5.06号模拟前端面试8问
1.promise如何实现then处理
在JavaScript中,Promise 是一个代表异步操作最终完成或失败的对象。它有三种状态:pending(等待),fulfilled(完成),rejected(拒绝)。一旦一个 Promise 对象的状态改变,就不会再变。
then 方法是 Promise 对象的一个方法,用于指定在 promise 对象状态变为 fulfilled 或 rejected 时的回调函数。then 方法接收两个参数,分别是 Promise 对象状态变为 fulfilled 和 rejected 时执行的回调函数。
下面是一个 then 方法的基本使用示例:—
let promise = new Promise(function(resolve, reject) {// 这里是异步操作setTimeout(() => resolve("操作成功"), 1000);
});promise.then(function(value) {console.log(value); // "操作成功"
}, function(error) {console.log(error);
});
在这个例子中,我们创建了一个新的 Promise 对象,然后在其中执行了一个异步操作(这里用 setTimeout 模拟)。当这个操作完成时,我们调用 resolve 函数来改变 Promise 对象的状态为 fulfilled,并设置其结果值为 “操作成功”。
然后,我们调用 then 方法来指定当 Promise 对象状态变为 fulfilled 时要执行的回调函数。这个回调函数会接收到 Promise 对象的结果值,并将其打印出来。如果在 Promise 对象中发生了错误(例如调用了 reject 函数),那么 then 方法的第二个参数(一个函数)会被调用,并接收到错误信息。
需要注意的是,then 方法返回一个新的 Promise 对象,因此可以链式调用。例如:
let promise = new Promise(function(resolve, reject) {setTimeout(() => resolve("操作成功"), 1000);
});promise.then(function(value) {console.log(value); // "操作成功"return value + ",后续操作";
}).then(function(value) {console.log(value); // "操作成功,后续操作"
});
在这个例子中,我们在第一个 then 方法的回调函数中返回了一个新的值,这个值会被传递给下一个 then 方法的回调函数。
2.koa2中间件原理
Koa2是一个基于Node.js的Web框架,它的特点是轻量级和高度可扩展。在Koa2中,中间件是一种特殊的函数,它可以访问请求对象(req)、响应对象(res)和应用程序实例(app)的上下文。中间件的主要作用是在请求和响应之间执行一些操作,例如记录日志、处理错误、解析请求体等。
Koa2中间件的工作原理如下:
-
当一个请求到达服务器时,Koa2会创建一个上下文对象(context),该对象包含了请求对象(req)、响应对象(res)和应用程序实例(app)。
-
Koa2会将这个上下文对象传递给第一个中间件。
-
中间件可以对这个上下文进行修改,然后调用下一个中间件。这个过程会一直持续到最后一个中间件。
-
当所有中间件都执行完毕后,Koa2会根据上下文中的响应对象生成HTTP响应,并发送给客户端。
下面是一个简单的Koa2中间件示例代码:
const Koa = require('koa');
const app = new Koa();// 定义一个简单的中间件
const logger = async (ctx, next) => {const start = new Date();await next();const ms = new Date() - start;console.log(`${ctx.method} ${ctx.url} - ${ms}ms`);
};// 使用中间件
app.use(logger);// 定义一个简单的路由
app.use(async ctx => {ctx.body = 'Hello World';
});// 启动服务器
app.listen(3000);
在这个示例中,我们定义了一个名为logger的中间件,它会记录每个请求的方法、URL和处理时间。然后我们将这个中间件添加到Koa2应用程序中,使其在处理每个请求时都会被执行。最后,我们定义了一个简单的路由,用于返回"Hello World"响应。
当我们运行这段代码并访问http://localhost:3000时,我们可以看到控制台输出类似于以下的日志信息:
GET / - 1ms
这表明我们的logger中间件已经成功地记录了请求的信息。
私信【学习】即可获取前端资料 都整理好啦!!!
3.常⽤的中间件
在Web开发过程中,常用的中间件有:
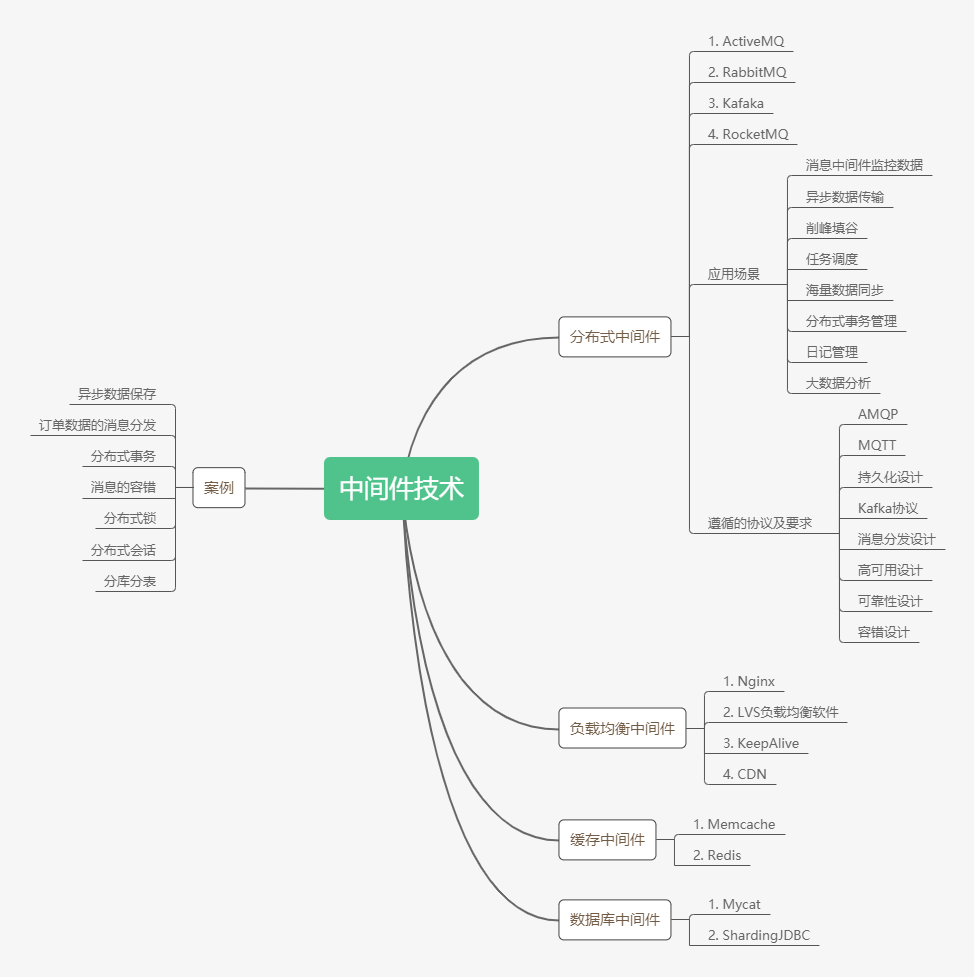
- 数据库中间件:如MySQL、MongoDB等,主要用于连接和操作数据库。
- 缓存中间件:如Redis、Memcached等,主要用于缓存数据,提高系统性能。
- 消息队列中间件:如RabbitMQ、Kafka等,主要用于实现异步通信和解耦。
- API网关中间件:如Zuul、Nginx等,主要用于统一管理和路由请求。
- 认证授权中间件:如JWT、OAuth2等,主要用于实现用户认证和授权。
以下是针对这些中间件的详细解释和代码示例:
- 数据库中间件:以MySQL为例,主要功能是连接和操作数据库。在项目中使用MySQL中间件,首先需要安装mysql模块,然后创建一个连接池,最后通过连接池进行数据库操作。
const mysql = require('mysql');
const pool = mysql.createPool({host: 'localhost',user: 'root',password: 'password',database: 'test'
});pool.query('SELECT * FROM users', (error, results, fields) => {if (error) throw error;console.log(results);
});
- 缓存中间件:以Redis为例,主要功能是缓存数据,提高系统性能。在项目中使用Redis中间件,首先需要安装redis模块,然后创建一个Redis客户端,最后通过客户端进行缓存操作。
const redis = require('redis');
const client = redis.createClient();client.on('connect', () => {console.log('Connected to Redis...');
});client.set('name', 'Bob', redis.print);
client.get('name', (err, reply) => {console.log(reply);
});
- 消息队列中间件:以RabbitMQ为例,主要功能是实现异步通信和解耦。在项目中使用RabbitMQ中间件,首先需要安装amqplib模块,然后创建一个RabbitMQ连接,最后通过连接发送和接收消息。
const amqp = require('amqplib/callback_api');amqp.connect('amqp://localhost', (err, conn) => {conn.createChannel((err, ch) => {const q = 'hello';ch.assertQueue(q, {durable: false});ch.sendToQueue(q, new Buffer('Hello World!'));});
});
- API网关中间件:以Zuul为例,主要功能是统一管理和路由请求。在项目中使用Zuul中间件,首先需要安装zuul模块,然后创建一个Zuul实例,最后通过实例进行路由配置。
@Configuration
public class ZuulConfig {@Beanpublic SampleZuulFilter simpleFilter() {return new SampleZuulFilter();}
}
- 认证授权中间件:以JWT为例,主要功能是实现用户认证和授权。在项目中使用JWT中间件,首先需要安装jsonwebtoken模块,然后创建一个JWT实例,最后通过实例进行用户认证和授权。
const jwt = require('jsonwebtoken');
const token = jwt.sign({ sub: user.id }, 'secret', { expiresIn: '1h' });
4. 服务端怎么做统⼀的状态处理
在服务端,实现统一的状态处理可以通过使用状态码和状态消息来实现。状态码用于表示请求的处理结果,而状态消息用于提供更详细的信息。以下是一个简单的示例,展示了如何在Node.js中使用Express框架实现统一的状态处理。
首先,我们需要安装Express框架:
npm install express
然后,创建一个名为app.js的文件,并编写以下代码:
const express = require('express');
const app = express();// 定义一个中间件来处理统一的状态处理
function handleStatus(req, res, next) {// 设置默认的状态码和状态消息res.statusCode = 200;res.statusMessage = 'OK';// 如果请求中包含自定义的状态码和状态消息,则更新它们if (req.body.statusCode) {res.statusCode = req.body.statusCode;}if (req.body.statusMessage) {res.statusMessage = req.body.statusMessage;}// 调用next()函数,将控制权传递给下一个中间件或路由处理程序next();
}// 使用handleStatus中间件处理所有请求
app.use(handleStatus);// 定义一个简单的路由处理程序
app.get('/', (req, res) => {res.send('Hello World!');
});// 启动服务器
app.listen(3000, () => {console.log('Server is running on port 3000');
});
在这个示例中,我们定义了一个名为handleStatus的中间件,它会处理统一的状态处理。当请求到达服务器时,这个中间件会检查请求中是否包含自定义的状态码和状态消息。如果存在,则更新响应的状态码和状态消息;否则,使用默认的状态码和状态消息。最后,调用next()函数将控制权传递给下一个中间件或路由处理程序。
私信【学习】即可获取前端资料 都整理好啦!!!
通过这种方式,我们可以在服务端实现统一的状态处理,确保所有的响应都遵循相同的状态码和状态消息规范。
5.如何对相对路径引⽤进⾏优化
在Web前端面试中,对相对路径引用进行优化是一个重要的问题。相对路径引用是指在HTML文件中使用相对路径来引用其他文件,如CSS、JavaScript和图片等。常见的问题包括路径过长、重复引用和不必要的层级嵌套。
解决方案之一是使用短路径。通过将文件放在根目录下或使用公共的文件夹结构,可以减少路径的长度。例如,将CSS文件放在一个名为“css”的文件夹中,然后使用<link rel="stylesheet" href="/css/style.css">来引用它。
另一个解决方案是避免重复引用。如果多个HTML文件都引用了相同的CSS或JavaScript文件,可以考虑将它们合并为一个文件,然后在每个HTML文件中只引用一次。这样可以减少HTTP请求的数量,提高页面加载速度。
此外,还可以避免不必要的层级嵌套。如果一个文件位于多层嵌套的文件夹中,可以使用绝对路径来引用它,而不是使用多个相对路径。例如,使用<img src="/images/logo.png">来引用位于根目录下的图片。
总之,对相对路径引用进行优化可以提高网页的性能和可维护性。通过使用短路径、避免重复引用和避免不必要的层级嵌套,可以有效地解决这些问题。
6.node⽂件查找优先级
在Node.js中,文件查找优先级是指在使用require()函数加载模块时,Node.js会按照一定的顺序来查找模块文件。以下是Node.js的文件查找优先级:
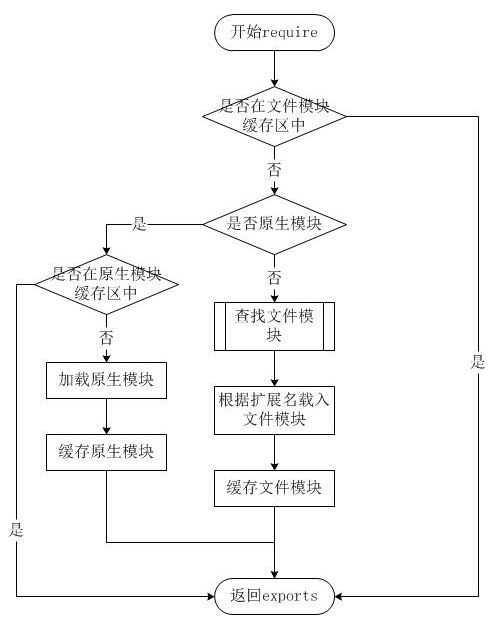
-
当前目录:首先,Node.js会在当前目录下查找模块文件。如果找到了匹配的模块文件,就会立即加载并返回。
-
node_modules目录:如果在当前目录下没有找到匹配的模块文件,Node.js会继续在node_modules目录下查找。这个目录是Node.js默认的全局模块安装位置。
-
NODE_PATH环境变量:NODE_PATH是一个包含多个路径的环境变量,用于指定额外的模块搜索路径。Node.js会按照这些路径的顺序依次查找模块文件。
-
内置模块:如果以上步骤都没有找到匹配的模块文件,Node.js会检查是否为内置模块。如果是内置模块,则直接加载并返回。
下面是一个代码示例,演示了Node.js的文件查找优先级:
// 假设当前目录下有一个名为myModule.js的文件
const myModule = require('./myModule'); // 优先从当前目录加载// 如果当前目录下没有找到匹配的模块文件,Node.js会继续在node_modules目录下查找
const express = require('express'); // 优先从node_modules目录加载// 如果仍然没有找到匹配的模块文件,Node.js会检查NODE_PATH环境变量中的路径
const customModule = require('custom-module'); // 优先从NODE_PATH指定的路径加载// 如果以上步骤都没有找到匹配的模块文件,Node.js会检查是否为内置模块
const fs = require('fs'); // 直接加载内置模块
通过了解Node.js的文件查找优先级,我们可以更好地理解模块加载的过程,并在编写代码时进行相应的优化和调整。
私信【学习】即可获取前端资料 都整理好啦!!!
7. npm2和npm3+有什么区别
npm2和npm3之间的主要区别如下:
-
依赖管理上的差异:
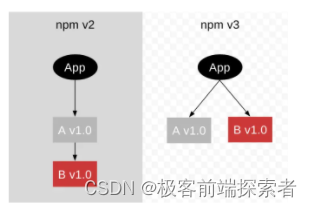
- npm2:在安装包时,会将依赖项的信息添加到dependencies属性中,而不是添加到devDependencies属性中。这可能导致在生产环境中安装不必要的开发依赖项。
- npm3:引入了扁平化依赖树的概念,所有的依赖项都会被添加到dependencies属性中。这样可以更清晰地管理依赖关系,并且可以避免重复安装相同的依赖项。
-
安装机制的不同之处:
- npm2:安装包时,会递归地解析依赖树,并按照依赖树的结构安装依赖项。如果一个包被多个项目所依赖,那么每个项目都会安装该包的副本。
- npm3:采用了扁平化的依赖树结构,所有的依赖项都会被安装在同一个层级下。这样可以减少重复安装相同依赖项的情况,节省磁盘空间和安装时间。
-
安全性方面的比较:
- npm2:没有内置的安全机制来防止恶意代码的注入或下载。用户需要手动检查包的来源和可信度。
- npm3:引入了安全机制,例如签名验证和安全漏洞扫描。这些机制可以帮助用户识别和防止安装恶意或存在安全漏洞的包。
-
性能上的改进或特点:
- npm2:在大型项目中,由于依赖树的结构复杂,安装和更新包的时间可能会较长。
- npm3:由于采用了扁平化的依赖树结构,安装和更新包的速度更快。此外,npm3还引入了一些优化措施,如缓存机制和并行安装,进一步提高了性能。
-
代码示例:
-
使用npm2进行包的安装:
npm install <package_name> -
使用npm3进行包的安装:
npm install <package_name>
-
总结起来,npm3相对于npm2在依赖管理、安装机制、安全性和性能方面都有较大的改进。它采用扁平化的依赖树结构,提高了包的安装速度和可靠性。同时,npm3还引入了安全机制,帮助用户识别和防止安装恶意或存在安全漏洞的包。
私信【学习】即可获取前端资料 都整理好啦!!!
8.knex连接数据库响应回调
当使用knex.js库连接数据库时,首先需要安装knex和相应的数据库驱动。以下是一个示例代码段,演示如何使用knex.js进行数据库连接以及处理响应回调:
// 导入knex模块
const knex = require('knex');// 配置数据库连接信息
const dbConfig = {client: 'mysql', // 数据库类型,这里以MySQL为例connection: {host: 'localhost', // 数据库主机地址user: 'your_username', // 数据库用户名password: 'your_password', // 数据库密码database: 'your_database' // 数据库名称}
};// 创建数据库连接实例
const db = knex(dbConfig);// 执行查询操作
db.select('*').from('your_table').then(rows => {// 处理查询结果console.log(rows);}).catch(error => {// 处理错误情况console.error(error);}).finally(() => {// 关闭数据库连接db.destroy();});
在上述代码中,我们首先导入了knex模块,并定义了数据库连接的配置信息。然后,通过调用knex(dbConfig)来创建一个数据库连接实例。接下来,使用select方法指定要查询的列,from方法指定要查询的表。最后,使用then方法处理查询结果,catch方法处理错误情况,finally方法确保在完成查询后关闭数据库连接。
请注意,在实际项目中,你需要根据自己的数据库类型和配置信息修改dbConfig对象中的相关字段。此外,还可以根据具体需求使用其他knex.js提供的方法,如插入、更新、删除等操作。