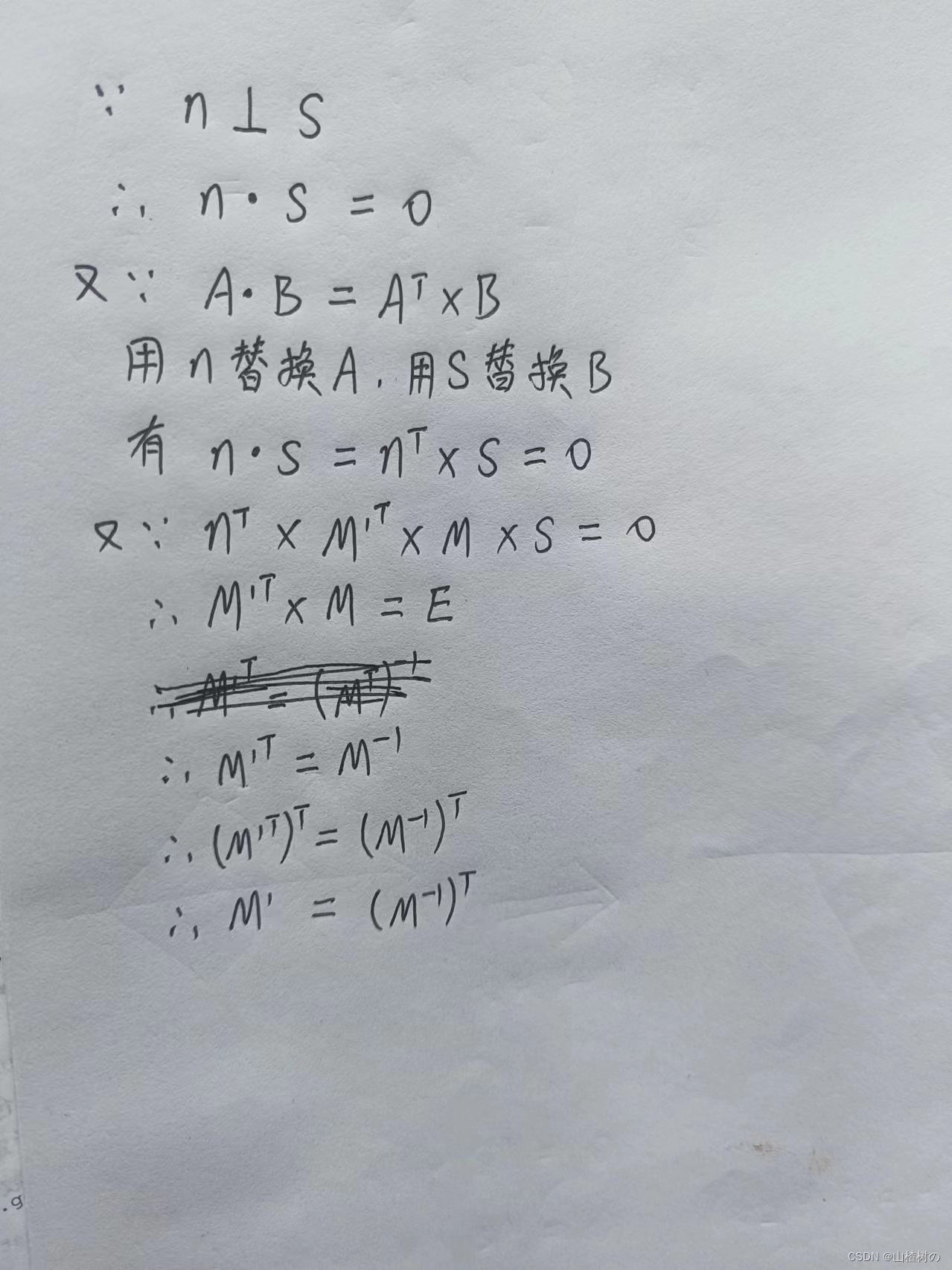⚪ 预备知识
1、理解源 IP 地址和目的 IP 地址
举例理解:(唐僧西天取经)
在 IP 数据包头部中 有两个 IP 地址, 分别叫做源 IP 地址 和目的 IP 地址。
如果我们的台式机或者笔记本没有 IP 地址就无法上网,而因为每台主机都有 IP 地址,所以注定了数据从一台主机传输到另一台主机就一定有源 IP 地址和目的 IP 地址,所以在报头中就会包含源 IP 地址和目的 IP 地址。
而我们将数据从一台主机传递到另一台主机并不是目的,真正通信的其实是应用层上的软件。
而我们知道应用层可不止一个软件。既然有了公网 IP 标识了一台唯一的主机,那么数据就可以由一台主机传递到另一台主机。但是有这么多的软件(进程),如何保证软件 A 发送的被软件 B 接收呢?(用什么来标识主机上的进程的唯一性呢?)
2、理解端口号和进程 ID
端口号是用于标识在一台设备上运行的不同网络应用程序或服务的数字标识符,它是一个 16 位的数字,可以是 0~65535 之间的任意值。当一个应用程序或服务需要通过网络进行通信时,它会打开一个特定的端口,并侦听该端口上的连接,这个侦听过程称为绑定(binding)。当其他设备或应用程序尝试连接到此端口时,操作系统会将连接转发给已经绑定到该端口的应用程序进程。
因此,可以说端口号和进程之间存在一对一的映射关系。一个特定的端口号通常与一个特定的进程或应用程序相关联,而且一个端口号只能与绑定一个进程。当网络通信发生时,数据包会通过端口号被正确地路由至相应的进程,以确保通信的正确进行。
同一台设备上的不同进程可以绑定不同的端口号,这样就使得多个应用程序能够同时进行网络通信,而无需担心冲突。每个进程可以通过独立的端口号进行区分和识别,从而实现并发的网络通信。
为了更好的表示一台主机上服务进程的唯一性,规定用端口号标识服务进程、客户端进程的唯一性。端口号(port)是传输层协议的内容。
- 端口号是一个 2 字节 16 位的整数。
- 端口号用来标识一个进程,告诉操作系统:当前的这个数据要交给哪一个进程来处理。
- 一个端口号只能被一个进程占用。(一个进程可以绑定多个端口号,但是一个端口号不能被多个进程绑定)
IP 地址(标识唯一主机)+ 端口号(标识唯一进程)能够标识网络上的某一台主机的某一个进程(全网唯一的进程)
端口号的解释:
- HTTP 通信使用的端口号是 80。在浏览器中输入网址并访问一个网站时,浏览器会与服务器进行 HTTP 通信。在这个过程中,浏览器将通过端口号 80 发送请求,以与服务器上运行的 Web 服务器进行通信。Web 服务器接收到请求后,会将相应的网页内容返回给浏览器,并通过端口号 80 将响应发送回浏览器。因此,端口号 80 在这种情况下用于标识 HTTP 通信。
- FTP 通信使用的端口号是 21。 使用 FTP 客户端与远程服务器进行文件传输时,通常使用的端口号是 21。FTP 客户端通过端口号 21 与 FTP 服务器建立连接并发送指令来上传、下载或删除文件。端口号 21 被 FTP 协议保留,用于标识 FTP 通信。
每个端口号都有特定的作用和用途,例如常见的端口号有:
- 20 和 21:FTP
- 22:SSH
- 25:SMTP(用于发送电子邮件)
- 53:DNS(域名系统)
- 80:HTTP
- 443:HTTPS
将数据送给对方的机器是我们的目的吗?
不是的,是手段。真正的网络通信过程,本质其实就是进程间通信。将数据在主机间转发仅仅是手段,机器收到之后,需要将数据交付给指定的进程。
前面说过进程间通信的本质是看到同一份资源,现在这个资源就是网络,而通信的本质就是 IO,因为我们上网的行为就两种情况:
- 把数据发送出去。
- 接收到数据。
标识一个进程有 pid,为什么还需要端口号呢?
- 首先 pid 是系统规定的,而 port 是网络规定的,这样就可以把系统和网络解耦。
- port 标识服务器的唯一性不能做任何改变,要让客户端能找到服务器,就像 110,120 一样不能被改变,而 pid 每次启动进程,pid 就会改变。
- 不是所有的进程都需要提供网络服务或请求(不需要 port),但每个进程都需要 pid。
虽然一个端口号只能绑定一个进程,但是一个进程可以绑定多个端口号。前面说了有源 IP 和目的 IP,而这里的 port 也有源端口号和目的端口号。我们在发送数据的时候也要把自己的 IP 和端口号发送过去,因为数据还要被发送回来,所以发送数据时一定会多出一部分数据(以协议的形式呈现)。
那么第一次是如何知道给哪个 IP 和 port 发送的?
服务器内部已经内置好了。
3、理解源端口号和目的端口号
传输层协议( TCP 和 UDP) 的数据段中有两个端口号 , 分别叫做源端口号和目的端口号, 就是在描述 “ 数据是谁发的, 要发给谁”。
4、认识 TCP、UDP 协议
我们用的套接字接口一定会使用传输层协议,不会绕过传输层去调用下面的协议。
传输层的协议分为 TCP 协议和 UDP 协议。
(1)TCP 协议
- 传输层协议
- 有连接(在正式通信前要先建立连接)
- 可靠传输(在内部帮我们做可靠传输工作)
- 面向字节流
(2)UDP 协议
- 传输层协议
- 无连接
- 不可靠传输(可能会出现网络丢包或数据包乱序、重复等问题)
- 面向数据报
传输层就是用来解决可靠性的一个协议。
那为什么 UDP 是不可靠传输的,而我们还要有这个协议呢?
在网络通信中,现在的主流网络出现丢包的概率并不大。即使出现了丢包的情况,在有些场景下也是可以容忍的。
可不可靠在这里只是一个中性词,是他们的特点。可靠性是需要付出大量的编码和数据的处理成本的,往往在维护和编码上都比较复杂。而不可靠没有成本,使用起来也简单。所以二者要分场景使用。
(3)网络字节序
- 小端:低权值的数放入低地址。
- 大端:低权值的数放入高地址。
那么如何定义网络数据流的地址呢?(如果一个大端机用大端的方式发送数据到一个小端机,现在跨网络我们也不知道数据到底是大端和小端)
- 发送主机通常将发送缓冲区中的数据按内存地址从低到高的顺序发出,接收主机把从网络上接到的字节依次保存在接收缓冲区中,也是按内存地址从低到高的顺序保存。
- 因此,网络数据流的地址应这样规定:先发出的数据是低地址,后发出的数据是高地址。TCP/IP 协议规定:网络数据流应采用大端字节序,即低地址高字节。不管这台主机是大端机还是小端机,都会按照这个 TCP/IP 规定的网络字节序来发送/接收数据。如果当前发送主机是小端,就需要先将数据转成大端;否则就忽略,直接发送即可。

为使网络程序具有可移植性,使同样的 C 代码在大端和小端计算机上编译后都能正常运行,可以调用以下库函数做网络字节序和主机字节序的转换。

- h 表示 host,n 表示 network,l 表示 32 位长整数,s 表示 16 位短整数。
- 例如 htonl 表示将 32 位的长整数从主机字节序转换为网络字节序,例如将 IP 地址转换后准备发送。
- 如果主机是小端字节序,这些函数将参数做相应的大小端转换然后返回。
- 如果主机是大端字节序,这些函数不做转换,将参数原封不动地返回。
一、socket 套接字
前面我们知道,IP + 端口号 port 标识了全网唯一的进程,我们把 IP + port 就叫做套接字socket。
套接字(Socket)是计算机网络编程中用于实现网络通信的一个抽象概念。它提供了一种编程接口,允许不同计算机之间通过网络进行数据传输和通信。具体来说,套接字可以看作是通信的两个端点,一个是服务器端的套接字,另一个是客户端的套接字。通过套接字,服务器端和客户端可以相互发送和接收数据。
在网络通信中,套接字使用网络协议(如 TCP/IP、UDP 等)来完成数据的传输和通信。根据所使用的网络协议的不同,套接字可以分为两种类型:
- 流套接字(Stream Socket,也称为面向连接的套接字):基于 TCP 协议,提供可靠的、面向连接的通信。使用流套接字时,数据可以按照发送的顺序和完整性进行传输,确保数据的准确性。流套接字的通信方式类似于电话通信,需要在通信前先建立连接。
- 数据报套接字(Datagram Socket,也称为无连接的套接字):基于 UDP 协议,提供不可靠的、无连接的通信。使用数据报套接字时,数据以数据包的形式进行传输,不保证数据的顺序和完整性。数据报套接字适用于一次性发送不需要可靠传输的数据。
1、socket 常见 API
(1)socket
创建 socket 文件描述符(TCP/UDP, 客户端 + 服务器)

![]()
(2)bind
绑定端口号( TCP/UDP, 服务器)

![]()
(3)listen
开始监听 socket(TCP, 服务器)

(4)accept
接收请求( TCP, 服务器)

(5)connect
建立连接( TCP, 客户端)

2、sockaddr 结构
socket API 是一层抽象的网络编程接口,适用于各种底层网络协议,如:IPv4、IPv6,以及后面要讲的 UNIX Domain Socket。然而,各种网络协议的地址格式并不相同。
套接字有不少类型,常见的有三种:
- 原始 socket
- 域间 socket
- 网络 socket
三种应用场景:网络套接字主要运用于跨主机之间的通信,也能支持本地通信,而域间套接字只能在本地通信,而原始套接字可以跨过传输层(TCP/IP 协议)访问底层的数据。
为了方便,设计者只使用了一套接口,这样就可以通过不同的参数来解决所有的通信场景。这里举两个具体的套接字类型:sockaddr_in 和 sockaddr_un:

可以看到 sockaddr_in 和 sockaddr_un 是两个不同的通信场景,区分它们就用 16 地址类型协议家族的标识符。但是,这两个结构体都不用,我们用 sockaddr。
比方说我们想用网络通信,虽然参数是 const struct sockaddr *addr,但实际传递进去的却是 sockaddr_in 结构体(注意要强制类型转换)。在函数内部一视同仁,全部看成 sockaddr 类型,然后根据前两个字节判断到底是什么通信类型然后再强转回去。可以把 sockaddr 看成基类,把 sockaddr_in 和 sockaddr_un 看成派生类,构成了多态体系。
- IPv4 和 IPv6 的地址格式定义在 netinet/in.h 中,IPv4 地址用 sockaddr_in 结构体表示,包括 16 位地址类型,16 位端口号和 32 位 IP 地址。
- IPv4、IPv6 地址类型分别定义为常数 AF_INET、AF_INET6。这样,只要取得某种 sockaddr 结构体的首地址,不需要知道具体是哪种类型的 sockaddr 结构体,就可以根据地址类型字段确定结构体中的内容。
- socket API 可以都用 struct sockaddr * 类型表示, 在使用的时候需要强制转化成 sockaddr_in,这样的好处是程序的通用性,可以接收 IPv4,IPv6,以及 UNIX Domain Socket 各种类型的 sockaddr 结构体指针做为参数
(1)sockaddr 结构

(2)sockaddr_in 结构
![]()
虽然 socket api 的接口是 sockaddr, 但是我们真正在基于 IPv4 编程时, 使用的数据结构是 sockaddr_in, 这个结构里主要有三部分信息: 地址类型, 端口号, IP 地址。
(3)in_addr 结构

in_addr 用来表示一个 IPv4 的 IP 地址,其实就是一个 32 位的整数。
二、简单的 demo —— UDP 网络程序
1、服务端的实现
要通信首先需要有 IP 地址,和绑定端口号:

(1)创建套接字 socket
在通信之前要先把网卡文件打开,函数作用:打开一个文件,把文件和网卡关联起来。
![]()
socket 是计算机网络提供的一个系统调用接口,它对传输层做了相关的一层文件系统级别的封装的接口。
- domain:是一个域,标识了这个套接字的通信类型(网络或者本地)。
![]()
(只需要关注上面框住的两个类,第一个 AF_UNIX 表示本地通信,而 AF_INET 表示网络通信)
-
type:套接字提供服务的类型。

这里我们讲的是 UDP,所以使用 SOCK_DGRAM。
-
protocol:想使用的协议,默认为 0 即可。因为前面的两个参数就已经决定了是 TCP 还是 UDP 协议了。
从这里我们就联想到系统中的文件操作,以后的各种操作都要通过这个文件描述符,所以在服务端类中还需要一个成员变量表示文件描述符。

创建完套接字后我们还需要绑定 IP 和端口号。
(2)绑定 bind

所以我们要先定义一个 sockaddr_in 结构体填充数据,再传递进去。
点分十进制字符串风格的 IP 地址(例:"192.168.110.132" )每一个区域取值范围是 [0-255]:1字节 -> 4个区域。理论上,表示一个IP地址,其实4字节就够了。点分十进制字符串风格的 IP 地址 <-> 4字节。

struct sockaddr_in {short int sin_family; // 地址族,一般为AF_INET或PF_INETunsigned short int sin_port; // 端口号,网络字节序struct in_addr sin_addr; // IP地址unsigned char sin_zero[8]; // 用于填充,使sizeof(sockaddr_in)等于16
};创建结构体后要先清空数据(初始化),我们可以用 memset,系统也提供了接口:


填充端口号的时候要注意端口号是两个字节的数据,涉及到大小端问题。
大小端转化接口:
#include <arpa/inet.h>
// 主机序列转网络序列
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
// 网络序列转主机序列
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);对于 IP,首先我们要先转成整数,再解决大小端问题。系统给了直接能解决这两个问题的接口:

上面的 inet_addr 就是把一个点分十进制的字符串转化成整数再进行大小端处理。

(3)启动服务器
作为一款网络服务器,是永远不退出的。
服务器启动-> 进程 -> 常驻进程 -> 永远在内存中存在,除非挂了
首先要知道服务器要死循环,永远不退出,除非用户删除。站在操作系统的角度,服务器是常驻内存中的进程,而我们启动服务器的时候要传递进去 IP 和端口号。

那么 IP 该怎么传递呢?
看下面的第(5)点
(4)读取数据 recvfrom
- sockfd:从哪个套接字读。
- buf:数据放入的缓冲区。
- len:缓冲区长度。
- flags:读取方式。 0 代表阻塞式读取。
- src_addr 和 addrlen:输出型参数,返回对应的消息内容是从哪一个客户端发出的。第一个是自己定义的结构体,第二个是结构体长度。

![]()

(5)地址转换函数
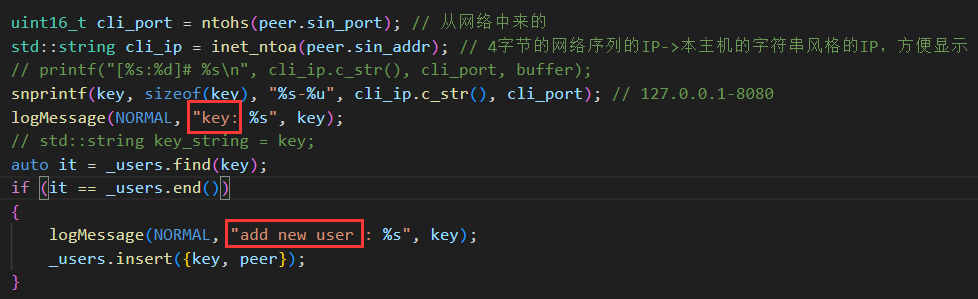
现在我们想要知道是谁发送过来的消息,信息都被保存到了 peer 结构体中,我们知道 IP 信息在 peer.sin_addr.s_addr 中。首先这是一个网络序列,要转成主机序列,其次为了方便观察,要把它转换成点分十进制。
操作系统给了一个接口能够解决这两个问题:

inet_ntoa 这个函数返回了一个 char*,很显然是这个函数自己在内部为我们申请了一块内存来保存 ip 的结果。那么是否需要调用者手动释放呢?

man 手册上说,inet_ntoa 函数是把这个返回结果放到了静态存储区。这个时候不需要我们手动进行释放。
那如果我们调用多次这个函数,会有什么样的效果呢?


因为 inet_ntoa 把结果放到自己内部的一个静态存储区,这样第二次调用时的结果会覆盖掉上一次的结果。
如果有多个线程调用 inet_ntoa,是否会出现异常情况呢?
- 在 APUE 中,明确提出 inet_ntoa 不是线程安全的函数。
- 但是在 centos7 上测试并没有出现问题,可能内部的实现加了互斥锁。
- 在多线程环境下,推荐使用 inet_ntop,这个函数由调用者提供一个缓冲区保存结果,可以规避线程安全问题。
同样获取端口号的时候也要由网络序列转成主机序列:


现在只需要等待用户端发送数据即可。
基于 IPv4 的 socket 网络编程,sockaddr_in 中的成员 struct in_addr sin_addr 表示 32 位的 IP 地址,但是我们通常用点分十进制的字符串表示 IP 地址,以下函数可以在字符串表示和 in_addr 表示之间转换:
A. 字符串转 in_addr 的函数

![]()
B. in_addr 转字符串的函数

其中 inet_pton 和 inet_ntop 不仅可以转换 IPv4 的 in_addr,还可以转换 IPv6 的 in6_addr,因此函数接口是 void *addrptr。
C. 代码示例



2、用户端的实现
首先我们要发送数据,就得知道客户端的 IP 和 port,而这里的 IP 就必须指明。

(这里的 IP 和 port 指的是要发送给谁)
创建套接字就跟前面的一样:
(1)绑定问题
这里的客户端必须绑定 IP 和端口来表示主机唯一性和进程唯一性,但不需要显示的 bind。
那为什么前面服务端必须显示的绑定 port 呢?
因为服务器的端口号是大家都知道的,不能改变,如果变了就找不到服务器了。
而客户端只需要有就可以,只用标识唯一性即可。
举例:手机上有很多的 App,而每个服务端是一家公司写的,但是客户端却是多个公司写的。如果我们绑定了特定的端口,万一两个公司都用了同一个端口号呢?这样就直接冲突了。
所以操作系统会自动形成端口进行绑定(在发送数据的时候自动绑定),所以创建客户端我们只用创建套接字即可。
(2)发送数据 sendto
这里的参数和前面讲的 recvfrom 差不多,而这里的结构体内部需要自己填充目的 IP 和目的端口号。

client 要不要 bind?
要,但是一般 client 不会显示的 bind,程序员不会自己 bind。
client 是一个客户端 -> 普通人下载安装启动使用的 -> 如果程序员自己 bind 了-> client 一定 bind 了一个固定的 ip 和 port,那万一其他的客户端提前占用了这个 port 呢?
client 一般不需要显示的 bind 指定 port,而是让 OS 自动随机选择。


3、本地间的进程通信
(1)代码







(2)IP 的绑定

这里的 127.0.0.1 叫做本地环回。client 和 server 发送数据只在本地协议栈中进行数据流动,不会将我们的数据发送到网络中。
作用:用来做本地网络服务器代码测试的,意思就是如果我们绑定的 IP 是 127.0.0.1 的话,在应用层发送的消息不会进入物理层,也就不会发送出去。

当我们运行起来后想要查看网络情况就可以用指令 netstat,后边也可以附带参数:
- -a:显示所有连线中的 Socket。
- -e:显示网络其他相关信息。
- -i:显示网络界面信息表单。
- -l:显示监控中的服务器的 Socket。
- -n:直接使用 ip 地址(数字),而不通过域名服务器。
- -p:显示正在使用 Socket 的程序识别码和程序名称。
- -t:显示 TCP 传输协议的连线状况。
- -u:显示 UDP 传输协议的连线状况。

那如果我们想要全网通信呢?该用什么 IP 呢?难道是云服务器上的公网 IP 吗?
我们可以发现,绑定不了云服务器上的公网 IP(也不建议绑定一个具体的 IP)。因为云服务器是虚拟化服务器(不是真实的 IP),所以不能直接绑定公网 IP。

既然公网 IP 绑定不了,那么内网 IP(局域网 IP)呢?

答案是可以的,说明这个 IP 是属于这个服务器的,但如果这里不是一个内网的就无法找到。
那服务器启动后怎么收到信息呢?(消息已经发送到主机,现在要向上交付)
实际上,一款服务器不建议指明一个同 IP。因为可能服务器有很多 IP,所以如果我们绑定了一个比如说 IP1,那么其他进程发送给 IP2 服务器就收不到了。


这里的 INADDR_ANY 实际上就是 0,这样绑定之后,再发送到这台主机上所有的数据,只要是访问绑定的端口(8080)的,服务器都能收到。这样就不会因为绑定了一个具体的 IP 而漏掉其他 IP 的信息了。其实就是让服务器在工作的工程中,可以从任意的 IP 中获取数据。

所以现在就不需要传递 IP 了:



三、DUP 功能扩展
- 执行 command -> pipe() fork() 子进程(exec*) command 命令。
- FILE *:可以将执行结果通过 FILE* 指针进行读取。

可以让别人通过公网 ip 给我这台机器发送消息,为了防止其他人对我的机器发送 rm 这类命令,加了一些限制(但并不完整!)



1、实现多线程互相通信(网络聊天室)
聊天室的原理是什么?
我们发送消息会经过服务端的转发,让每个在线的客户端都能看到发送的消息,这样就实现了群聊。
(1)加入聊天室进行聊天的用户
(2)分析和处理数据

(3)多线程处理
因为客户端不能立即收到消息打印出来(阻塞停留在接收消息),为了解决这个问题我们可以采用多线程,一个线程专门接收消息,一个线程专门发送消息。

(4)代码






可以发现,无论是多线程读还是写,用的 socket 都是一个,socket 代表的就是文件,UDP 是全双工的,可以同时进行收发而不受干扰。
(5)运行结果


2、UDP(Windows 环境下 C++ 实现)
在 Windows 下写客户端,在 Linux 下用 Linux 充当服务器实现客户端发送数据,服务器接收数据的功能(Windows 下的套接字和 Linux 下的几乎一样)。



注意:这里要实现正常通信,云服务器要进行被远程访问,就需要开放公网 IP 的端口,具体步骤可参考:【Linux】轻量级应用服务器如何开放端口 -- 详解-CSDN博客
四、TCP socket API 详解
下面介绍程序中用到的 socket API,这些函数都在 sys/socket.h 中。
1、插件套接字 socket
在通信之前要先把网卡文件打开。
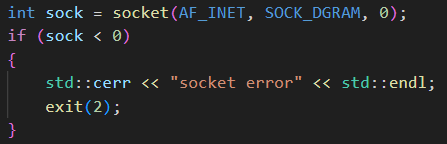
- socket() 打开一个网络通讯端口,如果成功的话,就像 open() 一样返回一个文件描述符。
- 应用程序可以像读写文件一样用 read/write 在网络上收发数据。
- 如果 socket()调用出错则返回 -1。
- 对于 IPv4,family参数指定为 AF_INET。
- 对于 TCP 协议,type 参数指定为 SOCK_STREAM,表示面向流的传输协议。
- protocol 参数的介绍忽略,指定为 0 即可。


成功则返回打开的文件描述符(指向网卡文件),失败返回-1。
这个函数的作用是打开一个文件,把文件和网卡关联起来。
- domain:一个域,标识了这个套接字的通信类型(网络或者本地)。

(只需要关注上面两个类,第一个 AF_UNIX 表示本地通信,而 AF_INET 表示网络通信。
- type:套接字提供服务的类型。

(下面的内容用的是 SOCK_STREAM)
-
protocol:想使用的协议,默认为 0 即可,因为前面的两个参数决定了,就已经决定了是 TCP 还是 UDP 协议了。
从这里我们就可以联想到系统中的文件操作,未来各种操作都要通过这个文件描述符,所以在服务端类中还需要一个成员变量表示文件描述符。

2、绑定 bind
- 服务器程序所监听的网络地址和端口号通常是固定不变的,客户端程序得知服务器程序的地址和端口号后就可以向服务器发起连接,服务器需要调用 bind 绑定一个固定的网络地址和端口号。
- bind() 的作用是将参数 sockfd 和 myaddr 绑定在一起,使 sockfd 这个用于网络通讯的文件描述符监听 myaddr 所描述的地址和端口号。
- 前面讲过,struct sockaddr* 是一个通用指针类型,myaddr 参数实际上可以接受多种协议的 sockaddr 结构体,而它们的长度各不相同,所以需要第三个参数 addrlen 指定结构体的长度。


bind() 成功返回 0,失败返回 -1。
- socket:创建套接字的返回值。
- address:通用结构体(前面有详细介绍)。
- address_len:传入结构体的长度。
所以我们需要先定义一个address_in 结构体填充数据,再传递进去。
然后就是跟 UDP 一样,先初始化结构体,再处理 IP 和端口。要注意 IP 要绑定任意 IP,也就是 INADDR_ANY 。(前面有介绍原因)

3、设置监听状态 listen
因为 TCP 是面向连接的,当我们正式通信的时候,需要先建立连接,那么 TCP 跟 UDP 的不同在这里就体现了出来。要把 socket 套接字的状态设置为 listen 状态,只有这样才能一直获取新链接,接收新的链接请求。
举例帮助理解:我们买东西如果出现了问题会去找客服,如果客服不在,那么就无法回复我们,所以就规定了客服在工作的时候必须要时刻接收回复消息,那么这个客服所处的状态就叫做监听状态。

关于第二个参数:backlog,后边讲 TCP 协议参数时会再详细介绍,目前先直接用。( 一般不能太大,也不能太小)
static const int gbacklog = 10;
listen() 成功返回 0,失败返回 -1。
- listen() 声明 sockfd 处于监听状态,并且最多允许有 backlog 个客户端处于连接等待状态,如果接收到更多的连接请求就忽略,这里设置不会太大(一般是 5)。


创建套接字成功,套接字对应的文件描述符值是 3,为什么是 3 呢?
因为当前对应的文件描述符返回的套接字本身就是一个文件描述符,0、1、2 被占用,再创建一个文件,对应的就是 3。
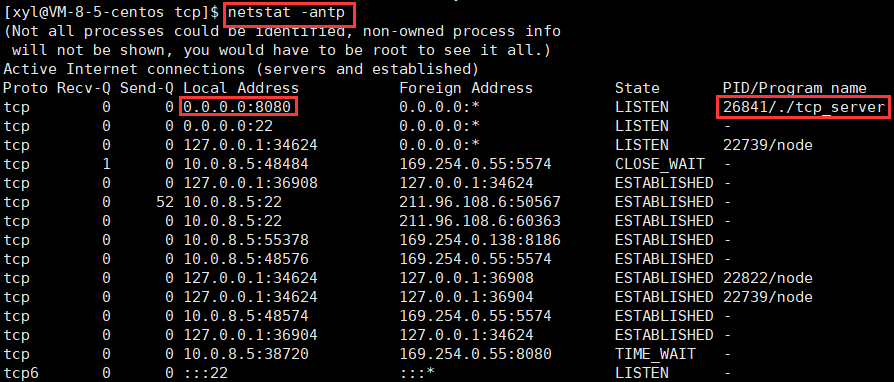
前面我们有讲到,端口号用来标识该主机上的唯一的网络服务进程,也就是上面的 8080 代表的就是 tcp_server。同时,我们也说过,一个端口号是不能被被重复绑定的。
![]()
前面还讲到命令 netstat -anup,用来查看 udp server,现在我们用命令 netstat -antp 来查看 tcp server:
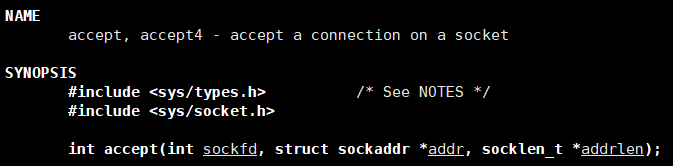
4、获取新链接 accept
前面初始化完成,现在就是要开始运行服务端。TCP 不能直接发送数据,因为它是面向链接的,所以必须要先建立链接。
![]()
成功返回一个文件描述符,失败返回 -1。
- sockfd:文件描述符,找到套接字。
- addr:输入输出型参数,是一个结构体,用来获取客户端的信息。
- addrlen:输入输出型参数,客户端传过来的结构体大小。
- 三次握手完成后,服务器调用 accept() 接受连接。
- 如果服务器调用 accept() 时还没有客户端的连接请求,就阻塞等待直到有客户端连接上来。
- addr 是一个传出参数,accept() 返回时传出客户端的地址和端口号。
- 如果给 addr 参数传 NULL,表示不关心客户端的地址。
- addrlen 参数是一个传入传出参数 (value-result argument),传入的是调用者提供的,缓冲区 addr 的长度以避免缓冲区溢出问题,传出的是客户端地址结构体的实际长度(有可能没有占满调用者提供的缓冲区)。
我们的服务器程序结构是这样的:

sockfd 本来就是一个文件描述符,那么这个返回的文件描述符是什么呢?
举例帮助理解:我们去吃饭时,会发现一些店铺的门口有工作人员来招揽顾客,他将我们领进门店之后,他会站在门口继续招揽顾客,而我们会由里面的服务员来招待我们,给我们提供服务。
这里揽客的工作人员指的就是 sockfd,而店里面的服务员就是返回值的文件描述符。也就是说,sockfd 的作用就是把链接从底层获取上来,而返回值的作用就是跟客户端通信。
那么我们就知道了,成员变量中的 _sock 并不是通信用的套接字,而是获取链接的套接字。为了方便观察,我们可以把前面所有的 _sock 换成 _listensock。

5、获取信息与返回信息(文件操作)
上面获取到了通信用的套接字 sock,因为 TCP 通信是面向字节流的,所以后续通信全部是用文件操作(IO),因为文件也是面向字节流的。
IO 的操作可以封装一个函数,方便后续进行多次扩展:

当 IO 完之后要记得关闭文件描述符 sock,否则会导致可用描述符越来越少。
(1)version 1.0(单进程循环版)

验证发现可以运行:


做一个测试,用命令 telnet(远程登陆工具)对服务端进行连接:

输入 Ctrl+],再回车,就可以发送消息并被对方收到了:

推出只需要输入命令 Ctrl+],再输入 quit 即可:


【测试多个连接的情况】

再启动一个客户端,尝试连接服务器,发现第二个客户端不能正确的和服务器进行通信。
当前版本只能一次处理一个客户端, 处理完一个才能处理下一个,这很显然是不能够被直接使用的。
为什么会导致上面的结果呢?
因为上面的代码自始至终都是单进程的,是单进程获取链接成功,进行 service,而 service 里面是一个死循环,这个死循环就是在读取。也就是说,我们 accecpt 了一个请求之后,就在一直 while 循环尝试 read,没有继续调用到 accecpt。那么如果这个循环不退出,就一直保存正常读写。而它一直在读写,那我们的单进程执行流就无法回到前面继续调用 accept,从而导致不能获取新链接做处理。

(2)version 2.0(多进程:创建子进程版)
因为 fork 后子进程会复制父进程的文件描述符。
这里注意子进程并不需要 _listensock 文件描述符,所以最好关闭。
接下来父进程怎么办呢?是等待吗?
如果父进程等待的话又会导致上面的情况,子进程不退出父进程就一直等待。子进程退出时,会给父进程发送一个 SIGCHLD,17 号信号。所以有一种解决办法就是用 signal 函数,在回调函数中把 waitpid 的参数设置为 -1(等待任意进程),就可以进行回收。

让子进程给新的连接提供服务,子进程能不能打开父进程曾经打开的文件 fd 呢?
能。因为父进程在创建子进程时,子进程的文件描述符表会继承自于父进程,会和父进程看到同一份文件。
子进程,子进程会不会继承父进程打开的文件与文件 fd 呢?
会。
子进程是来进行提供服务的,需不需要知道监听 socket 呢?
不需要。子进程就是用来提供服务的,换而言之,子进程只需要知道 servicesock 就可以了,listensock 与它没有关系,尽量让进程关闭掉它所不需要的套接字。
如果父进程关闭 servicesock 会不会影响子进程?




五、TCP 功能扩展
1、实现客户端
(1)创建套接字 socket
Socket 可以看成在两个程序进行通讯连接中的一个端点,一个程序将一段信息写入 Socket中,该 Socket 将这段信息发送给另外一个 Socket 中,使这段信息能传送到其他程序中。
所以客户端也需要一个套接字:

(2)绑定问题
client 要不要 bind 呢?
跟前面一样要绑定,但是不需要显示的 bind,但一定是需要 port,所以需要让 OS 自动进行 port 选择。客户端需要有连接别人的能力,也就是下面的(3)connect。
由于客户端不需要固定的端口号,因此不必调用 bind(),客户端的端口号由内核自动分配。
注意:
- 客户端不是不允许调用 bind(),只是没有必要调用 bind() 固定一个端口号,否则如果在同一台机器上启动多个客户端,就会出现端口号被占用导致不能正确建立连接。
- 服务器也不是必须调用 bind(),但如果服务器不调用 bind(),内核会自动给服务器分配监听端口,每次启动服务器时端口号都不一样,客户端要连接服务器就会遇到麻烦。
(3)发起链接 connect
- 客户端需要调用 connect() 连接服务器。
- connect 和 bind 的参数形式一致,区别在于 bind 的参数是自己的地址,而 connect 的参数是对方的地址。


connect() 成功返回 0,出错返回 -1。
这里的 addr 和 addrlen 填入的是服务端信息。
在 UDP 通信中,客户端在 sendto 时会自动绑定 IP 和 port,而 TCP 就是在 connect 的时候进行绑定。因为 connect 是系统调用接口,所以在调用 connect 时会自动的给绑定当前客户端的 ip 和 port,进而可以让我们在后续使用 sockfd 进行通信。

(4)客户端并行
A. version 2.1(多进程版)
前面我们在用了 signal 函数来对孙子进程可以回收,现在不用这种办法,可以这么写:

这里的意思就是创建孙子进程,父进程直接退出,让孙子进程执行 service,此时孙子进程就会被操作系统收养,不需要我们管,而父进程退出,外边的父进程也等待成功了。

其实右边服务端下面的等待可以不用等待,因为 SIGCHLD 信号默认的处理方式是忽略。

上面我们可以看到客户端退出了但是文件描述符并没有被回收,原因是我们只关闭了子进程的文件描述符,而没有关闭父进程。
B. version 3.0(多线程版)
在多线程这里用不用进程关闭特定的文件描述符呢?
不用。在多进程中每个文件都有文件描述符表,但在多线程中每一个线程和主线程共享一个文件描述符表,所以不能关闭文件描述符。


![]()




C. version 4.0(线程池版)
前面我们写过线程池,具体可以参考:【Linux 系统】多线程(线程控制、线程互斥与同步、互斥量与条件变量)-- 详解-CSDN博客
这里直接拿来用即可,修改一下代码,因为 service 可以不属于类,所以可以把 service 放在任务 Task.hpp 中。





【小写字符 -> 大写字符】
上面的 change 函数的功能是:将小写字符转换成大写字符。

【在线翻译 —— 英译汉服务器】

![]()

六、TCP 协议通讯流程
下图是基于 TCP 协议的客户端/服务器程序的一般流程:
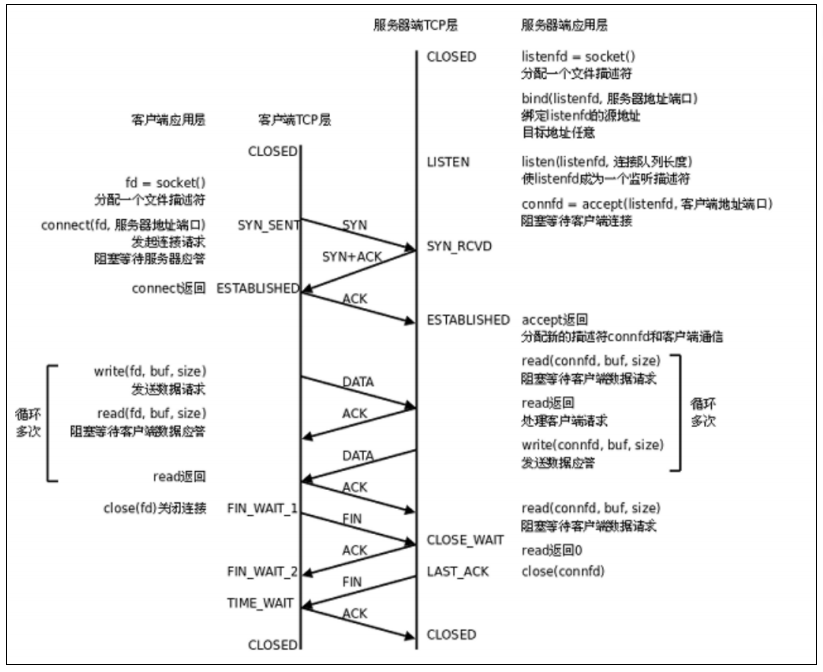
1、服务器初始化
- 调用 socket,创建文件描述符。
- 调用 bind,将当前的文件描述符和 ip/port 绑定在一起,如果这个端口已经被其他进程占用了,就会 bind 失败。
- 调用 listen,声明当前这个文件描述符作为一个服务器的文件描述符,为后面的 accept 做好准备。
- 调用 accecpt,并阻塞,等待客户端连接过来。
2、建立连接的过程
- 调用 socket,创建文件描述符。
- 调用 connect,向服务器发起连接请求。
- connect 会发出 SYN 段并阻塞等待服务器应答(第一次)。
- 服务器收到客户端的 SYN,会应答一个 SYN-ACK 段表示 “同意建立连接”(第二次)。
- 客户端收到 SYN-ACK 后会从 connect() 返回,同时应答一个 ACK 段(第三次)。
3、数据传输的过程
- 建立连接后,TCP 协议提供全双工的通信服务。所谓全双工的意思是,在同一条连接中, 同一时刻,通信双方可以同时写数据。相对的概念叫做半双工,同一条连接在同一时刻,只能由一方来写数据。
- 服务器从 accept() 返回后立刻调用 read(),读 socket 就像读管道一样,如果没有数据到达就阻塞等待。
- 这时客户端调用 write() 发送请求给服务器, 服务器收到后从 read() 返回,对客户端的请求进行处理,在此期间客户端调用 read()阻塞等待服务器的应答;
- 服务器调用 write() 将处理结果发回给客户端,再次调用 read() 阻塞等待下一条请求。
- 客户端收到后从 read() 返回,发送下一条请求,如此循环下去。
4、断开连接的过程
- 如果客户端没有更多的请求了,就调用 close() 关闭连接,客户端会向服务器发送 FIN 段(第一次)。
- 此时服务器收到 FIN 后,会回应一个 ACK,同时 read 会返回 0(第二次)。
- read 返回之后,服务器就知道客户端关闭了连接, 也调用 close 关闭连接,这个时候服务器会向客户端发送一个 FIN(第三次)。
- 客户端收到 FIN,再返回一个 ACK 给服务器(第四次)。
为什么是四次挥手呢?
因为 TCP 是基于确定应答来保证单项可靠性的,如果对方给我发消息,我也给对方进行应答,那么就能够保证双向的可靠性。所以,发出去的断开连接的过程需要应答。当客户端断开连接时,要保证客户端到服务的连接被成功关闭,所以需要调用一次,而服务端除了要释放自身创建好的文件描述符,也要关闭从服务端到客户端对应的连接,因为双方都要调用 close() 各自两次,那么一来一来就绪各自需要两次挥手,加起来就是四次挥手。
5、在学习 socket API 时要注意应用程序和 TCP 协议层是如何交互的
- 应用程序调用某个 socket 函数时 TCP 协议层完成什么动作,比如调用 connect() 会发出 SYN 段。
- 应用程序如何知道 TCP 协议层的状态变化,比如从某个阻塞的 socket 函数返回就表明 TCP 协议收到了某些段,再比如 read() 返回 0 就表明收到了 FIN 段。
七、总结
对比 UDP 服务器,TCP 服务器多了获取新链接和监听的操作,而因为 TCP 是面向字节流的,所以接收和发送数据都是 IO 操作,也就是文件操作。
1、TCP 和 UDP 对比
- 可靠传输 VS 不可靠传输
- 有连接 VS 无连接
- 字节流 VS 数据报
![【UnityUI程序框架】The PureMVC Framework[一]底层源码中文详解](https://img-blog.csdnimg.cn/430fd5b6362d48c281827ddc6a56789d.gif)