导读本文将介绍云器科技自研的 Lakehouse 产品。通过本次分享,您将了解云器 Lakehouse 产品特性,了解一体化数据平台如何提升数据处理和数据分析的效率,使之更轻松、更简洁、更高效,了解增量计算如何做到平衡数据新鲜度、查询性能和成本。
本文归纳了三个要点:
1. 利用一体化架构统一离线与实时
2. 利用增量计算,T+1 轻松升级到 T+0
3. 利用 autoMV,秒变优化老司机,性能额外提升 9X
分享嘉宾|王贯扬 云器科技 产品负责人
编辑整理|刘明城
内容校对|李瑶
出品社区|DataFun
01一体化架构统一离线与实时
云器的 Lakehouse 产品是云器自研的云原生企业级数据平台,有如下产品特性:
- 多云独立,可以完全托管在多云环境中
- 存算分离、可弹性扩展的计算引擎和存储
- 具备数据集成、数据开发、数据资产管理、运维监控等功能的数据管理平台
- 采用增量计算技术,单引擎 Lakehouse 统一批流交互全分析场景
此外,基于数据湖的一体化架构,为目前热门的人工智能大模型提供开放的接口,可以直接使用云器 Lakehouse 的数据湖中数据进行模型训练。
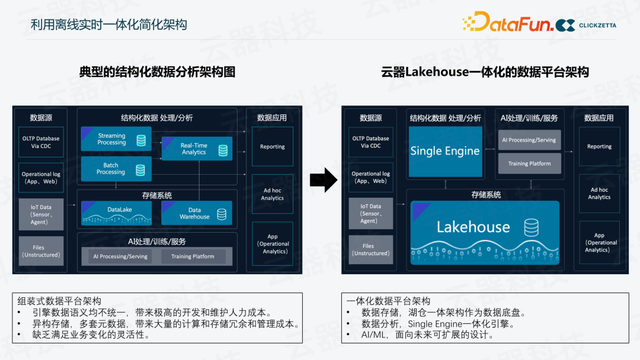
图2:组装式架构和云器 Lakehouse 一体化架构对比
云器一体化平台统一批、流和交互分析,简化数据分析架构。在传统组装式架构(Lambda 架构)下,企业会需要分别建立离线和实时的链路,并处理它们的混合。在这样的链路中,可能涉及多个计算引擎和存储系统,还可能有多种开发语言,有变化需求时,处理会十分繁琐而耗时。例如批处理场景中,通常使用 Hadoop 体系中的 Spark 或 Hive 等离线链路;当需要处理实时性要求较高的数据时,使用 Flink 等实时链路来处理并支持上层应用;而当同时需要历史数据和实时数据时,则需要将这两部分数据混合在一起,数据不一致、指标口径不一致等问题随之出现。为了应对如此复杂的开发环境,云器 Lakehouse 团队选择为客户提供一体化数据平台,使整个数据分析架构变得更加简单。
一体化平台统一了离线、实时链路中的数据存储,不再需要多套系统分别保存数据,从而保持了数据一致性,降低了数据冗余。
此外,云器 Lakehouse 采用存算分离 shared-everything 的架构设计,企业无需关注计算资源的扩容和分配,计算资源可以根据需求进行动态调整,并且按使用量计费,避免了按峰值需求采购计算资源,大幅降低了资源空闲率,节省了计算资源成本。一个引擎(Single-Engine)的另一个好处是,分析师不再需要在不同组件上适应多种 SQL 语法了,大幅降低了开发和运维的技术门槛,数据人员可以专注在数据分析和价值创新上。

图3:电商场景数据加工链路
以某电商场景数据加工为例,图3是基于一体化引擎简化架构的数据加工链路。复杂的场景统一为简洁的标准数仓架构,多样数据源数据写入原始表经过清洗加工等ETL过程,再衍生加工出 ADS 表支持上层应用。
在传统 Lambda 架构中,通常需要两条链路,一条离线加工链路完成原始表的处理,一条实时链路处理增量实时数据。最后,还需要将离线和实时数据加工结果进行汇总计算,最后提供给上层应用。
云器 Lakehouse 开发使用体验会更加简洁,举例来看:
对于同样的电商场景数据加工链路,不再需要分别建设离线加工链路和实时数据处理链路,可在实时写入数据的原始数据表上直接进行数据加工和指标分析处理。
数据加工:使用物化视图替代传统的 table 数据表,即可自动进行增量计算,使这套代码不仅可以处理离线任务,当需要变成实时任务的时候,只需要调整该物化视图的刷新时间,便可自动对距上一次刷新产生的增量数据进行处理。刷新时间的修改范围可从天级别调度到 1 分钟,在 T+1 和分钟级实时数据间灵活变化。

图4:使用物化视图进行数据加工
指标分析:建立指标分析所需的 ADS 表时,也同样使用物化视图嵌套数据加工结果的物化视图实现。开发指标分析逻辑时,全部代码都使用声明式的SQL语句编写,仅需要编写全量数据处理逻辑,结合基于物化视图的增量计算能力即可自动实现增量计算。大大降低了数据指标抽取、汇总和分析的开发难度,实现全链路的统一搭建体验。

图5:声明式全量数据处理 SQL 简化指标分析逻辑
搭建好的数据处理全链路均具备灵活在T+1到T+0范围内随时调整数据实时性的能力。可随时通过调整链路上各处理节点的物化视图刷新时间调整数据时效性。

图6:T+1 天级别调度
以下是基于上述链路生产的数据形成的BI看板。

图8:基于离线+实时一体化链路形成的BI看板
综上,云器 Lakehouse 一体化平台使用增量计算,融合了离线和实时链路,简化架构,提高开发效率,使大数据开发团队能够从容应对复杂场景的业务需求。
02利用增量计算,T+1 轻松升级到 T+0
组装式架构(也称为 Lambda 架构)是目前业界普遍的数据平台架构方式,通过结合使用多种实时、离线等功能组件,以达到支持业务的目的。然而,在实际数据分析和处理中,我们经常陷入"数据不可能三角"的困境:

图9:数据不可能三角
如果我们想提高数据的新鲜度,可能会面临数据存储成本的大幅增加;如果想节省成本,又可能会降低数据查询的性能。而如果我们想预先计算一些结果以提高常用查询的性能,又会影响数据的新鲜度。因此,我们经常需要在数据不可能三角之间进行权衡,找到一个平衡点。而不同时期,对一份数据性能、花费成本、新鲜度的考量又不同。在“数据不可能三角”中频繁权衡、转换是一个让人头疼的问题。

图10:基于下一代增量计算技术灵活调整数据新鲜度
与组装式架构相对的是一体化架构(也称为 Kappa 架构)——云器 Lakehouse 就是采用这样的架构设计,基于下一代增量计算技术,更好地平衡调整数据新鲜度、性能和成本。
什么是增量计算?增量计算类似于在 Lambda 架构中,我们进行的离线计算+实时计算。离线计算的结果就如在增量计算中,t0 时刻得到的存量数据计算结果,而实时计算部分就如增量计算中对 t0 到 t1 时间段数据增量变化 delta 进行同样计算得到的结果。增量计算实质上就是把原本的全量计算拆分为存量数据的计算结果和增量数据的计算结果,复用已有的存量数据计算结果,并对增量数据进行计算和结果合并,来达到节省计算量,提高 query 性能的目的。在云器 Lakehouse 中开发使用增量计算的数据链路,不需要编写增量计算的代码,而是可以使用物化视图来实现这个链路,仅编写全量数据的处理逻辑,就可以自动获得增量计算的能力。
增量计算并不是一个新的概念,Spark streaming 等产品也有采用,但云器 Lakehouse 的增量计算更“聪明”一些。在实际业务场景中,增量计算并不是时刻都优于全量计算的。比如在数据总量不大,但频繁变动的情况下,如果坚持所有计算都使用增量计算的逻辑,可能还不如全量计算更为高效。云器 Lakehouse 的增量计算更善于帮助用户“精打细算”。在云器 Lakehouse 中,每一次使用增量计算前,都会对增量计算所消耗的计算资源和可能带来的收益进行预估,并与全量计算进行成本和收益的对比,从而选择最为经济的方式。在这个机制下,开发人员可放心调整数据的增量刷新时间,而把方案选择、成本优化的工作交给平台自动分析。

图11:基于增量计算改造后的电商数据加工链路
上图就是基于增量计算对前文电商数据加工链路改造后的结果。从原始表到明细表、聚合表的更新均通过增量物化视图,自动应用增量计算。当调整不同的数据新鲜度和刷新时间时,能够平滑地进行迁移和变化。
03利用 autoMV,秒变优化老司机,性能额外提升 9X

图12:大量业务查询中往往存在可复用的结果
AutoMV(自动的物化视图),用AI和自动化的方式解决查询性能优化问题。
在实际应用中,我们经常会遇到业务人员对数据查询速度慢的抱怨。面对这种情况,我们只有:扩容、忍受、优化,三种选择。前两种选择并非理想之选,第三种选择可以通过优化重复或相似请求,缓存结果数据来实现。
有没有一种可能,将大量请求中重复的部分提取出来,创建成物化视图,然后将原始的 SQL 查询重写为使用这些物化视图保存的预计算结果,从而提高整体查询性能。可以,但是,这种优化是建立在对业务查询请求和底层数据都非常数据,有经验的数据开发人员花费大量时间进行分析和测试后才可完成的。通常我们在应接不暇的业务需求中,很难长时间专注于上述优化工作,此外,作业的需求也在不断变化,优化的效果也可能很快就会被稀释。
为了解决查询性能问题,我们在平台上为开发人员提供一项名为"自动物化视图(autoMV)"的技术,它可以自动创建一系列物化视图来优化指定范围内查询作业的性能。
下面通过一个模拟大规模数据查询作业的计算来展示 auto MV 的查询优化效果。
07:55
我们以 SSB 1G 的数据和查询为基准,第一次运行时关闭结果缓存和 MV 的重写,SSB 总运行时间为 16 秒多,QPS 为 0.770。而第二次运行时,仍关闭结果缓存但打开 autoMV,应用自动生成的 MV 进行 SQL 重写。经 autoMV 重写后,SSB 运行时间缩短到 2 秒多,每秒查询数提升到 6.253。从中可以看出 autoMV 可以自动完成对大量 SQL 的优化工作,优化效果显著。
我们再将这两次作业的所有 query 进行比较。在并发执行的 SSB 基准测试中,为应用 autoMV 的总耗时为 2.69 分钟。而在应用 auto MV 重写后,总耗时缩短至约 17 秒,性能提升 9.08 倍,CPU 使用时间减少 10.03 倍。

图14:auto MV 查询优化效果
在应用 autoMV 过程中,所有的 MV 操作都是后端自动处理的,对于用户而言是无感知的。此外,并非所有的 MV 都是划算的,有些 MV 的创建收益高且应用频率也高,而另一些则不划算。因此,autoMV 会放弃不划算的 MV,只选择那些能够带来显著收益的 MV,并自动创建在我们的数据仓库中。在应用 autoMV 时,全程无需手动干预,云器 Lakehouse 内置的 AI 模型可以帮助我们完成预评估 MV、创建 MV 和 query 重写等所有优化操作。
回顾本次分享的内容,首先介绍了云器 Lakehouse 使用离线实时一体化架构来简化架构,接着分享了如何使用增量计算来平衡数据的不可能三角,最后是应用 autoMV 来简化查询优化的工作,让业务人员获得更好的查询体验。
04问答环节
Q1:物化视图的方式,数据查询和计算效率怎么样。数据刷新一次的时长大概多少?
A1:基于增量计算,我们的物化视图的查询刷新效率可以达到分钟级。
Q2:查询引擎是基于什么做的?还是纯自研?
A2:查询引擎是自研的,我们有一群非常优秀的小伙伴专注于运行和优化计算,以不断提升性能。
Q3:物化视图(mv)自动创建,会自动删除吗?每个查询(query)最多生成多少物化视图(mv),如果生成太多元数据,系统会不会有压力?
A3:物化视图会根据自身的价值和生命周期进行评价,当价值不高时会自动删除以节省存储空间。每个查询生成的物化视图的数量取决于整个集群中值得创建的视图数量,这是通过对元数据进行管理和优化来保证弹性扩展的。
Q4:调度配置周期最低的频次是多少?分钟?秒?
A4:在调度配置上,最低频次是一分钟,分钟级的调度。
Q5:能详细讲下删除数据和修改是怎么在增量计算时实现的?
A5:云器提供了数据集成服务 Ingestion server,可以通过监控 binlog 流和 Kafka 消息等,进行原始数据写入。数据的写入支持 update 和 delete。在增量计算时,支持对 update 和 delete 的数据进行增量计算,并具备算法优化这类场景下增量计算的效率。
Q6:整个集群数据量大约什么规模?
A6:主要看愿意放多少规模,多少规模都是可以承载的。云器 Lakehouse 本身是基于云原生的存算分离架构,理论上计算集群和底层的存储资源都可以无限扩展。
Q7:存储必须使用对象存储的吗?可以部署在客户 hadoop 集群上吗?
A7:目前我们必须基于对象存储,因为对象存储也是目前云上性价比和可靠性综合最高的存储产品。我们也会针对性做性能优化来弥补对象存储在查询性能上的不足。
Q8:hologres 也有物化视图,不过仅支持上游表 appendonly,lakehouse 也是仅支持 appendonly 还是非 appendonly 也可以?
A8:不仅支持 appendonly,还支持物化视图和增量计算的 update 和 delete。
云器Lakehouse作为面向企业的全托管一体化数据平台,只需注册账户即可管理和分析数据,无需关心复杂的平台维护和管理问题。新一代增量计算引擎实现了批处理、流计算和交互式分析的统一,适用于多种云计算环境,帮助企业简化数据架构,消除数据冗余。