文章目录
- 1 Hudi 简介
- 2 COW和MOR
- 3 接入COW模式Hudi表
- 4 使用Flink SQL查看新接表
- 5 使用Hive查看新接表
- 6 总结
1 Hudi 简介
Hudi是一个流式数据湖平台,使用Hudi可以直接打通数据库与数据仓库,连通大数据平台,支持对数据增删改查。Hudi还支持同步数据入库,提供了事务保证、索引优化,是打造实时数仓、实时湖仓一体的新一代技术。下面以我实际工作中遇到的问题,聊下湖仓一体的好处,如有不对,敬请指正。

像传统关系型数据库,MySQL/Oracle等大多支持OLTP,但不支持OLAP。如果写很复杂的SQL,传统关系型数据库根本跑不动,尤其是需要跨系统/跨数据库联合查询分析,传统关系型数据库并不支持(这个可以使用Presto解决)。
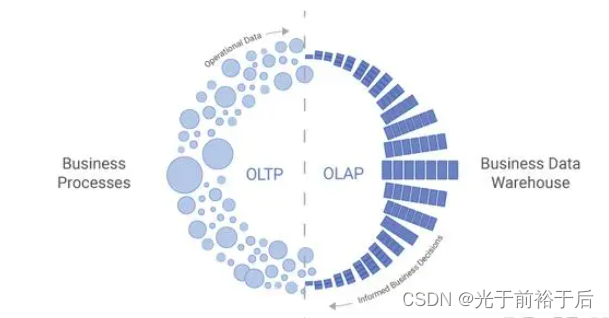
而离线数仓无法支持实时/准实时需求,无法记录级更新,当业务表数据量很大时,无论使用增量还是全量接入Hive,对业务库都有很大压力(使用从库可缓解)。Hudi能很好解决这个问题,通过配置可以准实时的写入Hudi,并同步到Hive,相当于业务表数据准实时的同步到Hive,这时取快照或者直接当作ODS层都可,再也不用担心ODS接入延迟了。
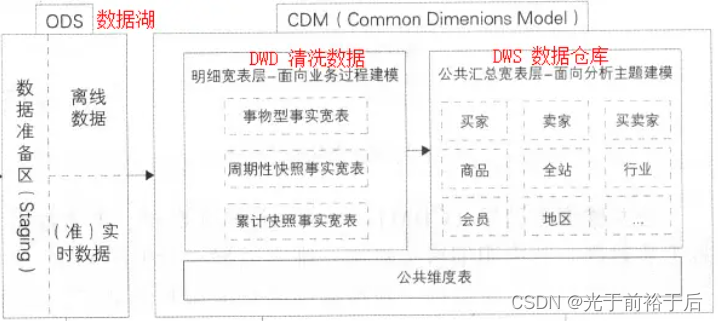
2 COW和MOR
Hudi有两种表类型,COW和MOR,如果接入表读多写少可选择COW,如字典表,读少写多使用MOR。
Copy on write:写时复制,使用列式文件格式(如 parquet)存储数据。不同进程在访问同一资源的时候,只有更新操作,才会去复制一份新的数据并更新替换,否则都是访问同一个资源。
Merge on read:读时合并,使用列式+基于行的(例如avro)文件格式的组合存储数据。更新被记录到增量文件中,然后被压缩以同步或异步地生成新版本的列式文件。
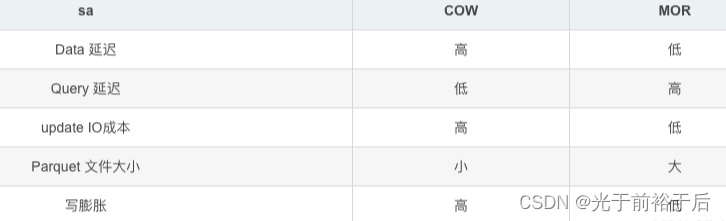
如果Hudi表是COPY_ON_WRITE类型,那么映射的Hive表对应是指定的Hive表名,此表中存储着Hudi所有数据。
如果Hudi表类型是MERGE_ON_READ模式,那么映射的Hive表将会有2张,一张后缀为rt ,另一张表后缀为ro。后缀rt对应的Hive表中存储的是Base文件Parquet格式数据+log Avro格式数据,也就是全量数据。后缀为ro Hive表中存储的是存储的是Base文件对应的数据。
3 接入COW模式Hudi表
开发测试时,可在客户端调试
./bin/sql-client.sh embedded -s yarn-session
调试没问题后,在DolphinScheduler配置上线

选择FLINK_STREAM
根据集群类型,选择部署方式
初始化脚本
初始化脚本配置一些参数和建表
SET 'yarn.application.queue' = 'root.etl';
set execution.checkpointing.interval='300s';
SET execution.checkpointing.mode = AT_LEAST_ONCE;
-- 保存checkpoint文件的目录
set state.checkpoints.dir='hdfs://cluster/tmp/flink/checkpoints/h_account_holiday';
-- 恢复时需设置检查点 set execution.savepoint.path='hdfs://cluster/tmp/flink/checkpoints/h_account_holiday/077107d6530a1c63cb9126258cfe2546/chk-72';set taskmanager.network.memory.buffer-debloat.enabled=true;SET state.checkpoints.num-retained= 3;
SET execution.checkpointing.externalized-checkpoint-retention = RETAIN_ON_CANCELLATION;set execution.checkpointing.min-pause = '180000';
set 'table.exec.sink.upsert-materialize' = 'NONE';
set execution.checkpointing.max-concurrent-checkpoints=1;set akka.ask.timeout = '1200s';
set web.timeout = '500000';
set heartbeat.timeout=500000;SET 'connector.mysql-cdc.max-connection-attempts' = '5';
SET 'connector.mysql-cdc.connection-attempts-timeout' = '1200s';SET restart-strategy='fixed-delay';
SET restart-strategy.fixed-delay.attempts='50';
SET restart-strategy.fixed-delay.delay='1min';
SET execution.checkpointing.timeout='40min';SET state.backend='rocksdb';
SET state.backend.incremental=true;set high-availability='zookeeper';
set high-availability.storageDir='hdfs://cluster/tmp/flink/ha-yarn';
set high-availability.zookeeper.quorum='bigdata-093:2181,bigdata-094:2181,bigdata-ds-12-195:2181,bigdata-ds-12-198:2181,bigdata-ds-12-199:2181';
set high-availability.zookeeper.path.root='/flink_yarn';
set yarn.application-attempts='10';CREATE CATALOG cdc_catalog WITH (
'type' = 'hive',
'default-database' = 'flink_cdc',
'hive-conf-dir' = '/opt/apps/apache-hive-2.1.1-bin/conf'
);
-- 使用刚创建的catalog
use catalog cdc_catalog;
-- 选择flink_cdc库
use flink_cdc;drop table if exists source_account_holiday;
create table if not exists source_account_holiday(
`id` int primary key not enforced
,workday date
,week int
,next_workday date
,create_time timestamp
,update_time timestamp
) with (
'connector'='mysql-cdc',
'hostname'='10.100.xx.xx',
'port'='3306',
'server-time-zone'='Asia/Shanghai',
'server-id'='6066-6070', -- 注意同一个实例,id不要重复,数字范围要大于并行度
'username'='xxx',
'password'='xxx',
'debezium.snapshot.mode'='initial',
'database-name'='xd_account',
'table-name'='account_holiday',
'connect.timeout'='1000000'
);drop table if exists sink_account_holiday;
create table if not exists sink_account_holiday(
`id` int primary key not enforced
,workday date
,week int
,next_workday date
,create_time string -- 注意timestamp需转成string
,update_time string -- 注意timestamp需转成string
) with (
'connector' = 'hudi',
'path' = 'hdfs://cluster/tmp/flink/hudi/sink_account_holiday',
'hoodie.datasource.write.recordkey.field'='id', -- 设置主键
'table.type'='COPY_ON_WRITE',
'write.timezone'='Asia/Shanghai',
'hive_sync.enabled'='true',
'hive_sync.mode'='hms',
'hive_sync.metastore.uris'='thrift://bigdata-003:9083,thrift://bigdata-004:9083,thrift://bigdata-009:9083,thrift://bigdata-012:9083,thrift://bigdata-008:9083,thrift://bigdata-007:9083',
'hive_sync.db'='hudi', -- 同步到hive hudi库h_account_holiday,自动建表
'hive_sync.table'='h_account_holiday',
'hive_sync.username'='hive',
'hoodie.datasource.hive_sync.omit_metadata_fields'='true'
);
脚本
从source表写入sink表
insert into sink_account_holiday
select id
,workday
,week
,next_workday
,date_format(create_time, 'yyyy-MM-dd HH:mm:ss') -- 注意timestamp需转成string
,date_format(update_time, 'yyyy-MM-dd HH:mm:ss') -- 注意timestamp需转成string
from source_account_holiday;
执行后注意看日志,成功会有Application ID 和 Job ID
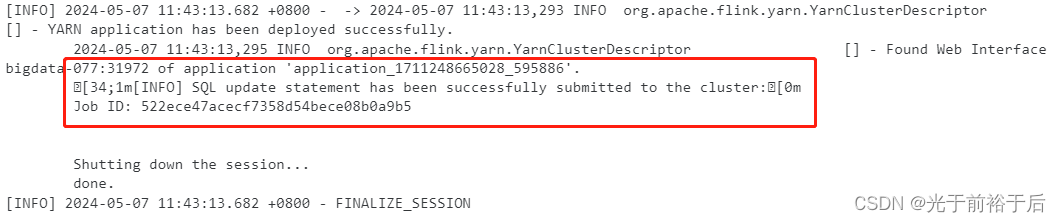
可通过Application ID 和 Job ID查看任务运行情况
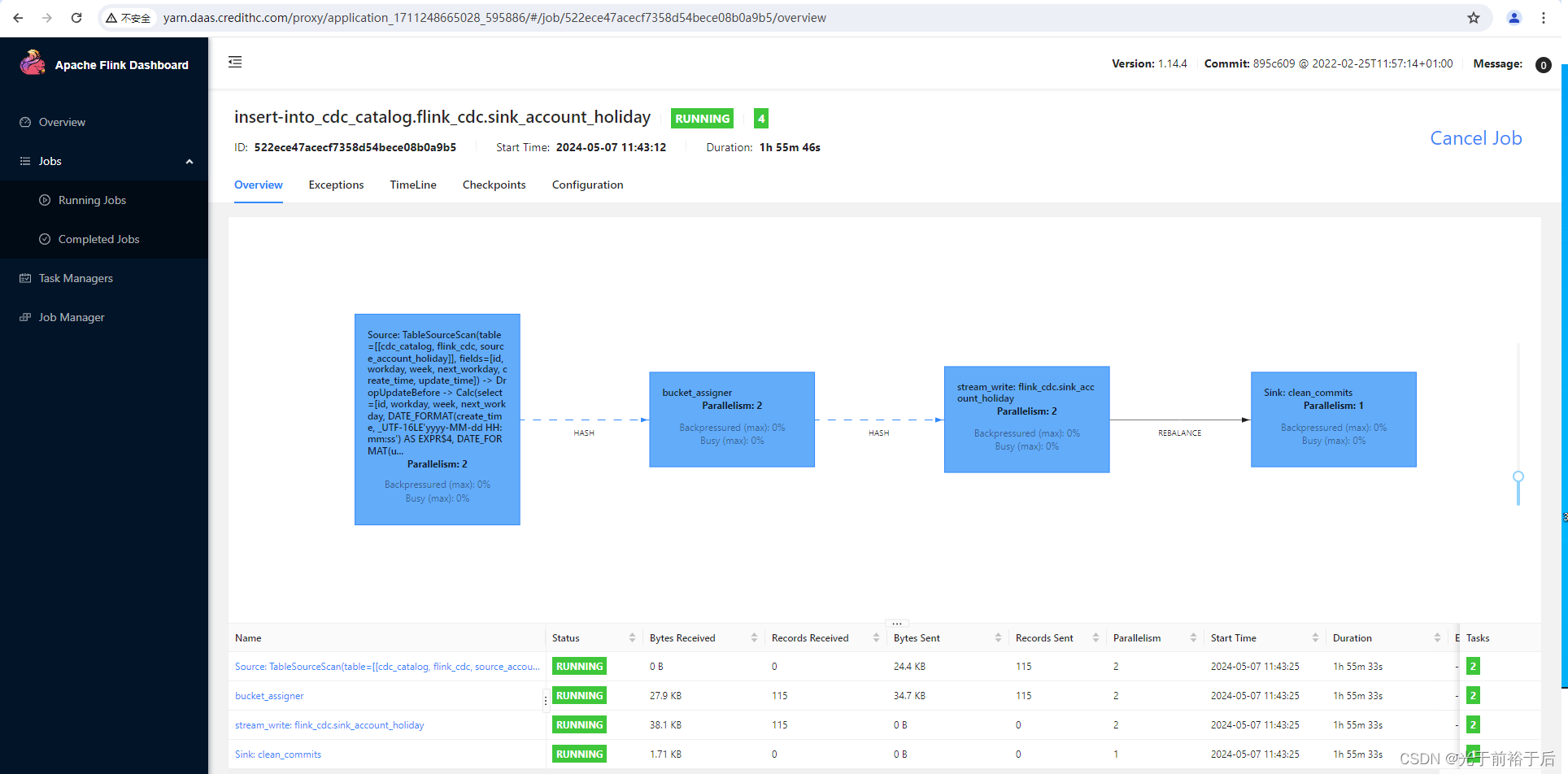
4 使用Flink SQL查看新接表
使用Flink SQL,可以实时看到数据更新
cd /opt/apps/flink-1.14.4/
./bin/sql-client.sh embedded -s yarn-session
embedded 内嵌模式
Flink SQL> CREATE CATALOG cdc_catalog WITH (
> 'type' = 'hive',
> 'default-database' = 'flink_cdc',
> 'hive-conf-dir' = '/opt/apps/apache-hive-2.1.1-bin/conf'
> );
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
[INFO] Execute statement succeed.Flink SQL> use catalog cdc_catalog;
[INFO] Execute statement succeed.Flink SQL> show databases;Flink SQL> use hudi;
[INFO] Execute statement succeed.
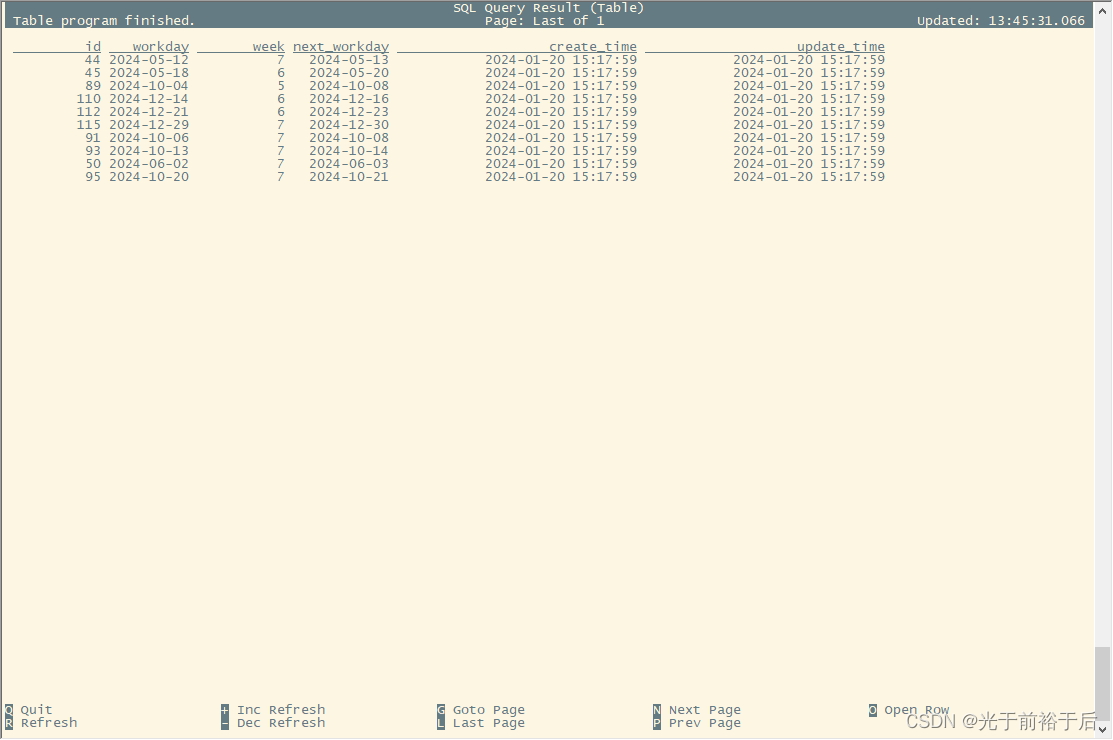
Flink SQL> select * from h_account_holiday limit 10;
5 使用Hive查看新接表
前面初始化脚本必须配置同步到hive,hive查不了source和sink表,只能查同步到hive的表
hive> use hudi;
OK
Time taken: 2.406 seconds
hive> set role admin;
OK
Time taken: 0.093 seconds
hive> select * from h_account_holiday limit 10;
OK
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
44 2024-05-12 7 2024-05-13 2024-01-20 15:17:59 2024-01-20 15:17:59
45 2024-05-18 6 2024-05-20 2024-01-20 15:17:59 2024-01-20 15:17:59
89 2024-10-04 5 2024-10-08 2024-01-20 15:17:59 2024-01-20 15:17:59
110 2024-12-14 6 2024-12-16 2024-01-20 15:17:59 2024-01-20 15:17:59
112 2024-12-21 6 2024-12-23 2024-01-20 15:17:59 2024-01-20 15:17:59
115 2024-12-29 7 2024-12-30 2024-01-20 15:17:59 2024-01-20 15:17:59
91 2024-10-06 7 2024-10-08 2024-01-20 15:17:59 2024-01-20 15:17:59
93 2024-10-13 7 2024-10-14 2024-01-20 15:17:59 2024-01-20 15:17:59
50 2024-06-02 7 2024-06-03 2024-01-20 15:17:59 2024-01-20 15:17:59
95 2024-10-20 7 2024-10-21 2024-01-20 15:17:59 2024-01-20 15:17:59
Time taken: 0.147 seconds, Fetched: 10 row(s)

6 总结
使用这种方案,真正实现了湖仓一体,基本满足了实时和离线需求,且主要使用SQL,开发和维护成本较低。不过,该方案也有个问题,flink cdc 会挂,导致数据没更新,还是要多关注下。
参考链接:
https://blog.csdn.net/qq_32727095/article/details/123863620
https://zhuanlan.zhihu.com/p/471842018
https://zhuanlan.zhihu.com/p/526372429
https://blog.csdn.net/JH_Zhai/article/details/136042662
https://www.jianshu.com/p/0837ada9de76

![[AIGC] 压缩列表了解吗?快速列表 quicklist 了解吗?](https://img-blog.csdnimg.cn/img_convert/7c70dfe31cd6cefffd2b2ffcd0dd652d.png)