前提:
快速排序(Quicksort)是对冒泡排序的一种改进。
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
hoare版本的快速排序算法分析与实现 :
hoare大佬的算法思想算是一道硬菜,容易咯牙那种,不如说快速排序所有版本都很有东西。
那么hoare大佬的算法思想是这样的:
有图我就喜欢上:
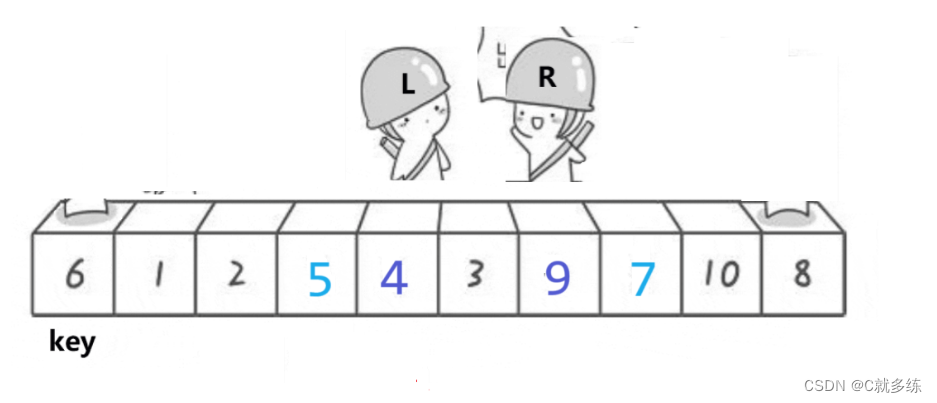
hoare版本的动图:
我们定义的一个基准位key;然后定义两个变量Left和Right,让Right从右向左找比a[key]小的数,让Left从左向右找比a[key]大的数。找到后让Left和Right交换,不断重复上述操作,直到right和left相遇,这时交换a[Left]和a[key](或者a[Right]和a[key]交换也行,毕竟Left和Right处在同一位置);让key的下标更新,这轮操作过后key的左边都比key小,key的右边都比key大。
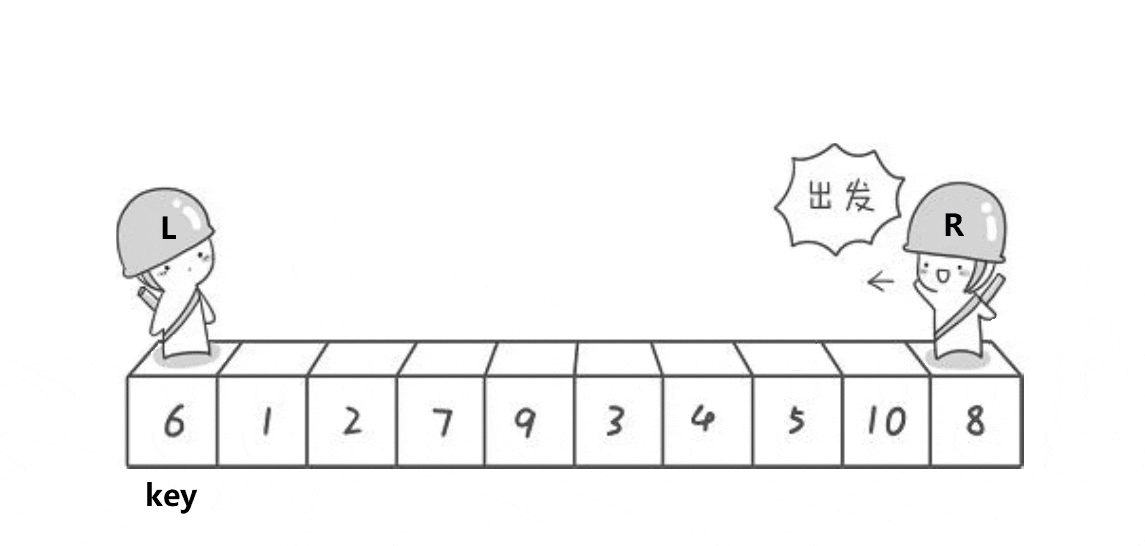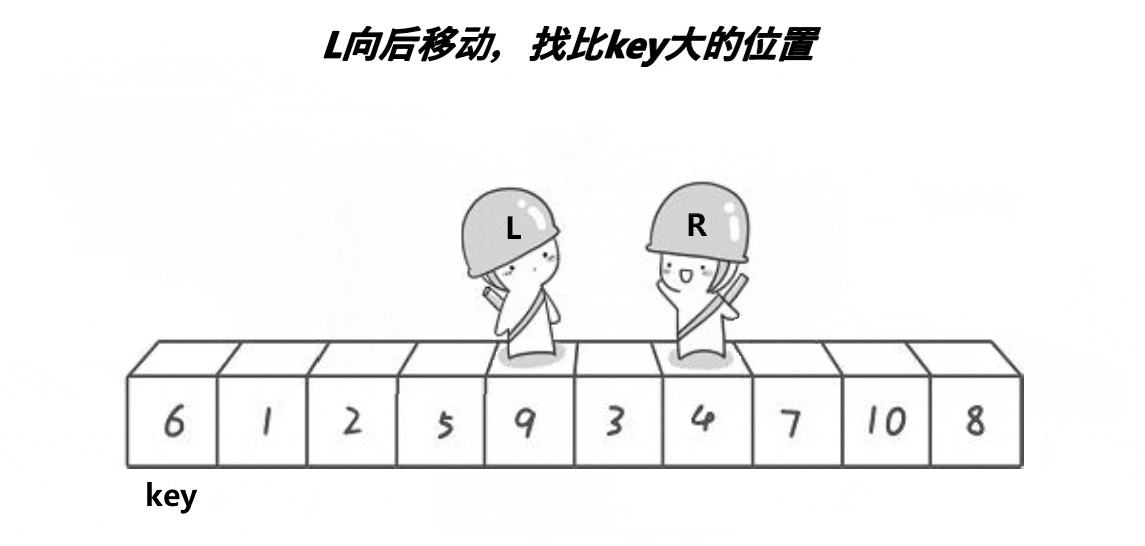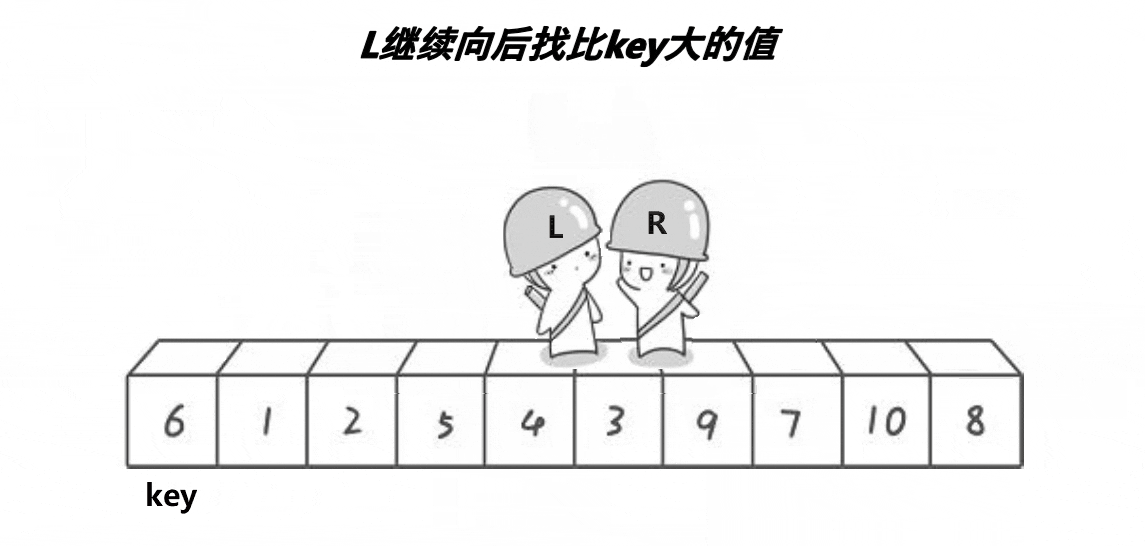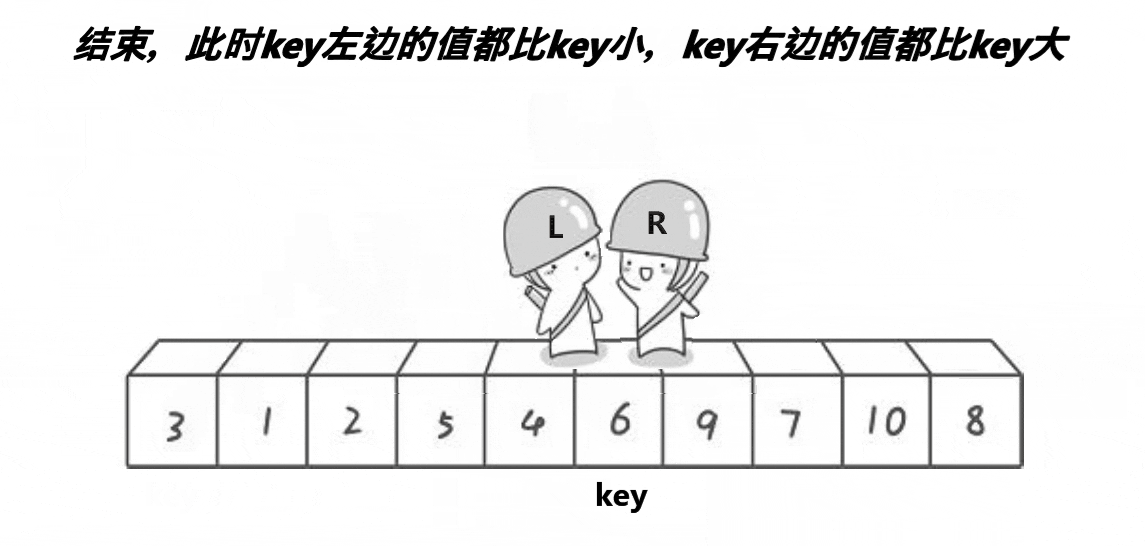
动图有点快,来个详细步骤:
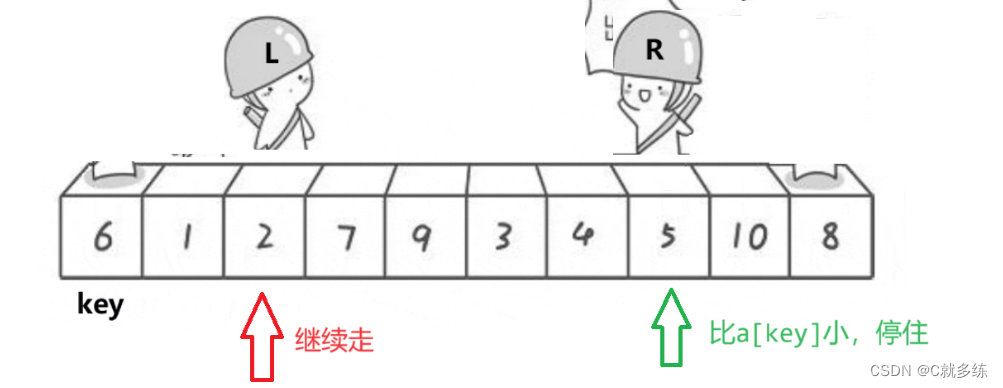
右边先走没找到小,继续走;左边再走,没找到大,继续走;
右边再走,找到小,停住等待交换;
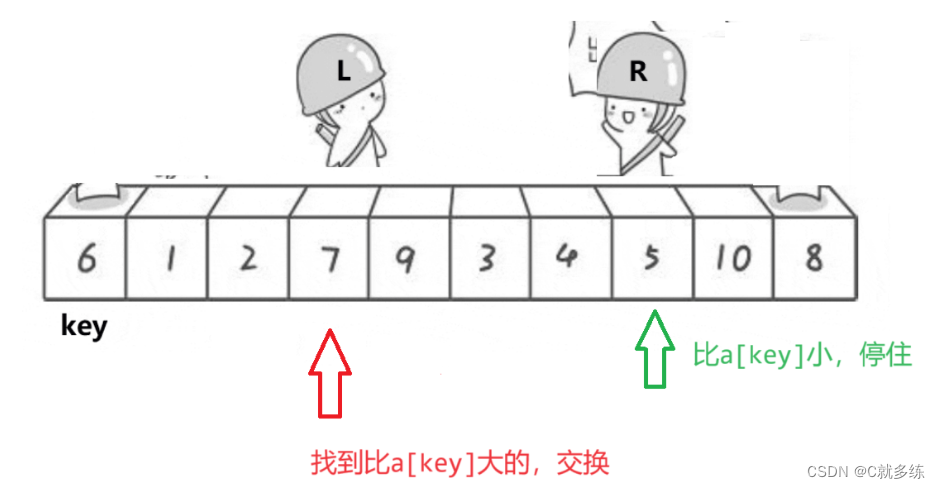
右边已经找到小,左边再走,找到大;二者可以交换;
交换
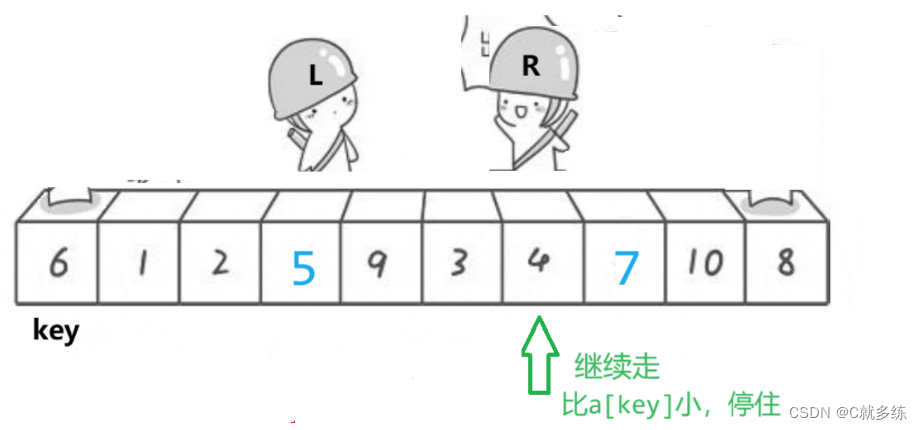
右边继续走,找到小,停住;
右边已经找到小,左边走,找到大;二者可以交换;
交换
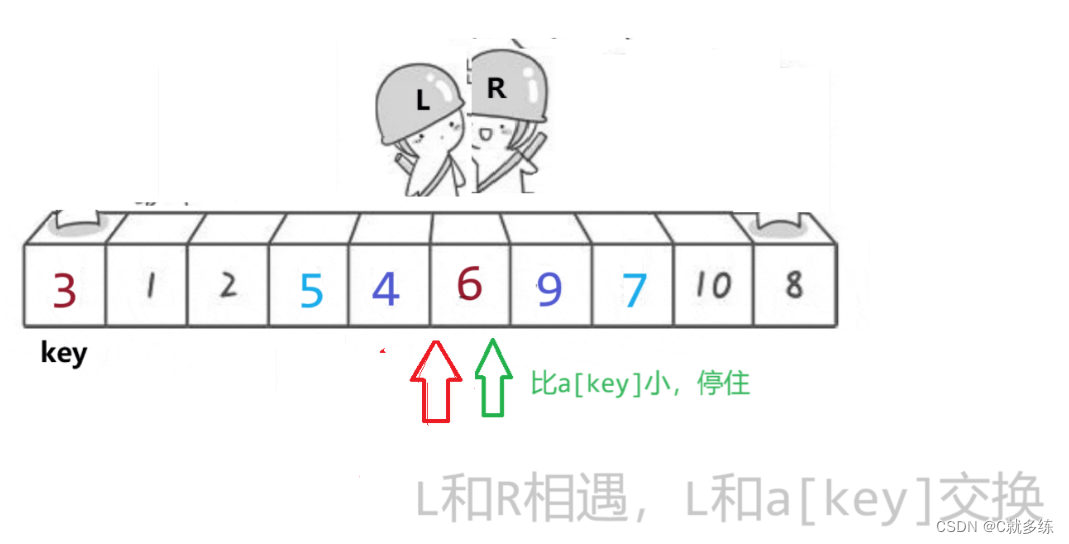
右边再走,找到小,停住;左边走,与R相遇;a[L]和a[key]交换
交换
更新key的位置,本轮操作完成;





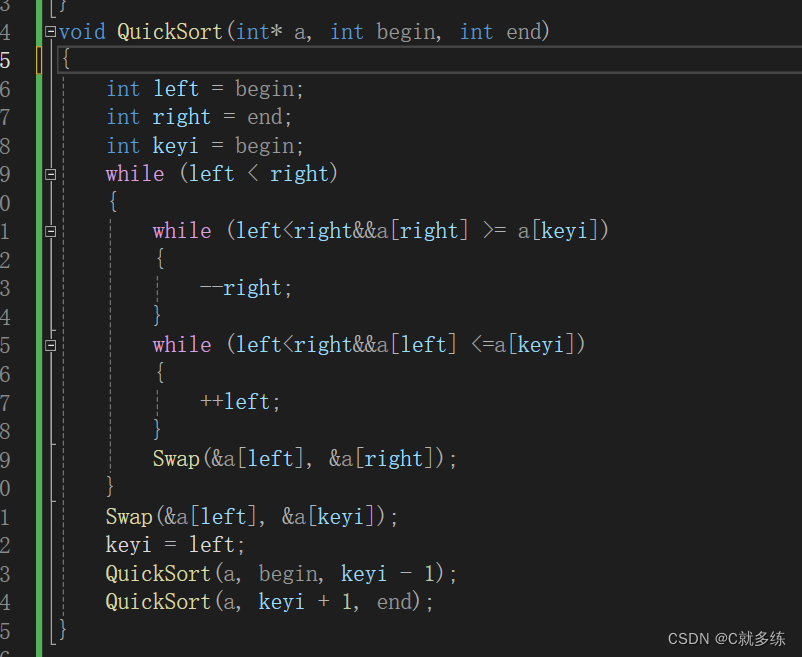
上代码:
我们定义了变量left和right控制遍历;定义变量keyi=begin,确定基准位(基准位有很多选择,一般为了简便选择起始位置)。
然后我们循环遍历序列,让右边先走,没遇到比基准位小的就继续向左走,找到了就停住;左边一样,没找到大继续走,找到就停住;
左右都停住后,就交换。然后继续循环,直到左右相遇,这时外循环结束,交换基准位和left,更新key的位置;
这里需要注意的是,right如果一开始就一直没有找到比a[key]小的数,一直找万一越过了left(这时是a[0])怎么办?这不妥妥的越界?因此我们应该如上图给循环添加限制条件(left<right)防止越界。left也是相同的处理。

上述代码完成后,做到了这个效果:即key的左边都比key小,右边都比key大。

如上图这样,key的左右其实并不有序。我们要做的是快速排序啊?即使是冒泡、直接插入排序排好都是完全有序的,快排难道这么拉吗?
在前提中我们提到了, 快速排序是Hoare于1962年提出的,其基本思想为:任取待排序元素序列中 的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右 子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。所以,实际上快速排序是一种二叉树结构的交换排序方法。而二叉树的一大重点就是递归!
所以要做到完全排序我们应该:
完美的递归思想是不是?

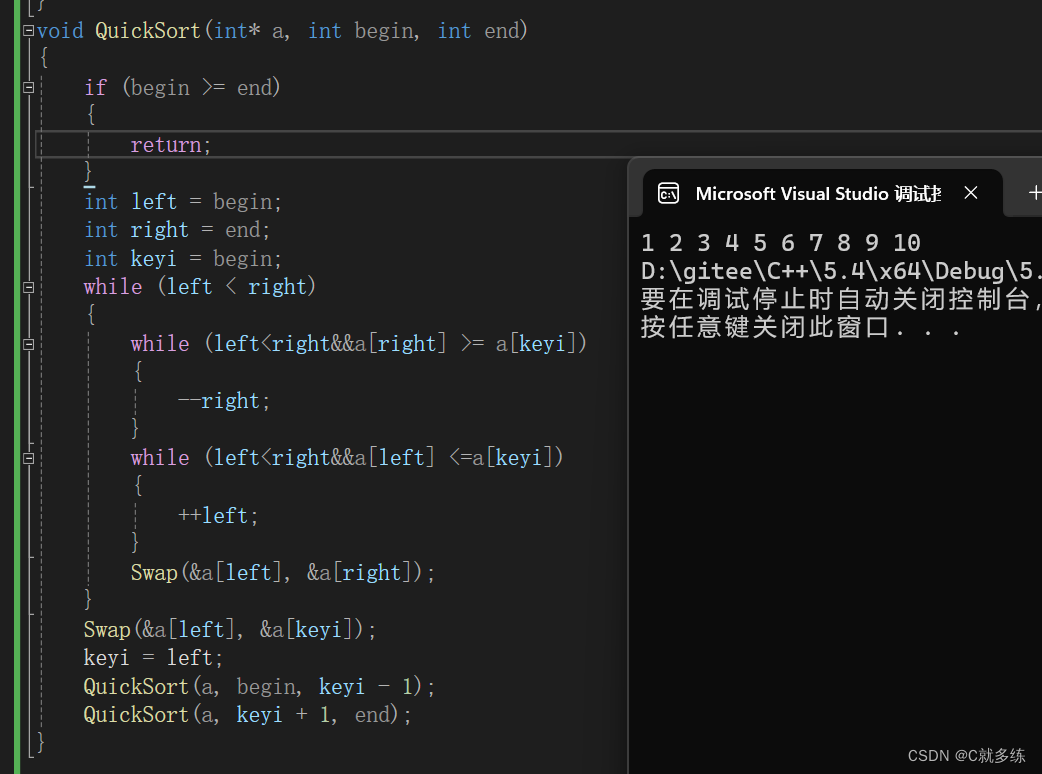
完全排序就结束了,我们试着调试一下:

运行了,有问题。

问题就出在递归上,递归到最后只有一个元素或没有元素(见上面简易递归图),数组发生了越界,所以我们需要特殊处理:
当begin>=end时,说明只有一个元素或为空,这时说明序列有序,直接返回,不要再继续。
这样基本的hoare版本的排序就结束了。

hoare版本的快速排序的小优化:
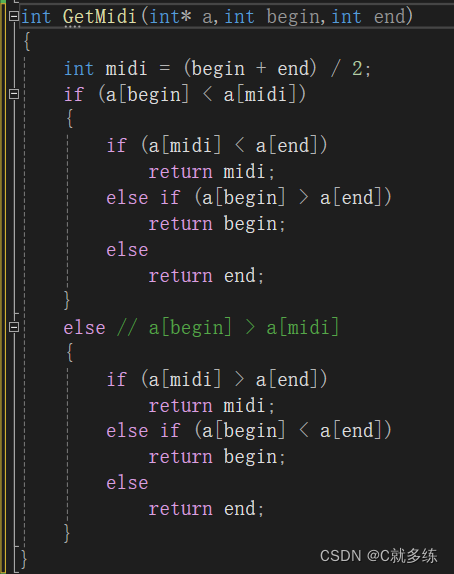
1、三数取中: 
三数取中是一种对快速排序的小优化,目的就是为了使基准数更加的小,提高后面的递归的效率;
话不多说,上代码:
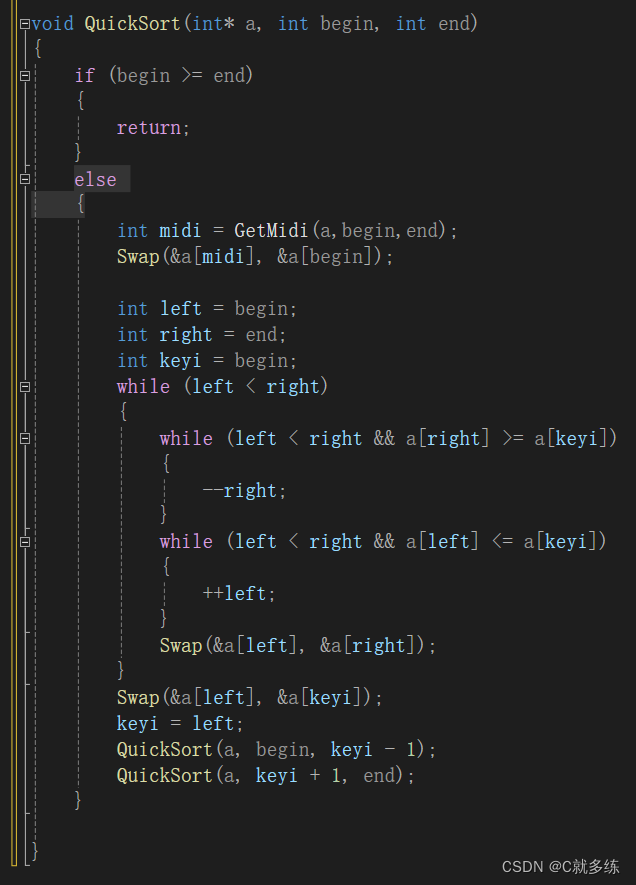
三数取中其实挺好理解的,就是取begin和end的中间值,比较三个数,哪个最小让其成为基准值。
2、小区间优化--直接插入排序优化:
我们学习二叉树时,都知道递归的最后一层占据整个递归的50%左右,倒数第二层25%左右,第三层12.5%左右。因此,如果我们能对最后递归次数最多的几层进行优化,效率会有一定的提升。

这就是快速排序的小区间优化的一种:直接插入排序优化:有不了解直接插入排序的可以看我的博客:排序算法——直接插入排序-CSDN博客
新增的这个判断就是当程序递归到此次,发现要排序的数目<=10,就不要再排序了,直接上直接插入排序(我们知道,直接插入排序对基本有序的序列排序效率是很高的)。

当然,这两种方法都是对直接插入排序的小的优化,甚至可能产生反效果。
直接插入排序的其他思想--挖坑法:
不得不感慨,这个世界总是有大佬不断推动世界推陈出新,挖坑法就是一种针对hoare版本难理解研究出的另一种版本。
挖坑法,顾名思义“挖坑”,它的骚操作是这样的:
1、我们将第一个元素仍设置为基准位,将其中的值保存起来,将第一个位置作为坑位。
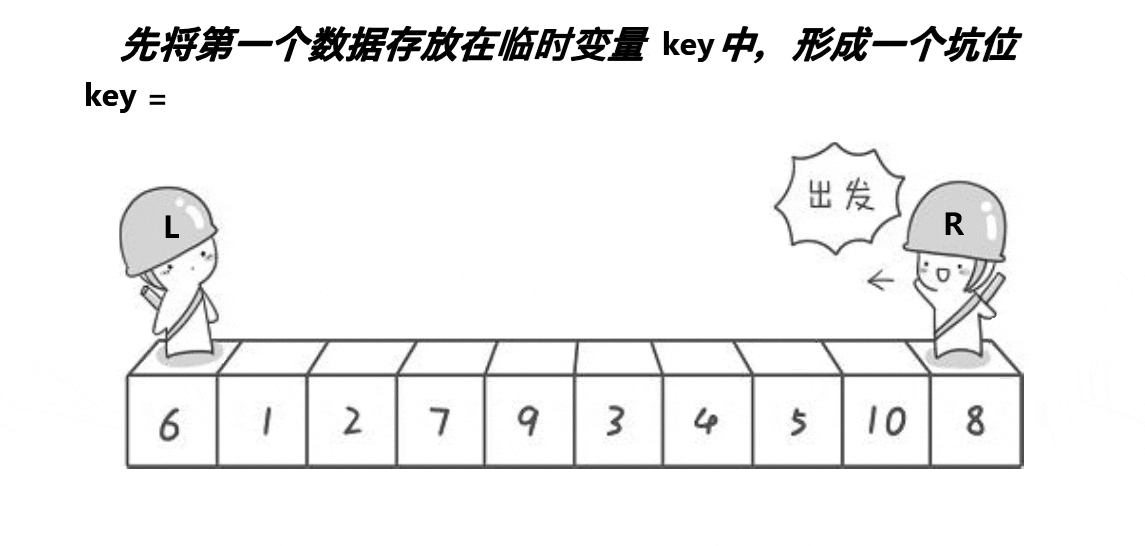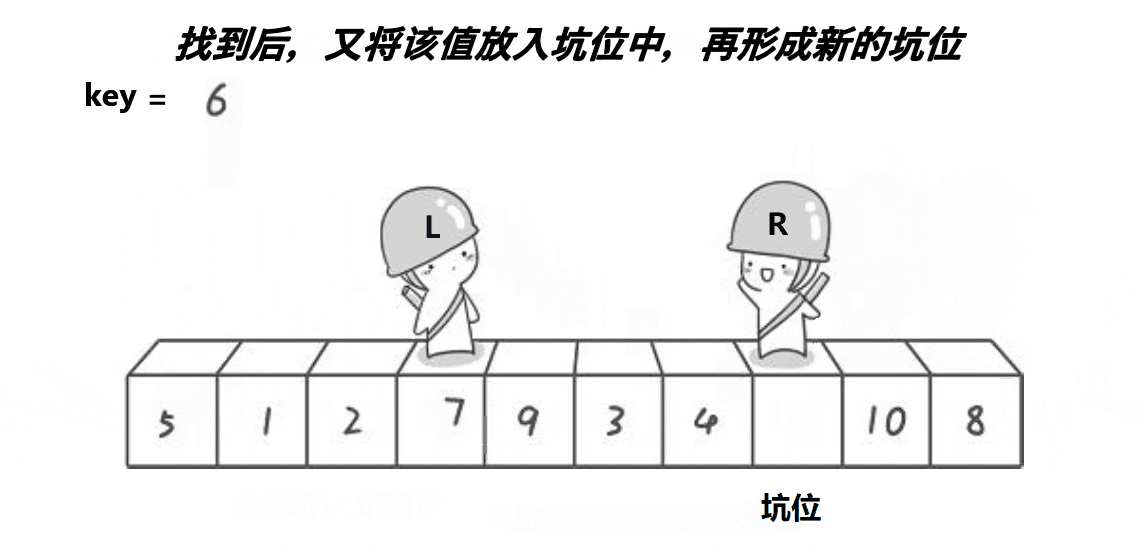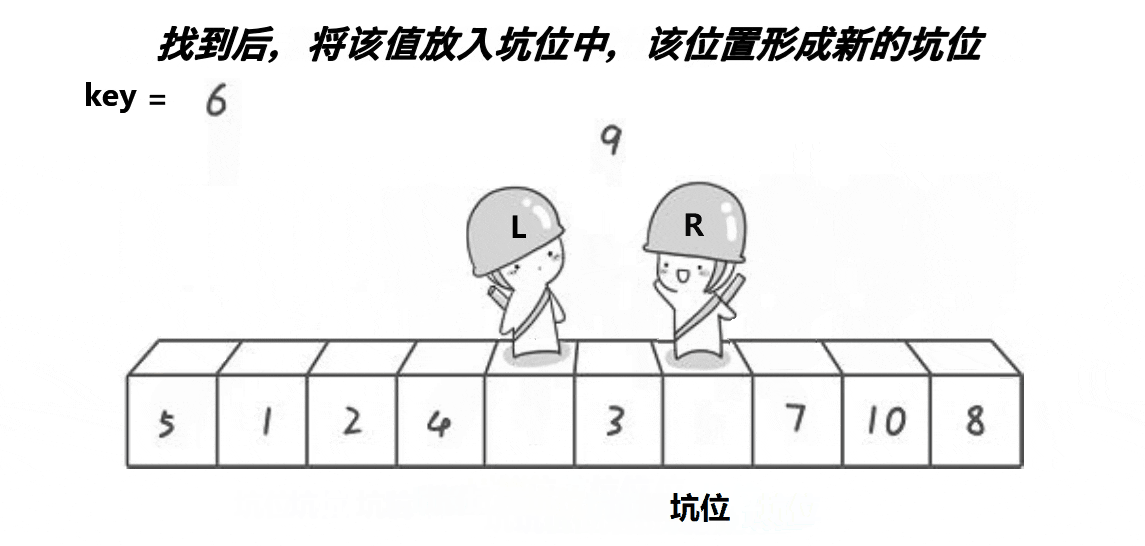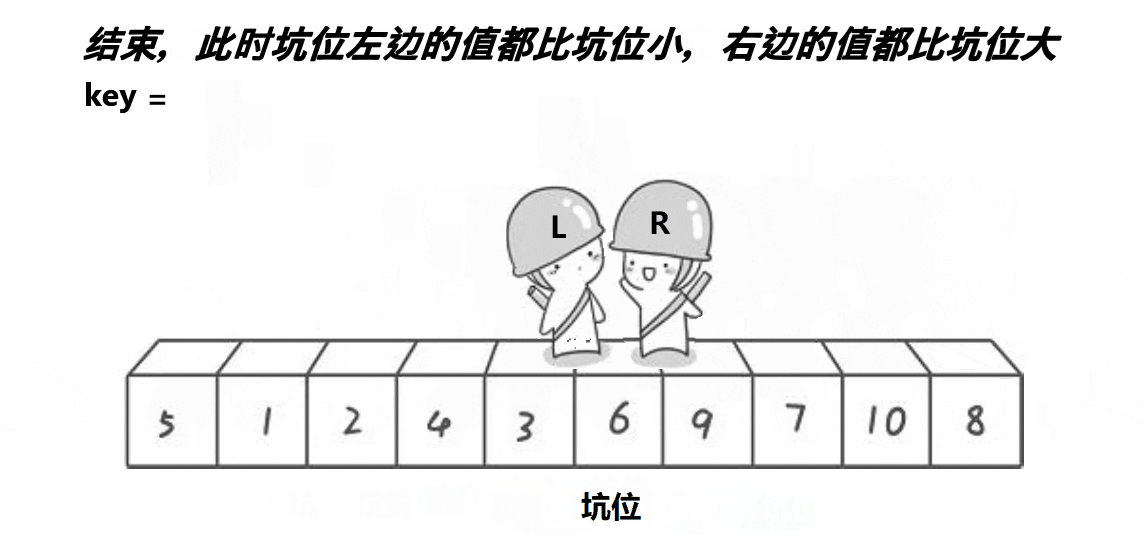
2、我们依旧设置left和right,让right从右向左走,如果找到比基准位小的数,就将其存到坑位处,那么原right处就形成了新的坑位。然后left向右走找大,找到大就将其放到坑位处,这就又形成新的坑位。不断重复该操作,直到left和right相遇。
3、这时我们保存的原基准位就发挥了作用,将其放到最后的坑位处,仍然达到了基准值左边都比他小,右边都比他大 的效果。
话有点多了,放图:
挖坑法比hoare版本的好理解一点,那么上代码:
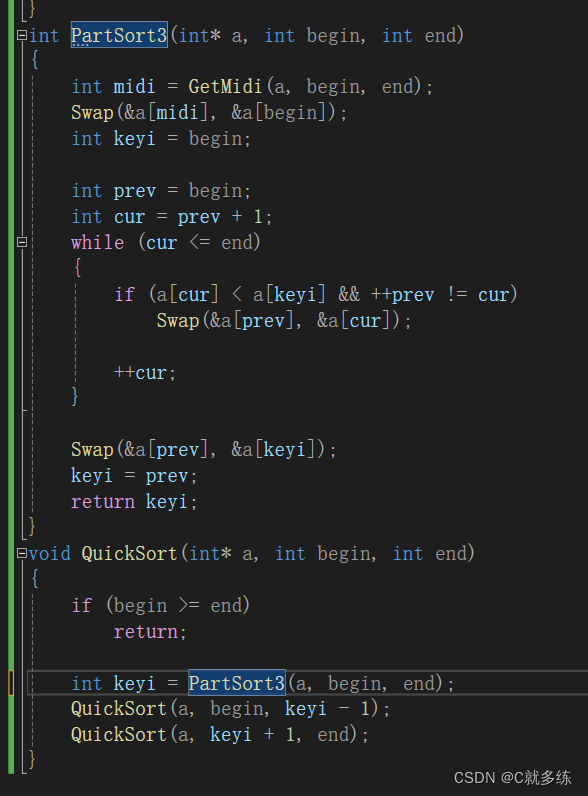
这里我们定义Key保存我们选定的初始坑位的值。然后定义变量hole来代表坑的位置。
下面的代码与hoare版本大同小异。当循环结束后,即begin和end相遇,这时坑位就是最后基准值的最终位置。
因为这里我们是封装了这样一个函数来实现挖坑法的步骤,所以要传坑位参数给QuickSort函数来进行递归排序。



直接插入排序的其他思想--前后指针法:
这个世界大佬那么多,好的想法自然不会只有一个,前后指针法,就是另一个快速排序的算法思想。
前后指针法,即使用一前一后两个指针,前指针寻找比基准值小的数,如果找到,后指针先后移一位,再与前指针所指的值做交换,前指针再++;如果遇到比基准值大的数,前指针继续++,后指针不移动。当前指针遍历完成整个序列时,将基准值与后指针指向的数交换。达到左边比基准值小,右边比基准值大的效果。

代码实现:
写个函数封装的一大好处就是可以再利用,哈哈~~
前后指针法,一大重点就是指针一前一后,前指针负责遍历,所以循环的继续条件就是要前指针不越界。然后,交换条件的判断也是一大毒点,要确保前指针指向的值小于基准值的同时,前后指针不能走到一起。这是为了确保我们不会将元素与其自身交换(这没有意义)。

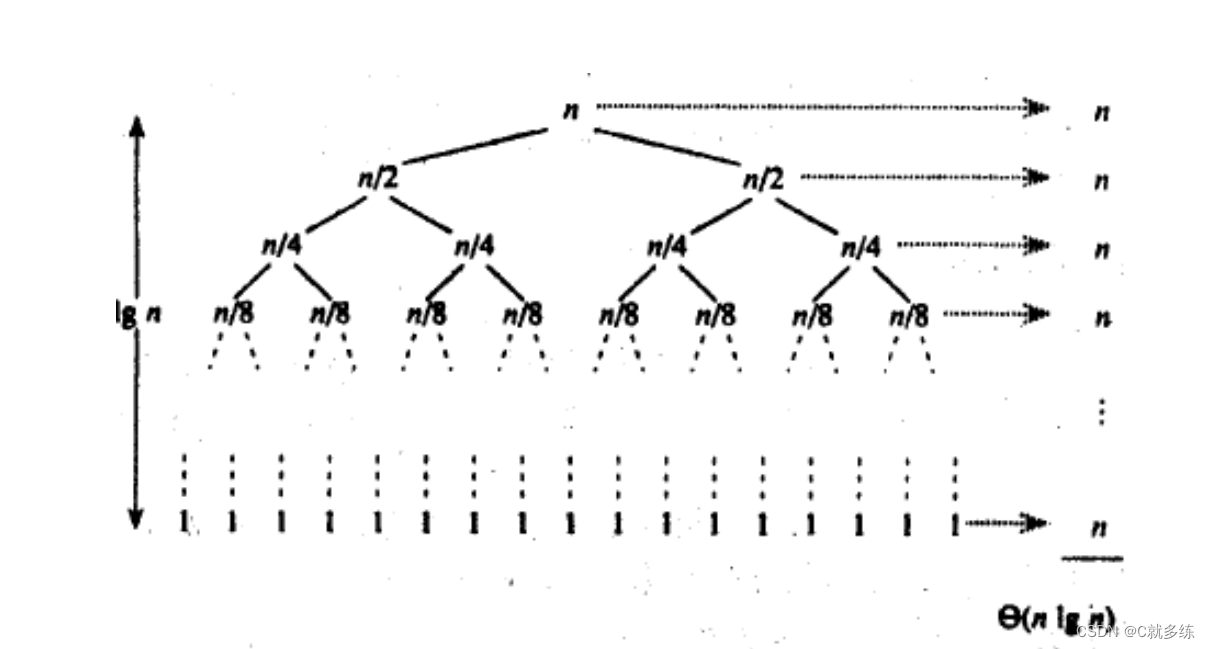
快速排序的时间复杂度:
快速排序的时间复杂度是O(n^logn);