21. DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
本文提出一种根据少量样例图片来对文生图模型进行微调的方法,从而可以生成包含样例物体,但风格、姿态、背景都可以任意修改的图片。现有的文生图模型都是需要给出特别详细的描述,然后生成对应的图片,但即使描述得再具体,再详细,生成的图片可能也不能满足使用者的要求。比如,我就想生成与自己家狗一样的狗狗照片,但是姿势、背景都可以自由设定,而不是任意生成一张狗的图片。为了解决这个问题,本文通过输入少量样例图片(例如几张自己家狗的照片),并给定一个包含特殊标记符的文字描述(“a [V] dog”),来对一个文生图模型(如SD、Imagen)进行微调训练,使模型将样例中狗的特征与特殊标记符"[V]“关联起来。在推理时,只要在文字描述中加入特殊标记符”[V]“就能个性化的生成自己家狗狗的图片,如“a [V] dog is swimming”。这一特性无疑是非常有价值的,因此在各大图像生成软件中也都包含了DreamBooth工具。

那么这么惊艳的效果是如何实现的呢?首先,我们简单回顾一下当前的文生图模型是如何工作的。目前流行的文生图模型,普遍采用基于扩散模型的架构,给定一个文字提示 P P P,由文本编码器 Γ \Gamma Γ进行编码后得到对应的文本条件 c = Γ ( P ) c=\Gamma(P) c=Γ(P),将一个随机噪声 ϵ \epsilon ϵ和条件 c c c一起输入到生成模型 x ^ θ \hat{x}_{\theta} x^θ中,可得生成的图像 x g e n = x ^ θ ( ϵ , c ) x_{gen}=\hat{x}_{\theta}(\epsilon, c) xgen=x^θ(ϵ,c)。生成模型 x ^ θ \hat{x}_{\theta} x^θ的训练过程如下 E x , c , ϵ , t [ w t ∥ x ^ θ ( α t x + σ t ϵ , c ) − x ∥ 2 2 ] \mathbb{E}_{\mathbf{x},\mathbf{c},\boldsymbol{\epsilon},t}\big[w_t\|\hat{\mathbf{x}}_\theta(\alpha_t\mathbf{x}+\sigma_t\boldsymbol{\epsilon},\mathbf{c})-\mathbf{x}\|_2^2\big] Ex,c,ϵ,t[wt∥x^θ(αtx+σtϵ,c)−x∥22]其中 x \mathbf{x} x表示真实的图像, α t \alpha_t αt可以理解为是噪声和原图之间的比例系数, σ t \sigma_t σt是噪声的方差, w t w_t wt是损失权重, t t t是时间步数。通过对原始图像逐步添加噪声得到时刻 t t t时的有噪声图像 z t = α t x + σ t ϵ \mathbf{z}_t=\alpha_t\mathbf{x}+\sigma_t\boldsymbol{\epsilon} zt=αtx+σtϵ,然后利用生成模型在文本条件的引导下对噪声图像逐步去噪得到生成图像。当然基于扩散的文生图方法还是有很多细节和实现方式了,具体可参考本博其他的文生图模型介绍,如DALLE·2,LDM和GLIDE。
了解了文生图模型的大体流程,下面就是要考虑如何让其根据我们提供的样例生成个性化图片了。最直接的方法,当然是使用样例图片对预训练好的文生图模型进行微调训练,但经过微调训练之后,模型可能具备了生成样例图片的能力,但它本质上是个随机采样的过程,无法保证每次生成的都是指定的样例图片。当然我也可以反复的训练,直到模型过拟合,只能输出特定样例的图片,但同时模型也丧失了生成其他图片的能力了,这肯定也不是我们希望看到的。那么如何告诉模型,我现在希望生成的就是我给你这几个样例图片里的对象呢?作者想到可以用一个特殊的标记符”[V]“来描述它,当模型看到输入文本里带有描述符”[V]“时,就知道我要生成样例图片中的对象了,如果没有特殊标记符,则生成其他的对象。基于这个想法,作者提出一种微调训练方法,给定几张样例图片(通常3-5张),并给定一个带有特殊标记符的文本描述“a [identifier] [class noun]”,其中”[identifier]“就是上文提到的特殊标记符,”[class noun]"是样例图片中对象的类别。利用这些文本-图像对对模型进行微调训练,使模型将样例对象的特征与特殊标记符绑定在一起,再看到这个标记符时就知道要生成样例对象了。
那么这个特殊标记符如何设定呢?作者尝试使用了“unique”或“special”这类现成的英文单词,但这些词汇本身是具备一定含义的,在原有的文本编码器中也有相应的理解先验,因此需要模型先将这些词与原本的意思解绑,再与样例对象绑定,这就给模型训练带来很大的困难。此外,作者还尝试了使用随机的字母和数字组合,如“xxy5syt00”,但编码器是逐个字母来编码的,这些字母也会包含较强的先验与前面使用单词的方式存在同样的问题。最终,作者选择使用一些“罕见词”,就是利用文本库中的一些出现概率极低的词汇作为特殊标记符,如“sys”。实际中作者发现使用T5-XXL模型的文本库中{5000,…10000}范围里的字符数小于3的词汇可以取得较好的效果。
在训练过程中,作者发现存在两个问题:1.语言漂移(Language drift),就是我们前文提到的随着训练,模型逐渐忘记了如何生成同类别的其他物体,如只能生成你家狗狗的照片,而不能生成其他狗的照片;2. 多样性损失,作者发现随着训练,模型输出图像中对象的姿态基本都保持不变。为了解决这个问题作者提出一种特定类别先验保持的损失函数(Class-specific Prior Preservation Loss),其思想也很简单,不是担心的在微调过程中忘记如何生成其他同类别的对象吗,我就把特殊标记符去掉,让模型同时生成一个其他类别的对象,和带有特殊标记符的生成过程一起进行微调,并计算损失,损失函数如下 E x , c , ϵ , ϵ ′ , t [ w t ∥ x ^ θ ( α t x + σ t ϵ , c ) − x ∥ 2 2 + λ w t ′ ∥ x ^ θ ( α t ′ x p r + σ t ′ ϵ ′ , c p r ) − x p r ∥ 2 2 ] \mathbb{E}_{\mathbf{x},\mathbf{c},\boldsymbol{\epsilon},\boldsymbol{\epsilon}^{\prime},t}[w_{t}\|\hat{\mathbf{x}}_{\theta}(\alpha_{t}\mathbf{x}+\sigma_{t}\boldsymbol{\epsilon},\mathbf{c})-\mathbf{x}\|_{2}^{2}+\lambda w_{t^{\prime}}\|\hat{\mathbf{x}}_{\theta}(\alpha_{t^{\prime}}\mathbf{x}_{\mathrm{pr}}+\sigma_{t^{\prime}}\boldsymbol{\epsilon}^{\prime},\mathbf{c}_{\mathrm{pr}})-\mathbf{x}_{\mathrm{pr}}\|_{2}^{2}] Ex,c,ϵ,ϵ′,t[wt∥x^θ(αtx+σtϵ,c)−x∥22+λwt′∥x^θ(αt′xpr+σt′ϵ′,cpr)−xpr∥22]可以看到是在原本的损失函数基础上又加了一项,其中 x p r \mathbf{x}_{\mathrm{pr}} xpr是由一个参数冻结的预训练好的扩散模型生成的图像, c p r \mathbf{c}_{\mathrm{pr}} cpr是文本条件,其对应的文本输入为“a [class noun]”,即去掉了特殊标记符, λ \lambda λ是一个权重系数。整个过程如下图所示
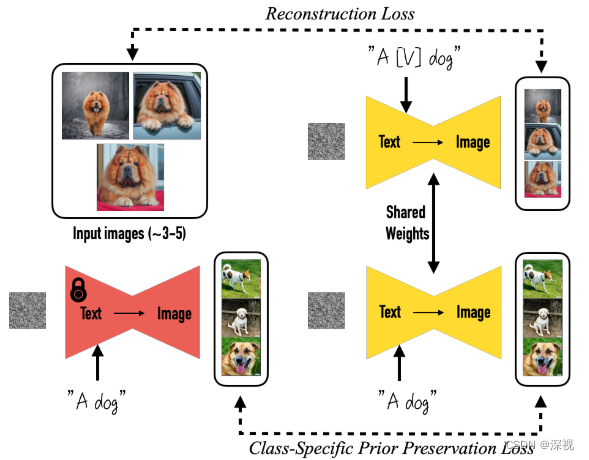
作者表示在TPUv4上只需要5分钟就能对Imagen模型完成微调,在A100上也只需要五分钟就能完成SD模型的微调。经过微调训练,模型可以根据样例图片生成非常多样的图片,并保持样例对象的主要特征不变,如下图所示

并且对于视角合成,艺术风格渲染和属性修改等复杂任务也不在话下










![[1726]java试飞任务规划管理系统Myeclipse开发mysql数据库web结构java编程计算机网页项目](https://img-blog.csdnimg.cn/direct/baf410b1909d49f28c6097babe8093e7.png)