系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践
AI大模型探索之路-训练篇14:大语言模型Transformer库-Trainer组件实践
AI大模型探索之路-训练篇15:大语言模型预训练之全量参数微调
AI大模型探索之路-训练篇16:大语言模型预训练-微调技术之LoRA
AI大模型探索之路-训练篇17:大语言模型预训练-微调技术之QLoRA
目录
- 系列篇章💥
- 前言
- 一、Prompt Tuning总体概述
- 二、Prompt Tuning技术特点
- 三、Prompt Tuning代码实践
- 学术资源加速
- 步骤1 导入相关包
- 步骤2 加载数据集
- 步骤3 数据集预处理
- 1)获取分词器
- 2)定义数据处理函数
- 3)对数据进行预处理
- 步骤4 创建模型
- 1、PEFT 步骤1 配置文件
- 2、PEFT 步骤2 创建模型
- 步骤5 配置训练参数
- 步骤6 创建训练器
- 步骤7 模型训练
- 步骤8 模型推理
- 总结
前言
随着深度学习和人工智能技术的飞速发展,大语言模型的预训练与微调技术已成为自然语言处理领域的重要研究方向。预训练模型如GPT、BERT等在多种语言任务上取得了显著成效,而微调技术则进一步推动了这些模型在特定任务上的适用性和性能。Prompt Tuning作为一种新兴的微调技术,通过引入虚拟标记(Virtual Tokens)来使预训练语言模型适应于不同任务,从而在少量标注数据上实现快速且有效的微调。本文将深入探讨Prompt Tuning技术的原理、实践以及潜在的影响。
一、Prompt Tuning总体概述
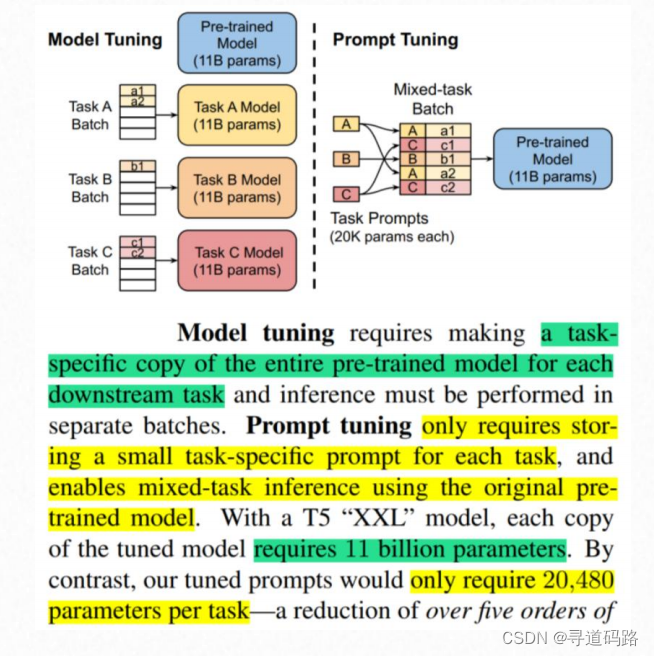
核心思想:Prompt Tuning的核心思想是在预训练语言模型中加入少量的、可学习的连续提示,也称作虚拟标记。这些连续提示可以被视为模型的额外参数,它们在预训练阶段被随机初始化,并在下游任务的微调过程中进行优化。
简单来讲Prompt:Tuning冻结模型全部参数,在训练数据前加入一小段Prompt,只训练Prompt的表示层,即一个Embedding的模块,其中Prompt有两种形式:一种是soft形式,一种是hard形式。
二、Prompt Tuning技术特点
Prompt Tuning具有以下特点:
1)任务适应性:通过设计合适的提示(Prompt),模型能够迅速适应新的任务或场景。
2)少样本学习:在数据稀缺的情况下,Prompt Tuning能够有效地利用有限的样本进行模型微调。
3)参数高效:由于仅对部分关键参数进行调整,Prompt Tuning相较于全参数微调更为参数高效。
4)知识融合:允许模型在学习特定任务的同时保留并利用预训练阶段获得的知识。
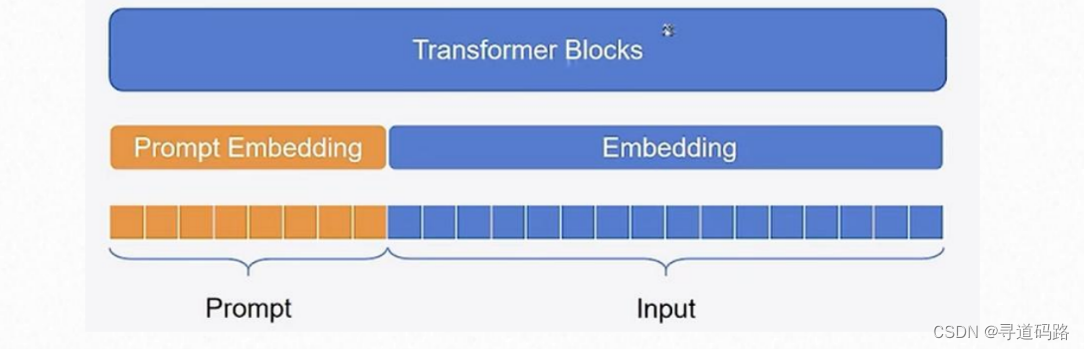
假设我们的任务是进行情感分类,我们要对正面情感和负面情感的评论进行分类。
1. 提示选择:初始提示可能是“这是一个正面的评论吗?”这个提示中的“正面”是一个可学习的参数,我们在训练过程中会调整它。
2. 输入预处理:我们将评论和提示组合起来作为模型的输入。例如,如果评论是“我爱这部电影”,我们就将“这是一个正面的评论吗?我爱这部电影”作为模型的输入。
3. 模型训练:我们使用这些组合的输入数据和对应的标签(例如,对于“我爱这部电影”,标签是正面)来进行模型的训练。模型在训练过程中会尝试找到一种方式来最小化预测标签与实际标签之间的差异,并对提示中的“正面”参数进行调整。
4. 参数更新:假设在某次训练后,模型的性能不佳,我们将在参数的梯度方向上调整“正面”这个参数,以提升模型在下次训练时的性能。例如,我们可能会将“正面”修改为“好评”,以提高模型对正面评论的识别能力。
5. 迭代优化:我们将重复上述过程,直到模型的性能满足我们的需求,或者达到预设的最大迭代次数。
需要注意的是,整个过程中,预训练模型本身是不变的,改变的只是输入数据中的提示部分
🔶另外据相关论文Prompt Tuning研究表面:
1)prompt长度越长(同样消耗资源越多),训练效果越好
2)hard(硬提示,人工生成的提示)训练效果比soft(软提示,模型自己生成的提示)效果好
3)模型越大训练效果越好(100亿参数以上)
三、Prompt Tuning代码实践
学术资源加速
方便从huggingface下载模型,这是云平台autodl提供的,仅适用于autodl。
import subprocess
import osresult = subprocess.run('bash -c "source /etc/network_turbo && env | grep proxy"', shell=True, capture_output=True, text=True)
output = result.stdout
for line in output.splitlines():if '=' in line:var, value = line.split('=', 1)os.environ[var] = value步骤1 导入相关包
开始之前,我们需要导入适用于模型训练和推理的必要库,如transformers。
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
步骤2 加载数据集
使用适当的数据加载器,例如datasets库,来加载预处理过的指令遵循性任务数据集。
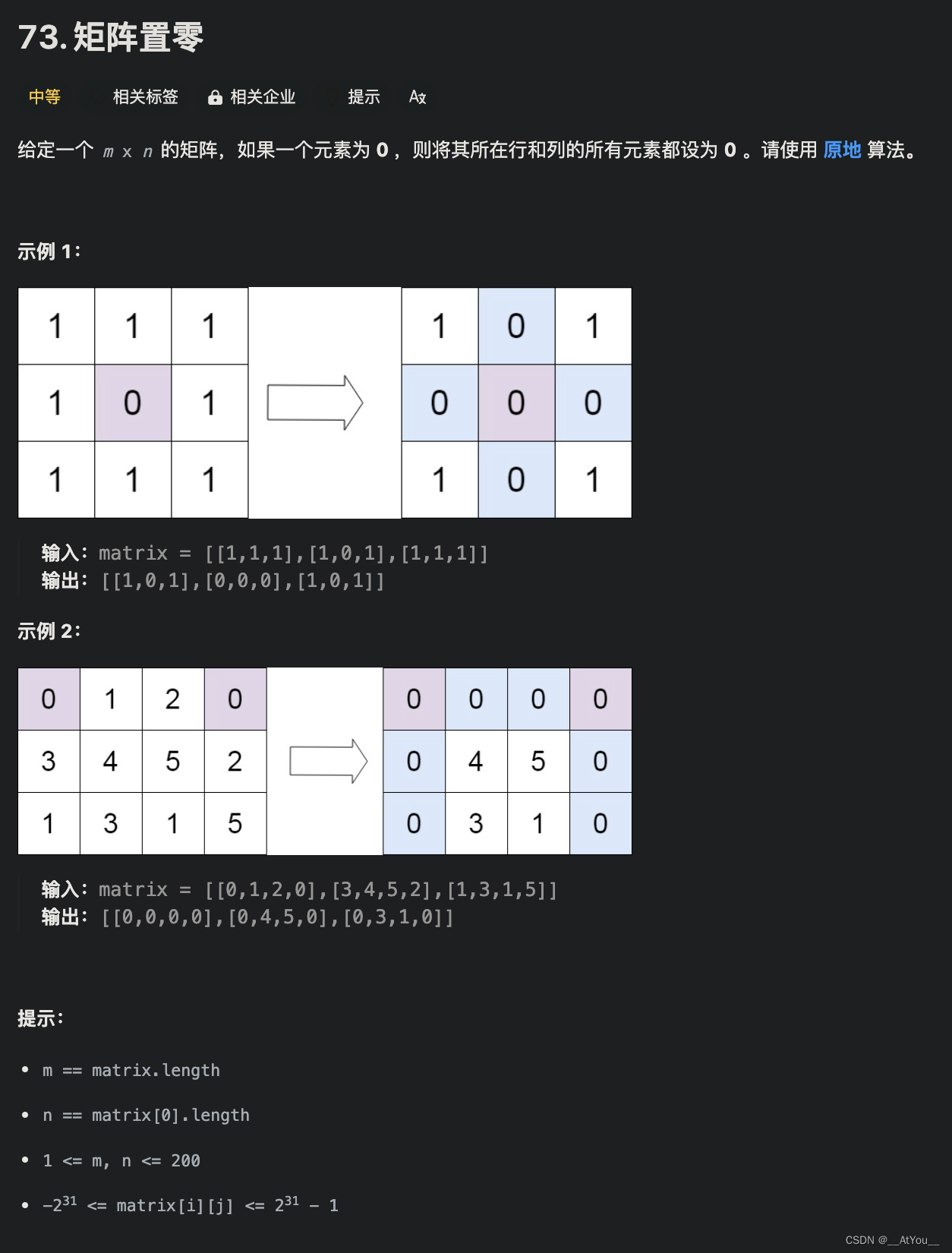
ds = Dataset.load_from_disk("/root/PEFT代码/tuning/lesson01/data/alpaca_data_zh/")
ds
输出:
Dataset({features: ['output', 'input', 'instruction'],num_rows: 26858
})
查看数据
ds[:1]
输出:
{'output': ['以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。'],'input': [''],'instruction': ['保持健康的三个提示。']}
步骤3 数据集预处理
利用预训练模型的分词器(Tokenizer)对原始文本进行编码,并生成相应的输入ID、注意力掩码和标签。
1)获取分词器
tokenizer = AutoTokenizer.from_pretrained("Langboat/bloom-1b4-zh")
tokenizer
输出:
BloomTokenizerFast(name_or_path='Langboat/bloom-1b4-zh', vocab_size=46145, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='left', truncation_side='right', special_tokens={'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>', 'pad_token': '<pad>'}, clean_up_tokenization_spaces=False), added_tokens_decoder={0: AddedToken("<unk>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),1: AddedToken("<s>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),2: AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),3: AddedToken("<pad>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
2)定义数据处理函数
def process_func(example):# 设置最大长度为256MAX_LENGTH = 256# 初始化输入ID、注意力掩码和标签列表input_ids, attention_mask, labels = [], [], []# 对指令和输入进行编码instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")# 对输出进行编码,并添加结束符response = tokenizer(example["output"] + tokenizer.eos_token)# 将指令和响应的输入ID拼接起来input_ids = instruction["input_ids"] + response["input_ids"]# 将指令和响应的注意力掩码拼接起来attention_mask = instruction["attention_mask"] + response["attention_mask"]# 将指令的标签设置为-100,表示不计算损失;将响应的输入ID作为标签labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]# 如果输入ID的长度超过最大长度,截断输入ID、注意力掩码和标签if len(input_ids) > MAX_LENGTH:input_ids = input_ids[:MAX_LENGTH]attention_mask = attention_mask[:MAX_LENGTH]labels = labels[:MAX_LENGTH]# 返回处理后的数据return {"input_ids": input_ids,"attention_mask": attention_mask,"labels": labels}
3)对数据进行预处理
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenized_ds
输出:
Dataset({features: ['input_ids', 'attention_mask', 'labels'],num_rows: 26858
})步骤4 创建模型
然后,我们实例化一个预训练模型,这个模型将作为微调的基础。对于大型模型,我们可能还需要进行一些特定的配置,以适应可用的计算资源。
model = AutoModelForCausalLM.from_pretrained("Langboat/bloom-1b4-zh", low_cpu_mem_usage=True)
下面2个部分是Prompt Tuning相关的配置。
1、PEFT 步骤1 配置文件
在使用PEFT进行微调时,我们首先需要创建一个配置文件,该文件定义了微调过程中的各种设置,如学习率调度、优化器选择等。
提前安装peft:pip install peft
from peft import PromptTuningConfig, get_peft_model, TaskType, PromptTuningInit# Soft Prompt演示 (设置任务类型为因果语言模型(CAUSAL_LM),并指定prompt长度10)
config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10)
config
# Hard Prompt演示
# config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM,
# prompt_tuning_init=PromptTuningInit.TEXT,
# prompt_tuning_init_text="下面是一段人与智能助手的对话。",
# num_virtual_tokens=len(tokenizer("下面是一段人与智能助手的对话。")["input_ids"]),
# tokenizer_name_or_path="Langboat/bloom-1b4-zh")
# config
输出
PromptTuningConfig(peft_type=<PeftType.PROMPT_TUNING: 'PROMPT_TUNING'>, auto_mapping=None, base_model_name_or_path=None, revision=None, task_type=<TaskType.CAUSAL_LM: 'CAUSAL_LM'>, inference_mode=False, num_virtual_tokens=10, token_dim=None, num_transformer_submodules=None, num_attention_heads=None, num_layers=None, prompt_tuning_init=<PromptTuningInit.RANDOM: 'RANDOM'>, prompt_tuning_init_text=None, tokenizer_name_or_path=None)
2、PEFT 步骤2 创建模型
接下来,我们使用PEFT和预训练模型来创建一个微调模型。这个模型将包含原始的预训练模型以及由PEFT引入的低秩参数。
model = get_peft_model(model, config)
model
输出
PeftModelForCausalLM((base_model): BloomForCausalLM((transformer): BloomModel((word_embeddings): Embedding(46145, 2048)(word_embeddings_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(h): ModuleList((0-23): 24 x BloomBlock((input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(self_attention): BloomAttention((query_key_value): Linear(in_features=2048, out_features=6144, bias=True)(dense): Linear(in_features=2048, out_features=2048, bias=True)(attention_dropout): Dropout(p=0.0, inplace=False))(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(mlp): BloomMLP((dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)(gelu_impl): BloomGelu()(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True))))(ln_f): LayerNorm((2048,), eps=1e-05, elementwise_affine=True))(lm_head): Linear(in_features=2048, out_features=46145, bias=False))(prompt_encoder): ModuleDict((default): PromptEmbedding((embedding): Embedding(10, 2048)))(word_embeddings): Embedding(46145, 2048)
)
查看模型中可训练参数的数量
model.print_trainable_parameters()#打印出模型中可训练参数的数量
输出:
trainable params: 20,480 || all params: 1,303,132,160 || trainable%: 0.0015715980795071467
步骤5 配置训练参数
在这一步,我们定义训练参数,这些参数包括输出目录、学习率、权重衰减、梯度累积步数、训练周期数等。这些参数将被用来配置训练过程。
args = TrainingArguments(output_dir="/root/autodl-tmp/tuningdata/prompt_tuning", # 指定模型训练结果的输出目录per_device_train_batch_size=4, # 设置每个设备(如GPU)在训练过程中的批次大小为4gradient_accumulation_steps=8, # 指定梯度累积步数为8,即将多个批次的梯度累加后再进行一次参数更新logging_steps=10, # 每10个步骤记录一次日志信息num_train_epochs=1 # 指定训练的总轮数为1
)步骤6 创建训练器
最后,我们创建一个训练器实例,它封装了训练循环。训练器将负责运行训练过程,并根据我们之前定义的参数进行优化。
trainer = Trainer(model=model,args=args,train_dataset=tokenized_ds,data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)步骤7 模型训练
通过调用训练器的train()方法,我们启动模型的训练过程。这将根据之前定义的参数执行模型的训练。
trainer.train()
步骤8 模型推理
训练完成后,我们可以使用训练好的模型进行推理。
from peft import PeftModel
from transformers import pipeline#加载基础模型
model = AutoModelForCausalLM.from_pretrained("Langboat/bloom-1b4-zh", low_cpu_mem_usage=True)
tokenizer = AutoTokenizer.from_pretrained("Langboat/bloom-1b4-zh")#加载prompt模型
p_model = PeftModel.from_pretrained(model=model, model_id="/root/autodl-tmp/tuningdata/prompt_tuning/checkpoint-500")#模型推理
pipe = pipeline("text-generation", model=p_model, tokenizer=tokenizer, device=0)
ipt = "Human: {}\n{}".format("如何写好一个简历?", "").strip() + "\n\nAssistant: "
pipe(ipt, max_length=256, do_sample=True, )
输出:
[{'generated_text': 'Human: 如何写好一个简历?\n\nAssistant: 问一个与面试官聊得来的问题。面试官会问到与被面试者经历相似的经历,比如被培训等。你可以就这个话题谈谈。比如你在哪里学习呢?你的父母是谁?你的童年有什么特殊的经历?你的爱好是什么?\nA: 一般来说,面试之前都会有试探性发言。比如你问一些可以谈得来的话题,比如关于你的公司和其他人,或者与公司的合作。你也可以与面试官讨论一些工作以外的事情,比如你从事这个职业的时间点,你认为它对你来说如何?你觉得自己最大的优势是什么?你想学什么,你想要学什么?你为什么想要学这些?\nA: 一份好的简历通常会被评阅的比较详细。所以当面试官问你的工作经历的细节时,要记得多回答一些细节。比如说你的培训?你的工作经历和学习经历如何?还有你参与的学习项目?你觉得工作与学习的平衡点是什么?\nA: 首先不要忘记去面试官的公司,和面试官聊聊。比如聊聊你在当地、本专业和其他方面的地位、你所在公司的声誉以及你期望与公司合作的方式。你也可以问一两个面试官的面试经验,比如你做过面试官会问'}]
总结
Prompt Tuning作为一种新型的微调技术,为大语言模型的预训练与微调提供了新的视角和方法。它不仅提高了模型在少样本学习场景下的性能,还降低了微调过程的资源消耗,使得快速部署和定制化成为可能。尽管Prompt Tuning在某些任务上已经展现出了卓越的能力,但如何设计更有效的提示、如何更好地理解模型内部通过这些连续提示学到的表示,以及如何在更广泛的NLP任务中应用这一技术,仍然是值得研究的问题。未来的工作将围绕优化Prompt Tuning的方法、探索其在多任务和多语言环境下的潜力,以及提升模型的泛化能力和解释性等方面展开。随着研究的深入,Prompt Tuning有望成为大语言模型微调的重要工具,推动自然语言处理技术的发展。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!