文章目录
- 一、vision transformer(ViT)结构解释
- 二、Patch Embedding部分
- 2.1 图像Patch化
- 2.2 cls token
- 2.3 位置编码(positional embedding)
- 三、Transformer Encoder部分
- (1) Multi-head Self-Attention
- (2) encoder block
- 四、head部分
- 五、vision transformer(ViT)完整代码
- 六、基于vision transformer(ViT)实现猫狗二分类项目实战
一、vision transformer(ViT)结构解释
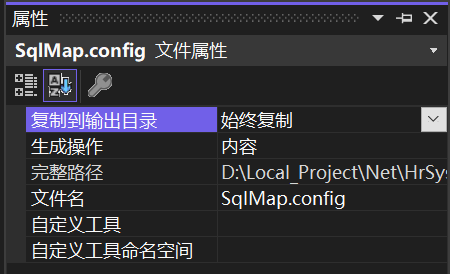
vision transformer(ViT)结构大致流程如下图
+------------+ +--------------+
| Input | ----> | Patch |
+------------+ +--------------+|v+-------+| Embed |+-------+|v+-------------------+| Transformer |+-------------------+|v+-------+| Pool |+-------+|v+-------+| MLP |+-------+|v+-------+| Class|+-------+|vOutputVision Transformrer(ViT)是一种基于自注意力机制的图像分类模型,它试图将图像分类任务转化为自然语言处理中的序列建模问题。与传统的卷积神经网络不同,ViT使用Transformer作为它的基本结构。
ViT的整体结构可以分为两个部分:Patch Embedding和Transformer Encoder。
在Patch Embedding阶段,输入的图像首先被划分为多个小的固定尺寸的图像块,称为patch。每个patch经过一个线性投影层和一个位置编码层得到相应的向量表示。这些向量表示被展平为序列并通过一个可训练的嵌入层得到输入序列。
在Transformer Encoder阶段,输入序列通过多个堆叠的Transformer Encoder层进行处理。每个Transformer Encoder层由多个注意力机制和多层感知机组成。注意力机制用于捕捉全局和局部的上下文信息,通过计算输入序列中不同位置的相互关系来获取注意力权重。多层感知机则用于在每个位置上对向量进行非线性转换。
在ViT的最后,经过多个Transformer Encoder层处理后的序列经过一个全局平均池化层得到固定长度的表示,再通过一个线性分类层进行分类预测。
总的来说,ViT的结构利用自注意力机制,将输入的图像转化为序列,并通过多个Transformer Encoder层对序列进行处理,最后通过全局平均池化和线性分类层得到分类结果。这种结构在图像分类任务上取得了不错的性能,并且能够处理较大尺寸的图像。
二、Patch Embedding部分
Patch Embedding部分主要由(1)图像Patch化(2)cls token(3)positional embeding构成
2.1 图像Patch化

代码实现
# 序列组合位置编码
class PatchEmbed(nn.Module):def __init__(self, input_shape=[224, 224], patch_size=16, in_chans=3, num_features=768, norm_layer=None, flatten=True):super().__init__()# 196 = (224 // 16) * (224 // 16) Patch化self.num_patches = (input_shape[0] // patch_size) * (input_shape[1] // patch_size)# Trueself.flatten = flatten# 注意: kernel_size = stride 才能实现patch之间不相交self.proj = nn.Conv2d(in_chans, num_features, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(num_features) if norm_layer else nn.Identity()def forward(self, x):# Step 1. Patch using Conv2d with 'kernel_size = patch_size'# [1,3,224,224] -> [1,768,14,14]x = self.proj(x)if self.flatten:# x = x.flatten(2).transpose(1, 2) # BCHW -> BNC# Step 2. H*W -> N 宽高维度平铺,形成序列# BCHW -> BCN N = H*W# [1,768,14,14] -> [1,768,196]x = x.flatten(2)# BCN -> BNC 交换1维和2维,即CN transpose一次只能对两个维度进行操作# [1,768,196] -> [1,196,768]x = x.transpose(1, 2)x = self.norm(x)return x
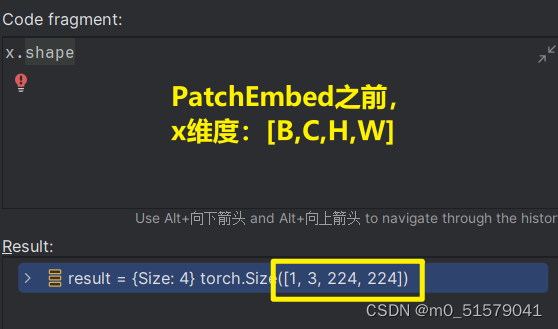
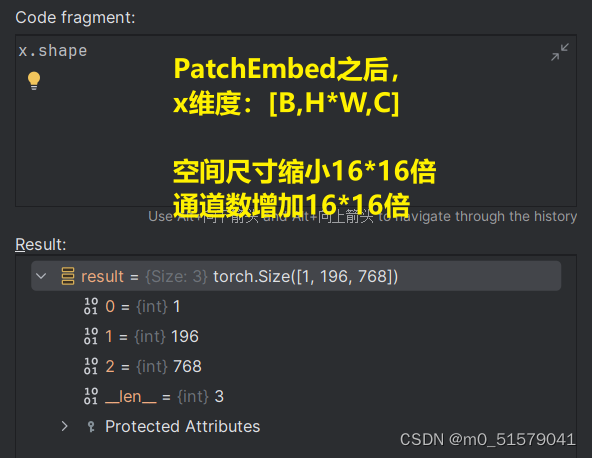
PatchEmbed之后,维度由[1,3,224,224]变为了[1,196,768]
2.2 cls token
在ViT模型中,每个图块都经过一系列的Transformer编码器层,这些编码器层处理图块之间的局部关系。而cls token则是在第一个编码器层的输入中插入的一个特殊令牌。它作为整个图像的表示引入了全局信息。
cls token的计算方式与其他图块的计算方式相同,它经过自注意力机制和前馈神经网络进行特征转换。然后,将经过编码器层处理后的cls token的输出连接到分类器中,用于图像分类任务的最终预测。
cls token的作用是捕捉整个图像的全局特征。因为Transformer模型是一种自注意力模型,并没有显式的全局信息概念,cls token的引入可以将整个图像的特征聚合成一个向量,使得模型具备对整个图像的全局理解能力。这样,模型就可以利用cls token的特征进行分类任务的预测。
代码实现
# [1,1,768]
cls_token = self.cls_token.expand(batch_size, -1, -1)
# H*W+1
# [1,196,768] -> [1,197,768]
x = torch.cat((cls_token, x), dim=1)

cls token之后,维度由[1,196,768]变为了[1,197,768]
2.3 位置编码(positional embedding)
由于ViT是基于自注意力机制(self-attention mechanism)构建的,它无法直接处理序列中项目的顺序信息。
位置编码通常是通过将位置信息转换为向量形式,然后将其添加到输入图像的嵌入表示中来实现的。这样,每个嵌入向量就会包含图像中的位置信息。位置编码的加入可以帮助模型在处理图像时更好地理解不同位置之间的关系,它使得模型能够关注图像中的全局和局部结构,从而更好地对图像进行建模。
总结起来,位置编码在ViT中的作用是引入图像中不同位置的位置关系,以帮助模型理解和处理图像中的全局和局部结构。
代码实现
# [1,196+1,768] -> [1,196,768]
img_token_pe = self.pos_embed[:, 1:, :]# old_feature_shape: [1,196,768] -> [1,14,14,768] -> [1,768,14,14]
img_token_pe = img_token_pe.view(1, *self.old_feature_shape, -1).permute(0, 3, 1, 2)
# new_feature_shape: [1,768,14,14] -> [1,768,14,14]
img_token_pe = F.interpolate(img_token_pe, size=self.new_feature_shape, mode='bicubic', align_corners=False)
# [1,768,14,14] -> [1,14,14,768] -> [1,196,768]
img_token_pe = img_token_pe.permute(0, 2, 3, 1).flatten(1, 2)
# [1,1,768] cat [1,196,768] -> [1,197,768]
pos_embed = torch.cat([cls_token_pe, img_token_pe], dim=1)# Step 4. residual connection + droppath
# [1,197,768] + [1,197,768] -> [1,197,768]
x = self.pos_drop(x + pos_embed)
位置编码(positional embedding)之后,维度还是[1,197,768],没有改变。
三、Transformer Encoder部分
Encoder部分主要由下面流程构成
(1)Multi-head Self-Attention:在Encoder block中,每个patch embedding都会与其他所有patch embeddings进行注意力计算。这种注意力计算将每个patch embedding与其他patch embeddings进行交互,从而使每个patch能够“看到”其他patch的信息。这种注意力计算可以通过独立的多头注意力机制实现,其中每个注意力头都可以学习不同的关注模式。
(2)Layer Normalization:在注意力计算之后,对每个patch embedding进行层归一化操作,以减少信息波动。
(3)Feed-Forward Network:在层归一化之后,通过一个全连接前馈网络,对每个patch的特征进行非线性转换。这个前馈网络可以是多层感知机(MLP),可以通过两个线性变换和一个激活函数来实现。
(4)Residual Connection:Encoder block中的每个操作都有一个残差连接,将输入与输出相加,以保留输入的信息。
(5)Layer Normalization:在前馈网络之后,再次对每个patch embedding进行层归一化操作。
(6)Dropout:为了防止过拟合,可以在Encoder block中应用dropout操作,以随机丢弃一部分特征。
(1) Multi-head Self-Attention
原理参考:【Transformer系列(2)】Multi-head self-attention 多头自注意力
代码实现
# multi-head self-attention
class Attention(nn.Module):def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):super().__init__()# multi-head,这里有点类似分组卷积self.num_heads = num_heads# 尺度self.scale = (dim // num_heads) ** -0.5# qkv通过Linear生成self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)def forward(self, x):# Step 1. get qkv# N=W*HB, N, C = x.shape# [B,N,3,num_heads,C//num_heads] -> [3,B,num_heads,N,//num_heads]qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2]# Step 2. get attention# q*k的转置,再除以根号维度attn = (q @ k.transpose(-2, -1)) * self.scale# softmax就是attentionattn = attn.softmax(dim=-1)# dropout,随机失活attn = self.attn_drop(attn)# Step 3. use attention on v# 注意力乘vx = (attn @ v).transpose(1, 2).reshape(B, N, C)# Linearx = self.proj(x)# dropout,随机失活x = self.proj_drop(x)return x
(2) encoder block
代码实现
# 多个block组成
self.blocks = nn.Sequential(*[Block(dim=num_features,num_heads=num_heads,mlp_ratio=mlp_ratio,qkv_bias=qkv_bias,drop=drop_rate,attn_drop=attn_drop_rate,drop_path=dpr[i],norm_layer=norm_layer,act_layer=act_layer) for i in range(depth)]
)
Transformer Encoder之后,维度还是[1,197,768],没有改变。
四、head部分
head部分,(1)会对encoder输出的[1,197,768]向量进行归一化,(2)然后再取出cls token,(3)再将cls token送入Linear层。
(1)归一化
# [1,197,768]
x = self.norm(x)
(2)取出cls token
# get cls_token 768类似channel
# [1,197,768] -> [1,768]
x= x[:, 0]
维度变化:1,197,768] -> [1,768]
(3)送入Linar层
self.head = nn.Linear(num_features, num_classes) if num_classes > 0 else nn.Identity()
# [1,768] -> [1,2] 2分类问题
x = self.head(x)
维度变化:[1,768] -> [1,2] 2分类问题
五、vision transformer(ViT)完整代码
class VisionTransformer(nn.Module):def __init__(self, input_shape=[224, 224], patch_size=16, in_chans=3, num_classes=1000, num_features=768,depth=12, num_heads=12, mlp_ratio=4., qkv_bias=True, drop_rate=0.1, attn_drop_rate=0.1, drop_path_rate=0.1,norm_layer=partial(nn.LayerNorm, eps=1e-6), act_layer=GELU):super().__init__()# [224, 224, 3] -> [196, 768]# 196 = (224 // 16) * (224 // 16) Patch化后,再平铺# 768 = 16 * 16 * 3 input_channel = 3 HW分别缩放16倍 output_channel拓宽16*16倍self.patch_embed = PatchEmbed(input_shape=input_shape, patch_size=patch_size, in_chans=in_chans,num_features=num_features)# kernel_size = stride# 196 = (224 // 16) * (224 // 16)num_patches = (224 // patch_size) * (224 // patch_size)self.num_features = num_features# new feature shape: [14,14]self.new_feature_shape = [int(input_shape[0] // patch_size), int(input_shape[1] // patch_size)]# old feature shape: [14,14]self.old_feature_shape = [int(224 // patch_size), int(224 // patch_size)]# --------------------------------------------------------------------------------------------------------------------## classtoken部分是transformer的分类特征。用于堆叠到序列化后的图片特征中,作为一个单位的序列特征进行特征提取。## 在利用步长为16x16的卷积将输入图片划分成14x14的部分后,将14x14部分的特征平铺,一幅图片会存在序列长度为196的特征。# 此时生成一个classtoken,将classtoken堆叠到序列长度为196的特征上,获得一个序列长度为197的特征。# 在特征提取的过程中,classtoken会与图片特征进行特征的交互。最终分类时,我们取出classtoken的特征,利用全连接分类。# --------------------------------------------------------------------------------------------------------------------## 196, 768 -> 197, 768# [1,1,768]self.cls_token = nn.Parameter(torch.zeros(1, 1, num_features))# --------------------------------------------------------------------------------------------------------------------## 为网络提取到的特征添加上位置信息。# 以输入图片为224, 224, 3为例,我们获得的序列化后的图片特征为196, 768。加上classtoken后就是197, 768# 196 = (224 // 16) * (224 //16) 768 = 16 * 16 * 3# 此时生成的pos_Embedding的shape也为197, 768,代表每一个特征的位置信息。# --------------------------------------------------------------------------------------------------------------------## 197, 768 -> 197, 768# [1,196,768] -> [1,196+1,768]self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, num_features))self.pos_drop = nn.Dropout(p=drop_rate)# -----------------------------------------------## 197, 768 -> 197, 768 12次# -----------------------------------------------## 0~drop_path_rate的等差数列,12位dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]# 多个block组成self.blocks = nn.Sequential(*[Block(dim=num_features,num_heads=num_heads,mlp_ratio=mlp_ratio,qkv_bias=qkv_bias,drop=drop_rate,attn_drop=attn_drop_rate,drop_path=dpr[i],norm_layer=norm_layer,act_layer=act_layer) for i in range(depth)])self.norm = norm_layer(num_features)self.head = nn.Linear(num_features, num_classes) if num_classes > 0 else nn.Identity()def forward_features(self, x):# Step 1. 序列化:先Patch,再HW平铺# [B,C,H,W] -> BNC N=H*Wx = self.patch_embed(x)# Step 2. 增加cls token# -1:当前维度不拓展# 1batch_size = x.shape[0]# [1,1,768]cls_token = self.cls_token.expand(batch_size, -1, -1)# H*W+1# [1,196,768] -> [1,197,768]x = torch.cat((cls_token, x), dim=1)# Step 3. 位置编码# [1,196+1,768] -> [1,1,768]cls_token_pe = self.pos_embed[:, 0:1, :]# [1,196+1,768] -> [1,196,768]img_token_pe = self.pos_embed[:, 1:, :]# old_feature_shape: [1,196,768] -> [1,14,14,768] -> [1,768,14,14]img_token_pe = img_token_pe.view(1, *self.old_feature_shape, -1).permute(0, 3, 1, 2)# new_feature_shape: [1,768,14,14] -> [1,768,14,14]img_token_pe = F.interpolate(img_token_pe, size=self.new_feature_shape, mode='bicubic', align_corners=False)# [1,768,14,14] -> [1,14,14,768] -> [1,196,768]img_token_pe = img_token_pe.permute(0, 2, 3, 1).flatten(1, 2)# [1,1,768] cat [1,196,768] -> [1,197,768]pos_embed = torch.cat([cls_token_pe, img_token_pe], dim=1)# Step 4. residual connection + droppath# [1,197,768] + [1,197,768] -> [1,197,768]x = self.pos_drop(x + pos_embed)# Step 5. multi-head self_attention# [1, 197, 768]x = self.blocks(x)# Step 6. layers_norm# [1,197,768]x = self.norm(x)# Step 7. get cls_token 768类似channel# [1,197,768] -> [1,768]x= x[:, 0]return xdef forward(self, x):# Step 1~6.# [1,3,224,224] -> [1,768]x = self.forward_features(x)# Step 7. Linear# [1,768] -> [1,2] 2分类问题x = self.head(x)return x
六、基于vision transformer(ViT)实现猫狗二分类项目实战
项目链接:https://download.csdn.net/download/m0_51579041/89255878
数据集链接:https://download.csdn.net/download/m0_51579041/89255922