17 内核开发-内核内部内联汇编学习
课程简介:
Linux内核开发入门是一门旨在帮助学习者从最基本的知识开始学习Linux内核开发的入门课程。该课程旨在为对Linux内核开发感兴趣的初学者提供一个扎实的基础,让他们能够理解和参与到Linux内核的开发过程中。
课程特点:
1. 入门级别:该课程专注于为初学者提供Linux内核开发的入门知识。无论你是否具有编程或操作系统的背景,该课程都将从最基本的概念和技术开始,逐步引导学习者深入了解Linux内核开发的核心原理。
2. 系统化学习:课程内容经过系统化的安排,涵盖了Linux内核的基础知识、内核模块编程、设备驱动程序开发等关键主题。学习者将逐步了解Linux内核的结构、功能和工作原理,并学习如何编写和调试内核模块和设备驱动程序。
3. 实践导向:该课程强调实践,通过丰富的实例和编程练习,帮助学习者将理论知识应用到实际的Linux内核开发中。学习者将有机会编写简单的内核模块和设备驱动程序,并通过实际的测试和调试来加深对Linux内核开发的理解。
4. 配套资源:为了帮助学习者更好地掌握课程内容,该课程提供了丰富的配套资源,包括教学文档、示例代码、实验指导和参考资料等。学习者可以根据自己的学习进度和需求,灵活地利用这些资源进行学习和实践。
无论你是计算机科学专业的学生、软件工程师还是对Linux内核开发感兴趣的爱好者,Linux内核开发入门课程都将为你提供一个扎实的学习平台,帮助你掌握Linux内核开发的基础知识,为进一步深入研究和应用Linux内核打下坚实的基础。
这一讲,主要分享如何在内核模块开发中阅读内联汇编代码。
1.内联汇编语法定义
在内核模块开发和学习别人代码中,我们经常看到c语言代码里面,含有汇编代码,阅读起来增加了很大的难度,怎么快速高效的理解这些代码,
使得自己能快速理解设计者的意图,成了学习内核代码不可获取的一环节。首先先来阅读下内联汇编代码结构。
Linux C 语言内联汇编的语法如下:
asm [volatile]("汇编指令": 输出操作数列表: 输入操作数列表: 被修改的寄存器列表);
输出操作数列表指定将从汇编代码中返回到 C 变量的寄存器或内存位置。
以下是使用语法解释:
"=约束符"(变量):约束符 指定寄存器的类型(例如,r 表示寄存器,m 表示内存),变量 是 C 变量的名称。
输入操作数列表指定传递给汇编代码的寄存器或内存位置。它使用以下语法:"约束符"(变量):与输出操作数列表中的语法相同。
被修改的寄存器列表指定在汇编代码执行期间可能被修改的寄存器。它使用以下语法:: "寄存器列表":寄存器列表 包含可能被修改的寄存器名称的逗号分隔列表。
volatile 关键字对于内联汇编不一定是必需的,如果定义了那么它告诉编译器不要对汇编代码进行优化。
有了一个基本的结构认识后,我们再看下他有什么用处,内核为什么定义这么多汇编代码?
2.内涵
Linux 内核中使用内联汇编的主要目的是为了:
- 提高性能:汇编代码通常比 C 代码更有效率,因为它可以直接操作硬件。在需要最高性能的关键部分(例如中断处理程序或设备驱动程序),使用汇编代码可以显着提高性能。
- 访问特定硬件功能:某些硬件功能(例如特殊寄存器或指令)无法通过 C 代码直接访问。内联汇编允许内核访问这些功能,从而实现对底层硬件的更精细控制。
- 移植性:内联汇编对于确保内核在不同体系结构上的移植性非常有用。通过针对特定体系结构编写汇编代码,内核可以利用该体系结构的特定优化和功能。
使用内联汇编的好处包括:
- 性能提升:如前所述,汇编代码通常比 C 代码更有效率。
- 硬件控制:内联汇编提供了对特定硬件功能的低级访问。
- 代码大小优化:汇编代码通常比 C 代码更紧凑,这有助于减少内核的总体代码大小。
- 可移植性:内联汇编有助于确保内核在不同体系结构上的可移植性。
3.使用示例
int a = 2;
int b;
asm volatile("movl %1, %%eax\\
""movl %%eax, %0":"=r"(b) #output register %0: "r" (a) # input register %1: "%eax"); #modify register
在这个示例中:
"=r"(b) 表示 b 变量是一个输出操作数,它将存储在 %eax 寄存器中。
: "r" (a) 表示 a 变量是一个输入操作数,它存储在寄存器中。
: "%eax" 表示 %eax 寄存器在汇编代码执行期间可能被修改。
上面代码的效果是,将 a 的值赋值给 b,最后a=b=2
4.具体代码使用实践
创建一个文件 asmtest.c
//
// Created on 2024/5/2.
//
#include <iostream>using namespace std;int main(){int a = 2;int b;asm("movl %1, %%eax\n" "movl %%eax, %0":"=r" (b): "r" (a): "%eax");printf("a:%d\n",a);printf("b:%d\n",b);}执行编译 g++ asmtest.c 生成可执行文件

执行命令,生成汇编代码
g++ -S asmtest.c

比较汇编结果和程序代码
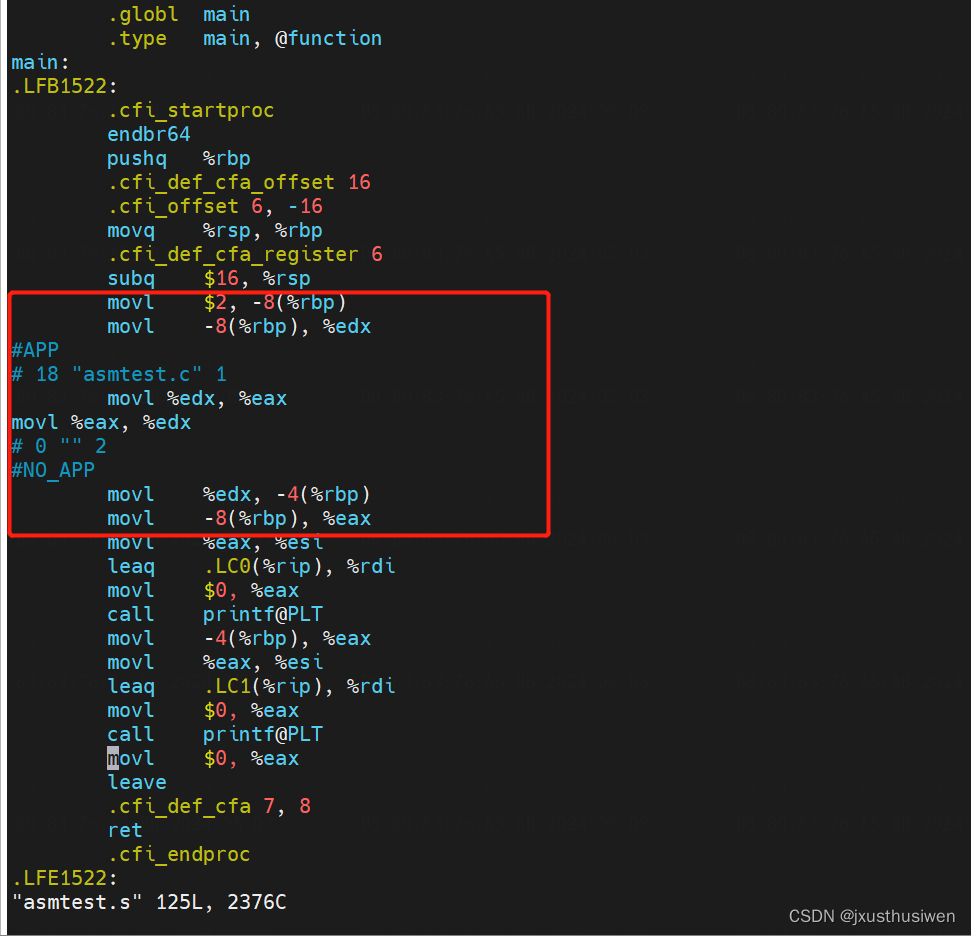
注意里面的rbp寄存器,这里详细说明下
rbp 是基指针寄存器,在 Linux C 语言内联汇编中扮演着至关重要的角色,它具有以下作用:
- 建立栈帧:rbp 用于建立栈帧,它指向当前函数的局部变量和参数在栈上的起始地址。
- 访问局部变量和参数:通过使用负偏移(相对于 rbp ),可以访问函数的局部变量和参数。例如:movl -8(%rbp), %eax 会将位于 rbp 向后偏移 8 字节处的变量加载到 EAX 寄存器中。
- 返回地址:在函数调用期间,返回地址(即调用后要返回的地址)存储在 rbp 向后偏移 8 字节处。
里面的movl -8(%rbp), %eax 就是执行完赋值后,将返回地址复制给eax 寄存器?
5.注意事项
在 Linux C 语言内联汇编的使用中需要考虑以下注意事项:
- 可移植性:内联汇编是体系结构相关的,这意味着针对特定体系结构编写的汇编代码可能无法在其他体系结构上工作。因此,在使用内联汇编时需要考虑可移植性。
- 调试难度:内联汇编代码比 C 代码更难调试,因为调试器无法理解汇编指令。因此,在使用内联汇编时需要仔细测试和调试代码。
- 代码可读性:内联汇编代码可能难以阅读和理解,因为它使用的是低级汇编指令。因此,在使用内联汇编时应添加适当的注释和文档。
- 安全性:内联汇编代码可以访问底层硬件,因此使用不当可能会导致安全漏洞。因此,在使用内联汇编时需要小心,并确保代码是安全的。
其他需要注意的事项:
- 使用 volatile 关键字:始终在内联汇编中使用 volatile 关键字,以防止编译器优化汇编代码。
- 指定被修改的寄存器:明确指定在汇编代码执行期间可能被修改的寄存器,以避免意外修改。
- 避免使用浮点寄存器:在 Linux 内联汇编中避免使用浮点寄存器,因为它们可能导致未定义的行为。
- 谨慎使用内存操作:在使用内存操作时要小心,确保正确对齐内存访问并避免访问无效地址。
- 测试和文档:彻底测试内联汇编代码,并添加适当的注释和文档以解释其作用和目的。
6.最佳实践
- 使用内联汇编函数:将内联汇编代码封装在函数中,以提高可读性和可维护性。
- 使用宏来简化汇编指令:创建宏来简化常见的汇编指令,从而提高代码的可读性和可维护性。
- 遵守编码标准:遵循一致的编码标准,包括缩进、命名约定和注释。
- 使用版本控制系统:将内联汇编代码存储在版本控制系统中,代码改动赋予记录,以跟踪更改并允许协作开发。
7.总结
Linux C 语言内联汇编允许程序员在 C 代码中嵌入汇编指令,从而直接访问底层硬件并优化性能。内联汇编在灵活性性能取得了一定的效果。 理解了它可以更好的理解内核源代码。后续有时间,我将更深入理解内联汇编是如何工作的,怎么和c混合在一起,提供最后功能。











![[1726]java试飞任务规划管理系统Myeclipse开发mysql数据库web结构java编程计算机网页项目](https://img-blog.csdnimg.cn/direct/baf410b1909d49f28c6097babe8093e7.png)