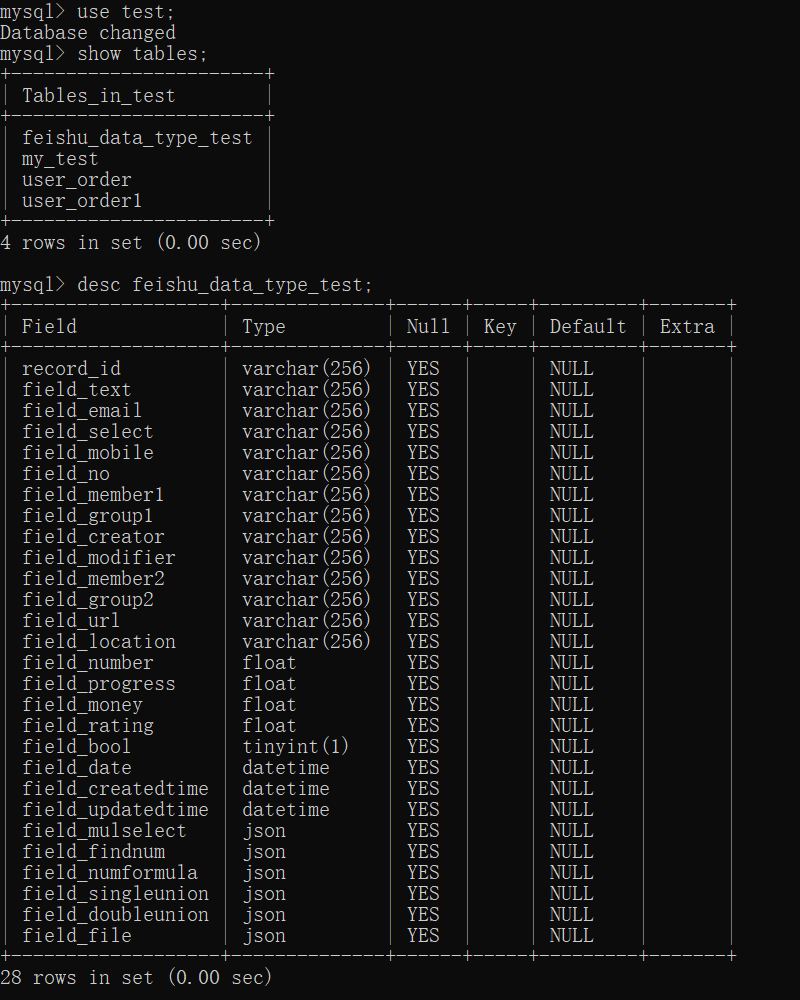
3.2 写入 MySQL 表
pandas.DataFrame.to_sql() 方法可以调用 sqlalchemy 库的 create_engine 模块实现和 MySQL 数据联通,直接将 DataFrame 数据写入 MySQL 中。参考代码如下:
from sqlalchemy import create_engine# 创建 SQLAlchemy engine 对象,这里以 MySQL 为例
# engine = create_engine('mysql://username:password@host:port/dbname')
engine = create_engine('mysql://root:password@127.0.0.1:3306/test')# 将 DataFrame 直接写入 MySQL 数据库
feishu_df.to_sql(name='feishu_data_type_test', con=engine, if_exists='append', index=False)
print('写入成功!')
说明:
- df.to_sql 方法将 DataFrame 写入到数据库中,name 参数指定表名,con 参数指定数据库引擎,if_exists 参数指定了如果表已经存在应该如何处理(例如,‘fail’、‘replace’ 或 ‘append’),index 参数表示是否将 DataFrame 的索引写入数据库,默认为 True,这里设置为 False 表示不保存索引。
- 默认情况下,to_sql 方法基于列名匹配,和顺序无关,即匹配 DataFrame 的列名与数据库表中的列名,所以只要保证 DataFrame 的列名与数据库表中的列名匹配即可。当然了,数据类型也必须兼容如果尝试将一个含有字符串的 DataFrame 列插入到数据库的整数字段中将会报错。
- 如果 if_exists 参数传递“replace”,则会根据 DataFrame 的列重新建表。
执行代码测试结果: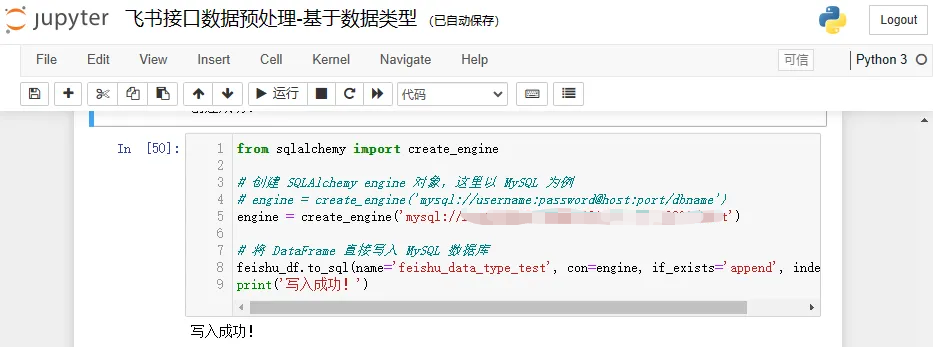
连接数据,查看表数据,截图如下: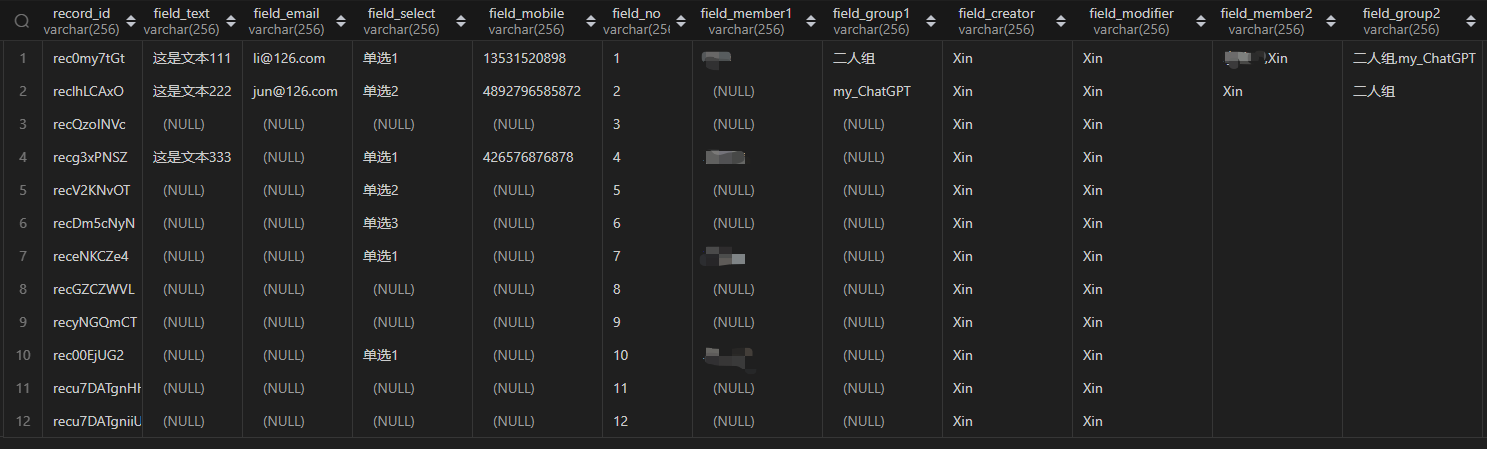

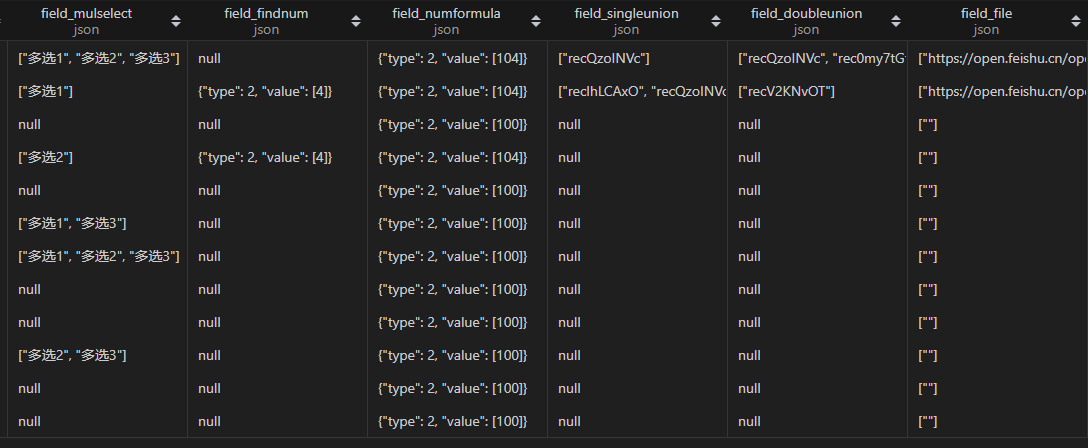
可以看到,所有的数据写入均符合预期!完美!!
四、小结
本文介绍了如何处理飞书的 28 中数据类型,以及通过 sqlalchemy 库将处理好的数据入库。
在探索一个未知的领域时,一般会从个别典型的案例先入手,随着认知的不断深入,逐渐有全局观,便会考虑通用案例,然后在通用案例下,再考虑局部的需求定制。
本文是一个比较全面的案例,更多的是在提供一个解决思路,相关代码的可拓展性较差,下一遍介绍另外一个飞书的 API 读取多维表的元数据来优化可拓展性问题,使得代码变得更加通用。下下篇则在通用的基础上再做定制化需求。
五、附:最终代码
- 在循环取数的代码的基础上新增三个函数
- extract_key_fields(feishu_datas):提取飞书接口数据的关键列
- cre_mysql_table(create_table_sql):在 MySQL 中建表
- insert_mysql_table(feishu_df, table_name):将提取的关键列数据写入 MySQL 数据表
- 注意点:
- 需要修改配置信息,包含 MySQL 的配置信息、飞书的 APP 配置信息、飞书多维表的配置信息。
- 需要修改飞书多维表的列名,对应的英文命名,还有 MySQL 的建表语句
- 目前该代码的可拓展性较差,下一遍介绍另外一个飞书的 API 读取多维表的元数据来优化可拓展性问题,使得代码变得更加通用。
import requests
import json
import pandas as pd
from sqlalchemy import create_engine, textdef get_tenant_access_token(app_id, app_secret):url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"payload = json.dumps({"app_id": app_id,"app_secret": app_secret})headers = {'Content-Type': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)# print(response.text)return response.json()['tenant_access_token']def get_bitable_datas(tenant_access_token, app_token, table_id, page_token='', page_size=20):url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/records/search?page_size={page_size}&page_token={page_token}&user_id_type=user_id"payload = json.dumps({})headers = {'Content-Type': 'application/json','Authorization': f'Bearer {tenant_access_token}'}response = requests.request("POST", url, headers=headers, data=payload)# print(response.text)return response.json()def extract_key_fields(feishu_datas):feishu_df = pd.DataFrame(feishu_datas)feishu_df['field_text'] = feishu_df.fields.apply(lambda x:x.get("文本", [{}])[0].get("text"))feishu_df['field_email'] = feishu_df.fields.apply(lambda x:x.get("email", [{}])[0].get("text"))feishu_df['field_select'] = feishu_df.fields.apply(lambda x:x.get("单选"))feishu_df['field_mobile'] = feishu_df.fields.apply(lambda x:x.get("电话号码"))feishu_df['field_no'] = feishu_df.fields.apply(lambda x:x.get("自动编号"))feishu_df['field_member1'] = feishu_df.fields.apply(lambda x:x.get("人员1", [{}])[0].get("name"))feishu_df['field_group1'] = feishu_df.fields.apply(lambda x:x.get("群组1", [{}])[0].get("name"))feishu_df['field_creator'] = feishu_df.fields.apply(lambda x:x.get("创建人", [{}])[0].get("name"))feishu_df['field_modifier'] = feishu_df.fields.apply(lambda x:x.get("修改人", [{}])[0].get("name"))feishu_df['field_member2'] = feishu_df.fields.apply(\lambda x: ','.join([val.get("name") for val in x.get("人员2", [{"name":""}])]))feishu_df['field_group2'] = feishu_df.fields.apply(\lambda x: ','.join([val.get("name") for val in x.get("群组2", [{"name":""}])]))feishu_df['field_url'] = feishu_df.fields.apply(lambda x:x.get("超链接",{}).get("link"))feishu_df['field_location'] = feishu_df.fields.apply(lambda x:x.get("地理位置",{}).get("full_address"))feishu_df['field_number'] = feishu_df.fields.apply(lambda x:x.get("数字"))feishu_df['field_progress'] = feishu_df.fields.apply(lambda x:x.get("进度"))feishu_df['field_money'] = feishu_df.fields.apply(lambda x:x.get("货币"))feishu_df['field_rating'] = feishu_df.fields.apply(lambda x:x.get("评分"))feishu_df['field_bool'] = feishu_df.fields.apply(lambda x:x.get("复选框"))feishu_df['field_date'] = pd.to_datetime(feishu_df.fields.apply(lambda x:28800 + int(x.get('日期',1000)/1000)),unit='s')feishu_df['field_createdtime'] = pd.to_datetime(feishu_df.fields.apply(lambda x:28800 + int(x.get('创建时间',1000)/1000)),unit='s')feishu_df['field_updatedtime'] = pd.to_datetime(feishu_df.fields.apply(lambda x:28800 + int(x.get('更新时间',1000)/1000)),unit='s')feishu_df['field_mulselect'] = feishu_df.fields.apply(lambda x:json.dumps(x.get("多选")))feishu_df['field_findnum'] = feishu_df.fields.apply(lambda x:json.dumps(x.get("查找引用数值")))feishu_df['field_numformula'] = feishu_df.fields.apply(lambda x:json.dumps(x.get("数字公式")))feishu_df['field_singleunion'] = feishu_df.fields.apply(lambda x:json.dumps(x.get("单向关联").get("link_record_ids")))feishu_df['field_doubleunion'] = feishu_df.fields.apply(lambda x:json.dumps(x.get("双向关联").get("link_record_ids")))feishu_df['field_file'] = feishu_df.fields.apply(\lambda x: json.dumps([val.get("url") for val in x.get("附件", [{"url":""}])]))feishu_df.drop(['fields'],axis=1,inplace=True)return feishu_dfdef cre_mysql_table(create_table_sql):# from sqlalchemy import create_engine, text# 创建 SQLAlchemy engine 对象,这里以 MySQL 为例# engine = create_engine('mysql://username:password@host:port/dbname')engine = create_engine('mysql://root:password@127.0.0.1:3306/test')# 定义一个建表的 SQL 语句# create_table_sql = ''''''# 使用 execute() 方法执行 SQL 语句with engine.connect() as connection:connection.execute(text(create_table_sql))print('创建成功!')def insert_mysql_table(feishu_df, table_name):# from sqlalchemy import create_engine# 创建 SQLAlchemy engine 对象,这里以 MySQL 为例# engine = create_engine('mysql://username:password@host:port/dbname')engine = create_engine('mysql://root:password@127.0.0.1:3306/test')# 将 DataFrame 直接写入 MySQL 数据库feishu_df.to_sql(name=table_name, con=engine, if_exists='append', index=False)print('写入成功!')def main():app_id = 'your_app_id'app_secret = 'your_app_secret'tenant_access_token = get_tenant_access_token(app_id, app_secret)app_token = 'your_app_token'table_id = 'your_table_id'page_token = ''page_size = 5has_more = Truefeishu_datas = []while has_more:response = get_bitable_datas(tenant_access_token, app_token, table_id, page_token, page_size)if response['code'] == 0:page_token = response['data'].get('page_token')has_more = response['data'].get('has_more')# print(response['data'].get('items'))# print('\n--------------------------------------------------------------------\n')feishu_datas.extend(response['data'].get('items'))else:raise Exception(response['msg'])# 提取关键字段feishu_df = extract_key_fields(feishu_datas)# MySQL 建表create_table_sql = '''create table if not exists test.feishu_data_type_test(record_id varchar(256) comment '飞书记录id',field_text varchar(256) comment '文本',field_email varchar(256) comment 'email',field_select varchar(256) comment '单选',field_mobile varchar(256) comment '电话号码',field_no varchar(256) comment '自动编号',field_member1 varchar(256) comment '人员1',field_group1 varchar(256) comment '群组1',field_creator varchar(256) comment '创建人',field_modifier varchar(256) comment '修改人',field_member2 varchar(256) comment '人员2',field_group2 varchar(256) comment '群组2',field_url varchar(256) comment '超链接',field_location varchar(256) comment '地理位置',field_number float comment '数字',field_progress float comment '进度',field_money float comment '货币',field_rating float comment '评分',field_bool bool comment '复选框',field_date datetime comment '日期',field_createdtime datetime comment '创建时间',field_updatedtime datetime comment '更新时间',field_mulselect json comment '多选',field_findnum json comment '查找引用数值',field_numformula json comment '数字公式',field_singleunion json comment '单向关联',field_doubleunion json comment '双向关联',field_file json comment '附件')'''cre_mysql_table(create_table_sql)# MySQL 表插入数据table_name = 'feishu_data_type_test'insert_mysql_table(feishu_df, table_name)if __name__ == '__main__':main()