🎩 欢迎来到技术探索的奇幻世界👨💻
📜 个人主页:@一伦明悦-CSDN博客
✍🏻 作者简介: C++软件开发、Python机器学习爱好者
🗣️ 互动与支持:💬评论 👍🏻点赞 📂收藏 👀关注+
如果文章有所帮助,欢迎留下您宝贵的评论,点赞加收藏支持我,点击关注,一起进步!
目录
前言
正文
01-机器学习分类模型简介
02-正态和收缩线性判别分析在分类中的应用
03-基于Scikit-Learn识别手写数字的图像
04-绘制不同分类器的分类概率
05-不同分类器的决策边界的性质比较
06-协方差椭球的线性和二次判别分析
总结
前言
机器学习分类模型是一种通过学习数据集中的特征与标签之间的关系,从而对新的数据进行分类的方法。其基本思想是通过训练数据来构建一个模型,然后利用这个模型对新的数据进行分类。常见的分类模型包括逻辑回归、支持向量机、决策树、随机森林、K近邻等。
正文
01-机器学习分类模型简介
机器学习分类模型是一种通过学习数据的特征与它们所属类别之间的关系,从而对新的未知数据进行分类的算法。这些模型可以用于解决各种分类问题,如图像识别、文本分类、医学诊断等。下面是一些常用的机器学习分类模型的工作原理和一些常见的分类算法:
工作原理:
数据准备:首先,需要准备带有标签的训练数据,其中包含输入特征(即描述数据的属性)和相应的类别标签。
模型训练:然后,选择合适的分类模型并使用训练数据对其进行训练。在训练过程中,模型会学习输入特征与类别标签之间的关系,以找到最佳的分类决策边界或者模型参数。
模型评估:训练完成后,使用测试数据评估模型的性能,通常使用一些性能指标(如准确率、精确率、召回率等)来衡量模型的分类效果。
预测:最后,可以使用训练好的模型对新的未知数据进行分类预测。
常见的分类算法:
支持向量机(SVM):SVM是一种强大的监督学习算法,其目标是找到一个最佳的超平面来将不同类别的数据分开,并使得边界到最近的训练样本的距离尽可能大。SVM在处理高维数据和非线性数据方面表现良好。
决策树:决策树是一种基于树结构的分类算法,它通过对数据进行递归的二分,每次选择最优的特征进行分裂,直到达到停止条件为止。决策树易于理解和解释,同时也能够处理分类和回归问题。
逻辑回归:逻辑回归虽然名字中带有"回归",但实际上是一种用于处理二分类问题的分类算法。它基于sigmoid函数将输入特征映射到0到1之间的概率值,然后根据概率值进行分类决策。
K近邻(K-Nearest Neighbors,KNN):KNN是一种基于实例的学习算法,它通过比较新样本与训练集中样本的相似度来进行分类。当需要对一个新样本进行分类时,KNN会找到离该样本最近的K个训练样本,并根据它们的类别进行投票决定新样本的类别。
下面以较为经典的支持向量机SVM分类算法为例,给出具体代码分析应用过程,这段代码主要解释如下:
加载数据集:使用load_iris()函数加载了鸢尾花数据集,其中包含了花萼和花瓣的长度和宽度等特征以及鸢尾花的类别。
数据预处理:将加载的数据集分为训练集和测试集,其中80%的数据用于训练模型,20%的数据用于评估模型性能。
创建和训练模型:首先创建了一个线性核的支持向量机(SVM)模型,并使用训练集对其进行训练。然后,又创建了一个相同的SVM模型,但这次在训练之前使用了主成分分析(PCA)对数据进行了降维处理。
模型评估:对训练好的两个模型进行了预测,并计算了预测准确率和混淆矩阵。准确率是模型在测试集上的分类正确率,而混淆矩阵则提供了模型在每个类别上的分类情况。
可视化决策边界:最后,使用绘制决策边界的函数plot_decision_boundary()对两个模型的决策边界进行了可视化。
# 导入所需的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.decomposition import PCA# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建SVM模型
svm_model = SVC(kernel='linear', random_state=42)# 训练模型
svm_model.fit(X_train, y_train)# 预测
y_pred = svm_model.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)# 可视化混淆矩阵
conf_mat = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(conf_mat)# 运行结果
Accuracy: 1.0
Confusion Matrix:
[[10 0 0][ 0 9 0][ 0 0 11]]# 创建SVM模型# 使用PCA进行数据转换
pca = PCA(n_components=2).fit(X_train)
X_train_pca = pca.transform(X_train)# 训练模型
svm_model.fit(X_train_pca, y_train)# 绘制决策边界
plt.figure(figsize=(10, 6))
plot_decision_boundary(svm_model, X_train_pca, y_train)
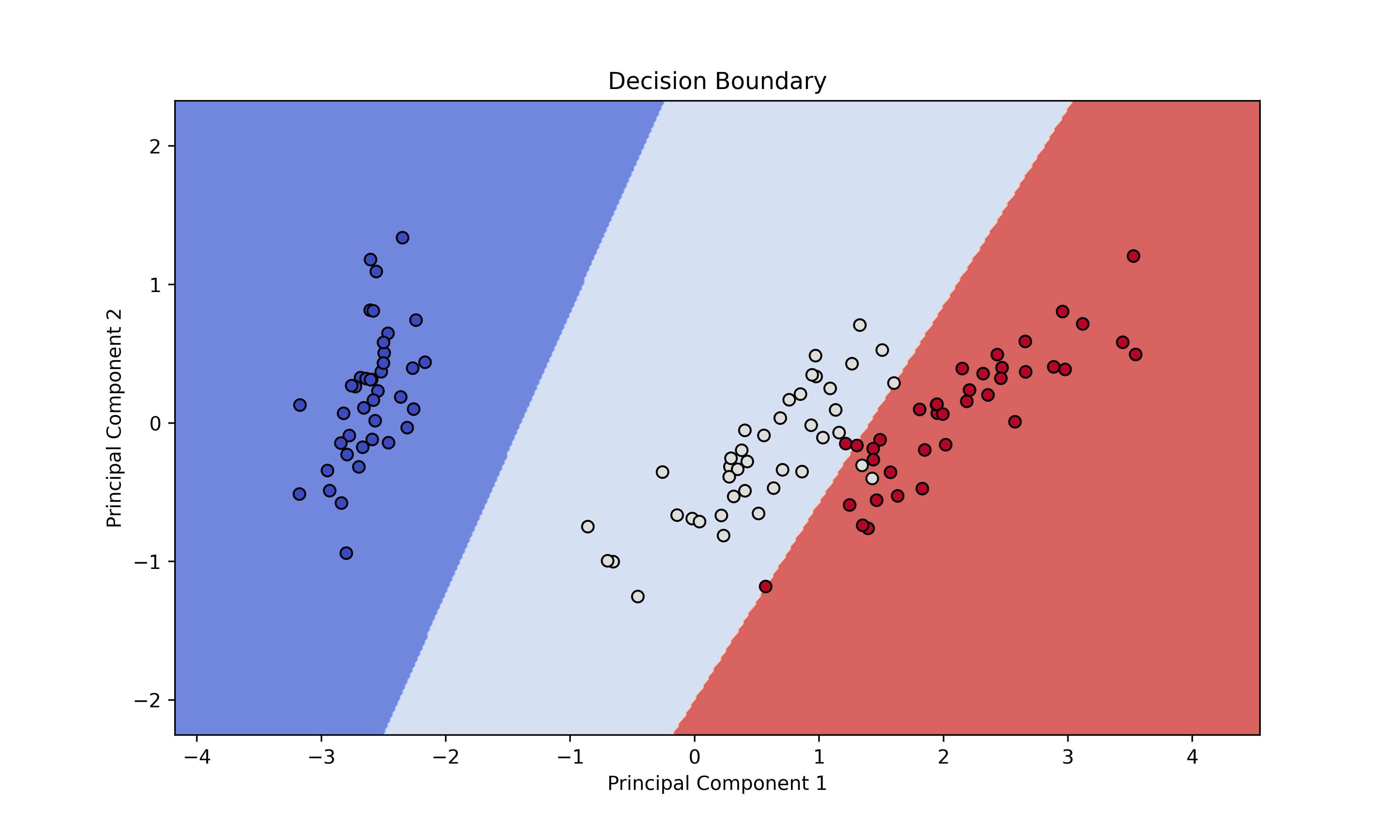
plt.show()示例运行结果如下图所示:
a、图像中的点表示训练集中的样本数据,不同颜色的点代表不同类别的样本。
b、背景色表示模型对特征空间的划分,不同颜色的背景表示模型对应的不同类别。
c、决策边界是将特征空间分成两部分的边界线,可以看作是模型对不同类别的分界线。在这个例子中,决策边界是一条直线,因为使用了线性核的SVM模型。
d、通过观察决策边界,可以了解模型是如何将不同类别的样本分开的,以及模型对于不同类别的判断边界。
02-正态和收缩线性判别分析在分类中的应用
正态判别分析(LDA)和收缩线性判别分析(Shrinkage Linear Discriminant Analysis)是两种常用的分类算法,它们在处理分类问题时具有不同的特点和应用场景。
正态判别分析(LDA):工作原理:LDA是一种监督学习算法,旨在将数据投影到低维空间,同时最大化类别之间的距离,最小化类别内部的方差。它基于假设每个类别的数据服从多变量正态分布,并通过计算类别间的均值差异和类别内部的协方差矩阵来找到最优投影方向。应用场景:LDA通常用于处理多类别分类问题,特别是当类别之间的分布差异比较明显时。它在人脸识别、语音识别、生物医学等领域有着广泛的应用。
收缩线性判别分析(Shrinkage Linear Discriminant Analysis):工作原理:与传统的LDA相比,收缩LDA通过引入收缩估计来减少对协方差矩阵估计的方差,从而提高了在高维数据下的分类性能。它通过对协方差矩阵进行缩放,使得具有相似特征的类别之间的协方差更加接近,从而改善了对协方差矩阵估计的不准确性。应用场景:收缩LDA通常用于高维数据分类问题,特别是当样本量较少、维度较高或者协方差矩阵估计不准确时。它在基因表达数据分析、图像分类等领域有着广泛的应用。
在实际应用中,选择使用LDA还是收缩LDA取决于数据的特点和问题的要求。如果数据集是低维且满足正态分布假设,并且样本量充足,则可以考虑使用传统的LDA。而如果数据集是高维的、样本量较少或者协方差矩阵估计不准确,则收缩LDA可能是更好的选择,因为它能够提高分类性能并减少过拟合的风险。
下面给处具体代码示例分析应用过程,这段代码解释如下:
数据生成:使用make_blobs函数生成了包含两个类别的样本数据,其中一个类别的中心点为[-2],另一个类别的中心点为[2]。然后在数据中添加了非判别性的特征,以模拟真实世界的数据集。
分类器性能评估:对于不同的特征数量,循环进行了多次训练和测试,计算了线性判别分析(LDA)和收缩线性判别分析(Shrinkage LDA)在每个特征数量下的平均分类精度。
绘图:使用Matplotlib库将不同特征数量下的平均分类精度绘制成图表。其中,横轴表示特征数量与样本数量的比率(即𝑛特征/𝑛样品n特征/n样品),纵轴表示分类精度。通过绘制两种分类器在不同特征数量下的分类精度曲线,可以比较它们的性能表现。
import numpy as np
import matplotlib.pyplot as pltfrom sklearn.datasets import make_blobs
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus'] = False
n_train = 20 # samples for training
n_test = 200 # samples for testing
n_averages = 50 # how often to repeat classification
n_features_max = 75 # maximum number of features
step = 4 # step size for the calculationdef generate_data(n_samples, n_features):X, y = make_blobs(n_samples=n_samples, n_features=1, centers=[[-2], [2]])# add non-discriminative featuresif n_features > 1:X = np.hstack([X, np.random.randn(n_samples, n_features - 1)])return X, yacc_clf1, acc_clf2 = [], []
n_features_range = range(1, n_features_max + 1, step)
for n_features in n_features_range:score_clf1, score_clf2 = 0, 0for _ in range(n_averages):X, y = generate_data(n_train, n_features)clf1 = LinearDiscriminantAnalysis(solver='lsqr', shrinkage='auto').fit(X, y)clf2 = LinearDiscriminantAnalysis(solver='lsqr', shrinkage=None).fit(X, y)X, y = generate_data(n_test, n_features)score_clf1 += clf1.score(X, y)score_clf2 += clf2.score(X, y)acc_clf1.append(score_clf1 / n_averages)acc_clf2.append(score_clf2 / n_averages)features_samples_ratio = np.array(n_features_range) / n_trainplt.plot(features_samples_ratio, acc_clf1, linewidth=2,label="收缩线性判别分析", color='blue')
plt.plot(features_samples_ratio, acc_clf2, linewidth=2,label="线性判别分析", color='red')plt.xlabel('n_特征/n_样品')
plt.ylabel('分类精度')
plt.grid(color='k', linestyle='-', linewidth=1)
plt.legend(loc=1, prop={'size': 12})
plt.suptitle('线性判别分析与收缩线性判别分析(1个判别特征)')
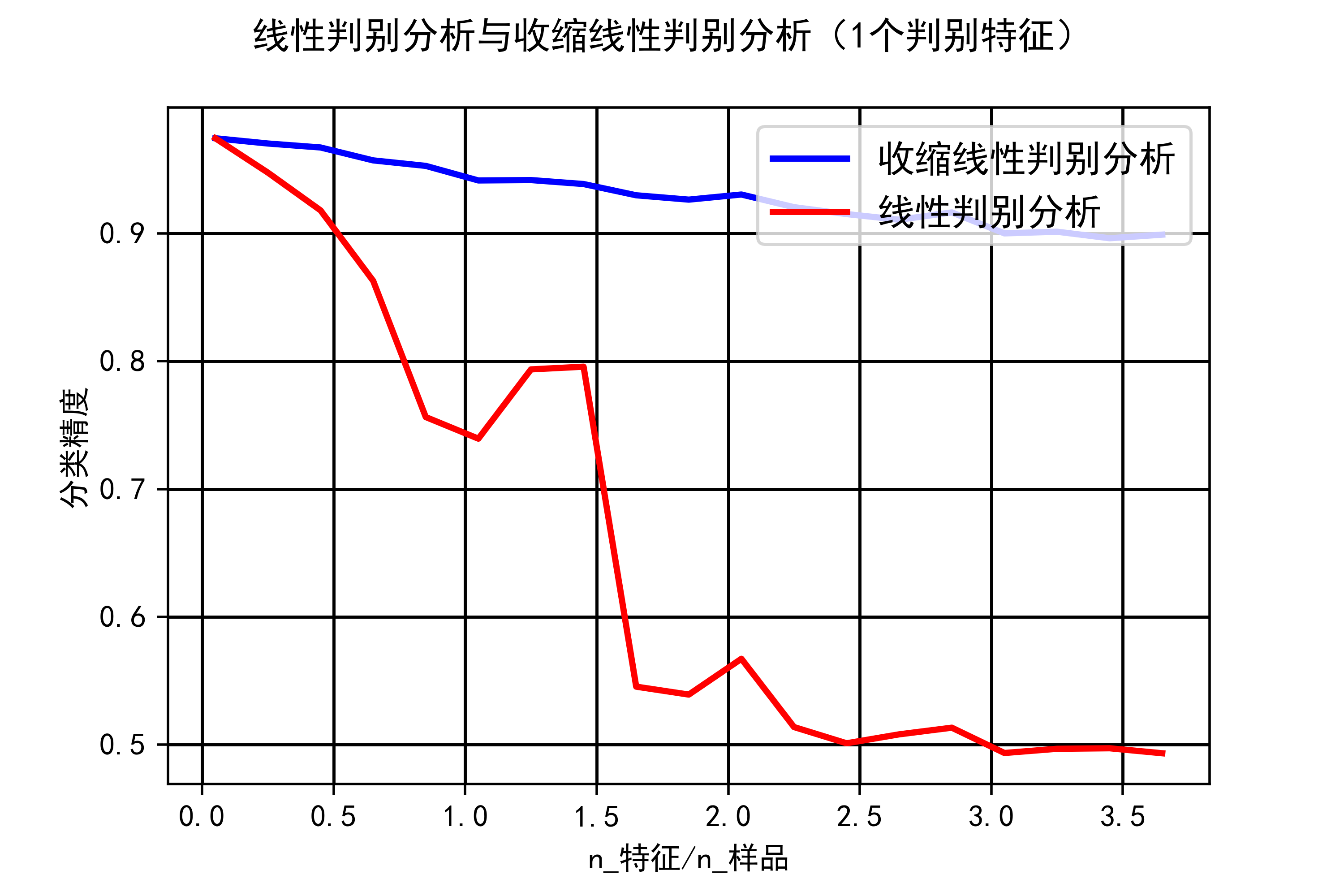
plt.show()示例运行结果如下图所示:
a、图中的蓝色曲线代表收缩线性判别分析(Shrinkage LDA)在不同特征数量下的平均分类精度。
b、图中的红色曲线代表线性判别分析(LDA)在不同特征数量下的平均分类精度。
c、横轴表示特征数量与样本数量的比率,随着特征数量增加,这个比率也会增加。
d、纵轴表示分类精度,即模型在测试数据上的分类正确率。分类精度越高,表示模型的性能越好。
e、通过比较两条曲线,可以看出收缩线性判别分析在不同特征数量下的分类精度是否优于传统线性判别分析。
03-基于Scikit-Learn识别手写数字的图像
支持向量机(SVM)是一种机器学习算法,用于分类和回归任务。在分类任务中,它的目标是找到一个决策边界,将不同类别的数据点分开。对于手写数字的图像识别任务,可以使用SVM来识别不同数字的图像。
首先,将手写数字的图像转换成数字矩阵的形式,其中每个数字代表像素的灰度值。然后,利用Scikit-Learn中的SVM模型进行训练。在训练过程中,SVM会尝试找到一个能够将不同数字之间的分界线最大化的超平面,以最大程度地将它们分开。
训练完成后,可以使用测试集来评估模型的性能。将测试集中的手写数字图像输入到训练好的SVM模型中,然后观察模型对这些图像的分类准确率。最终,我们可以得到一个能够识别手写数字图像的SVM分类器,可以用于实际的数字识别任务中。
下面给出具体代码分析应用过程:这段代码是一个基于支持向量机(SVM)的分类器,用于识别手写数字的图像。下面是对代码的简要解释:
导入库和数据集:首先,导入了需要使用的库,包括 matplotlib 用于绘图和可视化,datasets 模块用于加载数据集,svm 模块包含了支持向量机算法,metrics 模块用于评估分类器性能,train_test_split 函数用于将数据集分为训练集和测试集。
加载数据集:使用 datasets.load_digits() 加载手写数字数据集。
数据预处理:将图像数据展平为一维数组,以便于后续分类器的处理。
创建并训练分类器:使用支持向量机分类器 svm.SVC() 创建了一个分类器,并将训练集数据和标签用于训练。
模型评估:使用测试集数据进行预测,并与真实标签进行比较,生成分类报告和混淆矩阵,以评估分类器的性能。
可视化:通过 matplotlib 库绘制了训练集中前四个样本的图像及其对应的标签,以及测试集中前四个样本的图像及其预测值,并展示了混淆矩阵以便更直观地了解分类结果。
import matplotlib.pyplot as plt# Import datasets, classifiers and performance metrics
from sklearn import datasets, svm, metrics
from sklearn.model_selection import train_test_split# 加载数据
digits = datasets.load_digits()# 创建子图
_, axes = plt.subplots(2, 4)
images_and_labels = list(zip(digits.images, digits.target))
# 展示前四个样本及其标签
for ax, (image, label) in zip(axes[0, :], images_and_labels[:4]):ax.set_axis_off()ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')ax.set_title('Training: %i' % label)n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))# Create a classifier: a support vector classifier
classifier = svm.SVC(gamma=0.001)# Split data into train and test subsets
X_train, X_test, y_train, y_test = train_test_split(data, digits.target, test_size=0.5, shuffle=False)# We learn the digits on the first half of the digits
classifier.fit(X_train, y_train)# Now predict the value of the digit on the second half:
predicted = classifier.predict(X_test)images_and_predictions = list(zip(digits.images[n_samples // 2:], predicted))
for ax, (image, prediction) in zip(axes[1, :], images_and_predictions[:4]):ax.set_axis_off()ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')ax.set_title('Prediction: %i' % prediction)print("分类器的分类报告 %s:\n%s\n"% (classifier, metrics.classification_report(y_test, predicted)))
disp = metrics.plot_confusion_matrix(classifier, X_test, y_test)
disp.figure_.suptitle("混淆矩阵")
print("混淆矩阵:\n%s" % disp.confusion_matrix)
plt.savefig("../4.png", dpi=500)
plt.show()示例运行结果如下图所示:
a、训练集样本图像及标签:首先展示了训练集中的前四个手写数字图像,每个图像的标题显示了对应的真实标签。这些图像是用于训练分类器的一部分数据,它们以灰度图像的形式显示在子图中。
b、测试集样本图像及预测值:接着展示了测试集中的前四个手写数字图像及其预测值。分类器对这些图像进行了预测,并将预测值显示在图像的标题中。通过这些图像可以看到分类器的预测结果。
c、分类报告:在输出中打印了分类报告,其中包含了分类器在测试集上的性能指标,如准确率、召回率、F1-score等,以及每个类别的支持数量。
d、混淆矩阵:最后,通过混淆矩阵可视化了分类器在测试集上的表现。混淆矩阵以热图的形式展示了分类器预测结果与真实标签之间的关系,更直观地显示了分类器的准确性和错误情况。


04-绘制不同分类器的分类概率
本小节使用一个三类的数据集,绘制不同分类器的分类概率。并使用支持向量分类器、带L1和L2惩罚项的Logistic回归, 使用One-Vs-Rest或多项设置以及高斯过程分类对其进行分类。
下面给出具体代码分析几种分类器的分类概率,这段代码实现了对鸢尾花数据集的分类,并绘制了不同分类器的分类概率图像。代码解释如下:
数据加载和准备:代码开始通过datasets.load_iris()加载鸢尾花数据集,并仅保留前两个特征以便于可视化。然后,将数据集的特征存储在X中,标签存储在y中。
创建不同分类器:代码创建了五种不同的分类器,分别是带有L1惩罚项的逻辑回归、带有L2惩罚项的多项式逻辑回归、带有L2惩罚项的一对其余(OvR)逻辑回归、线性支持向量分类器(Linear SVC)以及高斯过程分类器(GPC)。
训练和评估分类器:对于每个分类器,代码使用fit()方法在训练集上进行训练,并使用predict()方法对训练集进行预测,计算准确率并打印输出。
绘制分类概率图像:对于每个分类器,代码使用predict_proba()方法获取在整个特征空间上的类别概率,并将概率可视化为图像。
import matplotlib.pyplot as plt
import numpy as npfrom sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn import datasetsiris = datasets.load_iris()
X = iris.data[:, 0:2] # we only take the first two features for visualization
y = iris.targetn_features = X.shape[1]C = 10
kernel = 1.0 * RBF([1.0, 1.0]) # for GPC# Create different classifiers.
classifiers = {'L1 logistic': LogisticRegression(C=C, penalty='l1',solver='saga',multi_class='multinomial',max_iter=10000),'L2 logistic (Multinomial)': LogisticRegression(C=C, penalty='l2',solver='saga',multi_class='multinomial',max_iter=10000),'L2 logistic (OvR)': LogisticRegression(C=C, penalty='l2',solver='saga',multi_class='ovr',max_iter=10000),'Linear SVC': SVC(kernel='linear', C=C, probability=True,random_state=0),'GPC': GaussianProcessClassifier(kernel)
}n_classifiers = len(classifiers)plt.figure(figsize=(3 * 2, n_classifiers * 2))
plt.subplots_adjust(bottom=.2, top=.95)xx = np.linspace(3, 9, 100)
yy = np.linspace(1, 5, 100).T
xx, yy = np.meshgrid(xx, yy)
Xfull = np.c_[xx.ravel(), yy.ravel()]for index, (name, classifier) in enumerate(classifiers.items()):classifier.fit(X, y)y_pred = classifier.predict(X)accuracy = accuracy_score(y, y_pred)print("Accuracy (train) for %s: %0.1f%% " % (name, accuracy * 100))# View probabilities:probas = classifier.predict_proba(Xfull)n_classes = np.unique(y_pred).sizefor k in range(n_classes):plt.subplot(n_classifiers, n_classes, index * n_classes + k + 1)plt.title("Class %d" % k)if k == 0:plt.ylabel(name)imshow_handle = plt.imshow(probas[:, k].reshape((100, 100)),extent=(3, 9, 1, 5), origin='lower')plt.xticks(())plt.yticks(())idx = (y_pred == k)if idx.any():plt.scatter(X[idx, 0], X[idx, 1], marker='o', c='w', edgecolor='k')ax = plt.axes([0.15, 0.04, 0.7, 0.05])
plt.title("Probability")
plt.colorbar(imshow_handle, cax=ax, orientation='horizontal')
plt.savefig("../4.png", dpi=500)
plt.show()# 运行结果:
Accuracy (train) for L1 logistic: 82.7%
Accuracy (train) for L2 logistic (Multinomial): 82.7%
Accuracy (train) for L2 logistic (OvR): 79.3%
Accuracy (train) for Linear SVC: 82.0%
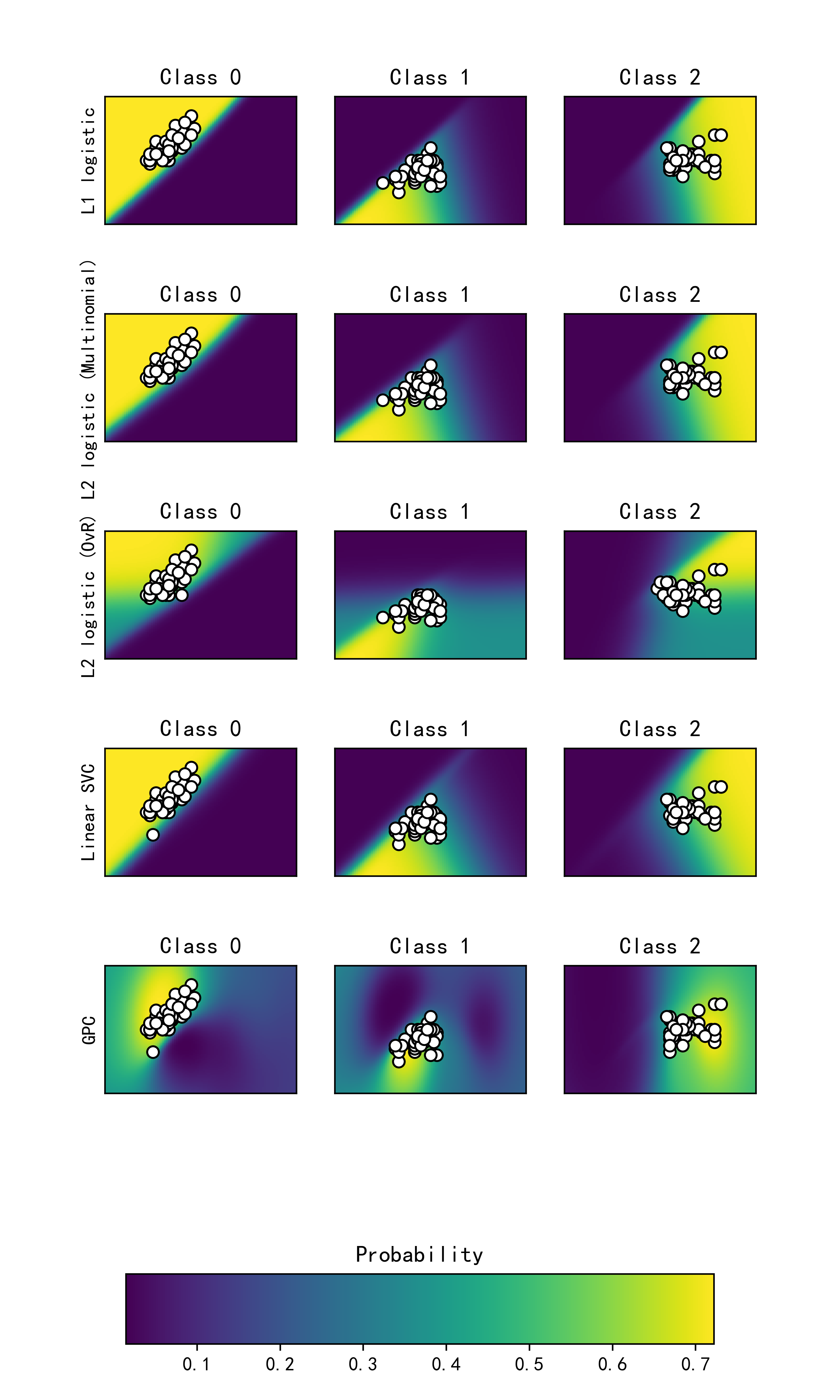
Accuracy (train) for GPC: 82.7% 示例运行结果如下图所示: 这些图像按行显示,每行代表一个分类器,按列显示,每列代表一个类别。图像的颜色深浅表示对应位置的类别概率,越深表示概率越高。同时,散点图显示了原始数据点,点的颜色表示它们的真实类别。
05-不同分类器的决策边界的性质比较
不同分类器的决策边界性质是指它们在将特征空间划分为不同类别区域时的方式和特点。下面是对几种常见分类器决策边界性质的比较解释:
(1)最近邻分类器(Nearest Neighbors):决策边界通常是非线性的,距离较近的点归为一类。决策边界的形状受到数据分布的影响,边界可能会紧密地围绕着数据点。
(2)线性支持向量机(Linear SVM):决策边界是线性的,通常是直线或者超平面。在特征空间中寻找一个能够最大化类别间间隔的超平面。
(3)高斯核支持向量机(RBF SVM):决策边界是非线性的,通过核函数将特征映射到高维空间,然后在高维空间中构建线性分隔超平面。决策边界的灵活性取决于核函数的选择和参数调整。
(4)高斯过程分类器(Gaussian Process):决策边界的形状不固定,可以适应数据的任意形状。使用高斯过程来建模类别之间的关系,可以提供决策边界的不确定性估计。
(5)决策树(Decision Tree):决策边界由一系列垂直于特征轴的决策边界组成,每个节点都代表一个特征测试。决策树的决策边界通常是矩形的,具有垂直和水平分隔线。
(6)随机森林(Random Forest):随机森林由多个决策树组成,每棵树都对数据进行随机抽样和特征选择。决策边界由多棵树投票决定,通常比单棵决策树的决策边界更平滑。
(7)神经网络(Neural Net):决策边界的形状非常灵活,可以适应各种复杂的数据模式。神经网络可以学习非线性的决策边界,具有很强的表达能力。
(8)AdaBoost:AdaBoost通过迭代训练弱分类器,每次调整样本权重来学习不同的数据特征,最终组合成强分类器。决策边界可以是任意形状,但会偏向于对错误分类样本进行更多关注,从而修正错误。
(9)朴素贝叶斯(Naive Bayes):决策边界通常是线性的或者简单的超平面,因为朴素贝叶斯假设特征之间相互独立。决策边界的形状取决于特征之间的相关性和数据分布情况。
(10)QDA(Quadratic Discriminant Analysis):决策边界可以是二次曲线或者二次超曲面,因为QDA允许类别的协方差矩阵不同。对于高维数据,决策边界的形状会更加复杂,可以适应各种数据分布。
下面给出具体代码分析这些分类器的比较过程,这段代码是一个完整的分类器比较和可视化程序,它的主要作用是:
导入必要的库和模块:numpy 用于数值计算。matplotlib.pyplot 用于绘图。ListedColormap 用于创建颜色映射。train_test_split 用于数据集的划分。StandardScaler 用于特征标准化。make_moons, make_circles, make_classification 用于生成不同形状的合成数据集。各种分类器算法模型。
定义一些变量和参数:h 是决策边界的步长。names 是分类器的名称列表,中文名字。classifiers 是对应的分类器算法模型列表。datasets 是三个不同形状的合成数据集。
循环遍历不同的数据集:对每个数据集进行预处理,包括标准化和划分训练集和测试集。设置绘图所需的网格范围和步长。绘制原始数据点和训练集、测试集的散点图。
循环遍历不同的分类器算法模型:在当前数据集上训练分类器。对网格中的每个点进行预测,生成决策边界。用颜色填充决策边界,同时绘制训练集和测试集的散点图。在子图标题中显示分类器的名称,并显示分类器在测试集上的准确率。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_moons, make_circles, make_classification
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysish = .02 # step size in the meshnames = ["最近邻", "线性支持向量机", "高斯核支持向量机", "高斯过程","决策树", "随机森林", "神经网络", "自适应增强算法","朴素贝叶斯", "二次判别分析"]classifiers = [KNeighborsClassifier(3),SVC(kernel="linear", C=0.025),SVC(gamma=2, C=1),GaussianProcessClassifier(1.0 * RBF(1.0)),DecisionTreeClassifier(max_depth=5),RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1),MLPClassifier(alpha=1, max_iter=1000),AdaBoostClassifier(),GaussianNB(),QuadraticDiscriminantAnalysis()]X, y = make_classification(n_features=2, n_redundant=0, n_informative=2,random_state=1, n_clusters_per_class=1)
rng = np.random.RandomState(2)
X += 2 * rng.uniform(size=X.shape)
linearly_separable = (X, y)datasets = [make_moons(noise=0.3, random_state=0),make_circles(noise=0.2, factor=0.5, random_state=1),linearly_separable]figure = plt.figure(figsize=(27, 9))
i = 1
# iterate over datasets
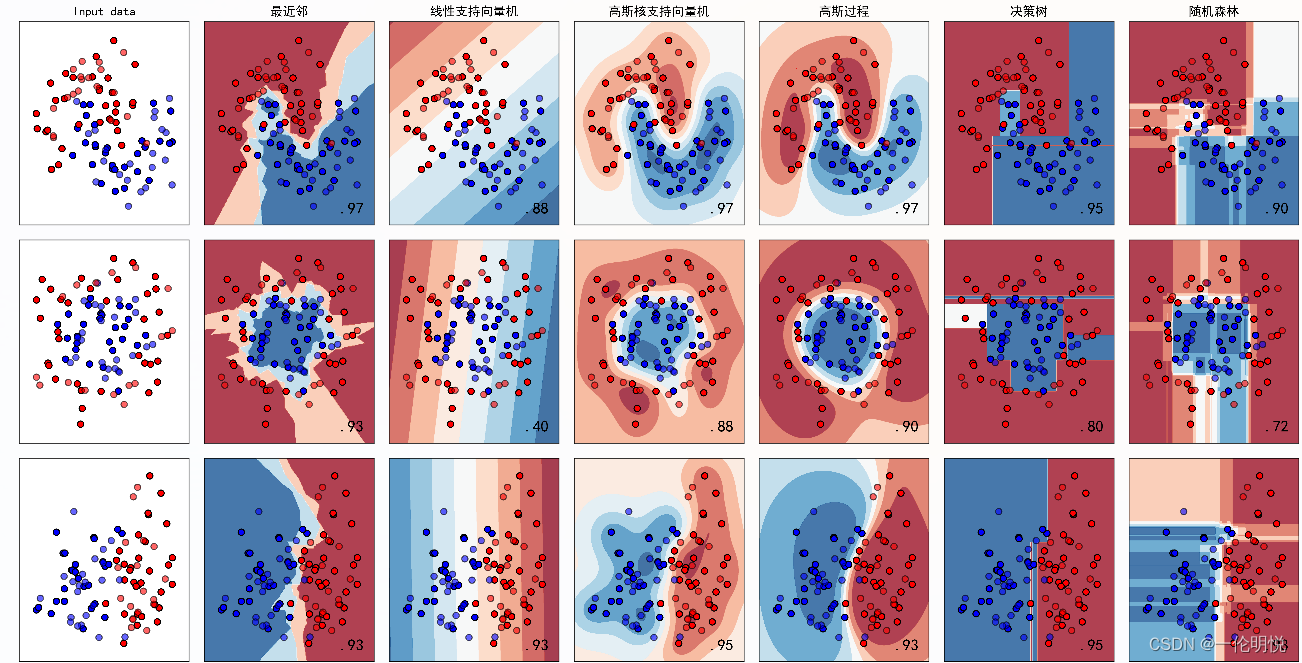
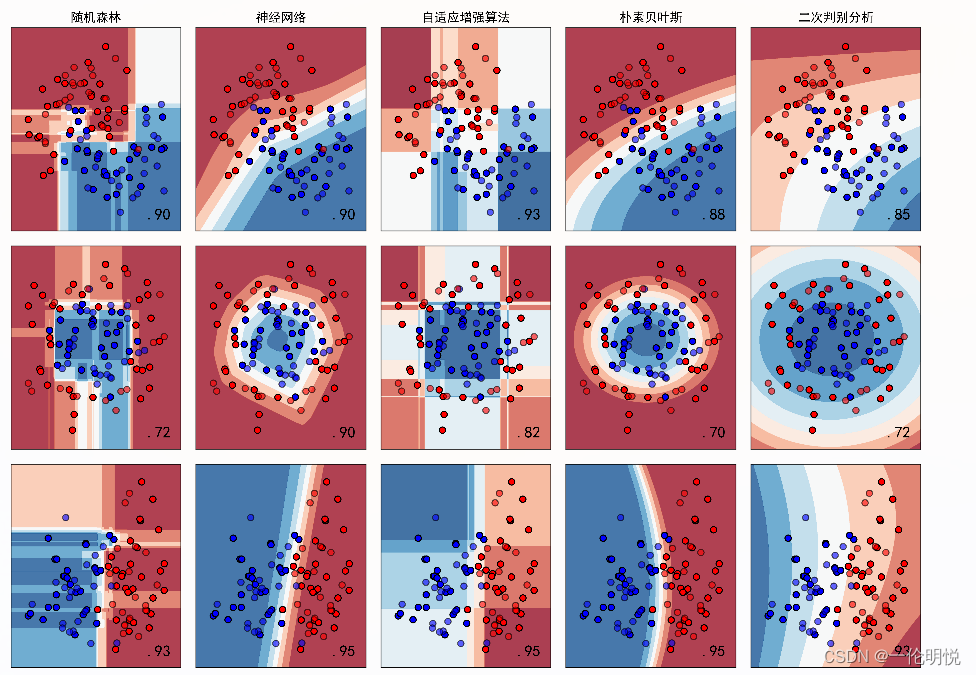
for ds_cnt, ds in enumerate(datasets):# preprocess dataset, split into training and test partX, y = dsX = StandardScaler().fit_transform(X)X_train, X_test, y_train, y_test = \train_test_split(X, y, test_size=.4, random_state=42)x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h))# just plot the dataset firstcm = plt.cm.RdBucm_bright = ListedColormap(['#FF0000', '#0000FF'])ax = plt.subplot(len(datasets), len(classifiers) + 1, i)if ds_cnt == 0:ax.set_title("Input data")# Plot the training pointsax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright,edgecolors='k')# Plot the testing pointsax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6,edgecolors='k')ax.set_xlim(xx.min(), xx.max())ax.set_ylim(yy.min(), yy.max())ax.set_xticks(())ax.set_yticks(())i += 1# iterate over classifiersfor name, clf in zip(names, classifiers):ax = plt.subplot(len(datasets), len(classifiers) + 1, i)clf.fit(X_train, y_train)score = clf.score(X_test, y_test)# Plot the decision boundary. For that, we will assign a color to each# point in the mesh [x_min, x_max]x[y_min, y_max].if hasattr(clf, "decision_function"):Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])else:Z = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1]# Put the result into a color plotZ = Z.reshape(xx.shape)ax.contourf(xx, yy, Z, cmap=cm, alpha=.8)# Plot the training pointsax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright,edgecolors='k')# Plot the testing pointsax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright,edgecolors='k', alpha=0.6)ax.set_xlim(xx.min(), xx.max())ax.set_ylim(yy.min(), yy.max())ax.set_xticks(())ax.set_yticks(())if ds_cnt == 0:ax.set_title(name)ax.text(xx.max() - .3, yy.min() + .3, ('%.2f' % score).lstrip('0'),size=15, horizontalalignment='right')i += 1plt.tight_layout()plt.show()示例运行结果如下图所示:生成的图像展示了不同分类器在不同形状的合成数据集上的决策边界。每个子图代表一个分类器在一个数据集上的表现,其中:
图中显示实色训练点和半透明的测试点。右下角显示测试集的分类准确率。
散点图表示原始数据点,不同颜色代表不同类别。
填充的区域表示分类器的决策边界,不同颜色的区域代表不同的类别预测。
每个子图的标题是分类器的名称。
右下角的数字表示分类器在相应数据集上的测试集准确率。
06-协方差椭球的线性和二次判别分析
协方差椭球(Covariance Ellipsoid)是用于可视化数据集特征之间关系的一种工具。在线性判别分析(LDA)和二次判别分析(QDA)中,协方差椭球是一个重要的概念。
线性判别分析(LDA)
线性判别分析是一种经典的监督学习算法,用于降低数据维度并且能够识别最能有效地分类不同类别的特征。其核心思想是将数据投影到一个低维度的子空间中,使得不同类别的数据点在投影后尽可能地分开。
在LDA中,假设每个类别的数据服从多元正态分布,并且各类别的协方差矩阵相等。在这种情况下,决策边界可以用一个超平面表示,该超平面被称为“判别平面”。
协方差椭球在LDA中的作用是描述数据的分布形状。在多元正态分布的假设下,每个类别的数据分布可以用一个椭球表示,该椭球的形状由协方差矩阵决定。协方差椭球的长轴方向与协方差矩阵的特征向量相一致,而长轴的长度与特征值相关。
二次判别分析(QDA)
二次判别分析是LDA的一种扩展,它放宽了LDA的一个假设:各类别的协方差矩阵不再假定相等,而是允许每个类别具有不同的协方差矩阵。这使得QDA能够更灵活地拟合数据,但也增加了模型的复杂度。
在QDA中,每个类别的数据分布可以用一个独立的协方差椭球来描述,而这些椭球的形状和方向可以不同。相比于LDA,QDA的决策边界更加灵活,能够更好地适应数据的分布。
协方差椭球在QDA中的作用与LDA类似,用于描述数据的分布形状。但在QDA中,不同类别的数据可能具有不同的协方差矩阵,因此每个类别的协方差椭球的形状和方向都可能不同。
总的来说,协方差椭球在LDA和QDA中都是用于描述数据分布形状的重要工具。在LDA中,协方差椭球表示不同类别数据的分布形状,而在QDA中,每个类别的数据可能具有不同的协方差椭球,从而使得决策边界更加灵活。
下面给出具体代码分析应用过程,这段代码实现了对线性判别分析(LDA)和二次判别分析(QDA)的可视化,并使用了协方差椭球来描述数据的分布形状。代码解释:
导入必要的库和模块:从scipy、numpy、matplotlib以及sklearn中导入所需的函数和类。
定义数据生成函数:dataset_fixed_cov()和dataset_cov()函数分别生成具有固定协方差和变化协方差的数据集。
定义绘图函数:plot_data()函数用于绘制数据点和决策边界,plot_ellipse()函数用于绘制协方差椭球,plot_lda_cov()和plot_qda_cov()函数分别用于绘制LDA和QDA中的协方差椭球。
创建画布并绘制图像:使用plt.figure()创建画布,然后循环遍历数据集,对每个数据集进行LDA和QDA分析,并绘制相应的图像。
from scipy import linalg
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from matplotlib import colorsfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis# #############################################################################
# Colormap
cmap = colors.LinearSegmentedColormap('red_blue_classes',{'red': [(0, 1, 1), (1, 0.7, 0.7)],'green': [(0, 0.7, 0.7), (1, 0.7, 0.7)],'blue': [(0, 0.7, 0.7), (1, 1, 1)]})
plt.cm.register_cmap(cmap=cmap)# #############################################################################
# Generate datasets
def dataset_fixed_cov():n, dim = 300, 2np.random.seed(0)C = np.array([[0., -0.23], [0.83, .23]])X = np.r_[np.dot(np.random.randn(n, dim), C),np.dot(np.random.randn(n, dim), C) + np.array([1, 1])]y = np.hstack((np.zeros(n), np.ones(n)))return X, ydef dataset_cov():n, dim = 300, 2np.random.seed(0)C = np.array([[0., -1.], [2.5, .7]]) * 2.X = np.r_[np.dot(np.random.randn(n, dim), C),np.dot(np.random.randn(n, dim), C.T) + np.array([1, 4])]y = np.hstack((np.zeros(n), np.ones(n)))return X, y# #############################################################################
# Plot functions
def plot_data(lda, X, y, y_pred, fig_index):splot = plt.subplot(2, 2, fig_index)if fig_index == 1:plt.title('线性判别分析')plt.ylabel('具有n固定协方差的数据')elif fig_index == 2:plt.title('二次判别分析')elif fig_index == 3:plt.ylabel('具有n变化协方差的数据')tp = (y == y_pred) # True Positivetp0, tp1 = tp[y == 0], tp[y == 1]X0, X1 = X[y == 0], X[y == 1]X0_tp, X0_fp = X0[tp0], X0[~tp0]X1_tp, X1_fp = X1[tp1], X1[~tp1]# class 0: dotsplt.scatter(X0_tp[:, 0], X0_tp[:, 1], marker='.', color='red')plt.scatter(X0_fp[:, 0], X0_fp[:, 1], marker='x',s=20, color='#990000') # dark red# class 1: dotsplt.scatter(X1_tp[:, 0], X1_tp[:, 1], marker='.', color='blue')plt.scatter(X1_fp[:, 0], X1_fp[:, 1], marker='x',s=20, color='#000099') # dark blue# class 0 and 1 : areasnx, ny = 200, 100x_min, x_max = plt.xlim()y_min, y_max = plt.ylim()xx, yy = np.meshgrid(np.linspace(x_min, x_max, nx),np.linspace(y_min, y_max, ny))Z = lda.predict_proba(np.c_[xx.ravel(), yy.ravel()])Z = Z[:, 1].reshape(xx.shape)plt.pcolormesh(xx, yy, Z, cmap='red_blue_classes',norm=colors.Normalize(0., 1.), zorder=0)plt.contour(xx, yy, Z, [0.5], linewidths=2., colors='white')# meansplt.plot(lda.means_[0][0], lda.means_[0][1],'*', color='yellow', markersize=15, markeredgecolor='grey')plt.plot(lda.means_[1][0], lda.means_[1][1],'*', color='yellow', markersize=15, markeredgecolor='grey')return splotdef plot_ellipse(splot, mean, cov, color):v, w = linalg.eigh(cov)u = w[0] / linalg.norm(w[0])angle = np.arctan(u[1] / u[0])angle = 180 * angle / np.pi # convert to degrees# filled Gaussian at 2 standard deviationell = mpl.patches.Ellipse(mean, 2 * v[0] ** 0.5, 2 * v[1] ** 0.5,180 + angle, facecolor=color,edgecolor='black', linewidth=2)ell.set_clip_box(splot.bbox)ell.set_alpha(0.2)splot.add_artist(ell)splot.set_xticks(())splot.set_yticks(())def plot_lda_cov(lda, splot):plot_ellipse(splot, lda.means_[0], lda.covariance_, 'red')plot_ellipse(splot, lda.means_[1], lda.covariance_, 'blue')def plot_qda_cov(qda, splot):plot_ellipse(splot, qda.means_[0], qda.covariance_[0], 'red')plot_ellipse(splot, qda.means_[1], qda.covariance_[1], 'blue')plt.figure(figsize=(10, 8), facecolor='white')
plt.suptitle('线性判别分析与二次判别分析',y=0.98, fontsize=15)
for i, (X, y) in enumerate([dataset_fixed_cov(), dataset_cov()]):# Linear Discriminant Analysislda = LinearDiscriminantAnalysis(solver="svd", store_covariance=True)y_pred = lda.fit(X, y).predict(X)splot = plot_data(lda, X, y, y_pred, fig_index=2 * i + 1)plot_lda_cov(lda, splot)plt.axis('tight')# Quadratic Discriminant Analysisqda = QuadraticDiscriminantAnalysis(store_covariance=True)y_pred = qda.fit(X, y).predict(X)splot = plot_data(qda, X, y, y_pred, fig_index=2 * i + 2)plot_qda_cov(qda, splot)plt.axis('tight')
plt.tight_layout()
plt.subplots_adjust(top=0.92)
plt.savefig("../4.png", dpi=500)
plt.show()
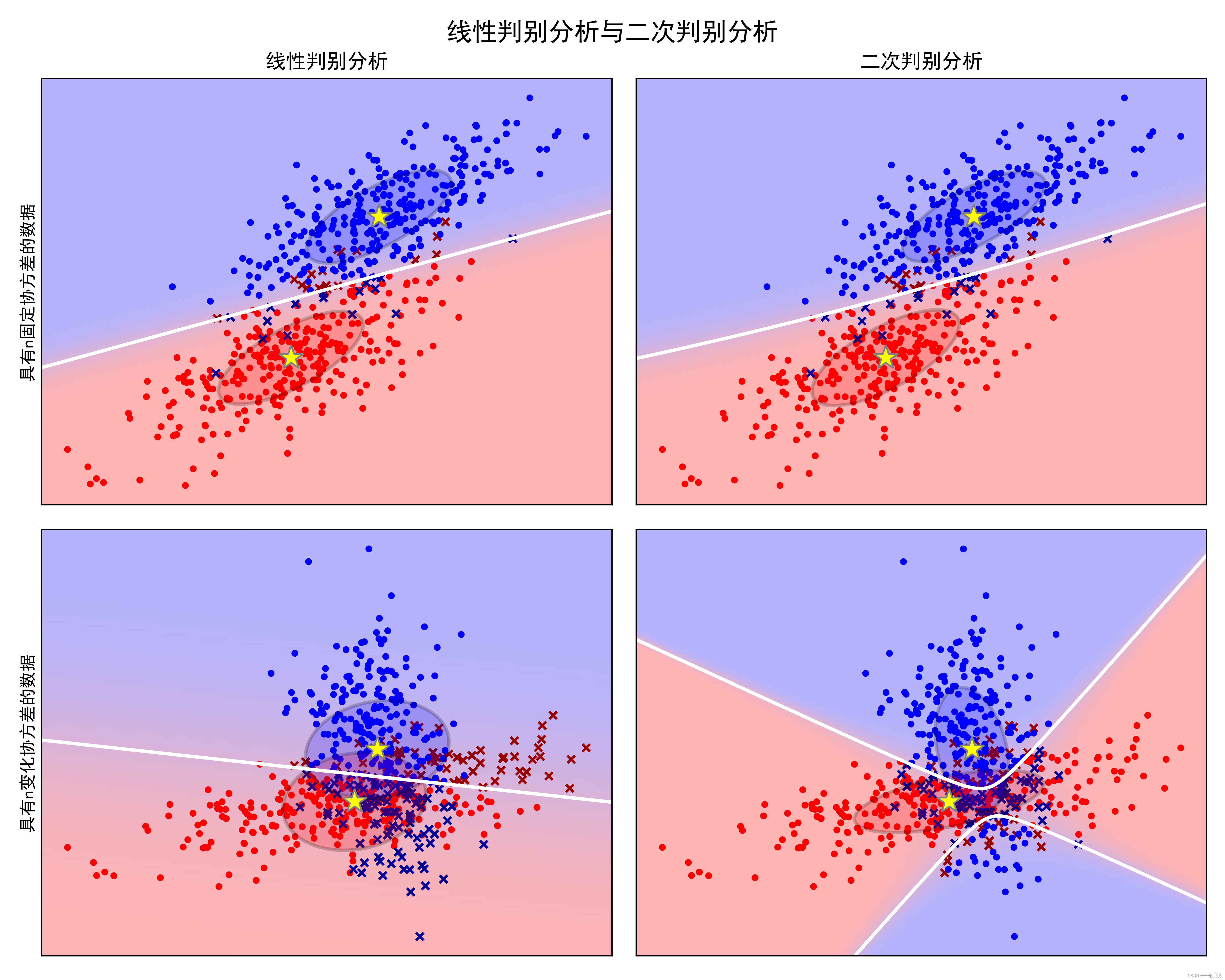
示例运行结果如下图所示:
子图分布:图像被分成两行两列,共四个子图,每个子图代表了一个数据集和相应的判别分析方法(LDA或QDA)。
数据点表示:红色和蓝色的点分别代表两个类别的数据点,其中红色代表类别0,蓝色代表类别1。
决策边界:白色虚线表示决策边界,分隔了两个类别的区域。
协方差椭球:每个子图中的半透明椭圆代表了对应类别的协方差椭球,其形状和方向反映了数据的分布情况。椭圆的中心是对应类别的均值点,椭圆的大小和形状受到协方差矩阵的影响,表征了数据分布的方差和相关性。
均值点表示:黄色星号表示每个类别的均值点,即数据集的中心。
总结
综上所述,可以从多个角度对机器学习分类模型进行总结。以下是一些可能包含的内容:
模型种类:逻辑回归(Logistic Regression);支持向量机(Support Vector Machine,SVM);决策树(Decision Tree);集成学习方法(如随机森林、梯度提升树);神经网络(Neural Networks);贝叶斯分类器(Bayesian Classifiers);K最近邻算法(K-Nearest Neighbors,KNN);判别分析方法(如线性判别分析、二次判别分析)
模型原理:每种模型的工作原理和假设条件,如逻辑回归假设数据服从伯努利分布,SVM通过找到最大间隔超平面进行分类等。
特点与适用场景:每种模型的优点和缺点,以及适用的数据情况和场景。比如,逻辑回归简单且易于解释,适用于线性可分或近似线性可分的数据;决策树适用于非线性可分的数据,且具有很好的解释性等。
训练和优化:每种模型的训练过程和优化方法,如使用梯度下降法或其他优化算法进行参数更新。
评估指标:用于评估模型性能的指标,如准确率、精确率、召回率、F1分数等,以及如何解释这些指标的含义。
特征工程:在应用机器学习模型之前,对数据进行的预处理和特征工程步骤,如数据清洗、缺失值处理、特征选择、特征变换等。
交叉验证与调参:使用交叉验证技术来评估模型泛化能力,并进行超参数调优,以提高模型性能。
应用案例:实际应用场景中各种分类模型的案例应用,以及它们在解决实际问题中的效果和局限性。
模型集成:使用模型集成技术来提高分类性能,如投票分类、堆叠集成等方法。
部署与监控:将训练好的模型部署到生产环境中,并建立监控机制来追踪模型性能和处理模型漂移等问题。
机器学习分类模型涵盖了多个方面,从模型种类到应用案例,都需要深入了解以有效地应用于实际问题中。





![[AIGC] 压缩列表了解吗?快速列表 quicklist 了解吗?](https://img-blog.csdnimg.cn/img_convert/7c70dfe31cd6cefffd2b2ffcd0dd652d.png)