05、Kafka 操作命令
1、主题命令
(1)创建主题
kafka-topics.sh --create --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test1 --partitions 4 --replication-factor 3
–bootstrap-server:设置kafka执行节点
–topic:主题名称
–partitions:设置分区数,可以用于并发消费。
–replication-factor:设置副本因子,数量不能大于kafka节点数。
(2)查看主题
kafka-topics.sh --list --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092

(3)在我们配置的文件夹下,
/usr/local/kafka_2.12-3.7.0/data
就可以看到topic对应的文件夹,其中 0,1,2,3是因为我们指定的partitions为4,创建了4个分区。
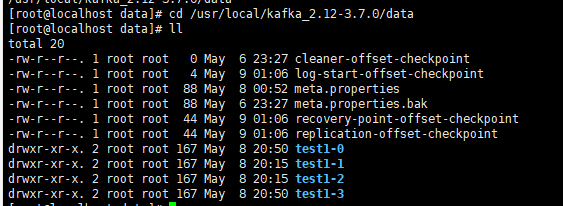
在其他两台机器上,也同样有这三个文件夹,是因为我们的replication-factor 为3,表示会有三个副本,刚好对应三台机器。
(3)查询主题描述信息
kafka-topics.sh --describe --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test1

ReplicationFactor 表示副本数为3
Partition:表示当前的分区号
Replicas:表示副本存放的机器
Leader:表示三个副本中的leader
Isr:表示当前可用的机器id
(4)修改主题
分区数partitions可以修改,只能比原来的大。
replication-factor 一旦确定就不能修改了。
kafka-topics.sh --alter --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test1 --partitions 6

(5)删除主题
kafka-topics.sh --delete --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test

2、生产消息
给test1主题,发送消息
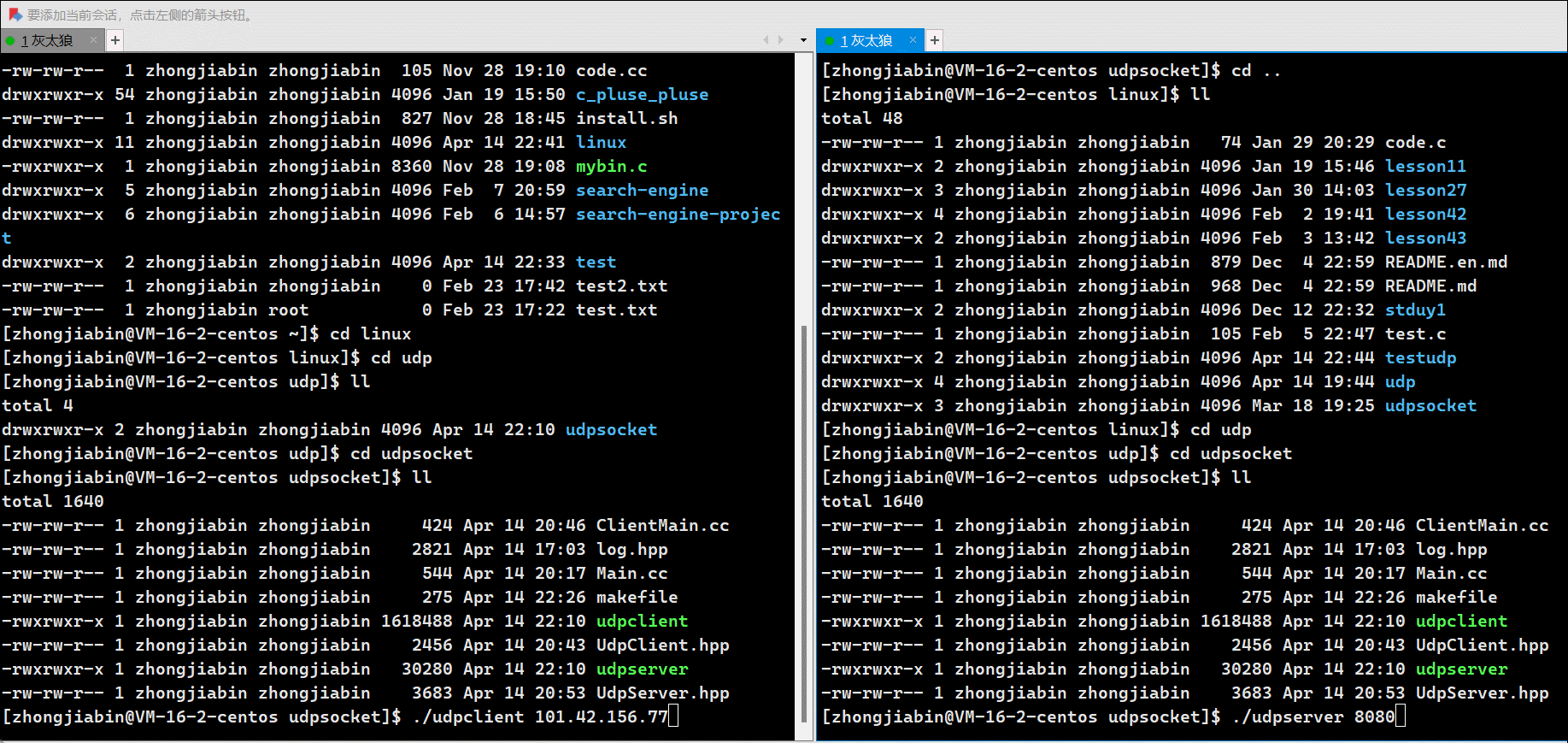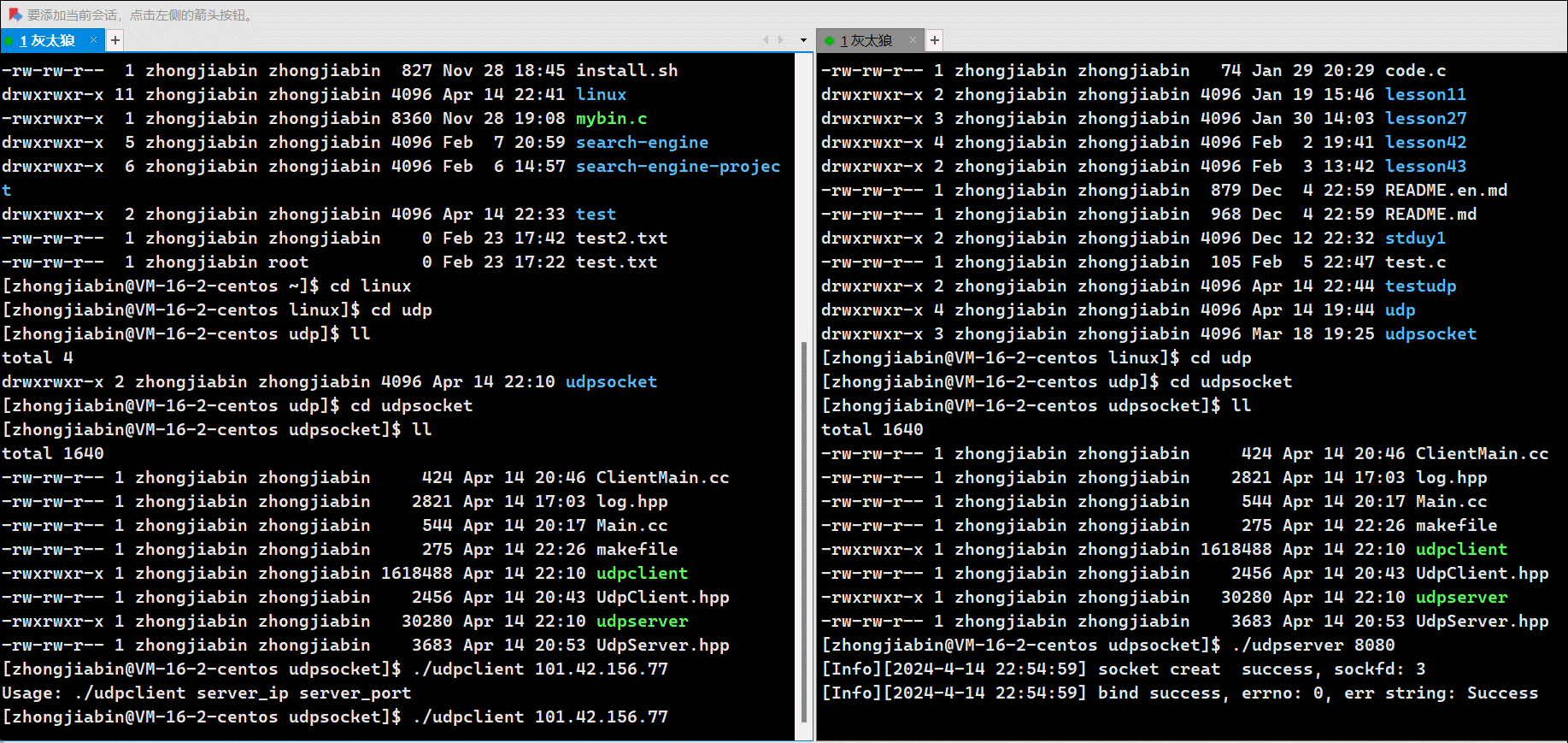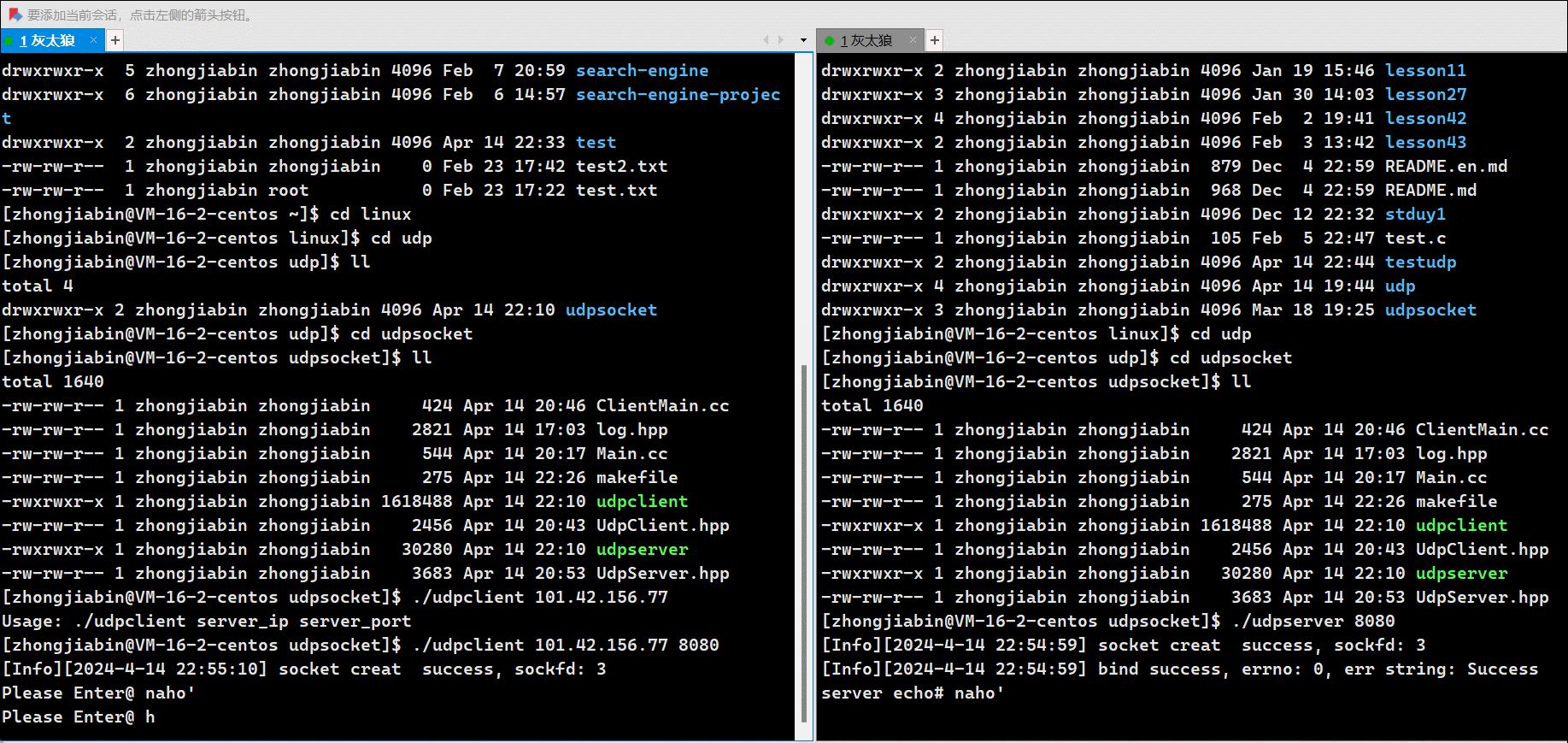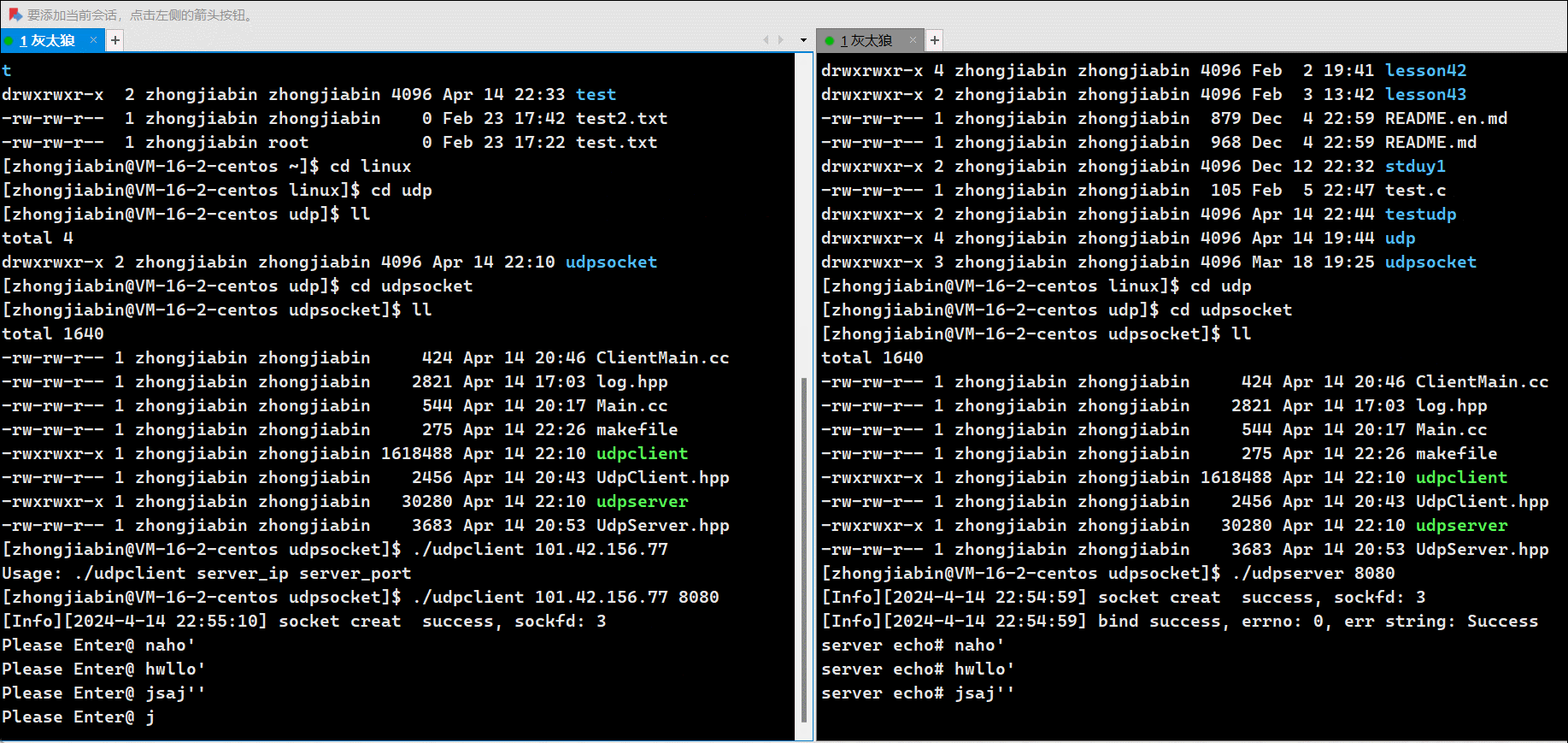
[root@localhost bin]# kafka-console-producer.sh --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test1
>hello world
如果给一个不存在的主题,发送消息:
kafka-console-producer.sh --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test2
>message1

第一个消息发送后会有警告,后续发送消息没有警告,因为会自动创建topic,并且指定
partitions 和 replication-factor 都为1。
kafka-topics.sh --describe --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test2

但是,建议 topic 还是手动创建,应该 partitions 是可以修改的,但是 replication-factor
是不允许修改的。
3、消费消息
(1)消费最新数据
消费 test1 主题下的消息:
kafka-console-consumer.sh --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test1
我们再启动一个生产者来发送消息:
kafka-console-producer.sh --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test1
>hello world

此时查看我们的消费者,就会打印接受到的消息:

上面消费者,只能消费最新的数据,无法消费历史数据。
(2)消费历史数据
消费 test1 主题下的历史消息:
- –from-beginning 表示从头开始消费:
kafka-console-consumer.sh --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test1 --from-beginning
- –offset earliest --partition 1 表示从1号分区的头部开始消费:
kafka-console-consumer.sh --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test1 --offset earliest --partition 1
- –offset latest --partition 1 表示从1号分区的尾部开始消费:
kafka-console-consumer.sh --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test1 --offset latest --partition 1

- –offset 2 --partition 1 从1号分区的offset 为2的位置开始消费:
kafka-console-consumer.sh --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test1 --offset 2 --partition 1
4、消费者组
消费者组其实就是一个容器,可以容纳若干个消费者,每一个消费者必须被包含在一个消费者组里面。
(1)通过 --group 来指定消费者组。
kafka-console-consumer.sh --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --topic test1 --group my-group1
如果分组存在,则会将消费者添加到对应分组下,如果不存在,则会创建消费者组。
(2)查看已有的消费者组
kafka-consumer-groups.sh --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --list

(3)删除消费者组
删除消费者组,必须要先保证消费者组下没有消费者:
kafka-consumer-groups.sh --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --delete --group my-group1

(4)查看消费的位置
kafka-consumer-groups.sh --describe --bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 --group my-group1

PARTITION:表示分区号
CURRENT-OFFSET:当前消费到的offset下标
LOG-END-OFFSET:当前分区最新的offset下标
LAG:是偏移量,未消费的数量。
消费详情:
kafka消费者在消费数据的时候,都是分组消费的,不同的消费者组之间没有影响,都会去消费。在同一个组内消费,一条消息只能被一个消费者消费,同时一个分区数据只能被一个消费者消费,如果消费者数量大于分区数,则多余出来的消费者永远不会消费消息。如果分区数大于消费者,则会均匀的将分区分配给多个消费者。
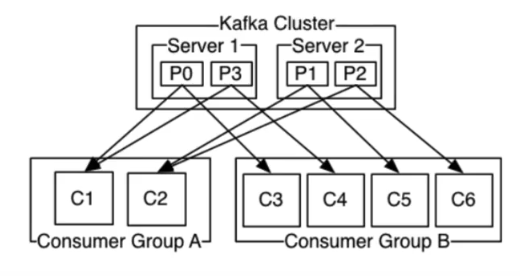
因此,kafka 的 topic 的 partition 个数代表是 kafka 的 topic 的并行度,同一时间最多可以有多个线程来消费 topic 的数据,所以如果要提高 kafka 的 topic 的消费能力,应该增大 partition 的个数。
5、手动平衡 leader:
# 使用的脚本是:kafka-leader-election.sh
# 必要的参数:
# --bootstrap-server:指定服务器列表
# --election-type:选举的类型,默认选择preferred即可
# 下面的三个参数三选一:
# --all-topic-partitions:平衡所有的主题、所有的分区
# --topic:平衡指定的主题,如果选择这个参数,则必须使用--partition指定分区
# --path-to-json-file:将需要平衡的主题、分区信息写入一个json文件,指定这个文件
# json的格式: {"partitions": [{"topic": "test", "partition": 1}, {"topic": "test", "partition": 2}]}[root@qianfeng01 data]$ kafka-leader-election.sh \
--bootstrap-server 192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092 \
--election-type preferred \
--all-topic-partitions
6、kafka 自带的压力测试工具
用Kafka官方自带的脚本,对Kafka进行压测。Kafka压测时,可以查看到哪个地方出现了瓶颈(CPU,内存,网络IO)。
一般都是网络IO达到瓶颈。
kafka-consumer-perf-test.sh
kafka-producer-perf-test.sh
(1)生产者Producer压测
kafka-producer-perf-test.sh \
--topic test \
--record-size 100 \
--num-records 100000 \
--throughput -1 \
--producer-props bootstrap.servers=192.168.135.132:9092,192.168.135.133:9092,192.168.135.134:9092
record-size:一条信息有多大,单位字节
num-records:总共发送多少条信息
throughput:每秒多少条信息,设置成-1,表示不限流,可测生产者最大吞吐量
producer-props:发送端端消息配置
结果:
100000 records sent, 27495.188342 records/sec (2.62 MB/sec), 1461.75 ms avg latency, 2183.00 ms max latency, 1696 ms 50th, 2103 ms 95th, 2177 ms 99th, 2181 ms 99.9th.
解析:
一共写入10万条消息
吞吐量为2.62 MB/sec
每次写入的平均延迟为1461.75ms
最大延迟2183.00 ms
(2)消费者 Consumer 压力测试
consumer测试,如果这四个指标(IO,CPU,内存,网络)都不能改变,考虑增加分区数来提升性能
kafka-consumer-perf-test.sh \
--broker-list hadoop100:9092 \
--topic test \
--fetch-size 10000 \
--messages 10000000 \
--threads 1
broker-list:节点地址
topic:指定topic名称
fetch-size:指定每个fetch的数据大小
messages:总共要消费的消息个数
结果:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec2020-06-27 13:17:57:490, 2020-06-27 13:18:11:751, 20.0272, 1.4043, 210000, 14725.4751, 1593235077858, -1593235063597, -0.0000, -0.0001
解释:
开始时间
结束时间
共消费数据:20.0272M
吞吐量:1.4043MB/s
共消费数据:210000条
平均每秒消费:14725.4751条