要问现在AI领域哪个概念最热,必然是openAI推出chatGPT之后引发的大模型。然而这项技术的起源,都来自一篇google公司员工的神作“Attention Is All You Need”——本文标题也是一种致敬^_^,目前已有近12万的引用(还在增长)。

在“Attention Is All You Need”中介绍了一种新的神经网络架构,被命名为变形金刚(也可以叫变压器,只是不那么cool)的Transformer,并应用到语言翻译中取得了很好的效果。这之后,基于Transformer架构的技术层出不穷,不仅在语言翻译中,在图像处理、语音处理、问答系统中都得到了广泛应用,chatGPT就是其中的明星应用。
本文将结合一个中译英例子,通过一步步的节点计算介绍,将这篇论文中提到的Transformer模型进行阐述,后文提到的“原文”就是指代“Attention Is All You Need”这篇论文。
鸟瞰框架
Transformer的模型架构主要由两部分组成,如下图中左边的框是编码器(Encoder),右边的框是解码器(Decoder)。
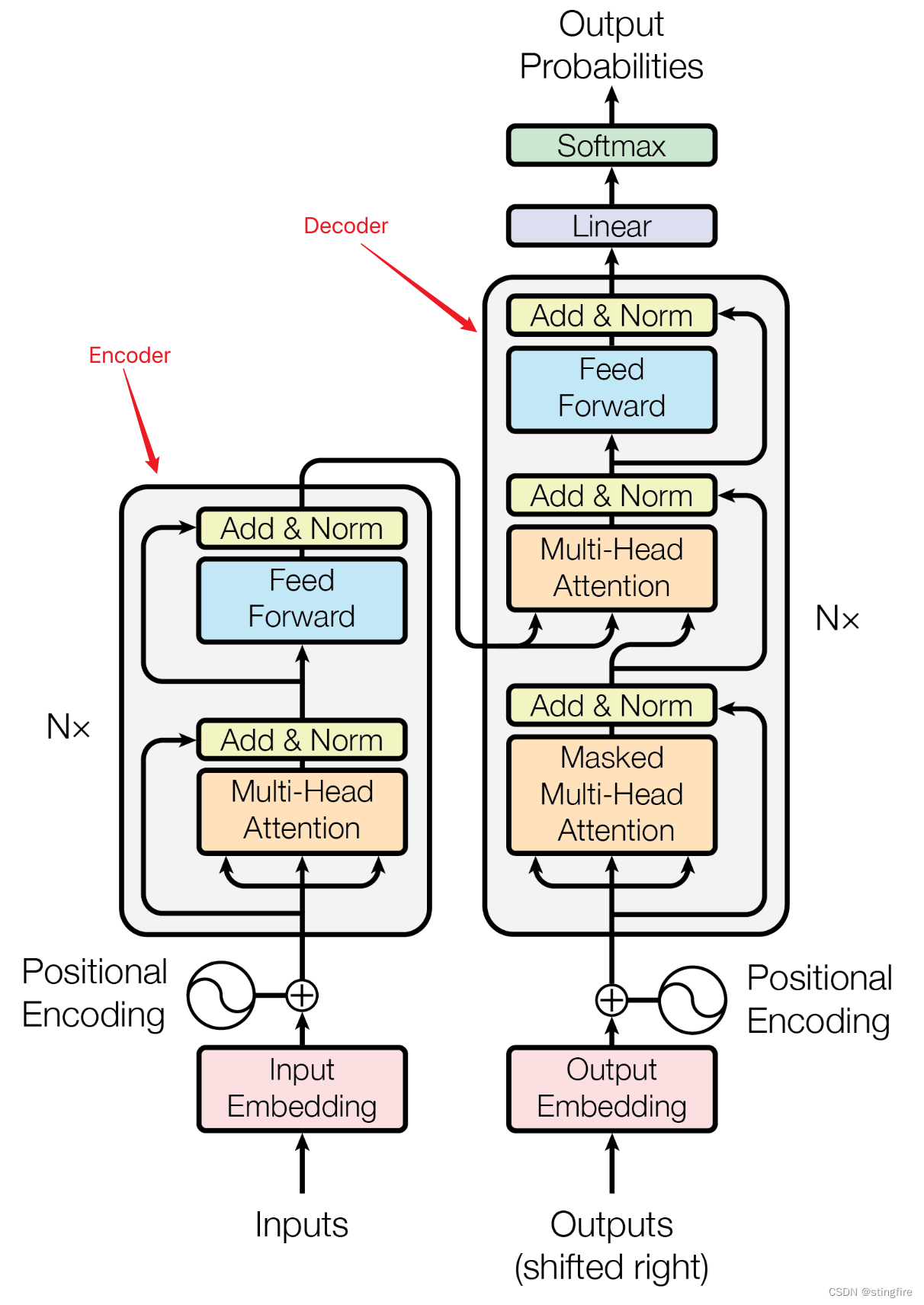
我们先忽略其中的细节,从最顶层鸟瞰Transfromer结构是这样的(原文N等于6):
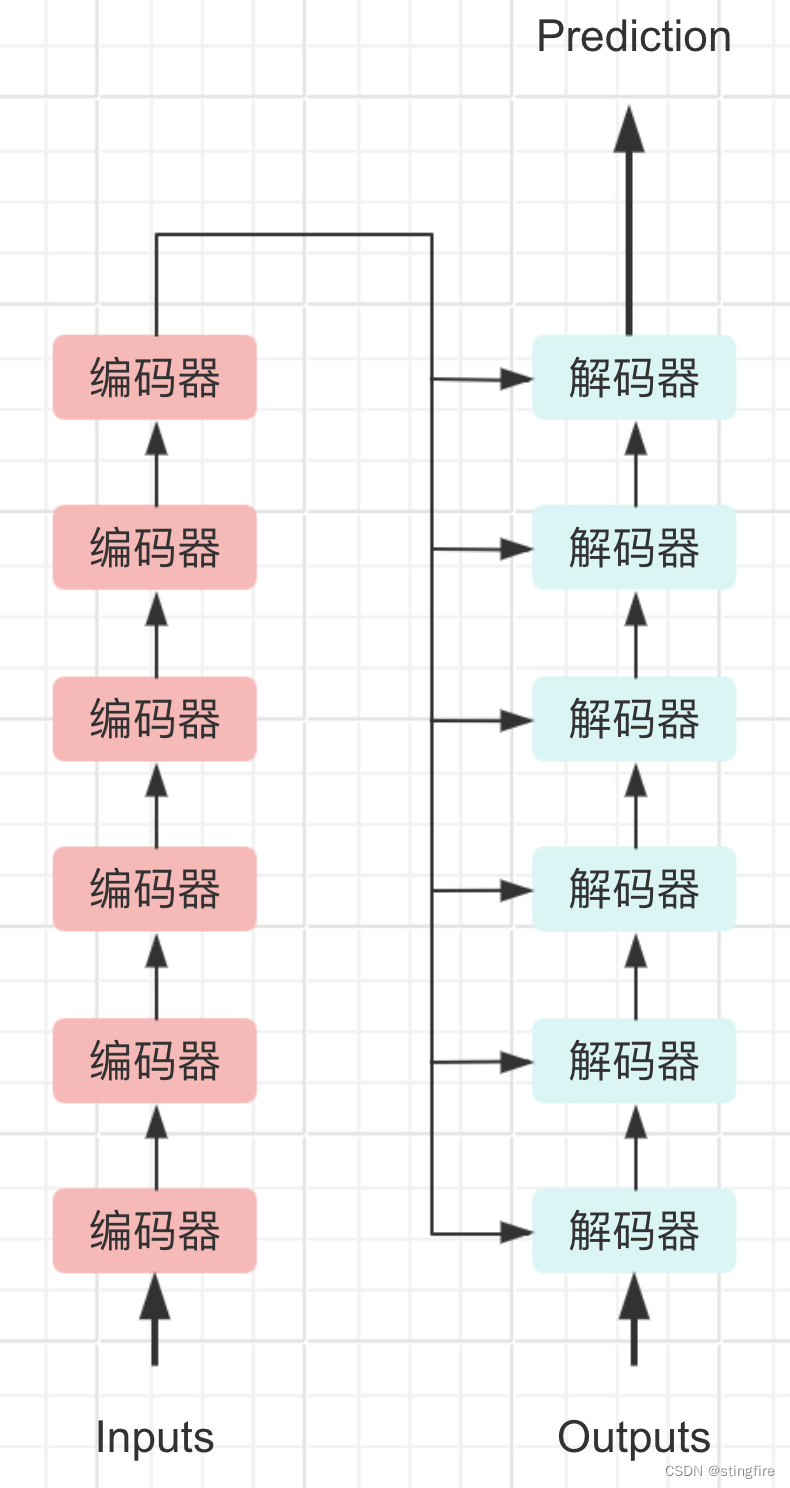
输入序列经过N(原文中取值6)层的编码后,产生的编码矩阵结果输入到后续的解码器中,同时将经过嵌入和线性变换处理的输出依次也输入第一层的解码器中,最终产生一个预测值。该预测值和样本之间的差用于权重矩阵的训练,最终得到我们需要的模型。
整个Transformer需要经过如下步骤的计算:
- 数据输入编码器和解码器前的处理
- 输入输出序列的词嵌入(Embedding)
- 位置编码(Positional Encoding)
- 编码器层
- 编码器中多头注意力子层
- 编码器中前馈子层
- 解码器层
- 解码器中多头注意力(掩码)子层
- 解码器中多头注意力子层
- 解码器中前馈子层
- 输出预测值
- 线性层
- Softmax层
下面从输入序列开始,逐层讲解Transformer的结构和计算。读者需要具备一些基础的线性代数知识(矩阵概念、向量及矩阵乘法)和神经网络知识(网络连接、激活函数、规范化等)。
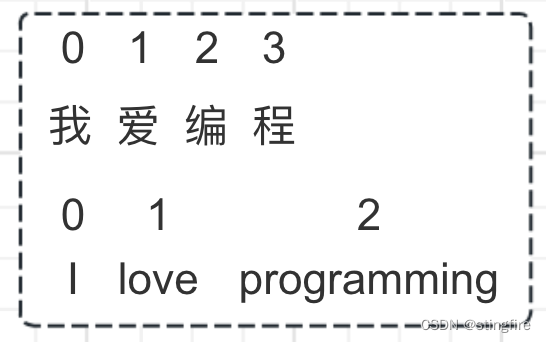
我们以一个中译英的任务举例,将“我爱编程”翻译成"I love programming"。把中文“我爱编程”拆开看成“我”(位置0)“爱”(位置1)“编”(位置2)“程”(位置3),英文为"I"(位置0)"love"(位置1)"programming"(位置2),如下图所示:
输入的嵌入层
也就是下图中红框部分:

输入Embedding
我们知道计算机并不能直接处理文字,它擅长的只是数值计算,因此我们需要将输入的字符进行编码才能输入到Transformer中。那能否用1、2、3依次编号这些文字呢?答案是不行。因为这只是形式上转成了数字,但每个词之间的关系并不能得到体现。比如“苹果”和“香蕉”,假设它们的编号分别是9527,9528,这看上去他们距离很近应该属于很相近的两个东西(反之,如果编号相差很大也一样存在可能意思相近的上下文)。但“苹果”要是出现在“手机”前,那它跟水果“香蕉”就应该相差很远。
怎么在上下文中体现词与词之间的相似性呢?它的编码就需要进行大量数据的训练,使得词与词之间的关系可以通过这种编码的数值关系来表达出来,在NLP领域就叫这个为embedding(中文翻译有叫嵌入,也有叫编码,大家自行根据上下文理解,本质上都是将文字转换成一个数值向量),比如谷歌开源的Word2Vec工具包就是做这个工作的。
通过embedding,输入的一个个词(实际处理中使用token,也就是先token化,此处简化将token等同为单词)就转换成了向量。也可以先初始化为随机向量,然后在训练Transformer时更新embedding值。原文中使用的是已学习好的embedding方法。
假设我们的embedding模型将输入的词转成的向量维度是512(原文选择的值),则“我爱编程”的每个词转成512维的向量如下所示。
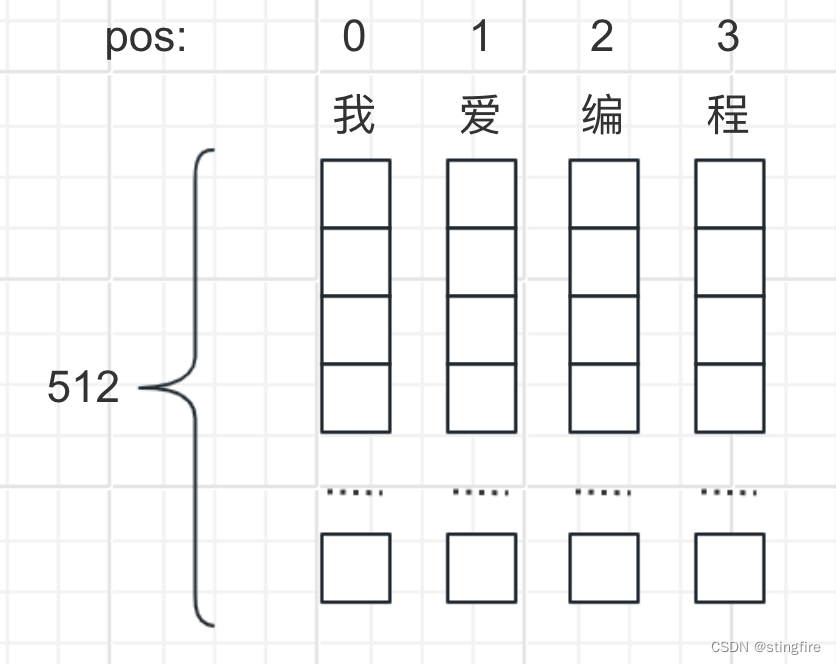
实际应用中,这些向量会拼接一块作为输入矩阵,这里的
为序列长度(这里
),
是embedding模型长度。
位置编码(Positional Encoding)
输入的序列通过embedding转成向量后不能直接进行后续运算,因为相较于RNN,这里体现不出每个词的位置信息。举例来说“我吃梨”跟“梨吃我”转成的是相同的3个向量,但显然前后两句的主语和宾语是不一样的。为了解决这个问题,需要引入位置信息,即“我吃梨”中的“我”在第一位,“梨”在第三位,这个信息的引入就是位置编码。原文中通过计算来获得,计算公式如下:
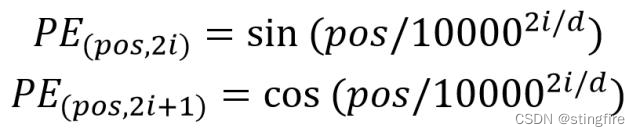
其中pos是单词在句子中的位置,比如“我爱编程”中的“我”的pos取值0,“爱”的pos取值1;d是位置编码后向量的维度,取跟输入embedding维度相同,所以这里是 512;i是向量维度的索引,这里的两个公式说明对第偶数维的值采用sin计算,对第奇数维的值采用cos计算。假设“我”的embedding后为(0.85, 0.34, 0.5, 0.61,......)的512维向量,分别计算每一维的位置编码后得到的向量是:
,这个位置编码向量也是512维的。
通过将词嵌入embedding向量和位置编码向量相加,得到的向量就是将输入编码器的输入向量x。如果将所有词的embedding和位置编码向量相加放到一个矩阵中,我们就可以最大化利用GPU的矩阵并行运算能力,这时的输入就是矩阵X,它是多个向量的拼接,即:
,
这里的是embeding的个数即序列长度,此处为4(“我爱编程”的词序列长度),所以
是个4*512的矩阵。
编码器多头注意力机制(Multi Head Attention)
本节我们介绍多头注意力机制,也就是框架图中红框所示部分,当输入经过嵌入和位置编码后首先进入的这个节点:
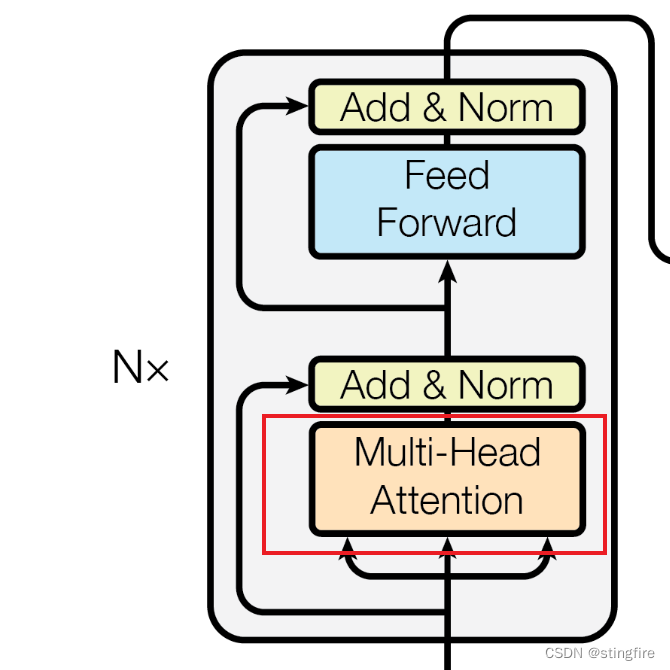
这是原文的一个创新点。在这里假设读者掌握向量及矩阵乘积的数学知识,如果能了解向量距离的概念就更好了。
注意力机制(Attention)
字面上理解,注意力就是我们观察对象中的重点部分。当我们从一张图片中去找寻一个对象时,我们会先大致在图片中搜寻色块形状相近的区块,然后再细节判断刚才的区块是否我们找寻的对象,那个查找相近区块过程就是注意力机制。
再拿我们从数据库中查询信息的过程打比方,我们输入的查询语句(Query)会先查询索引(Key),找到匹配项下的值(Value)并返回。如何用数学公式来表示这个过程呢,这就是注意力机制描述的事情。我们注意到整个过程离不开怎么定义匹配,换句话说如何定义Q(文中后续用Q简单代指Query,类似K代替Key, V代替Value)与K和V的相近程度呢?越相近就越匹配,就越需要我们注意。
两个向量之间的相似度可以用他们在向量空间中的距离来表示。定义距离的方法有很多种,原文中使用的是点积,如下图所示:

细心的读者会发现这个图的标题是“Scaled” Dot-Product Attention,这个缩放是在点积结果上除以得到,
是矩阵Q、K的向量维度(原文中是512),表示成数学公式形式即为:
![]()
这里的Q、K、V分别是嵌入层处理后的输出乘以对应的权重矩阵得到的,即:
。
其中,是输入序列经embedding和positional encoding之后得到的向量拼接而出的输入表示矩阵,
、
(Q和K具有相同的
)和
为权重矩阵,这里的
是embedding时的维度(本文即为512),而
和
可以任意选择(原文中应用到多头注意力机制中,选择的是值为64,介绍多头注意力机制时再解释)。初始化这些矩阵为随机矩阵,在后续的训练中会不断更新权重值。
通过注意力机制,我们就能获得每个词在句子中跟其他词之间的相似度,值越大表明相关性越高。由于这里是计算整个句子中各个词间的相关性,包含了自身的计算,所以又叫自注意力(Self-Attention)。
上图中有个Mask节点,在编码器中不使用,主要在解码器中有一个多头注意力子层在接受输出序列embedding时使用,后面再介绍。
多头注意力机制(Multi Head Attention)
上述的注意力机制是对一组(Q,K,V)的计算,原文作者发现采用多个这样的权重矩阵来处理输入会取得更好的结果。即通过多组(,
,
)来计算对应的Q、K、V:
如下图即使用了h个(,
,
),这里原文使用的h值为8。将
进行h等分,得到
。
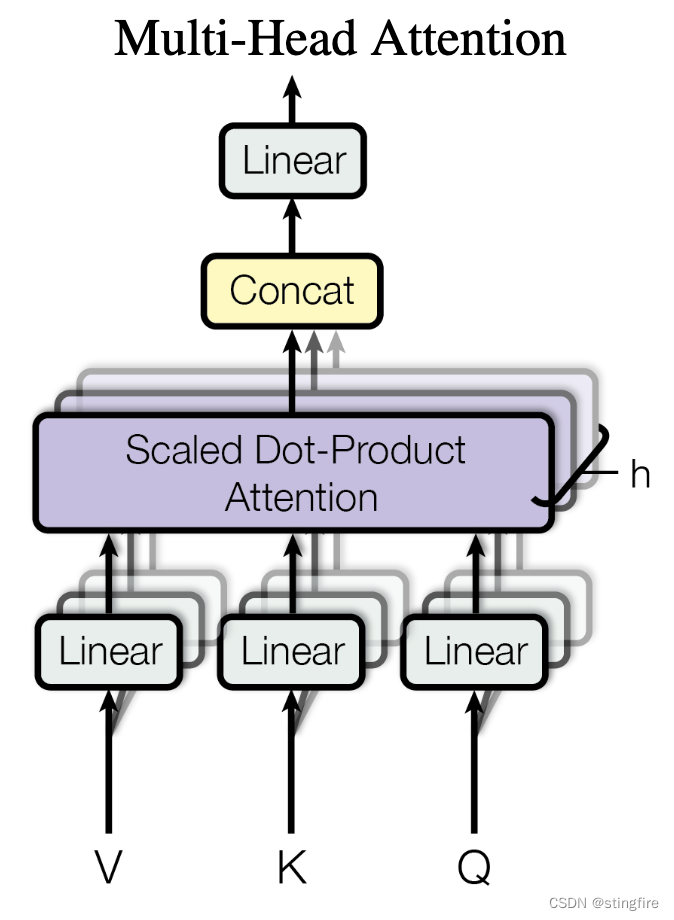
整个过程相当于一个输入X经过h组(Q、K、V)的线性变换后分别输入对应的单头注意力进行计算,再将各个注意力计算出来的结果拼接(Concat)到一块,乘以一个矩阵(本文中
为行值8*64,列值为512,即
是一个512*512的矩阵)进行线性变换后输出。
也是一个初始化为随机值的矩阵,用于训练更新。
使用公式表达即为:

其中一个head计算出来的结果为4*64的矩阵,h=8个head计算的结果拼接成一个4*512的矩阵。乘以这个512*512的矩阵后,结果是一个4*512的矩阵。
为什么要使用多头注意力机制呢?这就类似卷积神经网络中使用多个卷积核来提取不同特征一样,多头注意力机制能够获取到输入序列中不同的信息进行学习。
同时多头注意力不同于RNN,它是可以多个head同时进行计算,这大大提高了计算的并发性,提升了计算效率。
Add&Norm
在框架图中我们看到经过多头注意力计算后的结果需要经过“Add&Norm”节点。如下图红框所示:
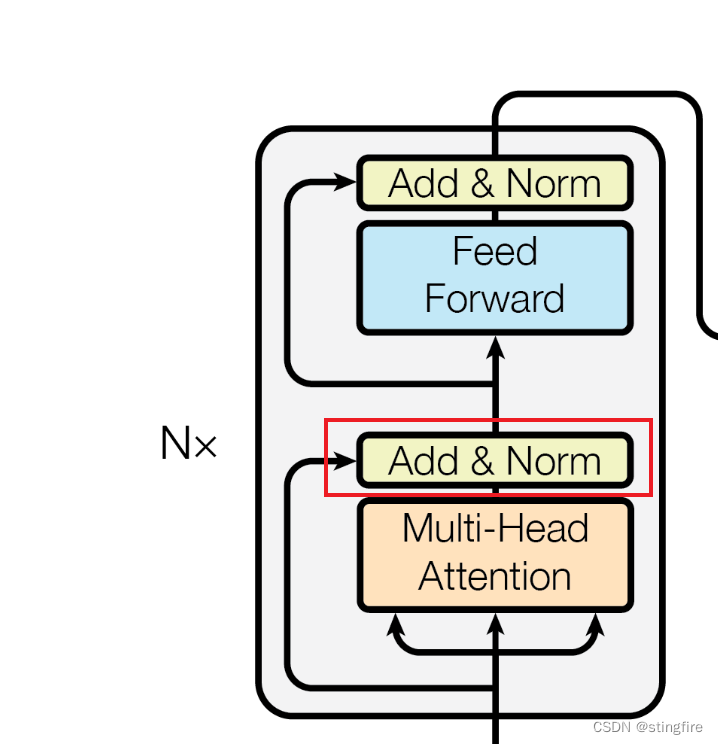
这里是两个计算操作:
- 残差求和
- 层规范化
通过残差求和与层规范化处理,能很好抑制梯度消失和爆炸,提升模型的质量。
残差求和
使用残差网络连接是一项神经网络老艺能了,主要是为了减少网络退化并提升训练效果的方法。残差求和即将输入的X和经过多头注意力机制计算的结果求和。
层规范化
Layer Normalization与Batch Normalization方法不同,它对单个样本进行规范化。具体操作就是对矩阵中每一层样本x求均值和方差
:
这时计算每一个样本x规范化值的公式是:
实际使用中会引入两个学习参数和
,在训练中进行更新,这时规范化值的计算是:
我们例子中的X和多头注意力结果做残差求和后是4*512的矩阵,因此需要做4次在512维样本上的规范化计算。
Add&Norm层的公式表达为:
前馈层(Feed Forward)
通过编码器第一个子层之后,下一个编码器子层就是前馈层。
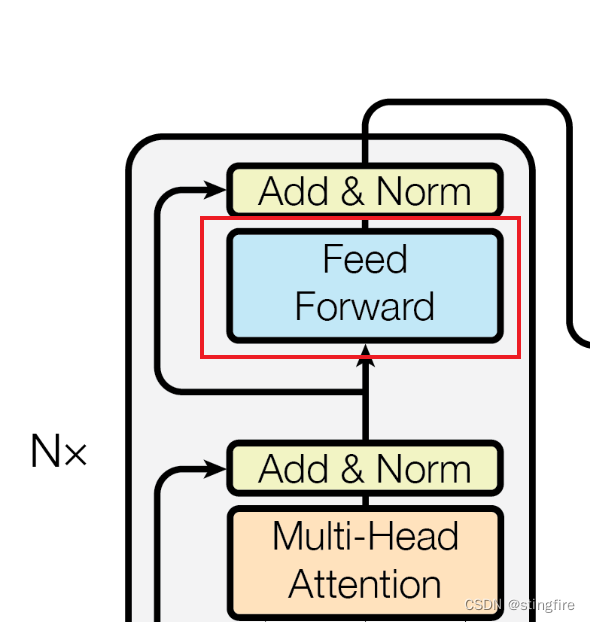
前馈层比较简单,是一个两层的全连接层,第一层使用ReLU作为激活函数,第二层不使用激活函数,仅做线性变换。数学公式表达即为:
前馈层之后又做一次Add&Norm,所以这次的Add&Norm公式是:
具体计算公式跟前面的Add&Norm是一样的,不再赘述。
至此,我们完成了编码器其中一个Layer的计算,这个Layer的输出将输入到下一个Layer中作为输入X。这样的Layer有N个(原文中N取值为6),我们只需要将前一个编码器Layer的输出作为下一个编码器Layer的输入,反复计算,得到最终的编码输出矩阵。
以上是编码器部分,在某些应用场景下,比如特征提取,可以单独拆出编码器使用。在翻译任务中,需要将编码的内容解码,下面开始计算解码器部分。
Outputs嵌入层
在介绍解码器层的计算前,我们注意到输入到解码器的Outputs和输入到编码器的Inputs既相似又有不同。如红框所示:
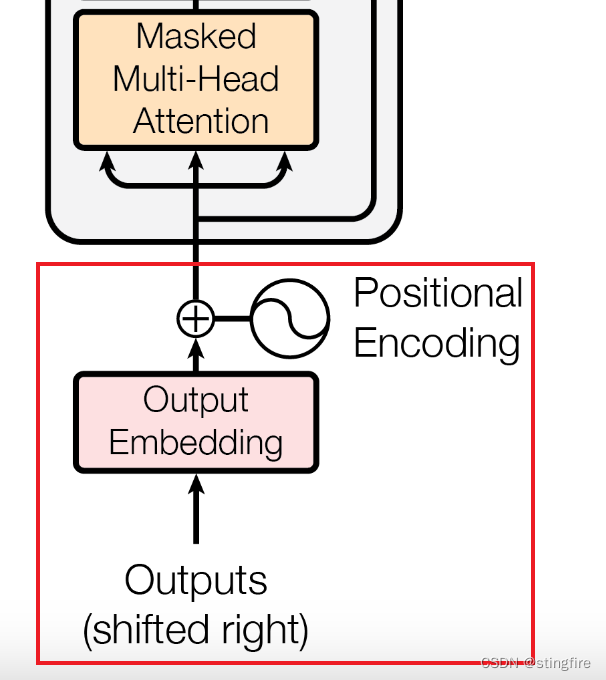
相同的是它也需要进行Embedding和Positional Encoding两步操作,这里不再赘述,大家可以翻看前面“输入的嵌入层”内容。
与Inputs不同的是下面有个标注“(shifted right)”,这是因为在翻译任务中需要根据之前的预测来计算预测下一个输出。为了让解码器能感知到输出语句的开始和结束,需要引入<start>和<end>两个标志token,所以咱们的例子是:

上图中,首先"<start>"的嵌入及位置编码输入解码器第一个多头注意力层,预测的目标值是"I"。第二次计算预测值时,将"<start> I"的嵌入及位置编码输入解码器第一个多头注意力层,预测的目标值是"love"。如此直到遇到"<end>"完成解码计算。
实际计算中是将"<start> I love programming"编码转换后一并输入多头注意力层,但这样会出现一个问题,就是我们预测"love"的时候,它只依赖"<start> I",而不能预先知道"programming"。也就是第i个字符的预测依赖[0, i]这段的注意力值,而需要摒弃i之后的字符。这就需要引入掩码矩阵。
解码器掩码多头注意力机制(Masked Multi-Head Attention)
这是解码器的第一个多头注意力层,如下图红框中所示:
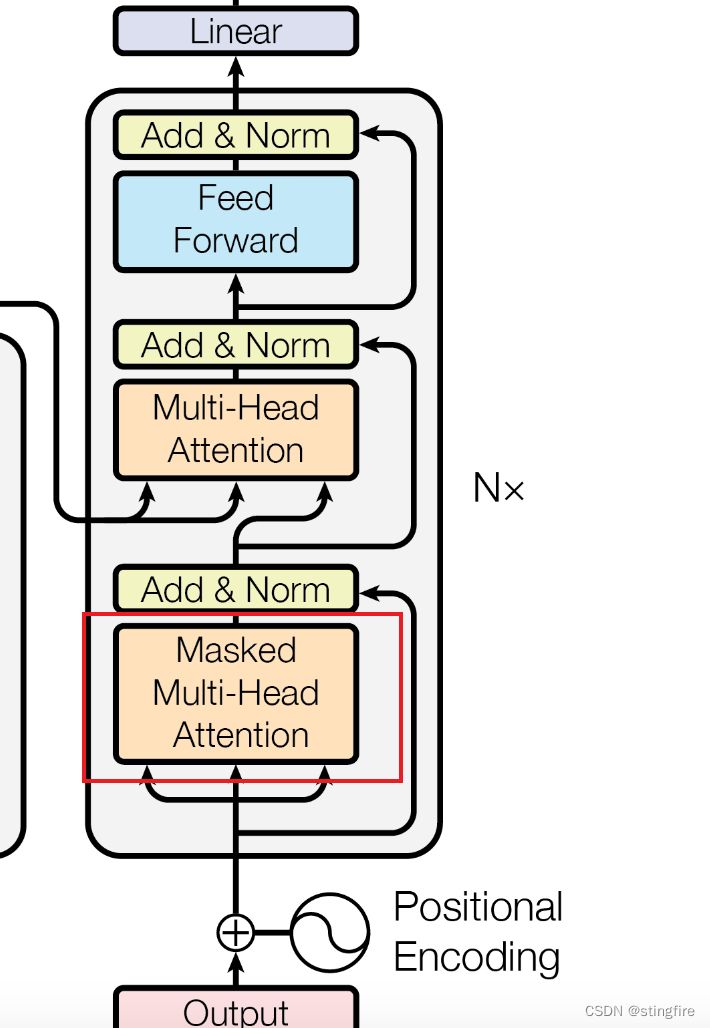
与编码器中的多头注意力计算相似,分别计算它的h组(Q、K、V)线性变换,计算过程可以参考编码器多头注意力机制一节的内容。不同的是这次在注意力计算之后需要再进行掩码运算,也就是前面提到的一个可选Mask节点在编码器中没有使用,在解码器中这个就必须应用上,用来防止预测第i位字符时“偷看”了i之后的预测值。
具体做法可以给运算结果乘以矩阵
,这样保留i及之前的注意力值。也可以像原文那样做相加运算,不过上述矩阵1的位置改为0,0的位置改为一个很大的负数
,这样矩阵相加后i之后的位置影响也被消除。
编码器输入的多头注意力机制
这一层的注意力值计算方式跟编码器中的多头注意力机制类似,不同的是Q来自解码器前面掩码多头注意力层的输出计算线性变换后得到,K和V来自编码器输出的结果线性变换后得到。其他计算与之前的多头注意力计算并无二致。
这一层的作用是在解码时也引入了编码器的输入信息,将输入和第i个位置之前的输出结合起来预测第i+1位的输出。
解码器中前馈层及Add&Norm运算和前面编码器中介绍的对应内容是一样的,此处不再重复介绍。总之经过一系列的注意力值和Add&Norm及前馈运算,如此反复N次(原文中N为6),最终数据来到线性层及Softmax层。
线性和Softmax预测
完成解码器的运算之后,结果矩阵Z是一个行数与解码器输入字符数(本文为3)一致、列数为任意某一个值的矩阵。矩阵Z将进行线性运算和Softmax计算得到预测值,如下图红框中所示部分:
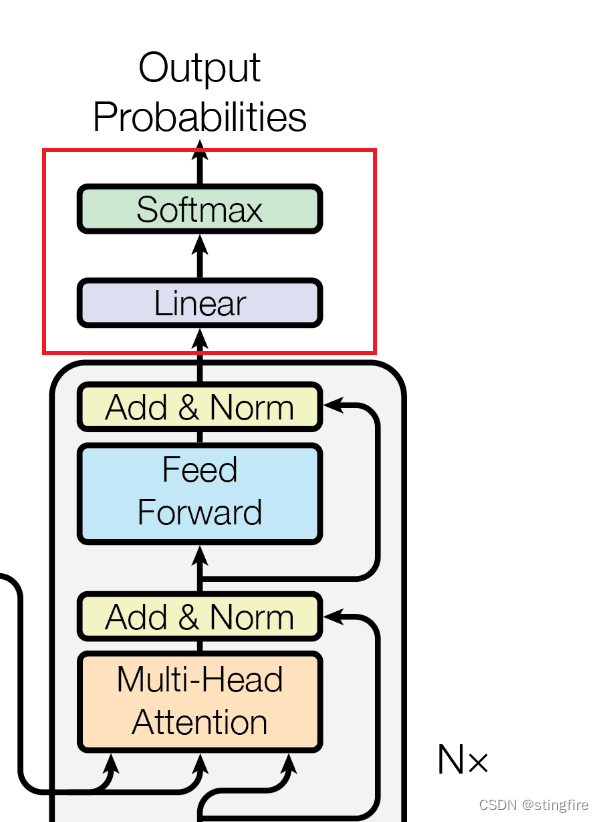
Linear层
线性层的目的是将解码器的输出矩阵Z计算出一个logits向量,表示词库中各词的分值。首先将Z的每行打平,假设,其中l是输入字符数(此处为3),m是选择的值,假设为64。则将Z打平为一个
的向量(3*64=192)。
上式中,n为目标词库的大小(比如这里翻译成英文,所以词库可以设置为某英文词库大小)。
Linear层计算出logits向量,对词库中每一个对应的词都提供了表示相关性的数值。
Softmax层
经过Linear层计算的结果,需要进行softmax计算来确定每个词对应的概率,最高概率所在位置的词即为预测的词。Softmax函数定义如下:
其中和
为第i和第j位上的logits值,
为对应logits向量第i维度上的softmax值。由此得到的向量中,以最大值所在位置为索引从词库中查找对应的词即为预测到的目标词。
后记
至此,我们完成了所有Transformer各层的计算。这里只简单介绍了每一步的计算方法,并没有讲解如何train和validation和test,只是提供一种理解Transformer这个模型架构的思路。参考资料中2和3相关示例和视频,可以相互借鉴。
当然,这是Transformer初次提出的论文内容,其结构中依然有很多需要改进的地方,还有一些更多的应用场景。关于Transformer的综述,可以看看参考资料4。
参考资料
- Attention Is All You Need
- Solving Transformer by Hand: A Step-by-Step Math Example
- Transformers for beginners | What are they and how do they work
- A Survey of Transformers