通过python爬取新浪财经的股票历史成交明细
要求
通过新浪财经爬取历史数据:http://market.finance.sina.com.cn/transHis.php?symbol=sz000001&date=2021-04-27&page=60
要求:输入日期和股票代码后将一天所有的记录存入一个csv文件,并打印输出当日股票的最大值,最小值和平均值
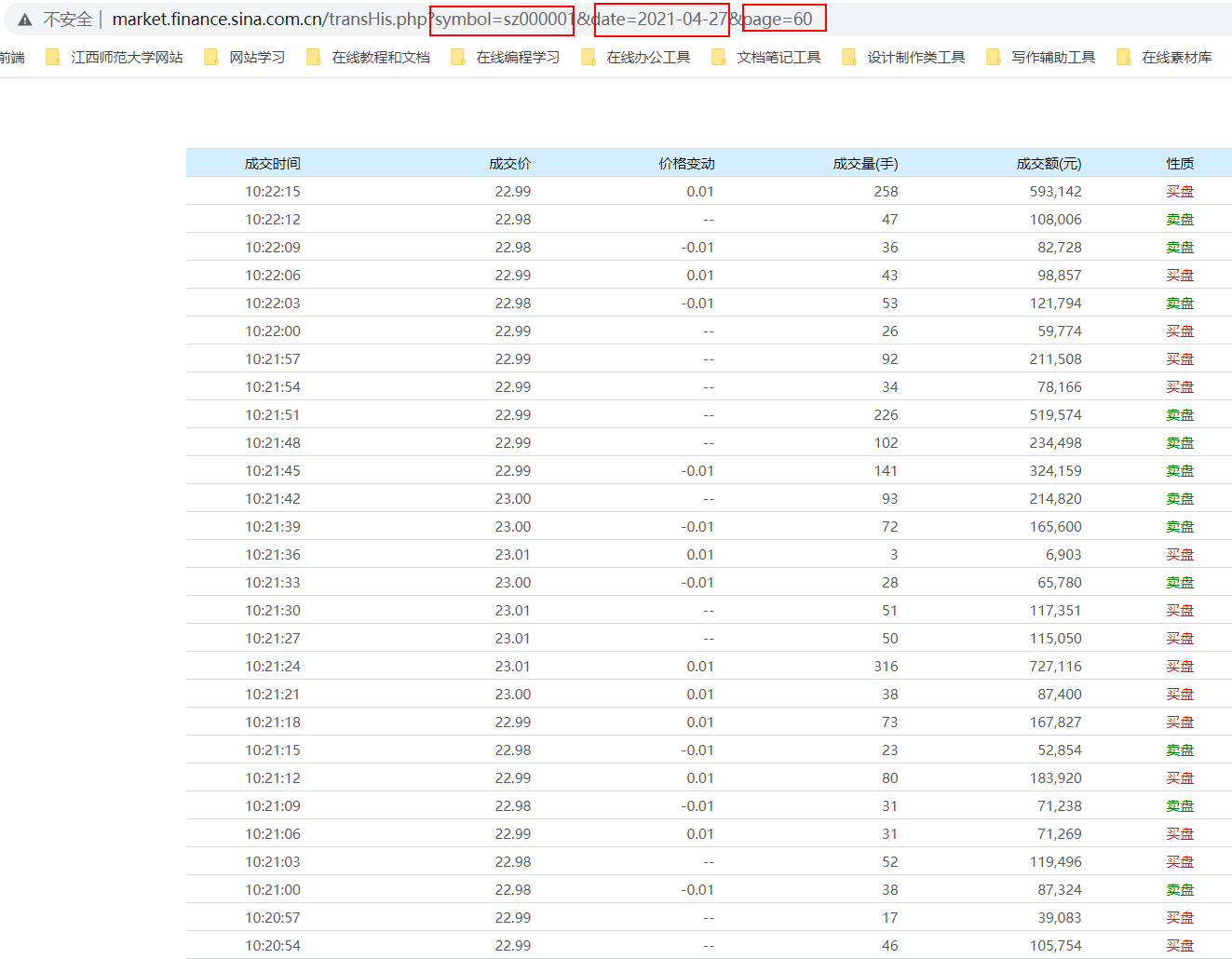
首先我们可以观察到股票的名字就是symbol参数,日期就是date参数,而page有很多页。假若我们需要爬取一整日的信息,我们就需要找到page的首页和尾页。但是每支股票每天的首页和尾页可能数字都不同,所以这个地方是难点,我们需要用if去判断是否已经到尾页。
导入库
import requests
import time
from bs4 import BeautifulSoup
import csv
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36 FS"}
# 全局定义一个listone列表用于之后存放爬取的信息
listone = []
输入想要的信息
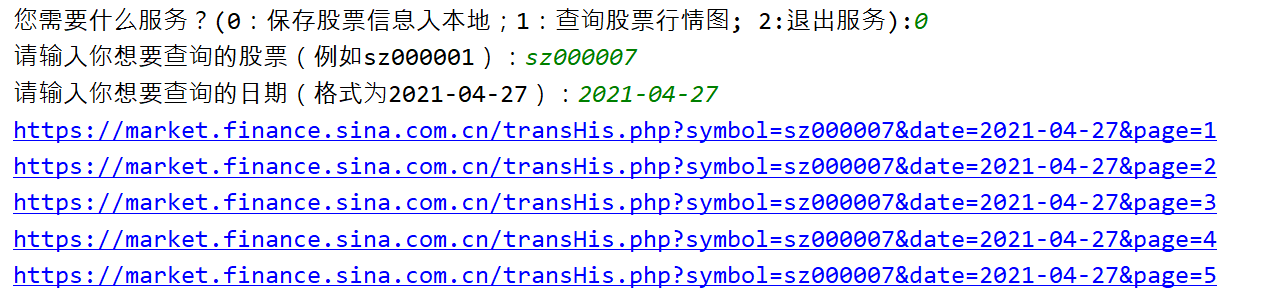
def main():#gupiao = input("请输入你想要查询的股票(例如sz000001):")#date = input("请输入你想要查询的日期(格式为2021-04-27):")# 这里的小代码我其实是为了测试以下尾页的停止,因为这个例子股票的日期在77页为尾页,80页说明flag为0# flag = gethtml('sz000001', '2021-04-27', 80)# 一般来讲股票不太可能超过100页。我们这里取一个上限值就好# 后续如果碰到尾页会之间break跳出循环不会到100页for i in range(1,100):# 早期为了不每次都手动输入可以直接先写定参数,后期再加入input# 返回如果是0则说明爬取错误或者到达尾页,要跳出循环flag = gethtml('sz000001','2021-04-27',i)# 最好需要间隔5s,否则太快爬取会被新浪封iptime.sleep(5)if flag==0:# 返回如果是0则说明爬取错误或者到达尾页,要跳出循环break#打印全局我们爬取数组保存在的listone数组里print(listone)#保存如csvsave_csv(listone)# compute()
main()
获取请求页面html
def gethtml(gupiao,date,page):# 拼接字符串urlurl = 'https://market.finance.sina.com.cn/transHis.php?symbol='+gupiao+'&date='+date+'&page='+str(page)# 打印访问url,方便后期查看进度print(url)try:# request发送get请求r = requests.get(url=url,headers=headers)# Noner.raise_for_status()# print("text的状态:",r.raise_for_status())r.encoding = r.apparent_encoding# 其实这里不管是不是尾页或是超过尾页text的状态都是none,都可以访问区别只是有没有数据而已# 所以这里我们无法根据request请求判断是否尾页,我们需要更进一层判断,即获取页面其中内容get_messageflag = get_message(r.text,page)if flag == 0:#如果get_message返回给我们的为0则说明真的出现错误或者到达尾页flag为0,需要终止跳出循环了。return 0except Exception as result:print("错误原因:",result)return 0分析r.text内容同时判断是否尾页
正常数据:
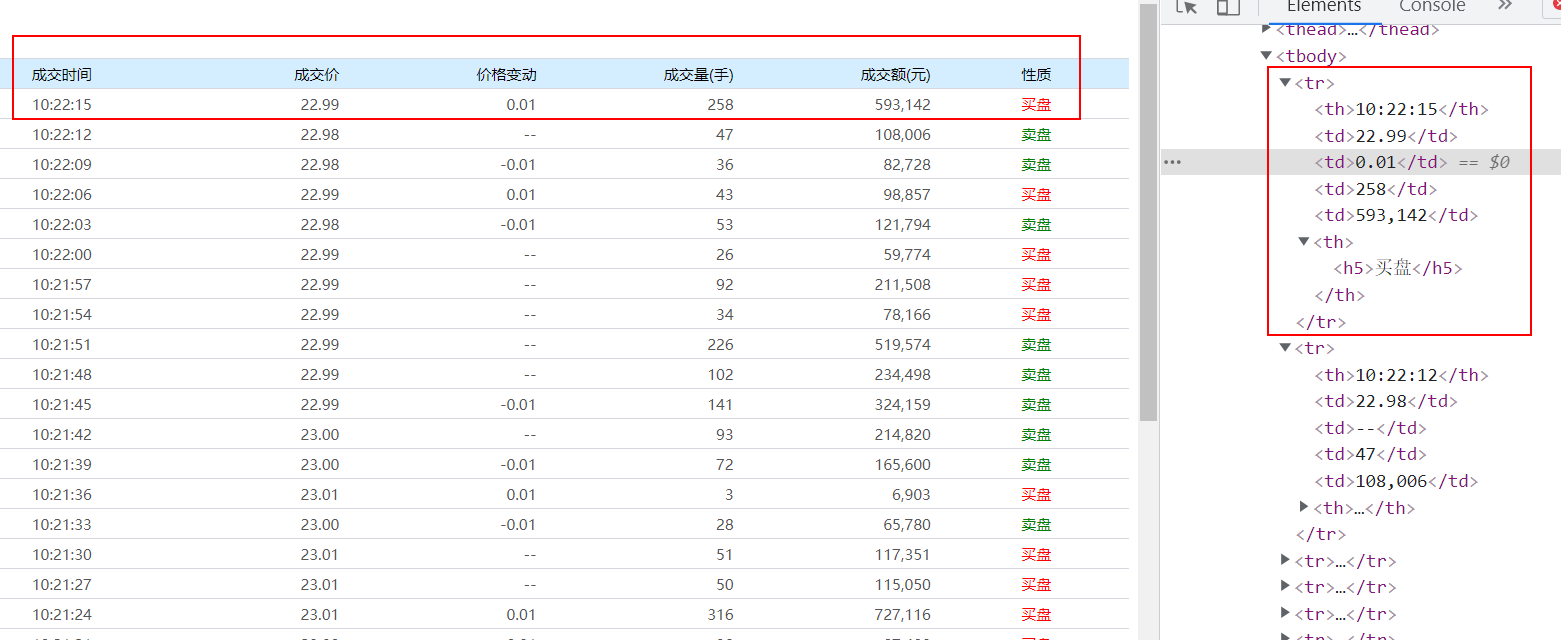
超过尾页tbody为空:
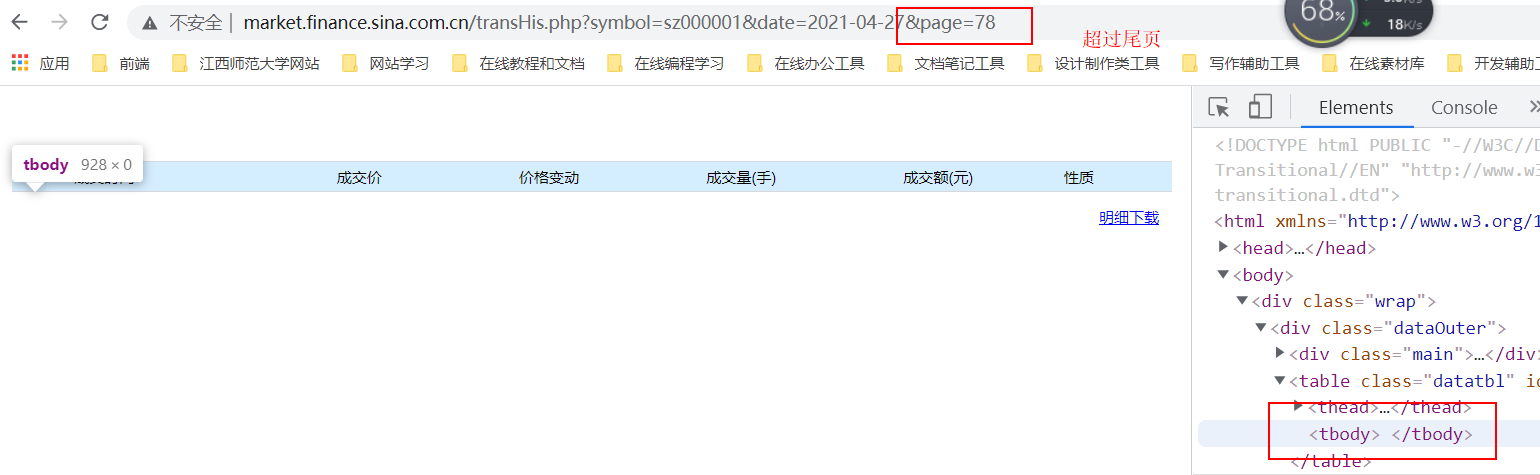
def get_message(text,page):# 煮一碗soupsoup = BeautifulSoup(text, 'lxml')# 这里我们可以打印看到如果是有数据的tbody里面会有内容,那么soup.tbody.string会为none# 但是如果是已经尾页没有数据的tbody里面会没有内容,那么soup.tbody.string会为空字符串# 我们可以根据这个区别来判断是否已经超过尾页# print(soup.tbody.string)if soup.tbody.string!=None:# 如果不是None说明tbody为空,已经爬取到尾页为空了# 此时打印到头信息,然后return 0告诉上一层并跳出循环停止爬取print('到头为空')return 0else:# 我们可以观察他整个tbody的结构,发现他的数据包含在tbody的每一个tr内# 对tbody里所有的tr进行遍历for each in soup.tbody.find_all('tr'):# 打印查看each内容# print(each)# 获取each内的th和td标签th = each.select('th')td = each.select('td')# zerofloat = float(td[0].get_text())# onefloat = float(td[1].get_text())# twoint = float(td[2].get_text())treeint = float(td[3].get_text().replace(',',''))# 根据索引获取到th内的信息,并放入listtwo中# listtwo = [th[0].get_text(),zerofloat,onefloat,twoint,treeint,th[1].contents[0].get_text()]listtwo = [th[0].get_text(),td[0].get_text(),td[1].get_text(),td[2].get_text(),treeint,th[1].contents[0].get_text()]# print(listtwo)# 最后将listtwo添加入listone的末尾listone.append(listtwo)# print(listone)
< td >和< th >标签内的索引内容:

保存入csv文件
def save_csv(list):print("list",list)with open('sina.csv', 'w',newline='', encoding='utf-8-sig') as f:wr = csv.writer(f)# 标题头wr.writerow(['成交时间','成交价','价格变动','成交量(手)','成交额(元)','性质'])# 把listone里所有爬取的数据写入csv文件wr.writerows(listone)f2.close()

求取平均值最大值最小值
def compute():with open('sina.csv','r',encoding='utf-8-sig') as f2:r = csv.reader(f2)#跳过表头的文字head = next(r)sum = 0max = 0min=100count = 0for row in r:# print(row)thisnum = float(row[1])sum = sum + thisnumif max<thisnum:max = thisnumif min> thisnum :min = thisnumcount= count+1avg = sum/countprint("最大值为",max)print("最小值为",min)print("平均值为",avg)f2.close()
pandas库
def pandas_conput(gupiao,date):if os.path.exists('sina'+gupiao+date+'.csv'):data_csv = pd.read_csv(f'sina'+gupiao+date+'.csv',encoding='utf-8-sig')print(data_csv)# 定义表格的行列名称index_df = ['成交价', '成交量(手)', '成交额(元)']columns_df = ['最大', '最小', '平均']# 填入表格数据data_df = []for index in index_df:l = []data = data_csv[index]l.append(data.max())l.append(data.min())l.append(data.mean())data_df.append(l)stock_df = pd.DataFrame(data_df, index=index_df, columns=columns_df)print(stock_df)else:print("文件不存在,请先爬取")
整体代码
import pandas as pd
import requests
import time
import os
from bs4 import BeautifulSoup
import csv
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36 FS"}
# 全局定义一个listone用于之后存放爬取的信息
listone = []def get_message(text,page):# 煮一碗soupsoup = BeautifulSoup(text, 'lxml')# 这里我们可以打印看到如果是有数据的tbody里面会有内容,那么soup.tbody.string会为none# 但是如果是已经尾页没有数据的tbody里面会没有内容,那么soup.tbody.string会为空字符串# 我们可以根据这个区别来判断是否已经超过尾页# print(soup.tbody.string)if soup.tbody.string!=None:# 如果不是None说明tbody为空,已经爬取到尾页为空了# 此时打印到头信息,然后return 0告诉上一层并跳出循环停止爬取print('到头为空')return 0else:# 我们可以观察他整个tbody的结构,发现他的数据包含在tbody的每一个tr内# 对tbody里所有的tr进行遍历for each in soup.tbody.find_all('tr'):# 打印查看each内容# print(each)# 获取each内的th和td标签th = each.select('th')td = each.select('td')#这里如果用compute函数计算平均值需要对各个数据(特别是成交额有逗号)进行处理# zerofloat = float(td[0].get_text())# onefloat = float(td[1].get_text())# twoint = float(td[2].get_text())# 因为原文有逗号,所以直接用float()强制转换会报错,所以我们需要先replace一下,如果用pandas计算其实可以不用强制转换为float,为字符串也行,但是compute必须替换为整型或浮点型进行计算treeint = float(td[3].get_text().replace(',',''))# 根据索引获取到th内的信息,并放入listtwo中# listtwo = [th[0].get_text(),zerofloat,onefloat,twoint,treeint,th[1].contents[0].get_text()]listtwo = [th[0].get_text(),td[0].get_text(),td[1].get_text(),td[2].get_text(),treeint,th[1].contents[0].get_text()]# print(listtwo)# 最后将listtwo添加入listone的末尾listone.append(listtwo)# print(listone)# 返回0则说明不存在页面 sz000001
def gethtml(gupiao,date,page):# 拼接字符串urlurl = 'https://market.finance.sina.com.cn/transHis.php?symbol='+gupiao+'&date='+date+'&page='+str(page)# 打印访问url,方便后期查看进度print(url)try:r = requests.get(url=url,headers=headers)# Noner.raise_for_status()# print("text的状态:",r.raise_for_status())r.encoding = r.apparent_encoding# 其实这里不管是不是尾页或是超过尾页text的状态都是none,都可以访问区别只是有没有数据而已# 所以这里我们无法根据request请求判断是否尾页,我们需要更进一层判断,即获取页面其中内容get_messageflag = get_message(r.text,page)if flag == 0:#如果get_message返回给我们的为0则说明真的出现错误或者到达尾页flag为0,需要终止跳出循环了。return 0except Exception as result:print("错误原因:",result)return 0def save_csv(list,gupiao,date):print("list",list)list1 = listwith open('sina'+gupiao+date+'.csv', 'w',newline='', encoding='utf-8-sig') as f:wr = csv.writer(f)wr.writerow(['成交时间','成交价','价格变动','成交量(手)','成交额(元)','性质'])wr.writerows(listone)f.close()def compute(gupiao,date):if os.path.exists('sina'+gupiao+date+'.csv'):with open('sina' + gupiao + date + '.csv', 'r', encoding='utf-8-sig') as f2:r = csv.reader(f2)head = next(r)sum = 0max = 0min = 100count = 0for row in r:# print(row)# 只单单计算了成交价thisnum = float(row[1])sum = sum + thisnumif max < thisnum:max = thisnumif min > thisnum:min = thisnumcount = count + 1avg = sum / countprint("最大值为", max)print("最小值为", min)print("平均值为", avg)f2.close()else:print("文件不存在,请先爬取")def pandas_conput(gupiao,date):if os.path.exists('sina'+gupiao+date+'.csv'):data_csv = pd.read_csv(f'sina'+gupiao+date+'.csv',encoding='utf-8-sig')print(data_csv)# 定义表格的行列名称index_df = ['成交价', '成交量(手)', '成交额(元)']columns_df = ['最大', '最小', '平均']# 填入表格数据data_df = []for index in index_df:l = []data = data_csv[index]l.append(data.max())l.append(data.min())l.append(data.mean())data_df.append(l)stock_df = pd.DataFrame(data_df, index=index_df, columns=columns_df)print(stock_df)else:print("文件不存在,请先爬取")def main():gupiao = input("请输入你想要查询的股票(例如sz000001):")date = input("请输入你想要查询的日期(格式为2021-04-27):")# 早期为了不每次都手动输入可以直接先写定参数,后期再加入input# 这里我其实是为了测试以下尾页的停止# flag = gethtml('sz000001', '2021-04-27', 80)# 一般来讲股票不太可能超过100页。我们这里取一个上限值就好# 后续如果碰到尾页会之间break跳出循环不会到100页for i in range(1,100):# 返回如果是0则说明爬取错误或者到达尾页,要跳出循环flag = gethtml(gupiao,date,i)# flag = gethtml('sz000001', '2021-04-27', i)# 最好需要间隔5s,否则太快爬取会被新浪封iptime.sleep(5)if flag==0:breakprint(listone)save_csv(listone,gupiao, date)# compute(gupiao,date)pandas_conput(gupiao, date)main()
利用qyside和qyptgraph进行绘图
这一块的内容还不是很熟悉,代码也不够完善(有一些bug),仅供参考
import pandas as pd
import requests
import time
import os
from bs4 import BeautifulSoup
import csv
import sys
from random import randint
from PySide2 import QtWidgets
import numpy as np
import PySide2
from PySide2.QtWidgets import QApplication
from PySide2.QtWidgets import QTableWidgetItem
from PySide2.QtWidgets import QTableWidget
from PySide2.QtUiTools import QUiLoader
import pyqtgraph as pg
from pyqtgraph.Qt import QtGui, QtCore
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36 FS"}
# 全局定义一个listone用于之后存放爬取的信息
listone = []class Stock:def __init__(self):loader = QUiLoader()# pyside2 一定要 使用registerCustomWidget# 来 注册 ui文件中的第三方控件,loader.registerCustomWidget(pg.PlotWidget)self.ui = loader.load("./pyside_ku/gupiao.ui")self.ui.find_but.clicked.connect(self.findonedate)self.ui.clear_but.clicked.connect(self.cleardata)def findonedate(self):# 清除画布self.ui.historyPlot.clear()# 获取股票代码,指标和日期gupiaodaima = self.ui.textedit.toPlainText()zhibiao = self.ui.comboBox.currentText()date = self.ui.date.date().toString('yyyy-MM-dd')# print(gupiaodaima,zhibiao,date)# 如果存在这个文件说明已经爬取过if os.path.exists('sina' + gupiaodaima + date + '.csv'):# 获取csvdata_csv = pd.read_csv(f'sina' + gupiaodaima + date + '.csv', encoding='utf-8-sig')# print(data_csv)# 定义表格的行列名称index_df = ['成交价', '成交量(手)', '成交额(元)','成交时间']# 填入表格数据data_price = [] #成交价data_num = [] #成交量data_money=[] #成交额data_time = [] #成交时间data_price = data_csv[index_df[0]]data_num = data_csv[index_df[1]]data_money = data_csv[index_df[2]]data_time = data_csv[index_df[3]]length = len(data_time)data_time = data_time.tolist()data_num = data_num.tolist()data_money = data_money.tolist()data_price = data_price.tolist()x = np.arange(length)xTick = []for i in zip(x,data_time):xTick.append(i)xTick = [xTick]self.ui.tableWidget.setRowCount(length)self.ui.tableWidget.setColumnCount(4)for row in range(length):item = QTableWidgetItem()item.setText(str(data_price[row]))self.ui.tableWidget.setItem(row, 0, item)for row in range(length):item = QTableWidgetItem()item.setText(str(data_num[row]))self.ui.tableWidget.setItem(row, 1, item)for row in range(length):item = QTableWidgetItem()item.setText(str(data_money[row]))self.ui.tableWidget.setItem(row, 2, item)for row in range(length):item = QTableWidgetItem()item.setText(str(data_time[row]))self.ui.tableWidget.setItem(row, 3, item)stock_table = pandas_conput(gupiaodaima,date)# print(stock_table['最小']['成交价'])if zhibiao == index_df[0]:self.ui.historyPlot.plot(x, data_price)self.ui.maxtextedit.setPlainText(str(stock_table['最大']['成交价']))self.ui.mintextedit.setPlainText(str(stock_table['最小']['成交价']))self.ui.avgtextedit.setPlainText(str(stock_table['平均']['成交价']))elif zhibiao == index_df[1]:self.ui.historyPlot.plot(x, data_num)self.ui.maxtextedit.setPlainText(str(stock_table['最大']['成交量(手)']))self.ui.mintextedit.setPlainText(str(stock_table['最小']['成交量(手)']))self.ui.avgtextedit.setPlainText(str(stock_table['平均']['成交量(手)']))elif zhibiao == index_df[2]:self.ui.historyPlot.plot(x, data_money)self.ui.maxtextedit.setPlainText(str(stock_table['最大']['成交额(元)']))self.ui.mintextedit.setPlainText(str(stock_table['最小']['成交额(元)']))self.ui.avgtextedit.setPlainText(str(stock_table['平均']['成交额(元)']))else:print('错误!')xax = self.ui.historyPlot.getAxis('bottom')xax.setTicks(xTick)else:choise2 = input("文件不存在,您要爬取么?(0:不需要;1:需要):")if (choise2 == '0'):passelif (choise2 == '1'):paqu(gupiaodaima,date)def cleardata(self):self.ui.historyPlot.clear()self.ui.textedit.setPlainText('sz000001')myPythonicDate = '2021-04-27'self.ui.date.setDate(QtCore.QDate.fromString(myPythonicDate, 'yyyy-MM-dd'))def get_message(text,page):# 煮一碗soupsoup = BeautifulSoup(text, 'lxml')# 这里我们可以打印看到如果是有数据的tbody里面会有内容,那么soup.tbody.string会为none# 但是如果是已经尾页没有数据的tbody里面会没有内容,那么soup.tbody.string会为空字符串# 我们可以根据这个区别来判断是否已经超过尾页# print(soup.tbody.string)if soup.tbody.string!=None:# 如果不是None说明tbody为空,已经爬取到尾页为空了# 此时打印到头信息,然后return 0告诉上一层并跳出循环停止爬取print('到头为空')return 0else:# 我们可以观察他整个tbody的结构,发现他的数据包含在tbody的每一个tr内# 对tbody里所有的tr进行遍历for each in soup.tbody.find_all('tr'):# 打印查看each内容# print(each)# 获取each内的th和td标签th = each.select('th')td = each.select('td')treeint = float(td[3].get_text().replace(',',''))# 根据索引获取到th内的信息,并放入listtwo中# listtwo = [th[0].get_text(),zerofloat,onefloat,twoint,treeint,th[1].contents[0].get_text()]listtwo = [th[0].get_text(),td[0].get_text(),td[1].get_text(),td[2].get_text(),treeint,th[1].contents[0].get_text()]# print(listtwo)# 最后将listtwo添加入listone的末尾listone.append(listtwo)# print(listone)
# 返回0则说明不存在页面 sz000001
def gethtml(gupiao,date,page):# 拼接字符串urlurl = 'https://market.finance.sina.com.cn/transHis.php?symbol='+gupiao+'&date='+date+'&page='+str(page)# 打印访问url,方便后期查看进度print(url)try:r = requests.get(url=url,headers=headers)# Noner.raise_for_status()# print("text的状态:",r.raise_for_status())r.encoding = r.apparent_encoding# 其实这里不管是不是尾页或是超过尾页text的状态都是none,都可以访问区别只是有没有数据而已# 所以这里我们无法根据request请求判断是否尾页,我们需要更进一层判断,即获取页面其中内容get_messageflag = get_message(r.text,page)if flag == 0:#如果get_message返回给我们的为0则说明真的出现错误或者到达尾页flag为0,需要终止跳出循环了。return 0except Exception as result:print("错误原因:",result)return 0
def save_csv(list,gupiao,date):print("list",list)list1 = listwith open('sina'+gupiao+date+'.csv', 'w',newline='', encoding='utf-8-sig') as f:wr = csv.writer(f)wr.writerow(['成交时间','成交价','价格变动','成交量(手)','成交额(元)','性质'])wr.writerows(listone)f.close()
def compute(gupiao,date):# 这里只计算了成交价的最大值最小值平均值if os.path.exists('sina'+gupiao+date+'.csv'):with open('sina' + gupiao + date + '.csv', 'r', encoding='utf-8-sig') as f2:r = csv.reader(f2)head = next(r)sum = 0max = 0min = 100count = 0for row in r:# print(row)thisnum = float(row[1])sum = sum + thisnumif max < thisnum:max = thisnumif min > thisnum:min = thisnumcount = count + 1avg = sum / countprint("最大值为", max)print("最小值为", min)print("平均值为", avg)f2.close()else:print("文件不存在,请先爬取")
def pandas_conput(gupiao,date):if os.path.exists('sina'+gupiao+date+'.csv'):data_csv = pd.read_csv(f'sina'+gupiao+date+'.csv',encoding='utf-8-sig')print(data_csv)# 定义表格的行列名称index_df = ['成交价', '成交量(手)', '成交额(元)']columns_df = ['最大', '最小', '平均']# 填入表格数据data_df = []for index in index_df:l = []data = data_csv[index]l.append(data.max())l.append(data.min())l.append(data.mean())data_df.append(l)stock_df = pd.DataFrame(data_df, index=index_df, columns=columns_df)return stock_dfelse:print("文件不存在")# 保存股票信息入本地
def paqu(gupiao,date):for i in range(1,100):flag = gethtml(gupiao,date,i)# 最好需要间隔5s,否则太快爬取会被新浪封iptime.sleep(5)if flag==0:breaksave_csv(listone,gupiao, date)pandas_conput(gupiao, date)# 查询股票行情图
def chaxun():app = QApplication([])stock = Stock()stock.ui.show()app.exec_()def main():while(1):choise = input('您需要什么服务?(0:保存股票信息入本地;1:查询股票行情图; 2:退出服务):')if choise=='0':gupiao = input("请输入你想要查询的股票(例如sz000001):")date = input("请输入你想要查询的日期(格式为2021-04-27):")paqu(gupiao,date)elif choise=='1':chaxun()elif choise=='2':breakelse:print("错误输入请重新输入")main()
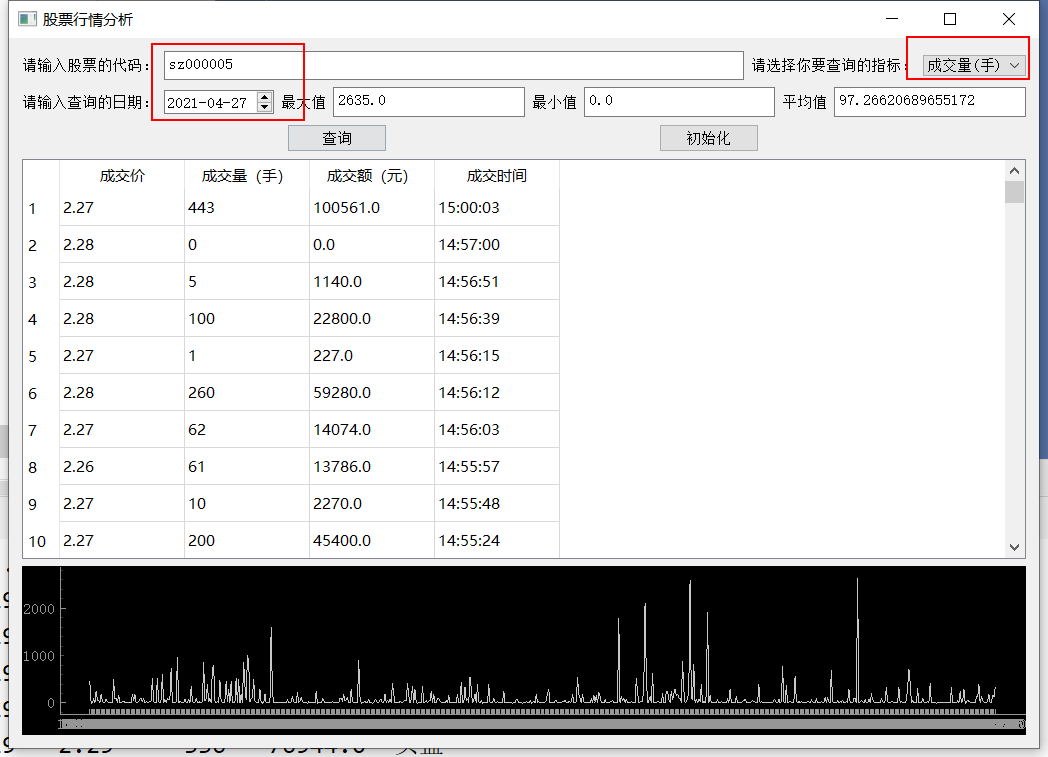
效果展示
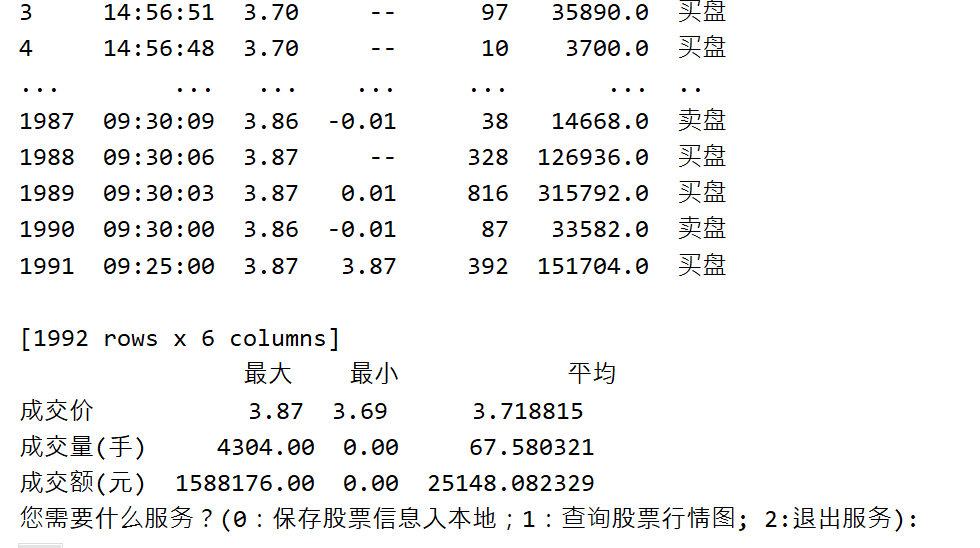
成交价
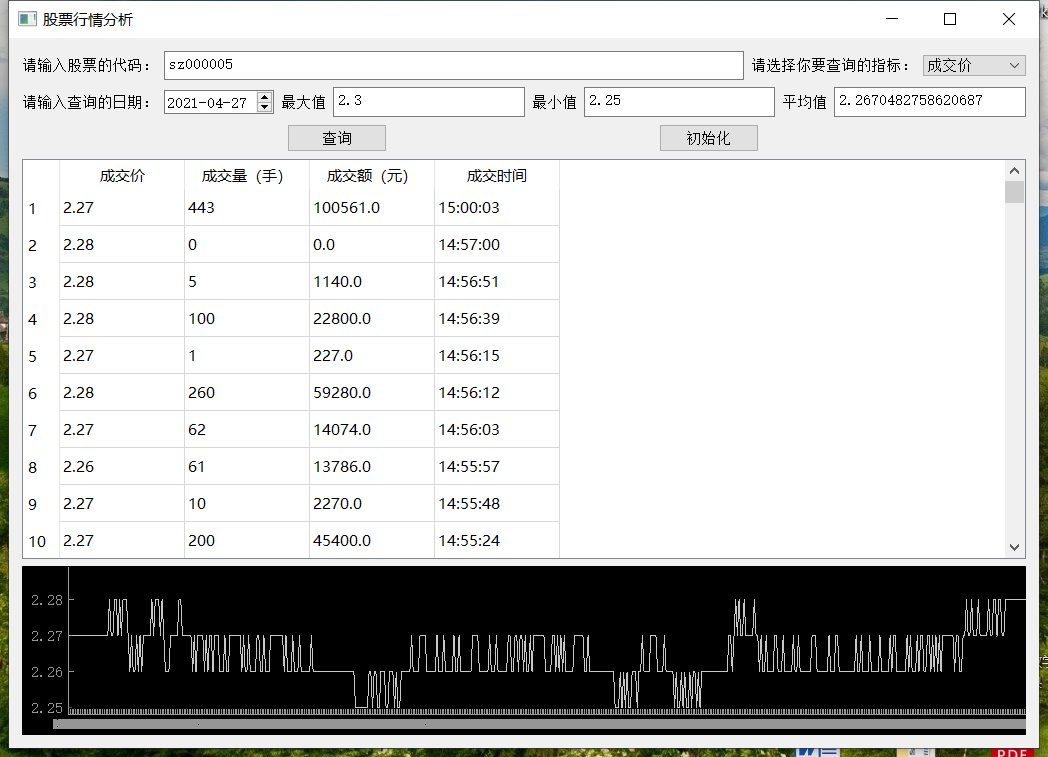
成交量