项目背景
学电子信息的你加入了一家节能环保企业,公司的主营产品是节能型洗车房。由于节水节电而且可自动洗车,产品迅速得到了市场和资本的认可。公司决定继续投入研发新一代产品:在节能洗车房的基础上实现无人值守的功能。新产品需要通过图像识别检测出车牌号码,车主通过扫码支付后,洗车房的卷帘门自动开启。新产品的研发由公司总工亲自挂帅,他对团队寄予厚望,作为人工智能训练师,你被分在图像识别团队。项目经理为你提供了数百张原始车牌图片,并配备了一位资深算法工程师为你提供预训练模型,要求你在硬件设计定稿打样之前,完成车牌识别的模型训练,能够识别京牌车号,并部署到边缘计算设备上测试通过。为了给后续实际上线工作提供可靠的基础,你的工作需要在一周内完成,请尽快开始。
分析项目
项目中需要我们通过图像识别能够检测出京牌车号,既然是图像识别,那就离不了cnn,而且里面还有一个要求是部署到边缘计算设备上,那么我们的网络及模型对硬件算力的要求就不能太高。这里我先想到的了LeNet,它输入数据大小是32*32的,也就是说拿到一张车牌图片,需要有以下步骤:切分图片、依次传入网络识别、拼接输出结果。
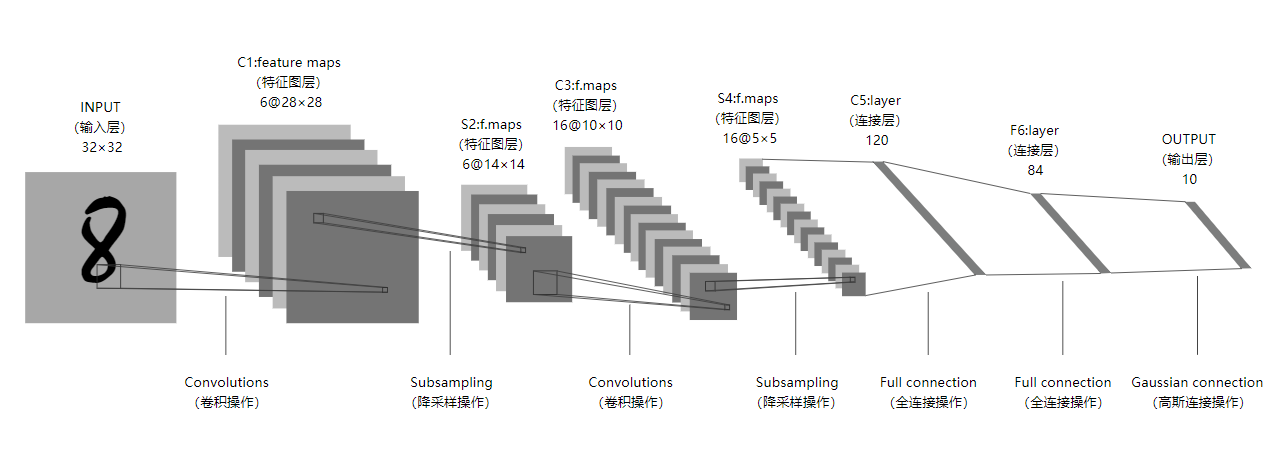 LeNet网络结构图
LeNet网络结构图
内心:“哦?就这三步骤?分分钟搞完。开始第一步:切分图片,好的第一步不会,项目崩溃“
后两步还好,难就难在切分图片,切分依据是什么?如何编写切分程序?切分程序能否在大多数据集上表现效果好?
🤔难道就要放弃了吗,要放弃了吗,真的要放弃了吗,不!我还有大招没放。之前参加过一个比赛也是关于车牌识别检测的,它给的数据集车牌图片是人在路边拍的,需要先裁剪出车牌图片再进行识别,记得当时做那个项目用了Yolo7 和 paddleocr这两个开源技术。不过这个洗车房项目里只要求了完成识别所以就免去第一步了,直接对车牌去进行识别。好的,识别这里我用LPRNet代替paddleocr
为什么要用LPRNet呢?原因如下:
- LPRNet模型大小仅有1.8兆,非常轻量
- LPRNet也是上次比赛中学习到的,那会我也去尝试了几遍,可是我测试集的识别准确率就是很低,那个博主的准确率高达97%,不服绝对不服,一定是我上次的打开方式不对哈哈哈哈,带着上次的不解与困惑让我再试一次
那最终就确立LPRNet为本次项目的主体
项目流程
1.部署LPRNet到本地
2.LPRNet项目分析
3.准备数据集
4.训练模型
搭建项目
1.部署LPRNet到本地
下载LPRNet
LPRNet下载地址![]() https://github.com/sirius-ai/LPRNet_Pytorch
https://github.com/sirius-ai/LPRNet_Pytorch
安装模块
README文件里有说

跑通测试代码
data文件夹下自带了1000张测试图片,运行项目根目下的 test_LPRNet.py 尝试跑通
test_LPRNet.py中的 show函数会起到一个阻塞作用,可以将参数show置为False

但直接将show置为False后,就不会展示以下每张图片的预测效果
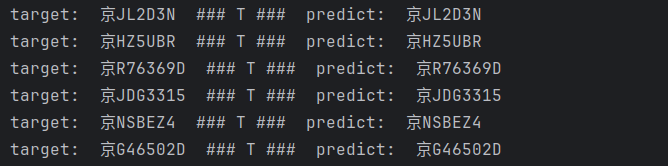
若想看到预测效果可以在show函数内部进行部分注释,show参数那要置为True
2.LPRNet项目分析
总的来看,这个项目是比较简单的,代码只有这4个文件
- load_data.py
- LPRNet.py
- test_LPRNet.py
- train_LPRNet.py
现在我想知道的是它的输入图片大小、标签格式
load_data.py中有resize方法,且与test_LPRNet.py、train_LPRNet.py相关联,表示当我的图片像素大小不为94*24的时候,会调用该方法重置图片大小。(它不会覆盖原有输入数据集的图片,只会使输入其他大小的图片不会报错)

标签的格式即图片文件名
LPRNet网络结构,直接看代码会比较难理解,可以结合图片去看
使用以下代码得到可视化onnx模型,导入到网页 https://netron.app/
from LPRNet import build_lprnet
import torchlprnet = build_lprnet(lpr_max_len=8, phase=True, class_num=68, dropout_rate=0.5)
device = torch.device("cuda:0" if torch.cuda else "cpu")
lprnet.to(device)
print("Successful to build network!")inputs = (1, 3, 24, 94)
input_data = torch.randn(inputs).to(device)
torch.onnx.export(lprnet, input_data, 'lpr.onnx')3.准备数据集
我用的数据集是CBLPRD-330k,用代码将里面为京牌的图片提取出来,有9000多张
import logging
import random
import os
import shutil# 需要修改为自己的实际路径
datas = open('../data.txt', 'r').readlines()
total = len(datas)
# random.shuffle(datas)print('开始过滤数据····')
jing = []
blue = []
green = []
for data_txt in datas:directory, licen, color = data_txt.split()if licen[0] == '京':if not licen[1].isdigit():if not licen[-1] == '挂':if not licen[-1] == '学':print(licen)if len(licen) == 7:blue.append(licen)elif len(licen) == 8:green.append(licen)else:logging.warning(len(licen))jing.append(licen)new_dir = '京/' + licen + '.jpg'shutil.copy(os.path.join('../', directory), new_dir)
print('total:', len(jing))
print('blue:', len(blue))
print('green:', len(green))
划分数据集(train、test)
import shutil
import random
from tqdm import tqdm
import osdirectory = 'data'
datas = os.listdir(directory)
random.shuffle(datas)
total = len(datas)
# 90 10
train_data = datas[:int(0.9 * total)]
test_data = datas[int(0.9 * total):]if not os.path.exists('train'):os.mkdir('train')if not os.path.exists('test'):os.mkdir('test')for data in tqdm(train_data):licen, suffix = data.split('.')new_dir = 'train/' + licen + '.' + suffixshutil.copy(os.path.join(directory, data), new_dir)
print('exec train over')for data in tqdm(test_data):licen, suffix = data.split('.')new_dir = 'test/' + licen + '.' + suffixshutil.copy(os.path.join(directory, data), new_dir)
print('exec test over')4.训练模型
虽然有9000张,其实也不算多,所以这里要用迁移学习思想
tips:比赛那次识别度低原因就是没有用迁移学习,全部参数传入,随着训练的进行,模型中的可学习参数层的参数都发生改变导致的🤧
- 将weights目录下自带的Final_LPRNet_model.pth重名为Pre_LPRNet_model.pth,将参数pretrained_model指定为预训练模型Pre_LPRNet_model.pth

- 冻结网络主干部分,仅训练输出层

# 将不更新的参数的requires_grad设置为False for name, param in lprnet.backbone.named_parameters():param.requires_grad = False # 仅把需要更新的模型参数传入optimizer optimizer = optim.RMSprop(lprnet.container.parameters(), lr=args.learning_rate, alpha=0.9, eps=1e-08,momentum=args.momentum, weight_decay=args.weight_decay) - (可选)加入tensorboard可视化训练
from torch.utils.tensorboard import SummaryWriter# 加入到训练的地方(只加入了loss变化图) writer.add_scalar('loss', scalar_value=loss.item(), global_step=epoch) writer.close()# 可以定义在 if __name__ == "__main__": 里 writer = SummaryWriter()
指定参数,绿色箭头表示一些常用的参数

运行train_LPRNet.py进行训练
5.测试
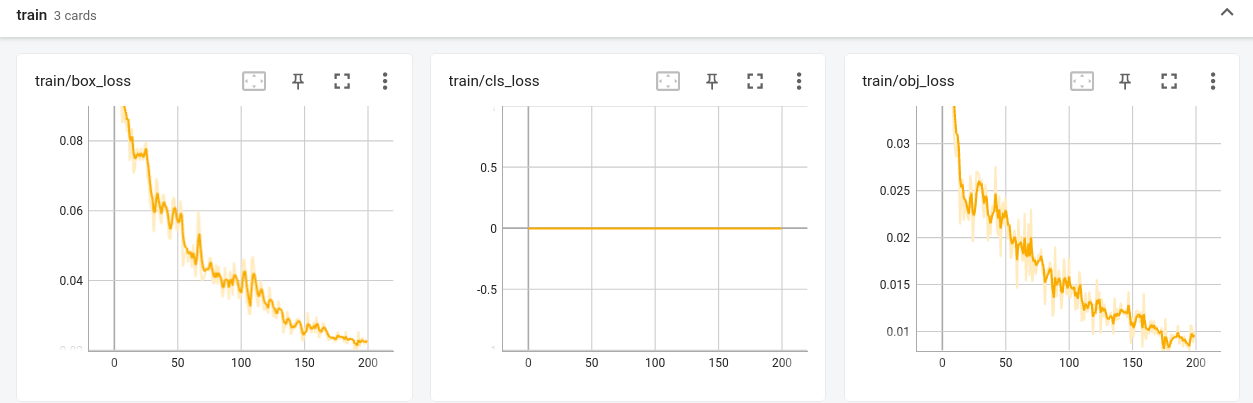
我这里训练了14轮,cpu上测试得到的效果 800多张图片准确率在86%~87%

在15轮之后,loss值会反弹的很厉害,效果会变差

项目总结
通过这个项目,又学到了一些新的东西,巩固实践了旧的知识。还有就是写这个总结挺费劲的,写总结花费的时间比我做项目的时间还要久····

项目拓展
洗车房项目所使用的数据集图像大小全部为128 * 48,这种图片相当于贴脸拍了

现在的需求:当给到一张大图片的时候,也能够识别出来、识别准确。
就是说,我现在拿自己手机去外面拍一张,只要这张照图片里有车牌都要能够识别到
这就需要使用YOLO先对目标(车牌)进行定位,再通过LPRNet识别,好!开整!
1.训练车牌识别模型
这次我用yolov5来做,就不写那么详细了,类似的训练详解我之前博客有可以去看
数据有限,网上找了36张图片标注训练,15张图片测试


测试图片

测试视频
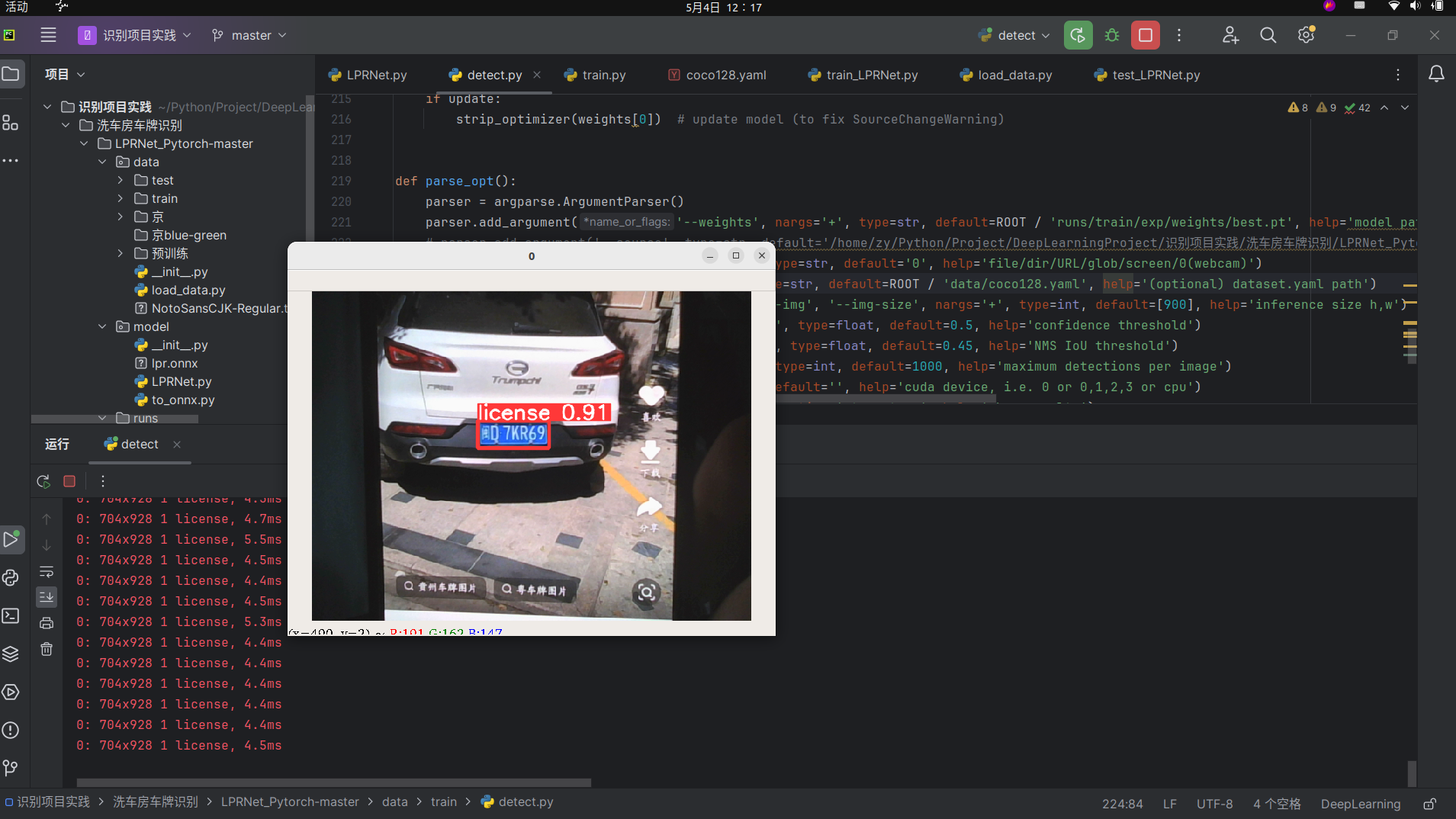
有车牌识别模型了,看上去效果还不错
2.把LPRNet加入到yolov5的detect.py中
改了一下午,此时00:10终于完成啦!现在可识别图片也可以识别视频流,而且可以显示中文哦!
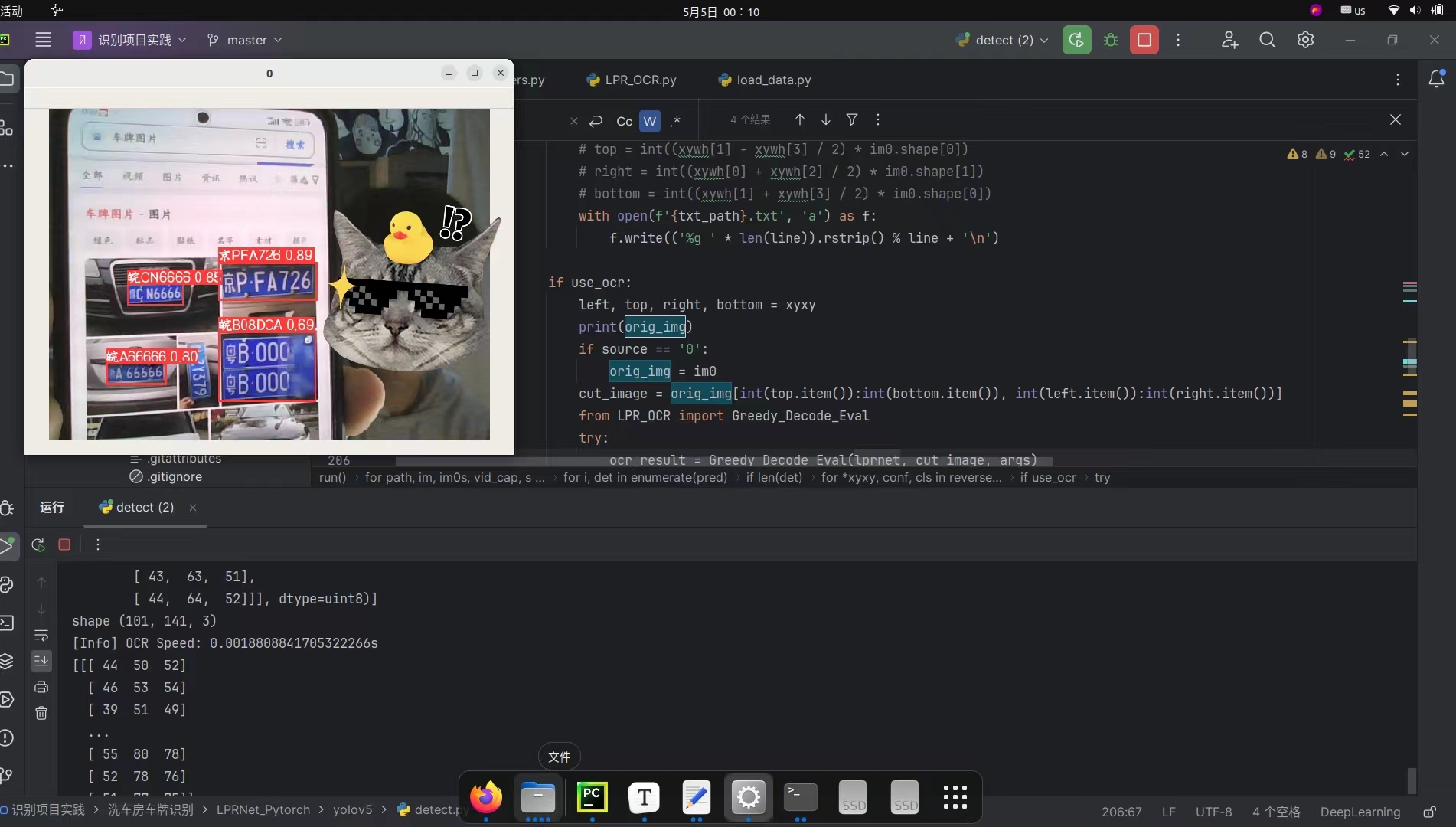
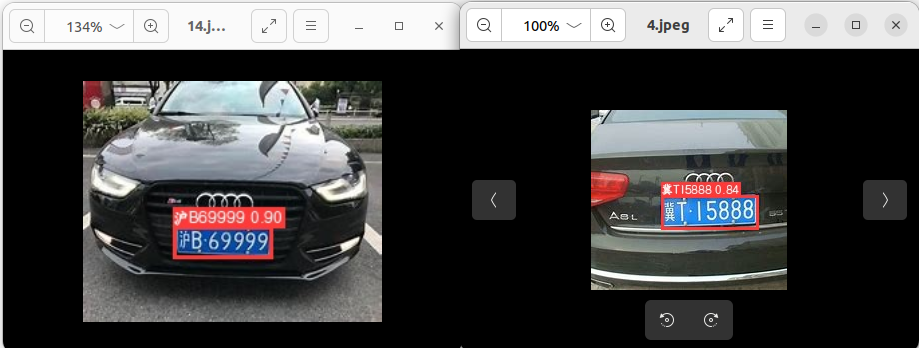
由于detect.py代码篇幅较长,改动的地方解释起来不是很好理解,也怕误导读者,所以就不在此解读了,如果你们对这个拓展感兴趣,等我整理好后会放到我的github主页,你们可以直接拿去调试
我的github主页:还没整理好呢,先不要着急!

最后感谢阅读!