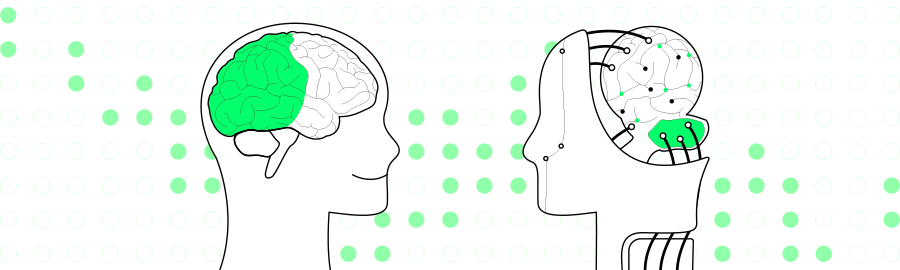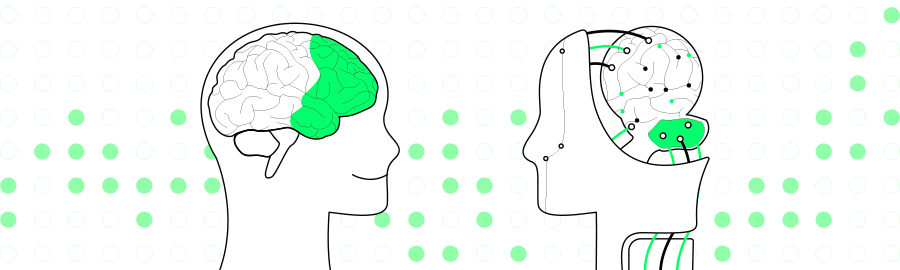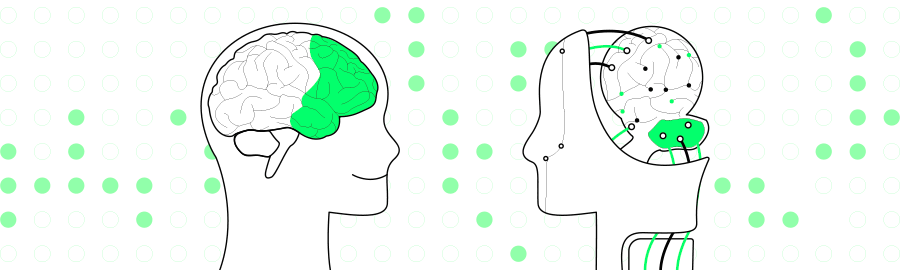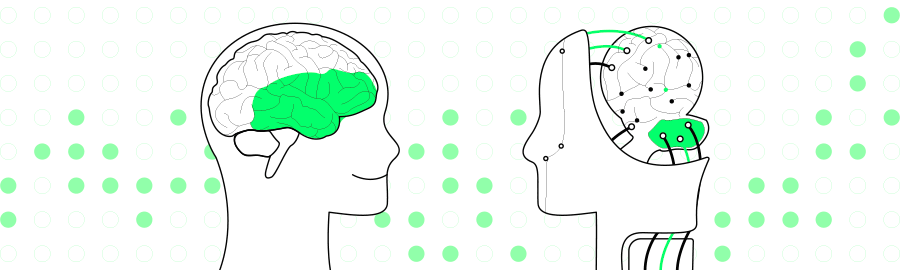
概述
最新多模态模型MiniGPT-4 开源:它使用先进的大型语言模型 (LLM)--Vicuna(其中 Vicuna 是基于 LLaMA 构建的)进行调优,在文本语言方面可以达到 ChatGPT 能力的90%。在视觉感知方面,作者采用了与BLIP-2相同的预训练视觉组件,其中该组件由EVA-CLIP的ViT-G/14和Q-Former组成。MiniGPT-4 只添加了一个映射层,将编码的视觉特征与Vicuna语言模型对齐,冻结了所有视觉和语言组件参数。
MiniGPT-4介绍
距离GPT-4 已经发布一个多月了,但识图功能还是体验不了。来自阿卜杜拉国王科技大学的研究者推出了类似产品 ——MiniGPT-4,大家可以上手体验了。
对人类来说,理解一张图的信息,不过是一件微不足道的小事,人类几乎不用思考,就能随口说出图片的含义。就像下图,手机插入的充电器多少有点不合适。人类一眼就能看出问题所在,但对 AI 来说,难度还是非常大的。
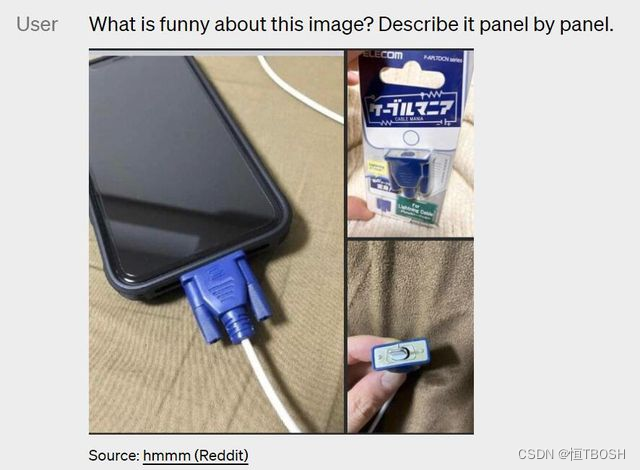
GPT-4 则能很快的指出图中问题所在:VGA 线充 iPhone是不合适的。
其实 GPT-4 的魅力远不及此,更炸场的是利用手绘草图直接生成网站,在草稿纸上画一个潦草的示意图,拍张照片,然后发给 GPT-4,让它按照示意图写网站代码,GPT-4 就能很快把网页代码写出来了。
但遗憾的是,GPT-4 这一功能至今仍未向公众开放,想要上手体验也无从谈起。不过,已经有人等不及了,来自阿卜杜拉国王