目录
- 写在前面
- 1. 环境配置
- 2. 获取网页数据
- 3. 解析网页数据
- 4. 提取所需数据
- 4.1 简单提取
- 4.2 多级索引提取
- 5. 常见问题
写在前面
仅作个人学习与记录用。主要整理使用Requests和BeautifulSoup库的简单爬虫方法。在进行数据爬取时,请确保遵守相关法律法规和网站的服务条款,尊重数据版权和用户隐私。同时,合理安排爬虫的访问频率,避免对目标网站造成不必要的负担。
1. 环境配置
安装Requests:
直接通过pip安装即可:pip install requests
安装BeatifulSoup:
直接通过pip安装即可:pip install beautifulsoup4
注意导入库时不能import beautifulsoup4,需要import bs4
2. 获取网页数据
import requests
from bs4 import BeautifulSoup
#res = requests.post('url')
res = requests.get('url')
nginx等web服务器不允许post访问静态资源。因此如果使用post访问页面也是报错,可以尝试使用get方式访问。
如果在使用requests.get()或requests.post()访问https请求时出现了SSLError,即显示Can’t connect to HTTPS URL because the SSL module is not available.时,需要将下述两种文件从bin文件夹复制到DLLs文件夹下:
libcrypto-1_1-x64.*
libssl-1_1-x64.*
[Anaconda安装路径]\Library\bin -> [Anaconda安装路径]\DLLs
如果是anaconda虚拟环境,需要将文件拷贝到相应的环境DLLs文件夹下,例如:
[Anaconda安装路径]\envs\[虚拟环境名]\Library\bin -> [Anaconda安装路径]\envs\[虚拟环境名]\DLLs
3. 解析网页数据
BeautifulSoup 是一个 Python 库,用于从 HTML 或 XML 文件中提取数据。它可以将复杂的 HTML 文档转换成一个复杂的树形结构,每个节点都是 Python 对象,所有对象可以归纳为四种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
以下是使用 BeautifulSoup 解析网页数据的代码:
import requests
from bs4 import BeautifulSoup
res = requests.get('url')
html = response.text
#利用BS库对网页进行解析,得到解析对象soup
soup = BeautifulSoup(html,'html.parser')
其中html.parser是Python 标准库中的内置解析器,不需要额外安装,但在某些情况下可能不如其他解析器强大或快速。以下是一些常用的第三方解析器:
- lxml 解析器:
lxml是一个第三方库,它提供了一个快速的 HTML 解析器。要使用lxml解析器,需要先安装lxml库。
然后,在 BeautifulSoup 中使用它:pip install lxmlsoup = BeautifulSoup(html, 'lxml') - html5lib 解析器:
html5lib是一个用于解析 HTML 的库,它根据 HTML5 标准来解析 HTML 文档。要使用html5lib解析器,您需要先安装html5lib库。
然后,在 BeautifulSoup 中使用它:pip install html5libsoup = BeautifulSoup(html, 'html5lib')
在选择解析器时,lxml 通常是速度最快的选择。但是如果只需要解析基本的 HTML 文档,html.parser 可能就足够了。如果需要严格的 HTML5 解析,html5lib 是不错的选择,尽管它可能比其他解析器慢。
4. 提取所需数据
4.1 简单提取
得到目标网页的解析对象soup后,接下来将鼠标光标移动到所需的数据上,比如一个链接、一张图片或者一段文字。在鼠标定位到所需数据上之后,右键点击鼠标,会弹出一个上下文菜单。接下来在弹出的上下文菜单中选择“检查”(Chrome、Firefox、Edge等常用浏览器都有此选项),或者通过快捷键(Ctrl+Shift+I)直接打开。
最后需要定位HTML元素:点击“检查”后,浏览器会打开开发者工具,并自动选中与鼠标位置相对应的HTML元素。在这里,可以找到该数据在网页源代码中的位置和结构。
例如抓取下述图书的名称:
 得到:
得到:
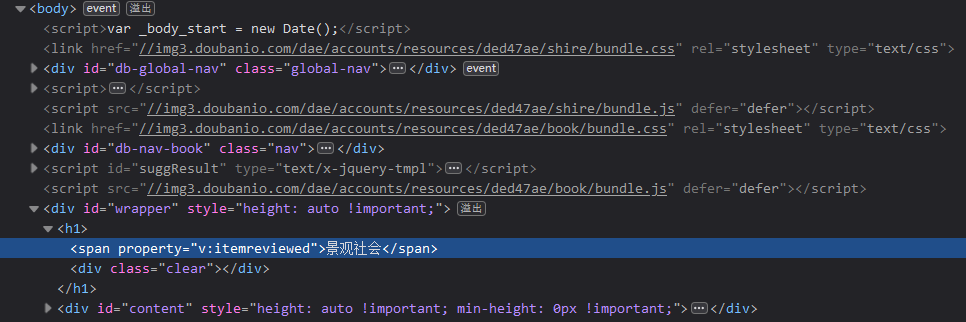 可以发现图书名称是在如下标签中的:
可以发现图书名称是在如下标签中的:
<span property="v:itemreviewed">景观社会</span>
因此可以设计如下代码查询:
book_title_tag = soup.find("span", property="v:itemreviewed")
book_title_tag = book_title_tag.contents[0]
if book_title_tag:book_title = book_title_tag.get_text()print('书名:', book_title)
else:print('未找到书名')
find方法只会返回第一个匹配的元素。如果你需要查找所有的匹配元素,可以使用find_all方法,它会返回一个包含所有匹配元素的列表ResultSet。
注意find_all()方法和find()函数返回的分别是ResultSet和一个Tag,访问ResultSet和Tag的内容需要使用下标:
.content[n]
而访问列表元素的下一级元素同样使用.contents[n]来访问:
.content[n].contents[m]
以下列举的是一些常用的提取方法:
-
通过标签名查找
title = soup.find('title')print(title.text) # 输出标签内的文本 -
通过属性查找
link = soup.find('a', {'href': 'http://example.com'})print(link.text) -
提取所有匹配的元素
links = soup.find_all('a') for link in links:print(link.get('href')) -
嵌套选择
div = soup.find('div', {'class': 'some-class'}) links = div.find_all('a') -
提取标签内的文本
p = soup.find('p') print(p.text) -
提取属性
img = soup.find('img') print(img.get('src')) -
提取多个属性
img = soup.find('img') attributes = img.attrs print(attributes['src'], attributes['alt']) -
按类查找
items = soup.find_all(class_='item') -
按 ID 查找
element = soup.find(id='some-id') -
使用 CSS 选择器
paragraphs = soup.select('p.some-class') for p in paragraphs:print(p.text)
4.2 多级索引提取
与上一节的简单提取方法不同,在BeautifulSoup中,多级索引是指通过多个层级的选择来定位特定的HTML元素。这通常涉及到使用不同的HTML标签和属性来逐步缩小搜索范围,直到找到需要的特定元素。
以下是一个使用BeautifulSoup进行多级索引的示例:
import requests
from bs4 import BeautifulSoupurl = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')# 假设要找的元素在一个id为'parent'的div内,然后是一个class为'child'的span内
parent_div = soup.find('div', id='parent')
if parent_div:child_span = parent_div.find('span', class_='child')if child_span:# 现在我们可以提取child_span中的文本或者执行其他操作text = child_span.get_text()print('找到的文本:', text)else:print('未找到class为child的span')
else:print('未找到id为parent的div')
首先通过find方法找到了id为parent的div元素,然后在这个div元素中继续使用find方法查找class为child的span元素。这种方法可以一直递归下去,直到找到所需要的特定元素。
此外,BeautifulSoup还支持CSS选择器,这使得多级索引更加直观。例如,如果你想要选择id为parent的div内所有class为child的span元素,可以使用如下选择器:
child_spans = soup.select('div#parent > span.child')
这将返回一个包含所有匹配span元素的列表。
5. 常见问题
(1)网页中的中文内容在使用requests获取后,中文乱码无法识别:【解决方法】
持续更新