NDSS 2023
开源地址:https://github.com/bfpmeasurementgithub/browser-fingeprint-measurement
霍普金斯大学
文章结构
- intro
- background
- threat model
- measurement methodology
- step1: traffic analysis
- step2: fingerprint analysis
- dataset
- attack statistics
- browser fingerprint collection and statistics
- observations
- observation1: adversarial vs. benign fingerprints
- observation2: adversarial generative strategies
- observation3: adversarial fingerprints over attack and account types
- discussion
Abstract
作者从14个主要商业网站收集到第一个十亿级的测量研究,且进一步将指纹分类为良性和攻击指纹,使用的是F5公司基于学习的反馈驱动的欺诈和bot检测系统;得到3个主要结论:
(i)攻击指纹在许多指标上与良性指纹显著不同,例如熵、唯一率和演变速度;(ii)攻击者正在采用各种工具和策略生成攻击指纹;(iii)攻击指纹在不同攻击类型之间变化,例如从内容抓取到欺诈交易。
Intro
浏览器指纹是 Cookie 的替代品,是由一系列客户端特征(如用户代理和画布渲染结果)组成的标识符,用于表示浏览器实例。虽然浏览器指纹的最初用途[30]是网络跟踪,例如个性化广告(通常被认为是对网络隐私的侵犯),但最近的进展使浏览器指纹在预防网络攻击方面发挥了更积极的防御作用。例如,Azad 等人[10]的研究表明,浏览器指纹是bot检测的一个重要因素。另一个例子是,Laperdrix 等人[46] 发现,在线金融交易通常会检查浏览器指纹,以防止欺诈性登录和支付。
与往常一样,攻击者和防御者之间也存在着角力: 这同样适用于作为防御手段的浏览器指纹,尤其是考虑到它是一种取决于熵的弱浏览器识别手段。具体来说,攻击者可以通过改变浏览器指纹来绕过现有的防御措施、 例如,指纹用于检测bot: 如果具有特定指纹和其他特征(如 IP 等低层特征)的请求数量超过阈值,客户端就会被检测并作为bot被阻止。然后,攻击者可以不断更改自己的指纹,以避免被拦截。因此,本文将这种由攻击者伪造的指纹定义为 “攻击者浏览器指纹”(或简称 “攻击者指纹”),而将来自用户浏览器的传统指纹定义为 “良性指纹”。
从直观上看,对抗性指纹不同于良性指纹,因为它们的目的是击败防御措施。虽然直觉上是正确的,但研究界对这些野生对抗性指纹的特性大多研究不足,也不了解。例如,一些开放式研究问题包括但不限于以下方面:(i) 在熵和特征方面,对抗性指纹与良性指纹有何不同;(ii) 对抗者采用什么策略和工具来改变指纹,特别是针对不同的攻击;(iii) 不同攻击类型的对抗性指纹有何不同。这些问题的答案不仅能为今后检测对抗性指纹(及相关攻击)提供启示,还能帮助研究人员更好地了解良性指纹的特性,以用于个性化广告等跟踪目的(对抗性指纹应排除在外)。
最先进的工作一般从三个主要来源对浏览器指纹进行小规模(如最多百万规模)研究:受控用户群[48]、[48]、盲目收集的网站流量[36]、[50]和蜜罐网站流量[53]。然而,无论规模大小,之前的测量工作都没有对来自同一网站的恶意和良性指纹进行比较。受控用户群和蜜罐网站只有对抗性或良性指纹;盲目收集的网站流量无法区分指纹是良性还是对抗性的。也就是说,它们都无法回答上述研究问题,即现实世界中对抗性指纹和良性指纹的实际区别,以及针对不同类型攻击生成对抗性指纹的工具和策略。
在本文中,我们首次对从 14 个商业网站(包括主要金融机构、餐馆和航空公司)收集到的恶意和良性指纹进行了十亿规模的测量研究。具体来说,我们与一家安全公司 F5 公司合作,利用其bot和欺诈检测与防御系统收集网站流量并对流量进行分类。然后,与bot和欺诈流量相关的浏览器指纹被视为恶意指纹,其余的则被视为良性指纹。需要注意的是,外部独立审查显示,bot和欺诈检测系统将账户接管攻击造成的成本降低了 96%,假账户总数降低了 92%。
我们的测量发生在 2021 年 1 月至 2021 年 6 月期间,结果是来自 14 个商业网站的 360 亿次 HTTP(s)请求/响应以及相应的浏览器指纹。检测系统通过五种详细的攻击类型将 42.5% 的流量归类为bot或欺诈(即恶意)流量,将 57.5% 的流量归类为用户流量(即良性)流量。与bot或欺诈流量相关的指纹被视为恶意指纹,而与用户流量相关的指纹被视为良性指纹。然后,我们从演化和熵等不同指标的角度对对抗性指纹和良性指纹进行比较,并分析对抗性指纹的特性,以利于生成工具和策略的使用。例如,如果缺少所有 JavaScript 特征,我们就认为指纹是使用脚本工具生成的;如果收集的渲染方法具有一致的虚拟机相关值,我们就认为指纹是使用虚拟机(VM)工具生成的。再比如,如果浏览器实例的指纹特征值为空,我们就认为该指纹特征被屏蔽了;如果良性指纹中没有出现该指纹特征值,我们就认为该指纹特征被随机化了。我们的分析提出了以下三点看法:
观察结果-1:在同一网站上,敌对浏览器的指纹与良性浏览器的指纹明显不同。在所有独特指纹中,只有 1.6% 是对抗性指纹和良性指纹共享的,其余的要么是对抗性指纹(8.1%),要么是良性指纹(90.3%)。它们在进化速度和熵等许多方面也存在差异。以进化为例。良性指纹往往会随着浏览器实例的更新而不断进化;相比之下,对抗性指纹则相对稳定,因为对抗者通常会将指纹与受损账户绑定,并在一次性使用后放弃伪造账户。
观察结果-2:反病毒者采用不同的工具生成反病毒指纹,并表现出不同的特性。 具体而言,我们总结了三种通用工具,即脚本工具、模拟浏览器(如无头浏览器或完整浏览器)和虚拟机(VM)。脚本工具是最流行的工具,尤其是在抓取网页内容方面,因为它效率高;相比之下,模拟浏览器和虚拟机不那么流行,但功能更强大,不仅能生成对抗性指纹,还能模拟良性指纹。
观察结果-3:不同攻击的对抗性浏览器指纹属性各不相同。以内容抓取和欺诈交易为例。用于内容抓取的对抗性指纹往往会频繁而随机地变化,以避免被网站屏蔽;相比之下,用于欺诈交易的对抗性指纹往往会模仿良性指纹的特征,从而获得更高的交易成功率。
Back
首先介绍攻击指纹和良性指纹的定义,然后阐述威胁模型;
浏览器指纹是客户端(例如,用户代理、WebGL渲染和字体列表)收集的浏览器特性组合,可以是显式或隐式(如通过边信道)收集的。传统的浏览器指纹定义假设它来自用户控制的浏览器,因此称为良性浏览器指纹。与良性指纹相反,敌对浏览器指纹,或简称敌对指纹,是由攻击者伪造的,用于绕过使用浏览器指纹进行的某些服务器端防御。攻击者可以使用各种工具,如脚本工具(例如,用Python编写)、模拟浏览器(例如,由Selenium自动化)和虚拟机,来构建敌对指纹的特征。
威胁模型考虑了利用浏览器指纹绕过服务器端防御的攻击。具体来说,我们的威胁模型涵盖以下根据其在真实世界网络流量中流行程度的攻击:
- 账户接管尝试(即凭据填充)。账户接管尝试[11]、[67]、[76]、[82]是指攻击者尝试使用大量不同的用户名和密码组合登录用户账户,这些组合经常来自地下经济或者过去的数据泄露。此类攻击也称为凭据填充。
- 欺诈交易。欺诈[54]、[55]、[66]是指攻击者代表受害者发起未经授权的交易,例如,下单、申请个人贷款、转账、结账或退货。欺诈通常发生在成功接管账户后,尽管一些欺诈行为可能不需要登录账户。
- 自动创建虚假账户。自动创建虚假账户是指通过机器人而非人类自动创建账户。据之前的研究[15]、[16]、[32]、[68],这些账户可以用于多种恶意目的,如登录后抓取信息、发布垃圾邮件或虚假评论,以及注册网站额外奖励。
- **强力内容抓取。**强力内容抓取[28]、[37]、[64]是指攻击者无视网站在robots.txt文件中列出的速率限制和黑名单,为自己的利益爬取目标网站,例如获取竞争对手如航空公司的价格信息。这种强力抓取可以基于虚假账户(称为已登录)或匿名(即,不登录)。
- 礼品卡破解。礼品卡破解[1]是一种暴力攻击,攻击者枚举所有可能的礼品卡号,并试图在合法用户之前消费卡中的价值。
Method
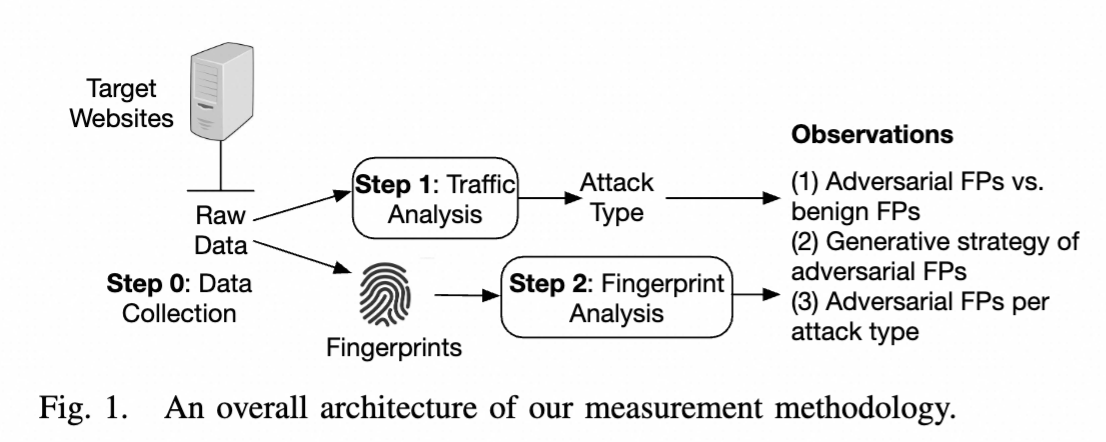
图1展示了测量的整体架构,包括三个步骤:0)数据收集,1)流量分析,2)指纹分析。步骤0收集所有原始数据,包括完整的HTTP(s)请求和响应。然后,步骤1的流量分析对HTTP请求进行分类,标识为良性或恶意,并细分攻击类型。最后,步骤2的指纹分析研究所有指纹的属性以及步骤1的输出,这导致我们得出三个核心观察结果。
步骤0。与一家安全公司合作,从14个顶级目标网站(104个子域名)收集数据。 数据收集是通过在目标网站的Web应用程序中植入JavaScript和这些目标的原生移动应用的SDK来实现的。然后,收集到的原始数据包含了跨网络级、浏览器级和用户级的丰富信息。网络级信息包括TCP/IP头(如源IP和目的IP地址)、设备ID、时间戳和源自治系统号(ASN)。浏览器级信息主要包含浏览器指纹,这些指纹分解为不同的特征,如用户代理、字体列表和canvas图像。(详细的特征将在第四部分B节中介绍。)用户级信息包括账户ID和用户行为(如访问的链接)。
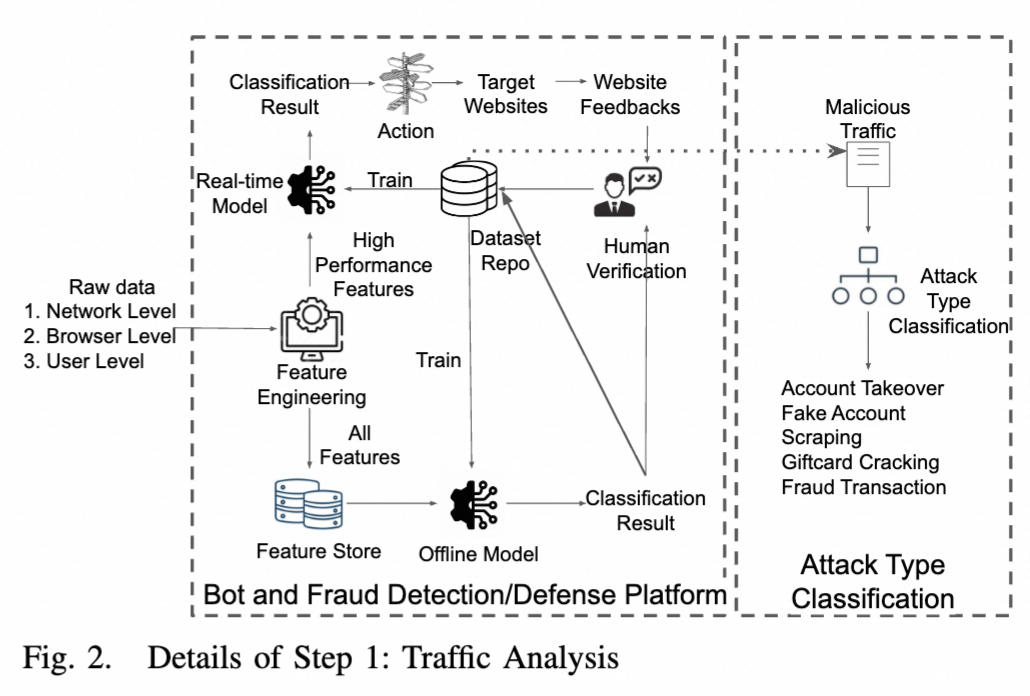
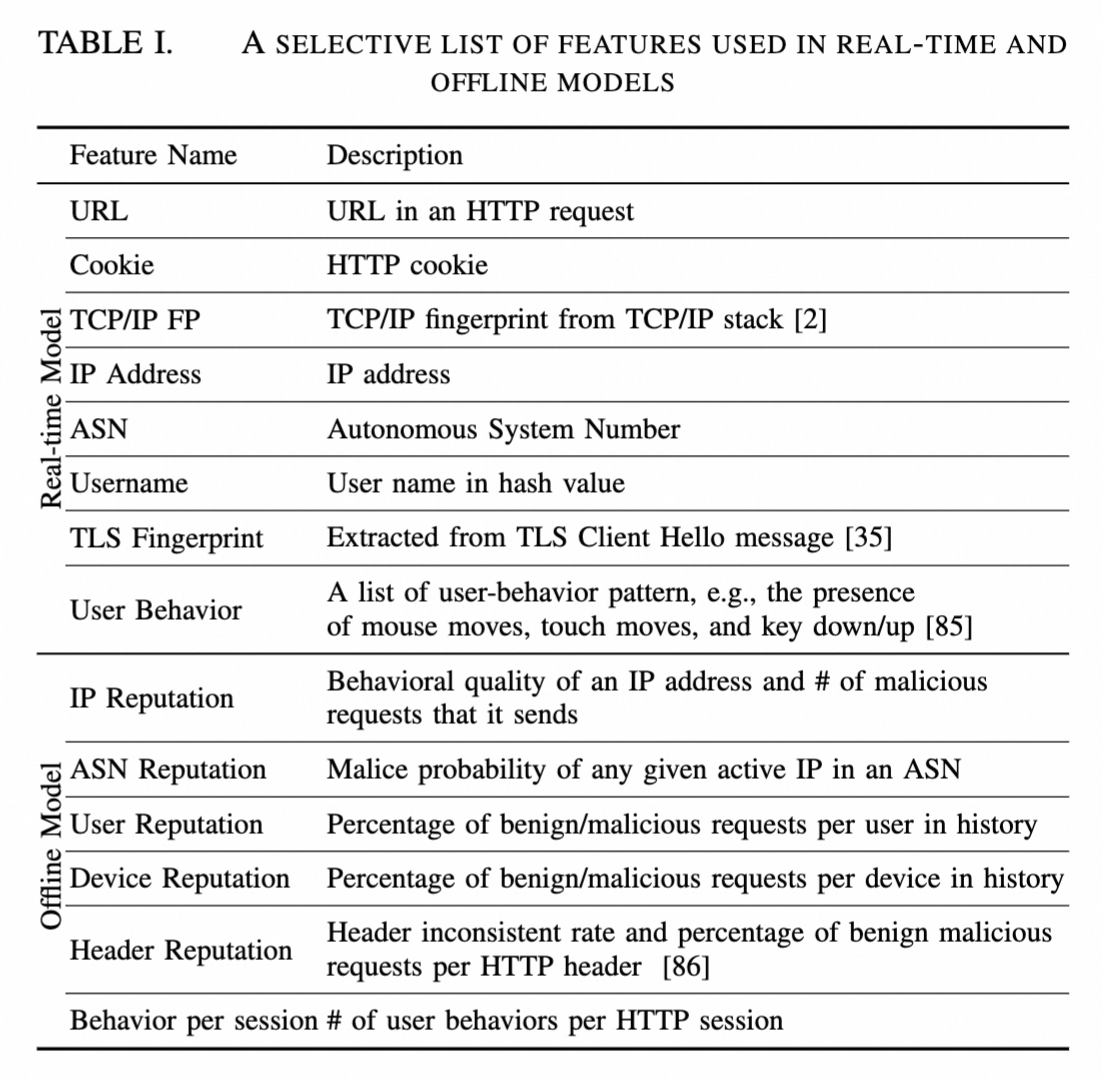
表I展示了根据它们对模型性能的贡献,实时和离线模型中使用的一些最重要特征的精选列表。实时模型主要采用可以从单个HTTP请求直接获取的高性能特征,如URL、Cookie、TCP/IP指纹和SSL指纹。相比之下,离线模型使用在特定时间段内多个HTTP请求的特征聚合统计。比如每IP、ASN、用户名、设备和HTTP头部的良性与恶意请求次数。请注意,我们仅列出部分特征。实际上,实时模型有数百个特征,而离线模型有数千个(因为特征聚合有不同组合)。
请注意,在创建双反馈循环之前的双模型初始训练集是通过结合规则和人工验证的方法构建的。表II展示了用于创建此类初始训练集的一些选择性指标。总体思路是根据异常程度过滤网络流量,然后人类专家验证流量。例如,会话时长。机器人通常自动化运行,因此与人类相比,其会话时长可能短得多。同样,机器人账号在注册时常使用虚假信息,如随机电话号码。这样的训练集是初步的,并在双反馈循环中进一步优化。
初始训练集的生成
现在,我们描述双重反馈循环。第一个反馈环是网站和实时模型之间的。如果平台做出错误的判断(例如,将机器人识别为良性,或将良性识别为机器人)并采取了错误的行动,那么这些反馈将从目标网站收集,经过人类专家验证,并在重新训练时更新到实时模型。第二个反馈环是实时模型与离线模型之间的。离线模型将进行独立的(更准确的)决策,不依赖实时模型。然后,离线模型的分析结果会被更新到数据集库中,进而影响第二个反馈环中的实时模型。请注意,实时模型和离线模型都受到人类专家的审计。具体来说,当以下情况发生时,人类专家会参与其中:(i) 客户(例如,网站用户)报告假阳性或假阴性,(ii) 实时模型与离线模型之间的不一致,以及 (iii) 报告的大规模攻击事件。此外,人类专家还会对预测置信度低的数据样本进行抽样检查,以确保两个模型的准确度。
双重模型和双重反馈循环架构的好处在于显著减少了适应性机器人和欺诈攻击。即便攻击者绕过了系统,反馈循环也能立即检测出这一情况,并更新实时模型以识别这些绕过行为。一个外部审查团队审查了机器人和欺诈检测/防御产品。审查结果显示,该平台产品长期下来可减少(i)96%的账户接管攻击损失,以及(ii)92%的虚假账户数量。我们想指出,虽然这个数字在初看时非常高,但实际上是合理的,并且对于一个付费的商业产品来说是必要的。一方面,该平台很少误分类良性的流量;另一方面,4%的账户接管和8%的虚假账户(经过外部团队验证)只发生在极小部分的网络流量和短暂的时间窗口中,且平台能迅速检测到。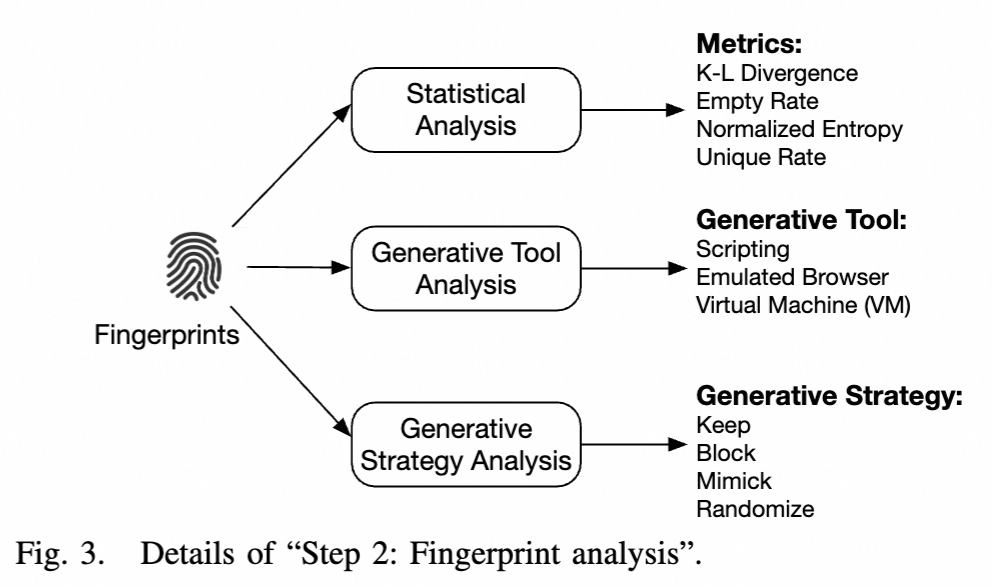
之后作者使用3个步骤分析了浏览器指纹;
生成工具分析:在这个子步骤中,我们分析敌对指纹并推断生成这些指纹的工具。具体来说,我们描述了三种通用的敌对工具类型及其在野外的检测方法。
- 脚本工具。脚本工具是简单的应用程序(如用Python编写),向目标网站发送HTTP请求。一方面,这些工具通常无法实现由JavaScript驱动的复杂客户端功能,例如渲染canvas图像;另一方面,它们速度很快,能方便地抓取大量内容。因为脚本工具通常不支持JavaScript,所以我们如果在指纹中发现没有任何JavaScript特征,则检测为脚本工具。
- 模拟浏览器。模拟浏览器是具有扩展或修改功能的浏览器,如无头浏览器、带有扩展的浏览器和定制的修改版浏览器,它们通常由Selenium等自动化工具驱动。这类模拟浏览器完全具备模拟所有不同浏览器指纹特性的能力。如果我们无法将工具鉴定为脚本工具或虚拟机(如下所述),则默认工具即为模拟浏览器。
- 虚拟机。由KVM和VMWare等软件驱动的虚拟机也结合模拟浏览器来模拟真实用户。虚拟机通常由云服务提供,并且也能模拟所有不同的指纹特征。如果指纹的渲染方法具有一致的VM基础渲染器和供应商,我们就检测生成工具为虚拟机。
生成策略分析:一旦攻击者使用了特定工具,下一步就是选择改变或生成浏览器指纹(向目标网站发送请求时收集)特征的策略。在实践中,我们观察到以下策略,并进行了总结:
- [保持] 保留原始指纹。攻击者的一种简单策略是保留工具的原始指纹(或某些特征值)。以内容抓取为例。虽然保留原始指纹增加了攻击者被阻止的可能性,但在某些特征的客户端请求阈值下,攻击者仍然可以获取一些信息。如果我们在特定浏览器实例中只观察到一个特征值,我们就认为攻击者保持了该值。
- [屏蔽] 在指纹中屏蔽特定特征。另一种相对较简单的策略是阻止指纹中特征的值。以canvas渲染为例。攻击者可以在浏览器中禁用canvas API,防止目标网站获取有效值。这种策略在一定程度上有效,因为良性指纹中也有缺失值,特别是在需要大量计算的某些特征上。例如canvas渲染和字体列表。如果我们在恶意请求中发现该特征值缺失,我们认为攻击者阻止了该值。
- [模仿] 模仿良性指纹。攻击者的一个复杂策略是在每个向目标网站发出的请求中模仿不同的良性指纹。这对攻击者较难,因为他们需要为每个HTTP(s)请求遍历大量的良性指纹。如果我们在恶意请求中发现一个浏览器实例有多重特征值,并且所有这些值也出现在良性指纹中,我们考虑攻击者在模仿良性指纹的值。
- [随机化] 在指纹中随机化某些特征值。因为模仿策略相对较难,一些攻击者会采取另种策略,即随机化某些特征值。例如,对于插件特征,攻击者修改插件API,每次返回一个随机的插件列表。要注意,这种生成的攻击性指纹在大多数情况下是唯一的,不会与其他良性指纹共享。如果我们观察到一个浏览器实例有多重特征值,且没有一个值出现在良性指纹中,我们认为攻击者是在随机化值。
使用的特征如下: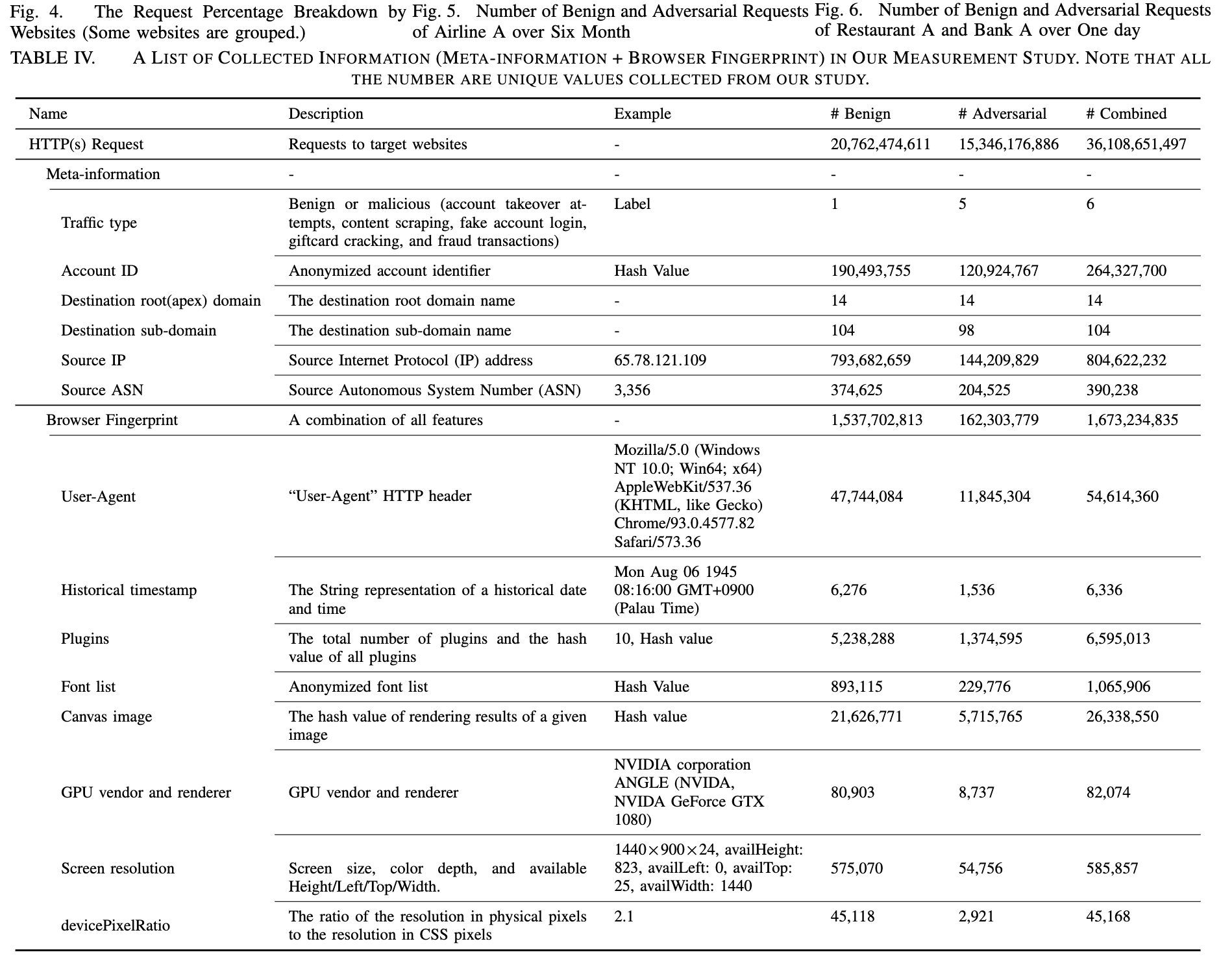
知识星球
在尾部推荐一下我们的知识星球,以AI应用在安全作为主题,包括AI在安全上的应用和AI本身的安全;
加入星球你将获得:
【Ai4sec】:以数据驱动增强安全水位,涵盖内容包括:恶意软件分析,软件安全,AI安全,数据安全,系统安全,流量分析,防爬,验证码等安全方向。星主目前在某大厂从事安全研究,论文以及专利若干,Csdn博客专家,访问量70w+。分享者均为大厂研究员或博士,如阿里云,蚂蚁,腾讯等;
选择加入即可获得:
1、前沿安全研究资讯
2、相关安全领域的研究入门和进阶,如malware,fuzz,program analysis,antibot等
3、大厂岗位内推,包括阿里云,蚂蚁,腾讯等
4、求职考研考博简历润色及辅导是允许读者一对一咨询求职、考研考博相关问题,并帮助读者修改简历和告知相关经验。
5、相关论文方向指导
现在正在低成本推广,秒杀一波福利,数量有限,先到先得,欢迎新老朋友们加入一起讨论:

对于没有抢到的朋友们,我们也有相应的较大额度的优惠券赠送: