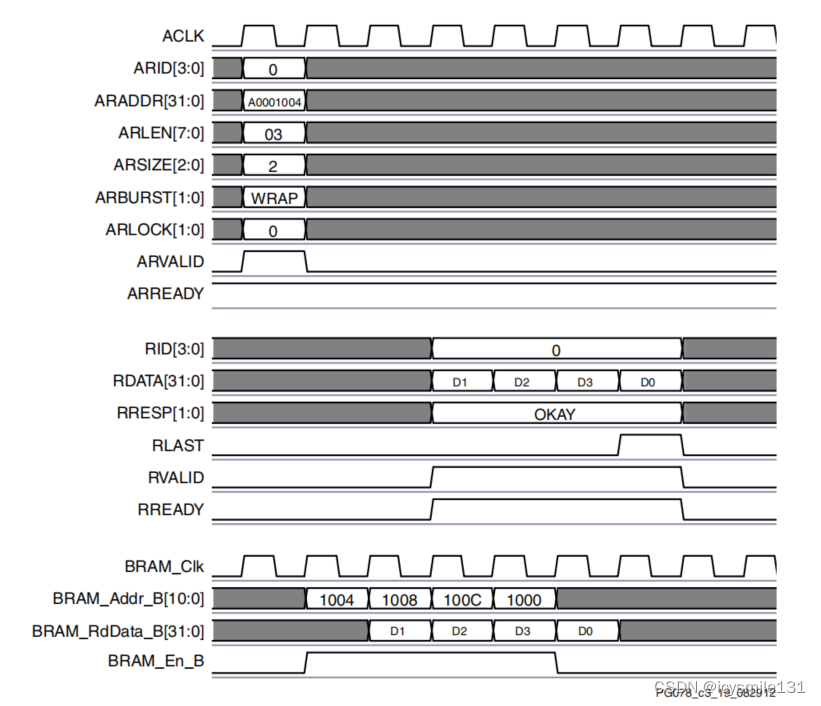
RNN 模型
与前后顺序有关的数据称为序列数据,对于序列数据,我们可以使用循环神经网络进行处理,循环神经网络RNN已经成功的运用于自然语言处理,语音识别,图像标注,机器翻译等众多时序问题;RNN模型有以下类别:
![![[RNN.jpg]]](https://img-blog.csdnimg.cn/direct/0743f03aa4674332aa89e8a2c81cff25.png)
SRNN模型
对于全连接模型, X ∈ R n d X \in \mathcal{R}^{nd} X∈Rnd, W X ∈ R d h W_X \in \mathcal{R}^{dh} WX∈Rdh, B ∈ R 1 h B \in \mathcal{R}^{1h} B∈R1h : H = f ( X W X + B ) H=f(XW_X+B) H=f(XWX+B)
有 H ∈ R n h H \in \mathcal{R}^{nh} H∈Rnh,当 X i ∈ R 1 d X_i \in \mathcal{R}^{1d} Xi∈R1d,有 H i = f ( X i W X + B ) H_i = f(X_iW_X+B) Hi=f(XiWX+B)
为了让隐藏层当前位置结合上一个位置的信息,我们可以把函数更改为: H i = f ( X i W X + B + H i − 1 ) H_i=f(X_iW_X+B+H_{i-1}) Hi=f(XiWX+B+Hi−1)
这样上一个位置的信息不够灵活,为了让信息更加灵活,最好也给上一个位置的信息加个权重进行处理,有 H i = f ( X i W X + H i − 1 W H + B ) H_i=f(X_iW_X+H_{i-1}W_H+B) Hi=f(XiWX+Hi−1WH+B)
最后优化一下: H i = f ( [ X i , H t − 1 ] W + B ) H_i=f([X_i,H_{t-1}]W+B) Hi=f([Xi,Ht−1]W+B)
如此便是RNN的核心,输出可以利用如下生成: O t = H i W O + B O O_t=H_iW_O+B_O Ot=HiWO+BO
不加 W H W_H WH会出现这样的结果 H t = f ( T i + f ( T i − 1 + ⋯ + f ( T 1 + H 0 ) ) ) H_t=f(T_i+f(T_{i-1}+\dots+f(T_{1}+H_{0}))) Ht=f(Ti+f(Ti−1+⋯+f(T1+H0)))
很明显,只是单纯的加减变换转非线性,灵活性不够,如果去掉激活函数,明显只是前一个位置的值和本位置的值相加;
由于每一个单元都对应一个隐藏单元,最后一个隐藏单元的信息结合了前面所有单元的信息,同时每一个输出单元是依据对应的隐藏单元决定的,这样可以对应多对一任务(最后一个隐藏单元)和多对多任务(所有的隐藏单元);
SRNN的不足
对应添加 W H W_{H} WH,有这样的结果 H t = f ( T i + f ( T i − 1 + ⋯ + f ( T 1 + H 0 W H ) W H ) ) … ) W H ) H_t=f(T_i+f(T_{i-1}+\dots+f(T_{1}+H_{0}W_H)W_H))\dots )W_H) Ht=f(Ti+f(Ti−1+⋯+f(T1+H0WH)WH))…)WH)
可以发现 W H W_H WH被反复的相乘了,由于其是方阵,假设可对角化,有 W H = P − 1 Λ P W_H=P^{-1} \Lambda P WH=P−1ΛP
如果 n n n 个 W H W_H WH 相乘有 W H n = P − 1 Λ n P W_H^n=P^{-1}\Lambda^n P WHn=P−1ΛnP
这样随着 n n n 的增大, Λ \Lambda Λ 对角线上大于1的值就会越来越大, 对角线上小于1的值就会越来越小,趋近于0;这就照成了RNN的短记忆性问题,为了延长记忆性,提取了LSTM和GRU模型;
LSTM
LSTM(Long Short-Term Memory)称为长短期记忆网络,最早是由 Hochreiter 和 Schmidhuber 在1997年提出,能够有效的解决信息的长期依赖,避免梯度消失或者爆炸;
LSTM在SRNN内部添加了很多的门控元素,这些元素可以把数据中的重要特征保存下来,可以有效的延长模型的记忆长度,但是LSTM的缺点十分明显,那就是模型结构过于复杂导致计算量太大,模型训练速度过慢。
f t = σ ( W x f x t + W h f h t − 1 + W c f c t − 1 + b f ) i t = σ ( W x i x t + W h i h t − 1 + W c i c t − 1 + b i ) o t = σ ( W x o x t + W h o h t − 1 + W c o c t + b o ) c t = f t ∘ c t − 1 + i t ∘ tanh ( W x c x t + W h c h t − 1 + b c ) h t = o t ∘ tanh ( c t ) y t = W h y h t + b y \begin{align} \begin{split} f_t & = \sigma(W_{xf} x_t + W_{hf} h_{t-1} + W_{cf} c_{t-1} + b_f) \\ i_t & = \sigma(W_{xi} x_t + W_{hi} h_{t-1} + W_{ci} c_{t-1} + b_i) \\ o_t & = \sigma(W_{xo} x_t + W_{ho} h_{t-1} + W_{co} c_t + b_o) \\ c_t & = f_t \circ c_{t-1} + i_t \circ \tanh(W_{xc} x_t + W_{hc} h_{t-1} + b_c) \\ h_t & = o_t \circ \tanh(c_t) \\ y_t & = W_{hy} h_t + b_y \end{split} \end{align} ftitotcthtyt=σ(Wxfxt+Whfht−1+Wcfct−1+bf)=σ(Wxixt+Whiht−1+Wcict−1+bi)=σ(Wxoxt+Whoht−1+Wcoct+bo)=ft∘ct−1+it∘tanh(Wxcxt+Whcht−1+bc)=ot∘tanh(ct)=Whyht+by
GRU
GRU(Gated Recurrent Unit)在LSTM的基础上进行了改良,通过损失了一些记忆力的方式加快训练速度。GRU相较于LSTM少了一个记忆单元,其记忆长度相对减弱了一些,但是仍然远超过RNN,遗忘问题相对不容易发生。
z t = σ ( W x z x t + W h z h t − 1 + b z ) r t = σ ( W x r x t + W h r h t − 1 + b r ) h t ~ = tanh ( W x h x t + W h h ( r t ∘ h t − 1 ) + b h ) h t = ( 1 − z t ) ∘ h t − 1 + z t ∘ h t ~ y t = W h y h t + b y \begin{align} \begin{split} z_t & = \sigma(W_{xz} x_t + W_{hz} h_{t-1} + b_z) \\ r_t & = \sigma(W_{xr} x_t + W_{hr} h_{t-1} + b_r) \\ \tilde{h_t} & = \tanh(W_{xh} x_t + W_{hh} (r_t \circ h_{t-1}) + b_h) \\ h_t & = (1 - z_t) \circ h_{t-1} + z_t \circ \tilde{h_t} \\ y_t & = W_{hy} h_t + b_y \end{split} \end{align} ztrtht~htyt=σ(Wxzxt+Whzht−1+bz)=σ(Wxrxt+Whrht−1+br)=tanh(Wxhxt+Whh(rt∘ht−1)+bh)=(1−zt)∘ht−1+zt∘ht~=Whyht+by
Bi-RNN
由于RNN只能单项传播信息,Bi-RNN利用两个单项RNN解决这一问题
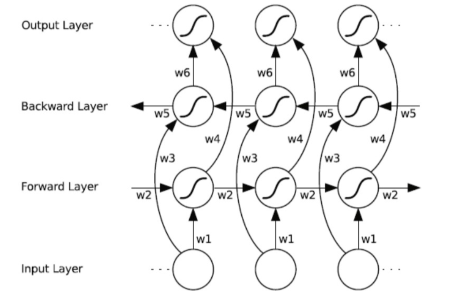
Bi-RNN 模型 的输出值是通过前向和后向两个的输出值拼接得到;
使用LSTM完成文本分类
这里以互联网电影资料库(Internet Movie Database)的评论来做一个评价好坏的二分类任务;
数据导入:
import numpy as np
import tensorflow as tfmaxlen = 200
max_features = 20000(x_train, y_train), (x_val, y_val) = tf.keras.datasets.imdb.load_data(num_words=max_features)
数据集构建:
x_train = tf.keras.preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_val = tf.keras.preprocessing.sequence.pad_sequences(x_val, maxlen=maxlen)train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(64)
val_data = tf.data.Dataset.from_tensor_slices((x_val, y_val)).batch(64)
模型创建:
class CustomModel(tf.keras.Model):def __init__(self):super(CustomModel, self).__init__()self.embedding = tf.keras.layers.Embedding(max_features, 128)self.lstm_1 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, return_sequences=True))self.lstm_2 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64))self.dense_final = tf.keras.layers.Dense(1, activation='sigmoid')def call(self, x):x = self.embedding(x)x = self.lstm_1(x)x = self.lstm_2(x)x = self.dense_final(x)return x
模型配置:
model = CustomModel()
model.compile(loss=tf.keras.losses.binary_crossentropy,optimizer='adam',metrics=['accuracy']
)
开始训练:
model.fit(train_data, epochs=10, validation_data=val_data)
训练结果:
Epoch 1/4
391/391 [==============================] - 43s 100ms/step - loss: 0.3848 - accuracy: 0.8215 - val_loss: 0.3382 - val_accuracy: 0.8538
Epoch 2/4
391/391 [==============================] - 38s 98ms/step - loss: 0.1943 - accuracy: 0.9288 - val_loss: 0.3826 - val_accuracy: 0.8511
Epoch 3/4
391/391 [==============================] - 38s 98ms/step - loss: 0.1680 - accuracy: 0.9397 - val_loss: 0.3751 - val_accuracy: 0.8548
Epoch 4/4
391/391 [==============================] - 38s 98ms/step - loss: 0.1076 - accuracy: 0.9629 - val_loss: 0.5110 - val_accuracy: 0.8176
结合使用CNN和RNN完成图片分类
这里继续使用CIFAR-10分类任务的数据
数据导入:
import matplotlib.pyplot as plt
import tensorflow as tf(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# x_train.shape, y_train.shape, x_test.shape, y_test.shape
# ((50000, 32, 32, 3), (50000, 1), (10000, 32, 32, 3), (10000, 1))index_name = {0:'airplane',1:'automobile',2:'bird',3:'cat',4:'deer',5:'dog',6:'frog',7:'horse',8:'ship',9:'truck'
}
数据集创建:
x_train = x_train / 255.0
x_test = x_test / 255.0y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.utils.to_categorical(y_test)
train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(64)
test_data = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(64)
先CNN,再RNN
创建模型:
class CustomModel(tf.keras.Model):def __init__(self):super(CustomModel, self).__init__()self.conv = tf.keras.layers.Conv2D(32, 3, padding='same')self.bn = tf.keras.layers.BatchNormalization(axis=-1)self.max_pool = tf.keras.layers.MaxPooling2D(strides=2, padding='same')self.reshape = tf.keras.layers.Reshape(target_shape=(-1, 32))self.lstm = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(50, return_sequences=False))self.flatten = tf.keras.layers.Flatten()self.dense_final = tf.keras.layers.Dense(10, activation='softmax')def call(self, x):x = self.conv(x)x = self.bn(x)x = self.max_pool(x)x = self.reshape(x)x = self.lstm(x)x = self.flatten(x)x = self.dense_final(x)return x
定义模型:
model = CustomModel()
model.compile(loss=tf.keras.losses.CategoricalCrossentropy(),optimizer='adam',metrics=['accuracy']
)
model.fit(train_data, epochs=3, validation_data=test_data)
训练结果:
Epoch 1/3
782/782 [==============================] - 36s 40ms/step - loss: 1.7976 - accuracy: 0.3488 - val_loss: 2.3082 - val_accuracy: 0.2340
Epoch 2/3
782/782 [==============================] - 30s 39ms/step - loss: 1.5557 - accuracy: 0.4350 - val_loss: 1.5993 - val_accuracy: 0.4222
Epoch 3/3
782/782 [==============================] - 30s 39ms/step - loss: 1.4037 - accuracy: 0.4898 - val_loss: 1.5229 - val_accuracy: 0.4519
结合使用CNN和RNN
class CustomModel(tf.keras.Model):def __init__(self):super(CustomModel, self).__init__()self.flatten = tf.keras.layers.Flatten()self.conv = tf.keras.layers.Conv2D(32, 3, padding='same')self.bn = tf.keras.layers.BatchNormalization(axis=-1)self.max_pool = tf.keras.layers.MaxPooling2D(strides=2, padding='same')self.dense_final_1 = tf.keras.layers.Dense(60, activation='relu')self.reshape = tf.keras.layers.Reshape(target_shape=[-1, 32])self.lstm = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(50, return_sequences=False))self.dense_final_2 = tf.keras.layers.Dense(60, activation='relu')self.concat = tf.keras.layers.Concatenate()self.dense_final = tf.keras.layers.Dense(10, activation='softmax')def call(self, x):x1 = self.conv(x)x1 = self.bn(x1)x1 = self.max_pool(x1)x1 = self.flatten(x1)x1 = self.dense_final_1(x1)x2 = self.reshape(x)x2 = self.lstm(x2)x2 = self.flatten(x2)x2 = self.dense_final_2(x2)x = self.concat([x1, x2])x = self.dense_final(x)return x
定义模型:
model = CustomModel()
model.compile(loss=tf.keras.losses.CategoricalCrossentropy(),optimizer='adam',metrics=['accuracy']
)model.fit(train_data, epochs=3, validation_data=test_data)
训练结果:
Epoch 1/3
782/782 [==============================] - 19s 22ms/step - loss: 1.5181 - accuracy: 0.4642 - val_loss: 1.4310 - val_accuracy: 0.4992
Epoch 2/3
782/782 [==============================] - 16s 21ms/step - loss: 1.1988 - accuracy: 0.5753 - val_loss: 1.4605 - val_accuracy: 0.5062
Epoch 3/3
782/782 [==============================] - 16s 21ms/step - loss: 1.0663 - accuracy: 0.6258 - val_loss: 1.5351 - val_accuracy: 0.5000