文章目录
- 一、UDP协议
- 1.UDP的传输流程
- 发送方
- 接收方
- 2.UDP协议报文格式:
- 长度受限
- 校验和
- 如何校验:
- CRC算法:循环冗余算法
- md5算法:
- 2.UDP的特点
- 二、开发中常见的自定义格式
- 1.xml(古老)
- 2.json(最流行)
- 3.protobuffer(pb)
- 端口号
一、UDP协议
1.UDP的传输流程
发送方
1.应用层:
QQ应用程序,把用户A输入的“nb woc”,打包成一个应用层的数据报(这个数据报的格式,只有qq的程序员知道)
假设按照这样的格式:
源qq、目的qq、发送时间、发送内容
123456,654321,2024-04-25 12:00,nb woc
这四个字段使用,来分割。这里就构成了一个简单的应用层数据报(字符串拼贴)。
上述描述的规则,就是此处我们约定的应用层协议。应用层协议中,具体用几个字段,字段的顺序,什么分隔符都可以由程序员根据具体的场景和具体的需求来自主决定。
打包完毕之后,就可以把应用层数据报,通过操作系统的API,把数据交给传输层
2.传输层
对刚才的应用层数据,再次进行打包,变成传输层数据报。
本质上还是”字符串拼接“,在刚才的应用层数据基础上,拼贴传输层的报头。
- 传输层的典型协议:TCP, UDP
以UDP为例:一个数据报 = 报头+载荷
UDP报头中最关键的信息就是“源端口”和“目的端口”

进行封装的过程,就是给数据添加更多的“辅助信息”
就相当于快递运送的时候,会进行多次包装(塑封、外层包装、快递盒等等),就可以在包装外面贴上标签信息。同时,打包也可以保护要传输的内容不被破坏。
打包成传输层数据报之后,这个数据又会进一步交给网络层。
3.网络层
在网络层会再次进行封装,打包成网络层数据报,然后交给数据链路层。
IP报头中,最重要的属性是源IP和目的IP
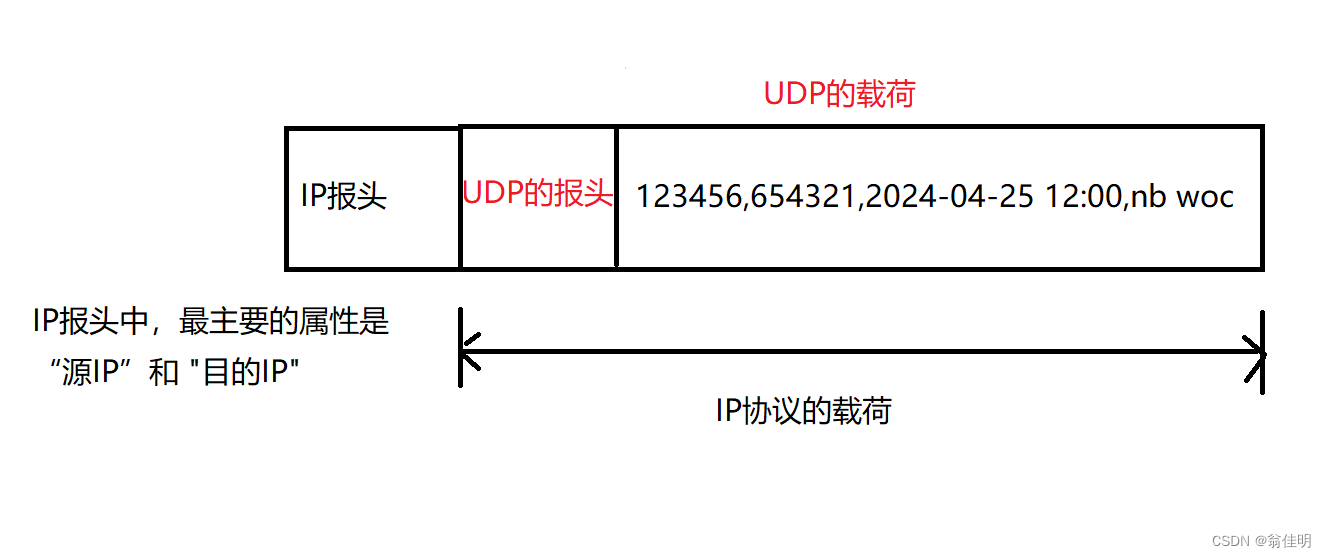
4.数据链路层
会再次打包成以太网的数据报,交给物理层进行传输。
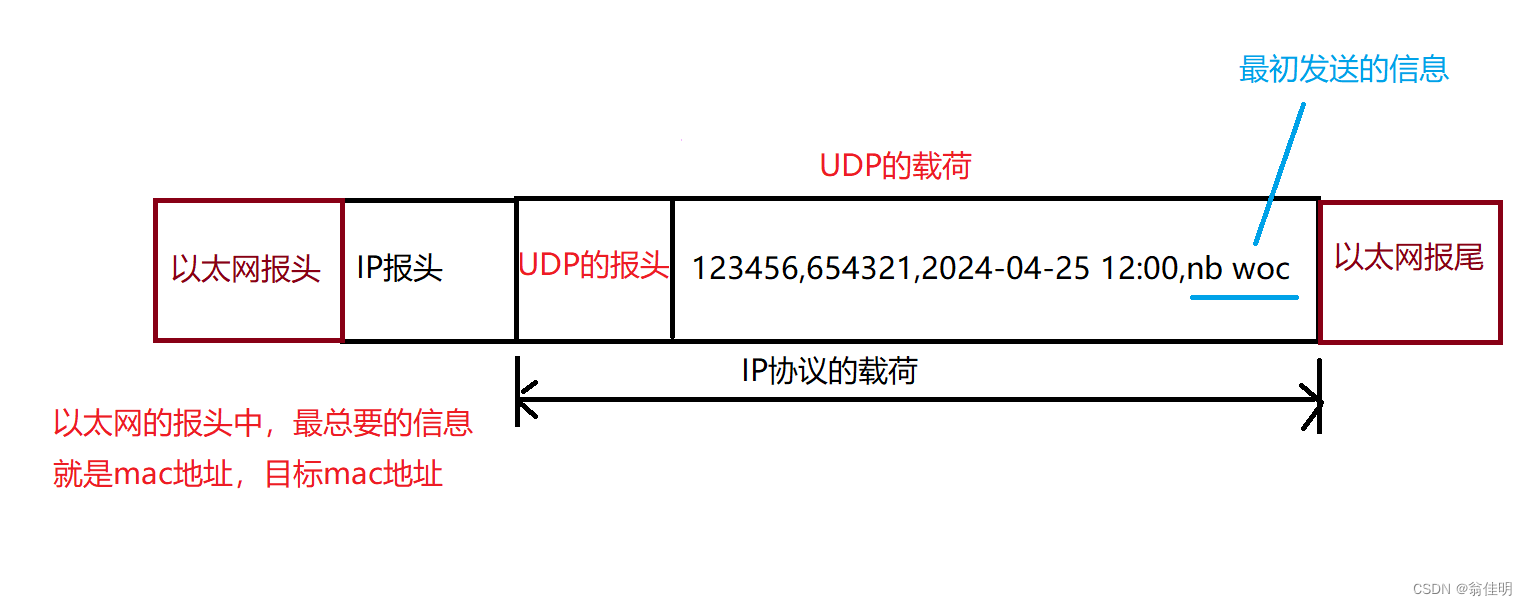
以太网的报头中,最主要的信息就是mac地址 和 目标mac地址。
5.物理层
把上述的数据,转换成二进制的01序列。通过光信号/电信号进行传输。
- 数据的封装:从上层协议到下层协议,层层给数据添加报头。一方面“贴上”辅助信息,来决定后续怎么传输数据。另一方面,可以通过报头来对传输的数据进行校验。就能及时的发现传输过程中的问题。
数据发送出去之后,由于A和B不是通过网线直连的,中间还要经过很多交换机/路由器设备进行转发。
接收方
当数据到达B之后,B就要针对上述数据进行“分用”
对数据报进行层层解析 ->拆快递!
1.物理层
拿到的光电信号转换成二进制数据,得到以太网数据报。交给数据链路层的协议来处理。
2.数据链路层
通过以太网协议,针对以太网数据报进行解析。解析出报头和报尾,以及中间的载荷。把载荷部分交给网络层协议来处理。
3.网络层
通过IP协议,对网络层数据报进行解析,去掉报头,拿到载荷。再进一步把载荷数据交给传输层。
4.传输层
通过UDP协议,针对这个数据报进行解析,去掉报头。把载荷信息交给应用层。
5.应用层
根据端口号,把数据交给QQ应用程序。QQ拿到数据进行解析,解析的方式就是QQ程序员自定义的应用层协议。
取出来nb woc,显示到页面上
实际上,数据报在网络中间还会经历一定的转发过程。如果经过路由器,就会封装分用到网络层。路由器解析到网络层,拿到IP地址后,决定下一步如何进行传输。在下一步传输的时候,又会重新经过网络层、数据链路层和物理层的封装。
如果经过的是交换机,就会封装分用到数据链路层。拿到mac地址来进行下一步的判断。
2.UDP协议报文格式:
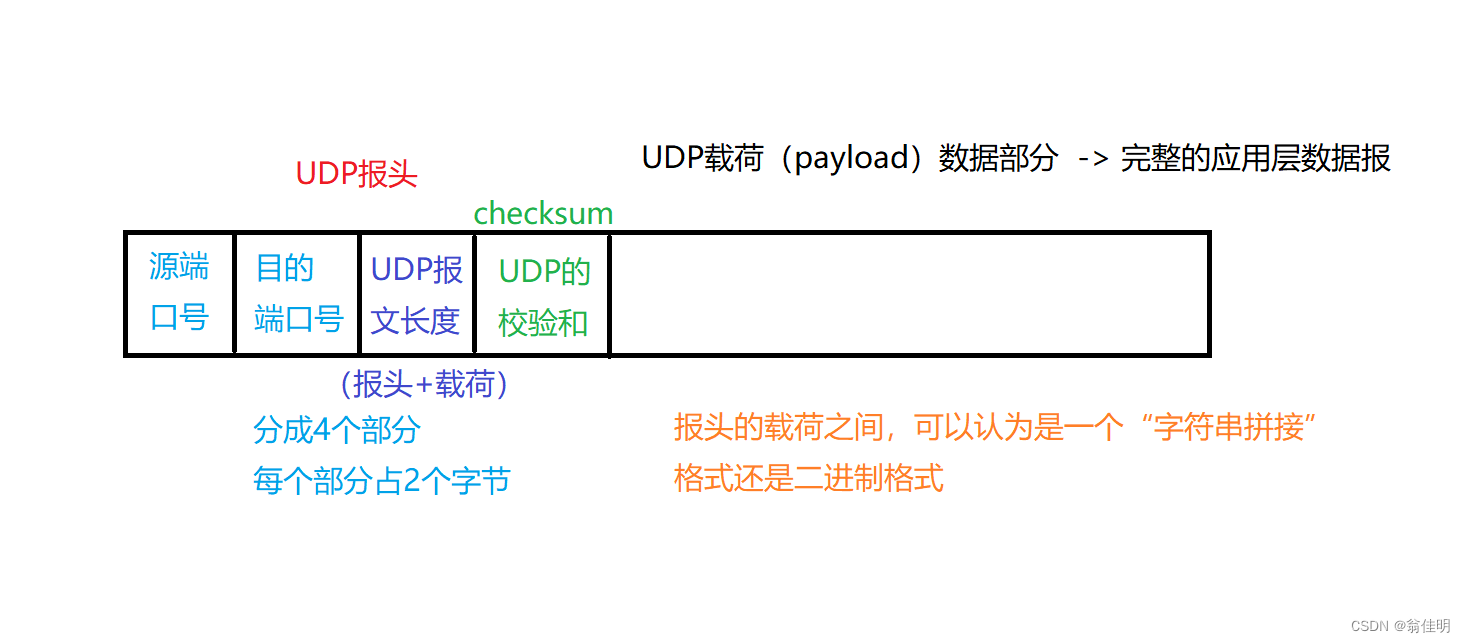
- 源IP,目标IP不在传输层,在网络层的IP协议里
长度受限
- UDP报文长度:2个字节,16位表示的数据(0 ~ 65535 ->64kb)一个UDP数据报最长是64kb.传输的大小有明确的限制。而TCP没有包大小的限制
校验和
本质上也是一个字符串,体积比原始数据更小,又是通过原始的数据生成的。如果原始数据相同,得到的校验和就一定相同。反之,校验和相同,原始数据大概率相同(理论上会有不同情况,概率非常低,可以忽略不计)
网络传输中,由于一些外部干扰,就有可能出现数据传输出错的情况。所以需要有办法能够检测识别出出错的数据。这个手段就是校验和
如何校验:
1.发送方,把要发送的数据整理好(data1),通过一定的算法,计算出校验和checksum1.
2.发送方把data1和checksum1一起通过网络发送出去
3.接收方收到数据,收到的数据称为data2(数据就可能和data1不一样了),也收到了checksum1
4.接收方根据data2,用相同的算法重新计算校验和,得到checksum2
5.对比checksum1==checksum2 ? 大概率相同 :不同 。
- UDP在计算校验和时,采用的是CRC算法
CRC算法:循环冗余算法
把当前要计算校验和的数据,每个字节进行累加。把结果保存在两个字节的变量中。
md5算法:
1.定长。无论原始数据多长,计算的md5,都是固定长度。
2.分散。给定两个原始数据,哪怕绝大部分内容都一样,只要其中一个字节不同,得到的md5的值差异都会很大。
因此,md5也适合作为hash算法
3.不可逆。算容易,还原很难。
2.UDP的特点
1.无连接。UDP协议本身不会存储对端的信息,要在发送数据时,显示指定要传输给谁
DatagramPacket requestPacket = new DatagramPacket(request.getBytes(), request.getBytes().length,InetAddress.getByName(serverIp), serverPort);//把转换字符串ipsocket.send(requestPacket);
2.不可靠,无法得知是否发送成功
3.面向数据报 ,以数据报为单位进行传输。DatagramPacket
4.全双工。通过一个socket,既可以send,也可以receive。
socket.send(requestPacket);//3.尝试读取服务器返回的响应DatagramPacket responsePacket = new DatagramPacket(new byte[4096],4096);socket.receive(responsePacket);
二、开发中常见的自定义格式
应用层和程序员接触最密切,在应用层中,很多时候都是程序员“自定义”应用层协议的。而协议就是一种约定,程序员在代码中规定好,数据如何进行传输
自定义协议:1.根据需求,明确要传输的信息。2.约定好信息按照什么格式来组织
1.xml(古老)
通过标签来组织数据,提高数据的可读性
请求:
<request> <userId>1000</userId><position>100,30</position>
</request>
缺点:标签写起来繁琐,传输的时候也占用更多网络带宽
2.json(最流行)
当下更流行的数据组织格式
- 键值对结构,键固定是字符串类型。值可以是数字、字符串、json、数组等待
{userId:"1000",position:"100,30",
}
优点:可读性好,更简洁
缺点:同样在网络传输中,消耗额外的带宽(需要把key也进行传输)。
除了对于性能要求非常高的场景不使用json,其余的很多地方都可以使用。
开发效率比执行效率更重要
3.protobuffer(pb)
protobuffer使用二进制的方式来组织数据。并且可以保证带宽占用最低。
相当于把要传递的信息按照二进制形式进行了压缩
优点:占用带宽最低,传输效率最高。适应于对性能要求比较高的场景
缺点:二进制格式,可读性不好,降低开发效率
- “现成”的应用层协议:HTTP协议(超文本传输协议)
端口号
写一个服务器,必须手动指定一个端口号。通过端口来区分当前这个主机上的不同应用程序
写一个客户端,客户端在通信的时候也会有一个端口号,是系统自动分配的
端口号在传输层中,固定占2个字节。表示的范围:0~65535。
1 ~1023 称为“知名端口号”:给一些比较”知名“的服务器,预留的位置
22:ssh服务器端口号(ssh协议是用来登录远程主机的)
80:http服务器的端口号
443:https服务器的端口号
1024 ~ 65535 :普通端口号
点击移步博客主页,欢迎光临~