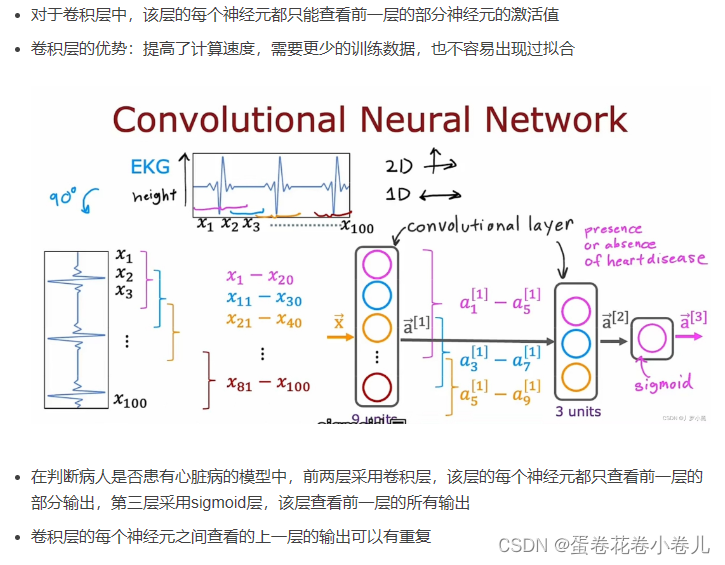
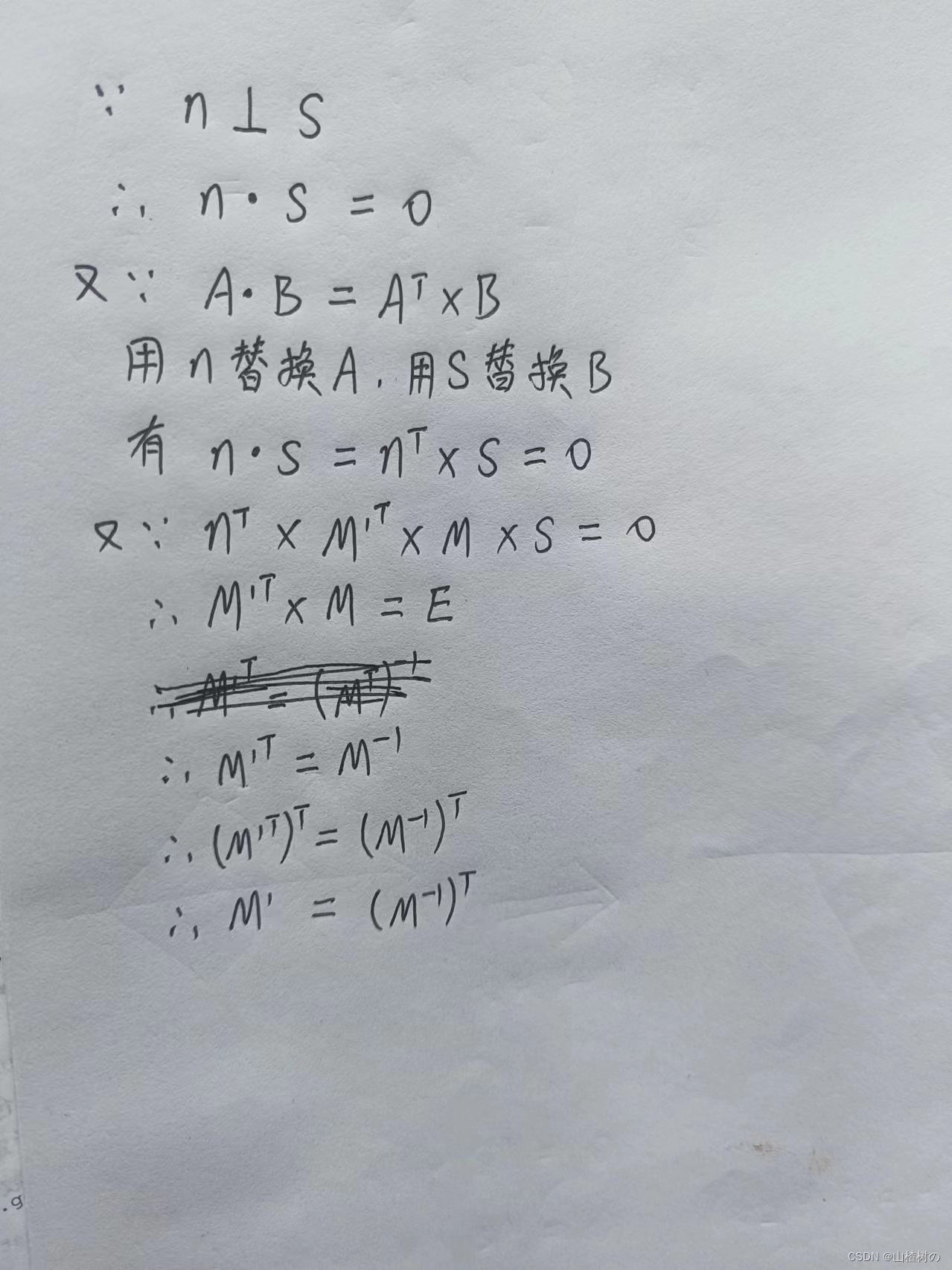神经网络中的层:输入层(layer 0)、隐藏层、卷积层(看情况用这个)、输出层。(参考文章)
激活函数:
隐藏层一般用relu函数;
输出层根据需要,二分类用sigmoid,多分类用softmax…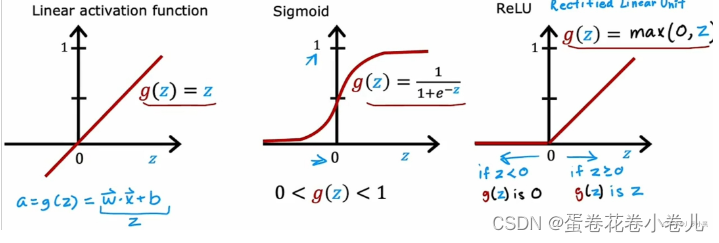 前向传播算法:参考文章
前向传播算法:参考文章
前向传播python实现
反向传播算法:参考文章
用Tensorflow搭建一个神经网络:参考文章
多分类问题
- softmax回归算法:
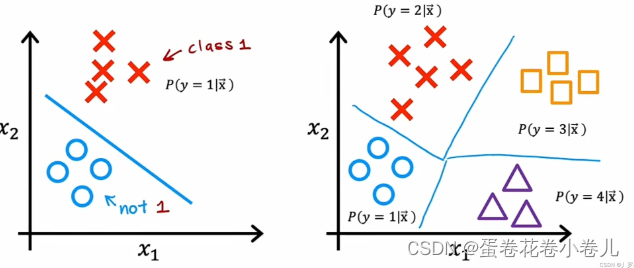 上图中 左二分类;右多分类
上图中 左二分类;右多分类
算法公式:
2. Softmax回归算法的损失函数: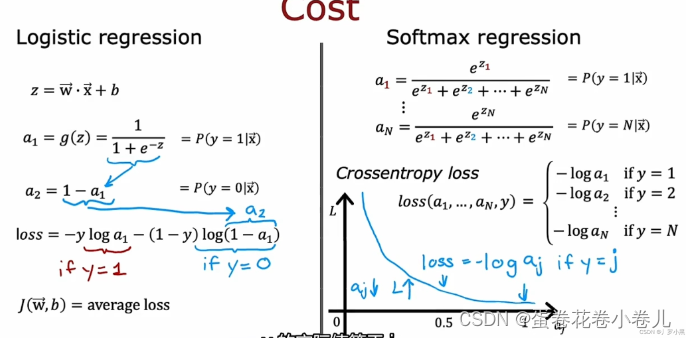

Adam算法
参考文章
- 在梯度下降中,学习率α控制着每一步的大小,如果α太小,可能会导致每一步走的太小,从而使梯度下降执行的太慢;相反,如果α太大,可能会导致每一步走的太大,从而使梯度下降来回振荡。
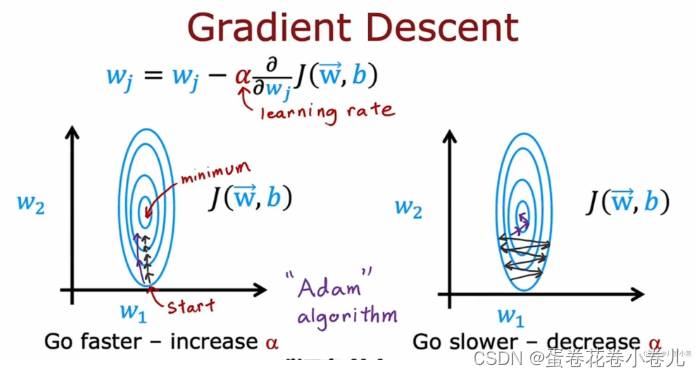
- Adam算法可以自动调整α的大小,来保证可以用最短、最平滑的路径到达成本函数的最小值,通常它比梯度下降算法的速度要更快。
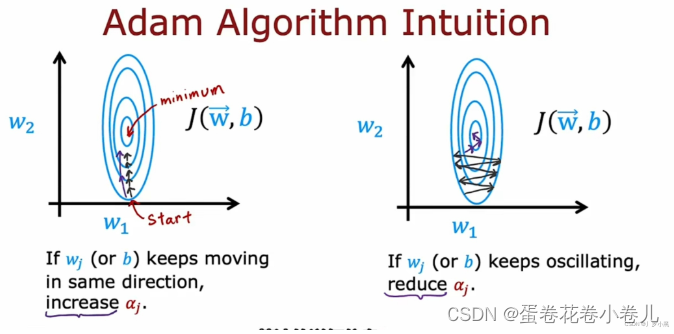
- 在w、b参数每次改变都朝着大致相同的方向移动时,adam算法会加大学习率α
- 在w、b参数每次改变都不断来回振荡时,adam算法会减小学习率α
交叉验证集

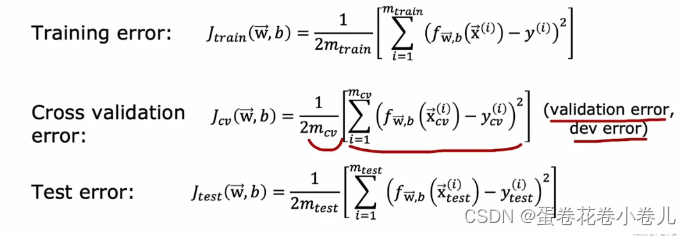
首先用训练集训练模型,之后用验证集选出最小的J,即相对最好的模型。
超参数d与 J t r a i n J_{train} Jtrain、 J c v J_{cv} Jcv的关系:(即随着数据的增多, J t r a i n J_{train} Jtrain、 J c v J_{cv} Jcv的图)
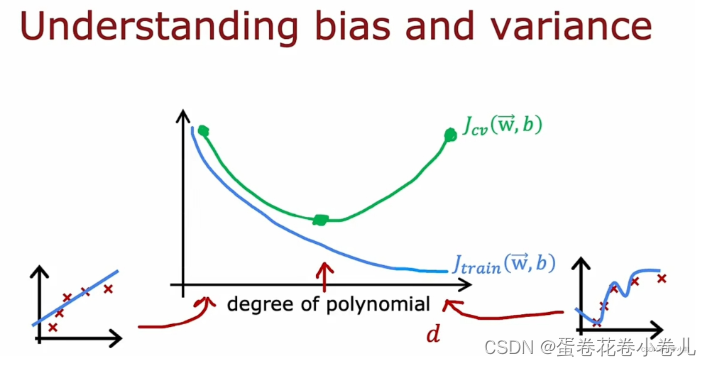
λ如何影响 J t r a i n J_{train} Jtrain、 J c v J_{cv} Jcv:
通过最小 J c v J_{cv} Jcv,可以帮助选择一个合适的λ、d,从而帮助选择合适的模型
补充:下图中的式子为L2正则化(L1和L2正则化的区别)
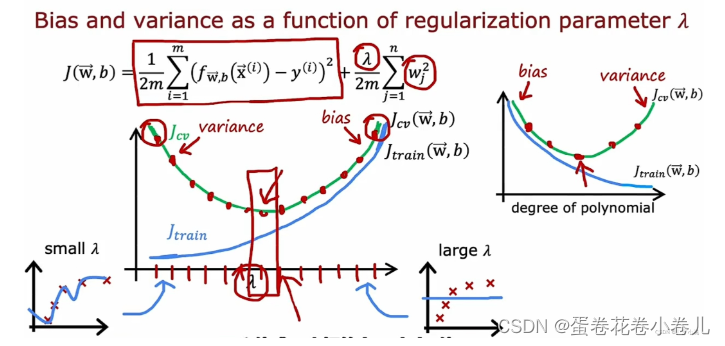
如何选择一个合适的λ:
从0开始,一次次的增大,找出最小的J。

学习曲线
通过画学习曲线这种可视化方式,来观察 J c v J_{cv} Jcv和 J t r a i n J_{train} Jtrain,并判断模型是否有高方差和高偏差。通过高方差、高偏差来改善模型算法。
(貌似一般不咋用,了解即可)参考文章
数据添加
- 加新数据
- 数据增强:通过旋转、缩小、方法、增加对比度、镜像变换等改变已有的训练样本,来获得一个全新的训练样本
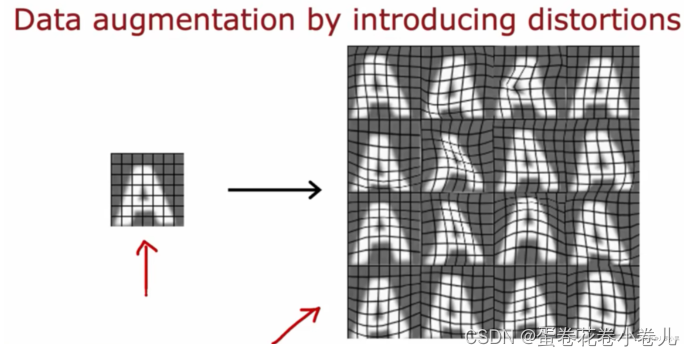 3. 数据合成:使用电脑上的字体,通过不同的对比度,颜色,字体进行截图得到。
3. 数据合成:使用电脑上的字体,通过不同的对比度,颜色,字体进行截图得到。

迁移学习
参考文章1
参考文章2

举例:你要训练狗的图片,但你先用猫的图片进行训练模型,训练好的模型再用狗的进行训练微调模型。这就是迁移学习。




![【UnityUI程序框架】The PureMVC Framework[一]底层源码中文详解](https://img-blog.csdnimg.cn/430fd5b6362d48c281827ddc6a56789d.gif)