目录
实验目的:
实验原理:
实验准备:
实验步骤与内容:
参考代码:
实验目的:
- 依托语音信号处理领域的声学特征提取任务,学习常用的语音信号处理工具,实现对语音数据的预处理和常用特征提取等操作;
- 熟悉掌握安装和使用各种语音信号处理 python 库的方法;
- 熟练掌握 matplotlib.pyplot 库绘制多图的方法。
实验原理:
语音是声音的一种,是由人的发声器官发出,具有一定语法和意义的声音。大脑对发音器官发出运动神经指令,控制发音器官各种肌肉运动使空气振动,空气由肺进入喉部,经过声带激励,进入声道,最后通过嘴唇辐射形成语音。
目前语音领域的任务主要有语音识别(Speech Recognition)、说话人识别
(Speaker Recognition)、语种识别、语音合成等。语音识别是当前人工智能比较热门的方向,技术比较成熟。各大公司也相继推出了各自的语音助手机器人, 如百度的小度、阿里的天猫精灵等。
语音的相关算法主要依靠机器学习和深度学习技术做支撑。但在训练模型之前,需要先将音频文件数据化,对音频进行预处理、转换到频率域得到频谱图, 再提取其中的语音特征。流程如图 6.1 所示。其中,最常用到的语音特征是梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)。

图 6.1 语音信号处理流程图
1.预处理
根据需要预先对音频信号进行一些处理,比如为了降低数据量将音频由多声道转为单声道、进行下采样等,还有预加重、标准化、去除静音等。
预加重处理是将语音信号通过一个高通滤波器:
![]()
式中 μ 的值介于 0.9-1.0 之间,我们通常取 0.96。预加重的目的是提升高频部分,使信号的频谱变得平坦,移除频谱倾斜,来补偿语音信号受到发音系统所抑制的高频部分。同时,也是为了消除发生过程中声带和嘴唇的效应。(因为口唇辐射可以等效为一个一阶零点模型)
2.频谱图
因为语音信号为短时平稳信号,所以需要进行分帧处理,以便把每一帧当成平稳信号处理。先将 N 个采样点集合成一个观测单位,称为帧。通常情况下 N 的值为 256 或 512,涵盖的时间约为 20~30ms 左右。为了避免相邻两帧的变化过大,因此会让两相邻帧之间有一段重叠区域,此重叠区域包含了 M 个取样点, 通常 M 的值约为 N 的 1/2 或 1/3。通常语音识别所采用语音信号的采样频率为8KHz 或 16KHz,以 8KHz 来说,若帧长度为 256 个采样点,则对应的时间长度是 256/8000×1000=32ms。
语音在长范围内是不停变动的,没有固定的特性无法做处理,所以将每一帧代入窗函数,窗外的值设定为 0,其目的是消除各个帧两端可能会造成的信号不连续性。常用的窗函数有方窗、汉明窗和汉宁窗等,根据窗函数的频域特性,常采用汉明窗。将每一帧乘以汉明窗,以增加帧左端和右端的连续性。
再对每一帧信号进行快速傅里叶变换,即可得到整条语音的频谱图如图 6.2所示。

图 6.2 频谱图
3.MFCC
MFCC 依据以下两点对人耳听觉系统建模:1、声音的真实频率和人耳对其感知的高低不是成正比的,当 f<1000Hz 时,人耳感知随声音实际频率线性分布, 当 f>1000Hz 时,呈对数分布。2、当两个频率接近的音调同时发出时,只能听到一个。
![]()
式中 f 为频率,单位为 Hz。
图 6.3 给出 Mel 频率与线性频率的关系。
图 6.3 Mel 频率和线性频率的关系

图 6.4 计算 MFCC 的流程图
MFCC 的计算基本步骤如图 6.4 所示。在得到频谱图之后,需要将能量谱通过一组 Mel 尺度的三角形滤波器组。定义一个有 M 个滤波器的滤波器组(滤波器的个数和临界带的个数相近),采用的滤波器为三角滤波器,中心频率为 f(m), m=1,2,...,M。M 通常取 22-26。各 f(m)之间的间隔随着 m 值的减小而缩小,随着m 值的增大而增宽,如图 6.5 所示。
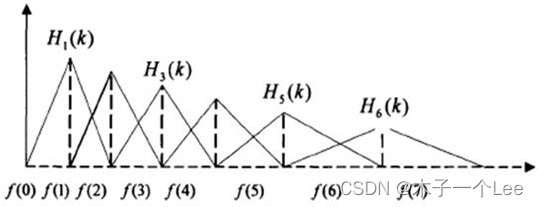
图 6.5 Mel 三角形滤波器组
三角滤波器的频率响应定义
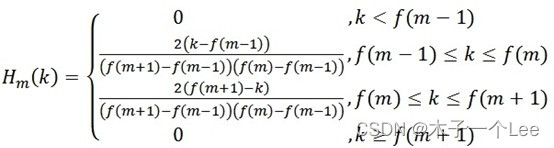
其中:
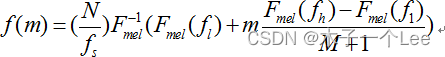
三角带通滤波器的主要目的是对频谱进行平滑化,并消除谐波的作用。此外还可以减少运算量。在 MATLAB 的 voicebox 工具箱中有 melbankm 函数可用于计算 Mel 滤波器组。
计算每个滤波器组输出的对数能量为:
![]()
经离散余弦变换(DCT)得到 MFCC 系数:

将上述的对数能量带入离散余弦变换,求出 L 阶的Mel-scale Cepstrum 参数。L 阶指 MFCC 系数阶数,通常取 12-16。这里 M 是三角滤波器个数。
实验准备:
1.pydub库
Pydub 提供了简洁的高层接口,极大的扩展了python 处理音频文件的能力, pydub 可能不是最强大的 Python 音频处理库,但绝对是 Python 最简洁易用的音频库,其功能足以满足大多数情况下的音频处理需求,但是 Pydub 库高度依赖ffmpeg,需要在使用前安装 ffmpeg。
Pydub 的核心功能大部分都在 pydub/audio_segment.py 中。使用 pydub,可以实现分割音频片段、改变音量大小、连接音频片段、添加淡入淡出效果等功能。
2.python_speech_feature 库
Python_speech_feature 是一个用于音频特征提取的 python 工具包,擅长音频信号处理。包含了一些常用的频谱特征的提取方法,比如常见的Mel Spectrogram、MFCC、CQT、chroma 等。
实验步骤与内容:
1.安装工具包
常用的语音工具包有 pydub、python_speech_feature 等,使用 pip install 安装即可。
对于 pydub 库,由于其高度依赖 ffmpeg,所以需要首先安装 ffmpeg,下载地址: Download FFmpeg。解压之后配置环境变量(右击此电脑 -> 属性 -->高级系统设置 -->环境变量—>将解压的 bin 目录路径添加在系统的 path 变量里),运行 cmd,输入 ffmpeg 测试安装是否成功。如出现下图 6.6, 则表示安装成功。
图 6.6 ffmpeg 安装成功
2.音频预处理
录制音频文件的软件大多数都是以 mp3 格式输出的,但 mp3 格式文件对语音的压缩比例较重,因此一般需要先将 mp3 转化为 wav 文件。首先,随意选取并下载一条 mp3 格式的音乐音频***.mp3,并将其转换成采样率为 16kHz wav 格式***.wav;然后,读取音频文件,如果音频不足 5s,重复该音频满足时长大于 5 秒,然后随机选取其中的 5s 片段,重复 3 次,再对首尾添加 3s 的淡入淡出,得到新的音频文件***_new.wav。(pydub 库)
所用接口:from_mp3()、from_wav()、set_frame_rate()、fade_in()、fade_out()、export()
3.特征提取
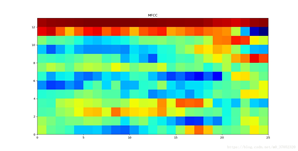
计算得到新音频文件的频谱图、fbank 和梅尔倒谱系数,并将新音频文件的时域波形图、logfbank 和梅尔倒谱系数绘制在一张图中,如图 6.7 所示。(python_speech_feature 库提取特征),如果输入音频是多通道,则只对第一个通道进行处理和展示。(logfbank 和 mfcc 特征均采用汉明窗作为窗函数,并将原始信号、logfbank 和梅尔倒谱系数在一行展示。)
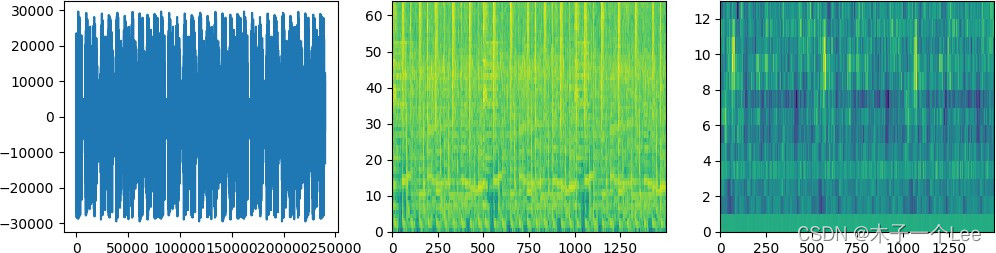
图 6.7 结果样例
音频读取:scipy.io.read() 特征提取:fbank()、mfcc()
绘图:matplotlib.pyplot.figure() 、 add_subplot(), matplotlib.pyplot.plot(), matplotlib.pyplot.pcolormesh()等接口
参考代码:
#python6_1
import random
from pydub import AudioSegment
#mp3转wav
s1 = AudioSegment.from_mp3("Hans Zimmer - 荣耀主题.mp3")
s1.export("Hans Zimmer - 荣耀主题.wav", format="wav")
s2=AudioSegment.from_wav("Hans Zimmer - 荣耀主题.wav")
s3=s2.set_frame_rate(16000)#转换成采样率为 16kHz wav
t = s3.duration_seconds #获取音频文件时长
while t<5:s3+=s3t+=s3.duration_seconds
five_seconds = 5000#以毫秒为单位
n=random.randint(0,150000)
m=n+five_seconds
s4=s3[n:m]+s3[n-2000:m-2000]+s3[n+10000:m+10000]
s4=s4.fade_in(3000)
s4=s4.fade_out(3000)
s5=s4.set_channels(1)#转换成单音道
s5.export("Hans Zimmer - 荣耀主题new.wav", format="wav")#python6_2
import matplotlib.pyplot as plt
import scipy
from scipy.io import wavfile
from python_speech_features import mfcc, logfbank, fbank
import wave
# 读取输入音频文件
(a, b) = wavfile.read("Hans Zimmer - 荣耀主题new.wav")
# 提取MFCC和滤波器组特征
mfcc_features = mfcc(b, a).T
filterbank_features = logfbank(b, a).T
# 梅尔倒谱系数
fig=plt.figure(figsize=(13,5))
a1= fig.add_subplot(133)#1行3列第3个
# a1.plot(mfcc_features)
#logfbank
a2=fig.add_subplot(132)#1行3列第2个
# a2.plot(filterbank_features)
#时域波形图
a3= fig.add_subplot(131)#1行3列第1个
a3.plot(b)
a1=a1.pcolormesh(mfcc_features)
a2=a2.pcolormesh(filterbank_features)
plt.show()
效果: