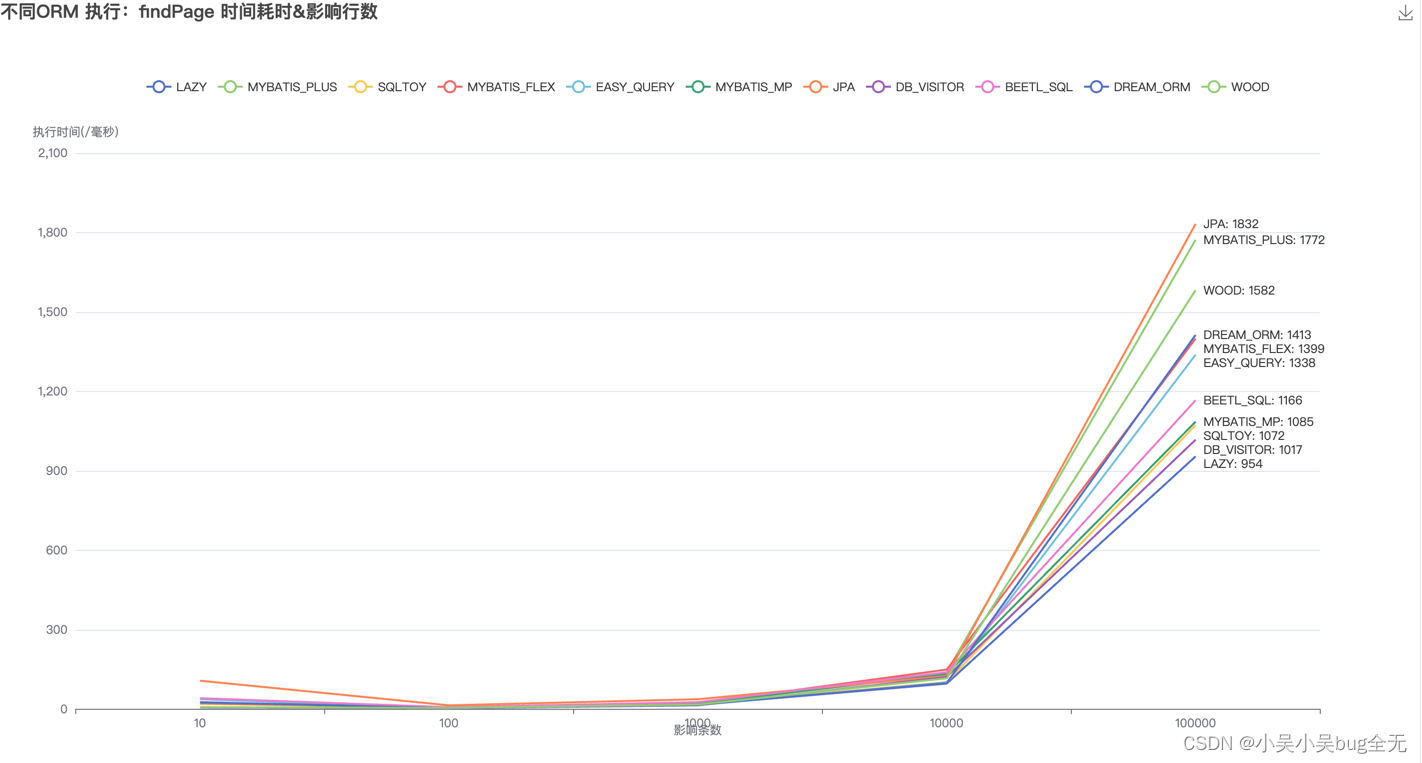
PG到目前为止使用的事务ID仍然是32位的,在内存计算时虽然已经使用64位事务ID,但是存储在页中tuple仍然使用32位事务ID,这就是说,事务ID回卷仍然是必须处理的问题。
所谓PG事务ID回卷,简单地说,就是在数据库频繁运行中,事务ID不断增加,32位的事务ID不够用了,怎么办?PG的处理方法,简单的说,就是在事务ID还没用完以前,把数据库中所有的tuple处理一遍,将以前的事务(不活跃的事务)修改的(包括插入)tuple中的事务ID改为2(或设置infomask),表示这个tuple对于以后的事务(不管是多少的事务ID)都是可见的,即freeze。
这样,当前事务达到2^32后,再从3开始(0、1、2保留做特殊事务ID),就不会有什么问题了,即就不会导致很旧的事务修改过的tuple不可见了。
这里有个隐含背景知识,就是PG内部读写tuple时,tuple中的事务ID,在当前事务ID之前 ,这个tuple对于当前事务才是可见的。
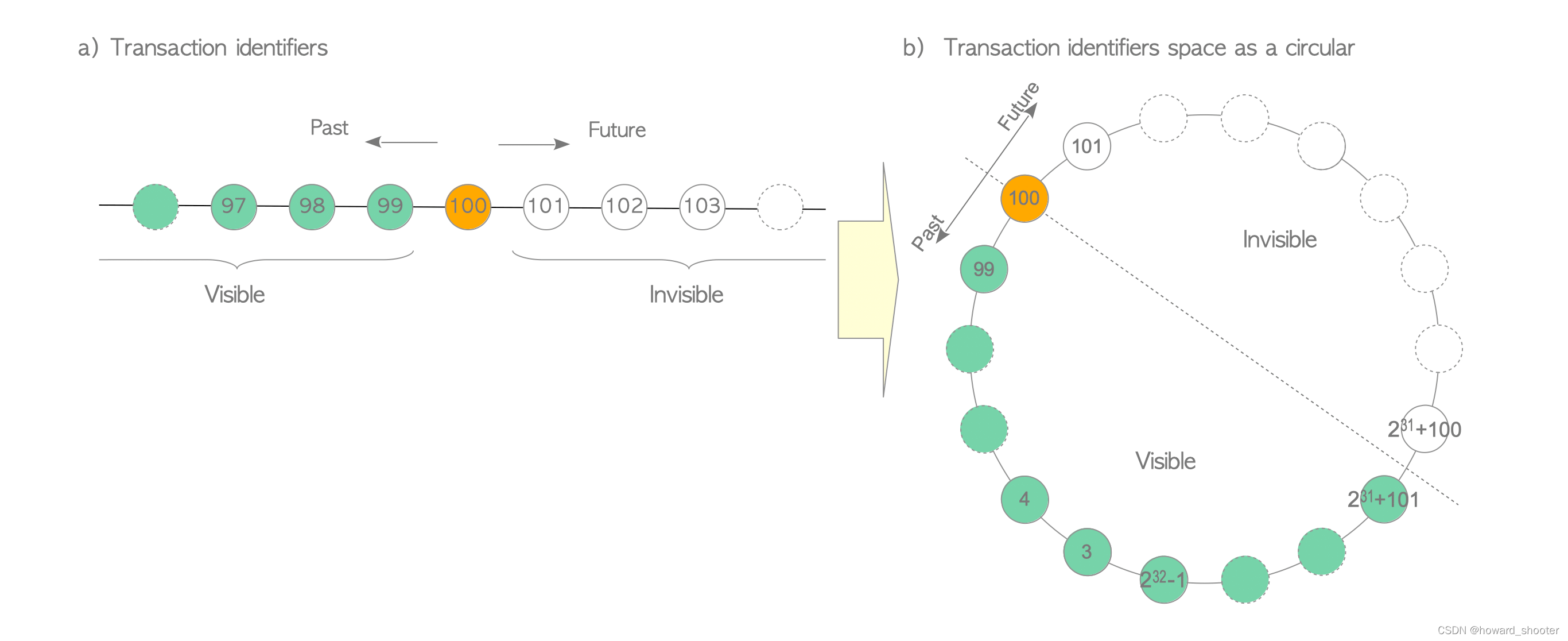
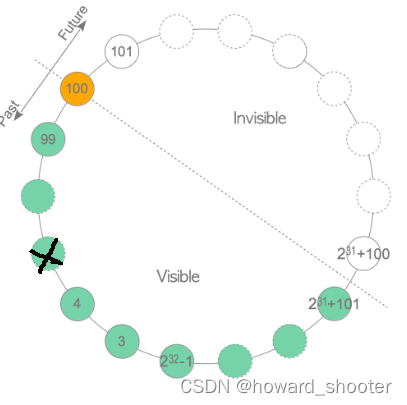
网上有一张图片,来说明“之前”、“之后”和回卷的概念,但是我觉得都没说明白,我来尝试理解一下,我觉得问题的关键是PG源码中比较事务ID的函数:
TransactionIdPrecedes() 和 TransactionIdFollows()


按照上面代码的算法,对于任何事物ID,例如100,如果另一个事务ID比它大,但是没有超过这个事务ID后的半圆,例如2^31+100,就认为是在它的后面,那么事务100的tuple,对事务2^31+100就是可见的。
按照上面代码的算法,对于任何事物ID,例如100,如果另一个事务ID比它大,还超过了事务ID后的半圆,例如2^31+101,就认为是在它前面,那么事务100的数据,对事务2^31+101就是不可见的。
这导致对任何事务ID,它只能看到它之前的 2^31 个事务的数据,而不是 2^32 个事务的数据,而且不同事务的可见事务集合也是不同的。
但是这个和freeze有什么关系呢?
想象事务ID一直在增加,穿过圆心的线顺时针转动,每转动一个事务ID,就有一个事务ID变的不可见,要想不丢失这个事务ID的数据,就要对它的tuples做freeze,这一岂不是freeze太频繁了吗?
实际上,PG对于past部分的tuple,早就做了freeze了,例如下图,一般X之前的tuple已经freeze过了,而当前事务ID不断增加,每隔一段时间做一次freeze,将与当前事务ID有一定差值(5千万)的past tuple,做freeze。
并不是在穿过圆心的直线另一端,快到达某个事物ID时(未做freeze的tuple事务ID与当前事务ID差值已经非常大了),才对这个事物ID做freeze。